一、前情提要
前面兩篇文章我們已經成功搭建了Hadoop以及安裝了Hive,Sqoop和Mysql資料庫,現在我們就來利用Hadoop嘗試做一個小實戰,實作單詞統計!
還沒有搭建Hadoop成功的同學,歡迎看看我之前的文章:Hadoop集群搭建(步驟圖文超詳細版)
目錄
- 一、前情提要
- 二、前置條件
- 三、上傳檔案至HDFS
- 四、壓縮Hadoop檔案
- 五、配置Eclipse
- 六、HDFS呼叫Api
二、前置條件
| 需要安裝 | 下載方法 |
|---|---|
| eclipse | 自備 |
| hadoop-eclipse-plugin-2.7.0.jar | 百度網盤下載 , 提取碼:f259 |
| MobaXterm | 百度網盤下載,提取碼:f64v |
本次將會用到的,HDFS命令大全:Hadoop——HDF的Shell命令,建議大家在操作時看看!!
三、上傳檔案至HDFS
首先,我們需要在Windows準備一個裝有英語單詞的文本檔案↓(不限詞數)
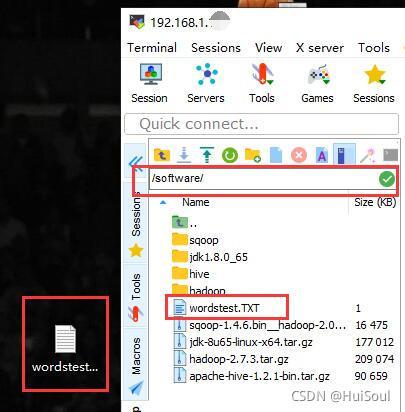
我們利用 MobaXterm 軟體將單詞檔案上傳至 Centos 中與 hadoop 檔案同目錄的 /software,這里大家根據自己檔案存放的地方存盤就好了,不一定要和我同一個目錄↓,
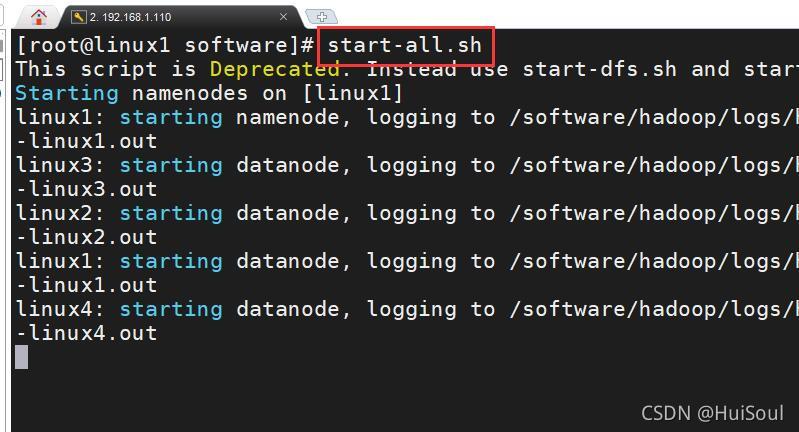
上傳至HDFS系統之前我們需要先啟動 Hadoop 集群!!
啟動 Hadoop 集群命令:start-all.sh
Tips:如果發現這個命令無法在任何目錄下使用,請檢查全域檔案中Hadoop路徑!!
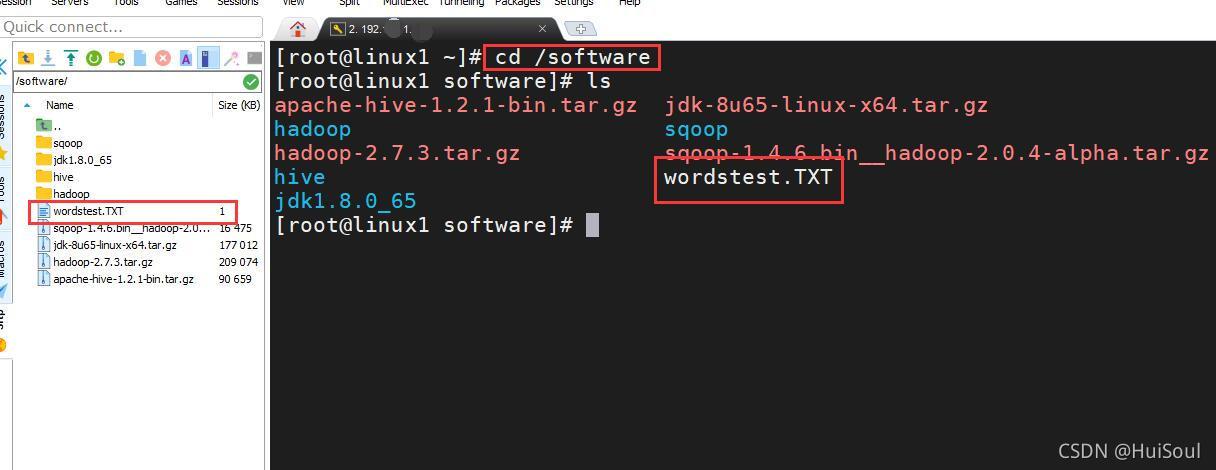
啟動集群之后,我們 cd 到存放單詞檔案的目錄下,命令↓
cd /software
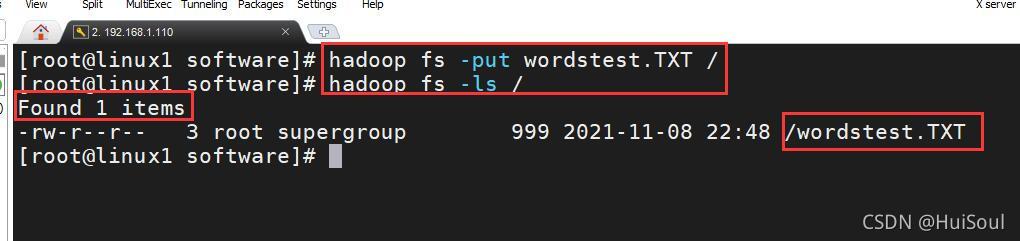
接著我們使用Hadoop的上傳檔案命令,再用 -ls 命令查看HDFS根目錄中的檔案,命令↓
hadoop fs -put wordstest.TXT /
hadoop fs -ls
注意!!如果Hadoop集群沒有正常啟動,將會報以下錯誤↓

查看上傳的wordstest.txt檔案內容,命令↓
hdfs dfs -cat /wordstest.TXT
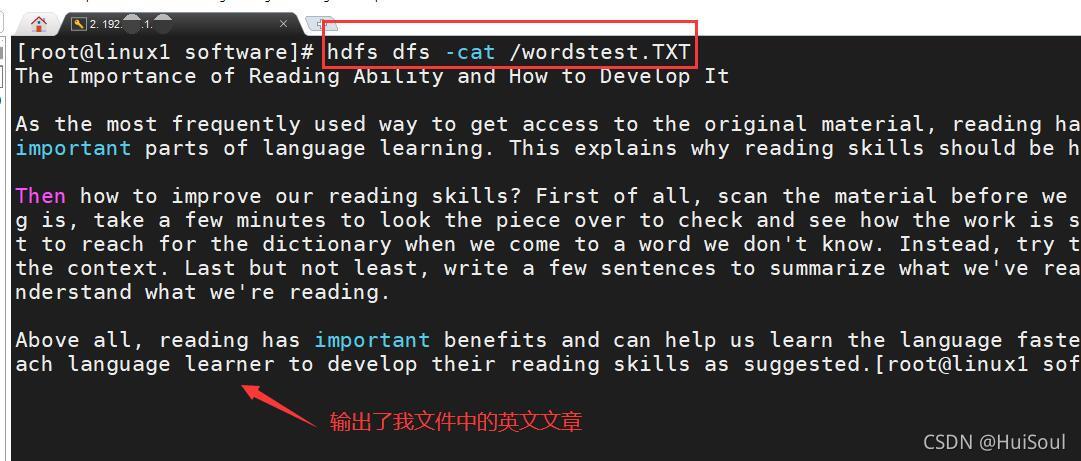
到這,英語單詞檔案已經上傳HDFS成功了!
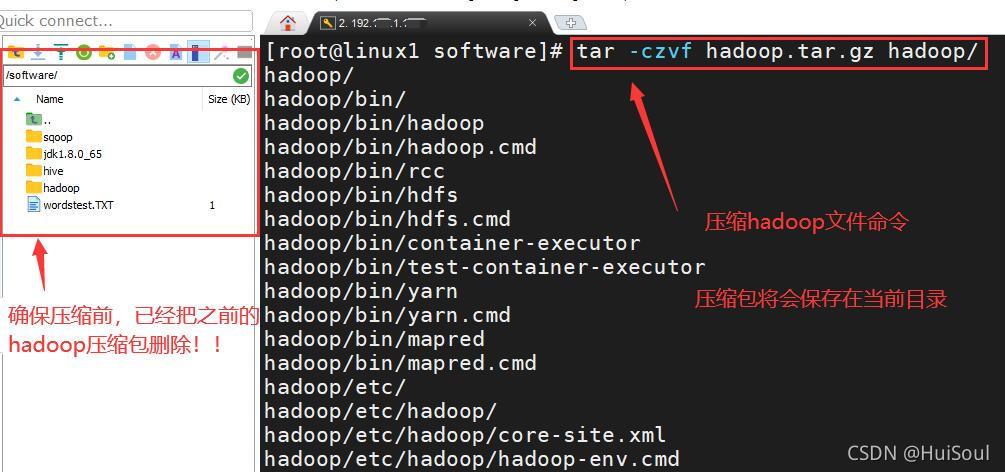
四、壓縮Hadoop檔案
命令↓
tar -czvf hadoop.tar.gz hadoop/
壓縮后的hadoop檔案↓
從 linux 系統上將 hadoop.tar.gz 壓縮包復制到Windows任一常用盤下↓
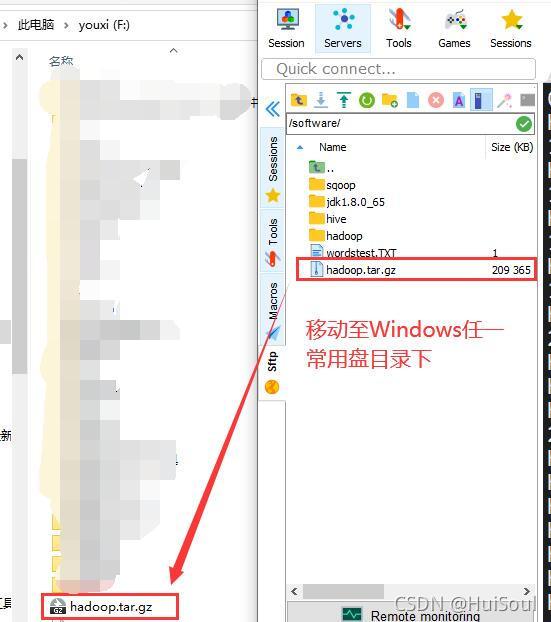
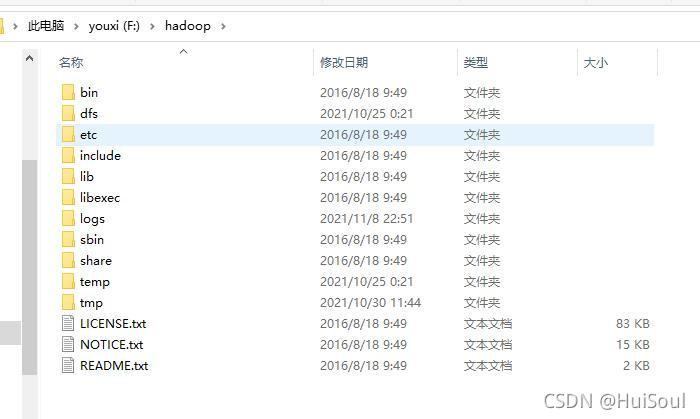
然后把 hadoop 壓縮包解壓縮↓
五、配置Eclipse
打開 Eclipse,在選單欄找到 Window,點擊里面的 Preferences↓
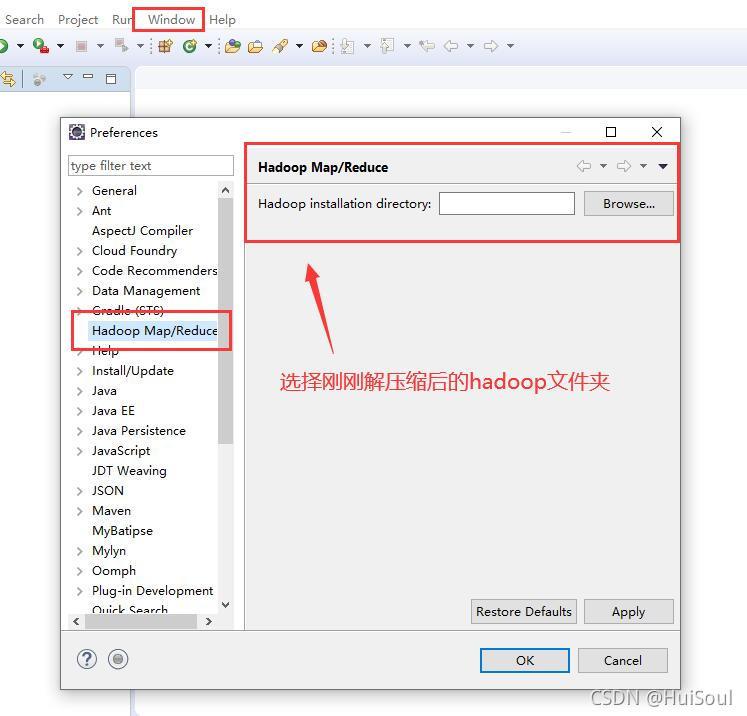
在左側找到Hadoop/ Map/Reduce配置,然后選擇hadoop檔案夾路徑↓
Tips:如果 Eclipse沒有安裝hadoop驅動插件,是不會顯示 Hadoop/ Map/Reduce 配置的!!如果發現沒有,在文章最上面找到 Eclipse-hadoop-plugin 下載,將插件放在 hadoop 目錄下的 plugins 中!
點擊 Apply 應用后,點擊 OK 回到主頁面,在 Eclipse 右上角找到下面這個按鈕點擊,在里面找到 Map/Reduce視圖 并選擇 OK ↓,回到主界面就會發現 Map/Reduce 視圖替換了之前的視圖
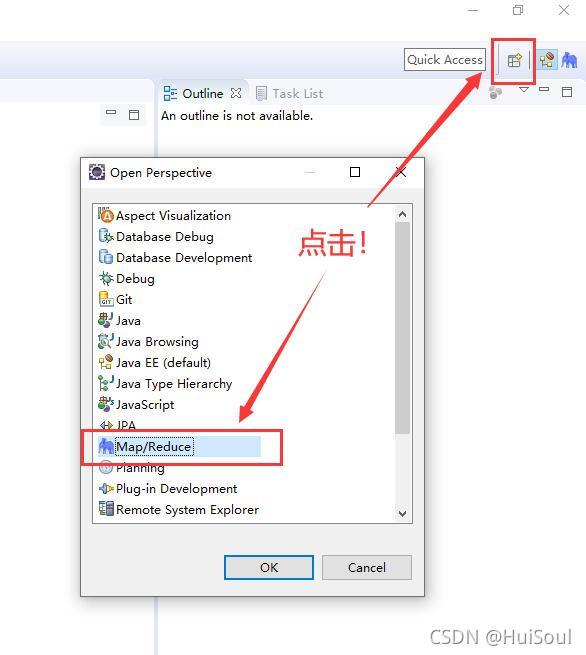
在主界面按順序分別點擊 Map/Reduce 和 圖示 后,填寫一下資訊↓
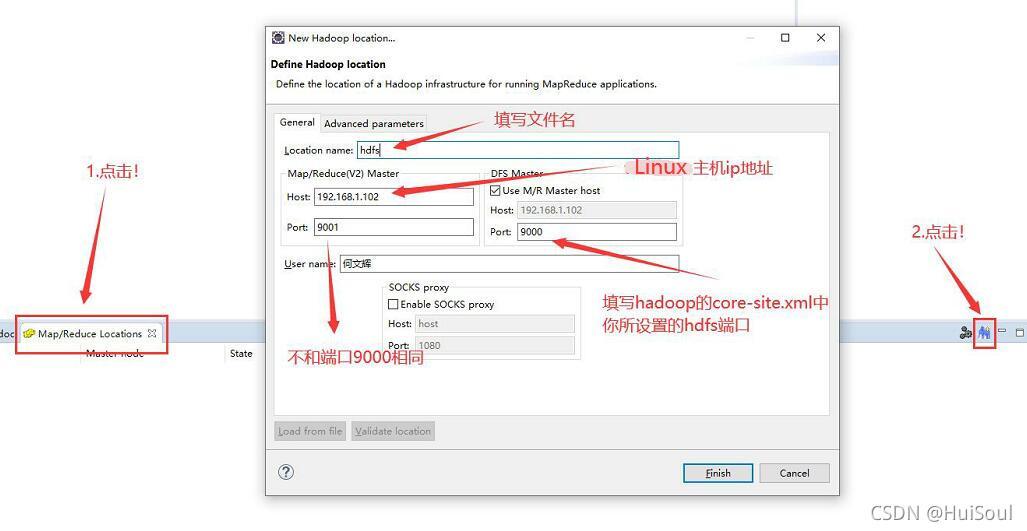
如果忘了設定 的HDFS 埠號,在 hadoop 檔案夾的 /etc/hadoop 目錄下找到 core-site.xml ,利用編輯器打開查看↓
同時!!我們查看完埠號后,還要復制 hadoop.tmp.dir 的目錄路徑↓
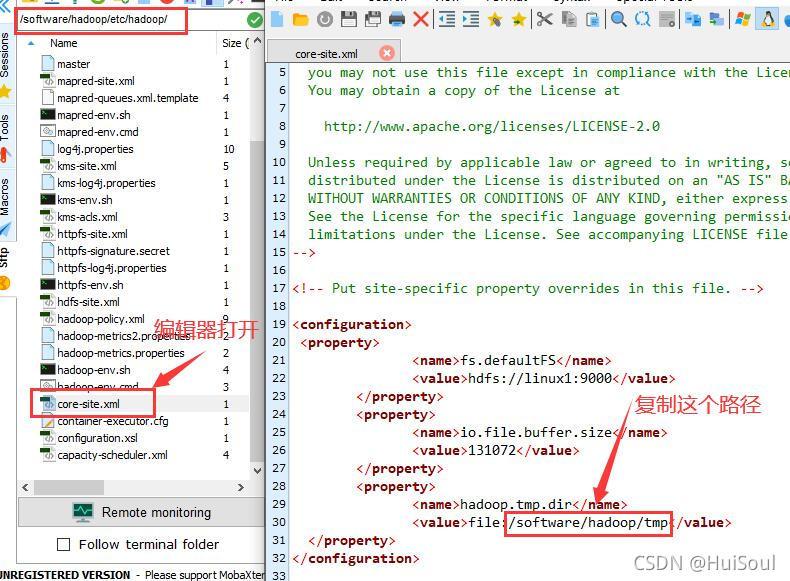
在 Edit Hadoop location 界面來到 Advanced parameters 頁面,找到 hadoop.tmp.dir 設定,并把剛剛復制的路徑覆寫原本的默認路徑↓
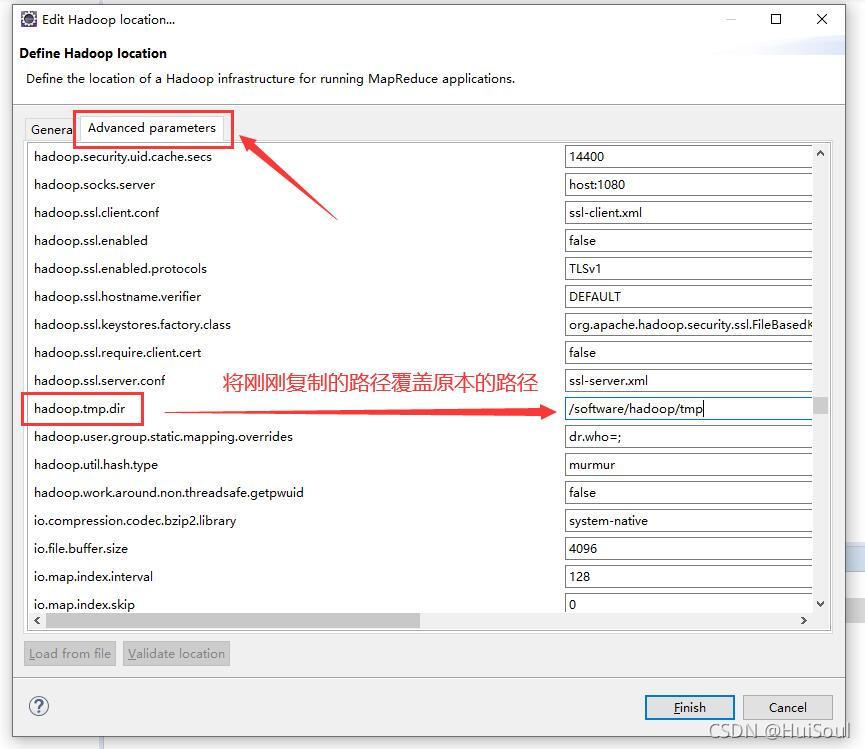
點擊 Finish ,然后就可以在主界面左側的hdfs專案中看到HDFS上的檔案結構!
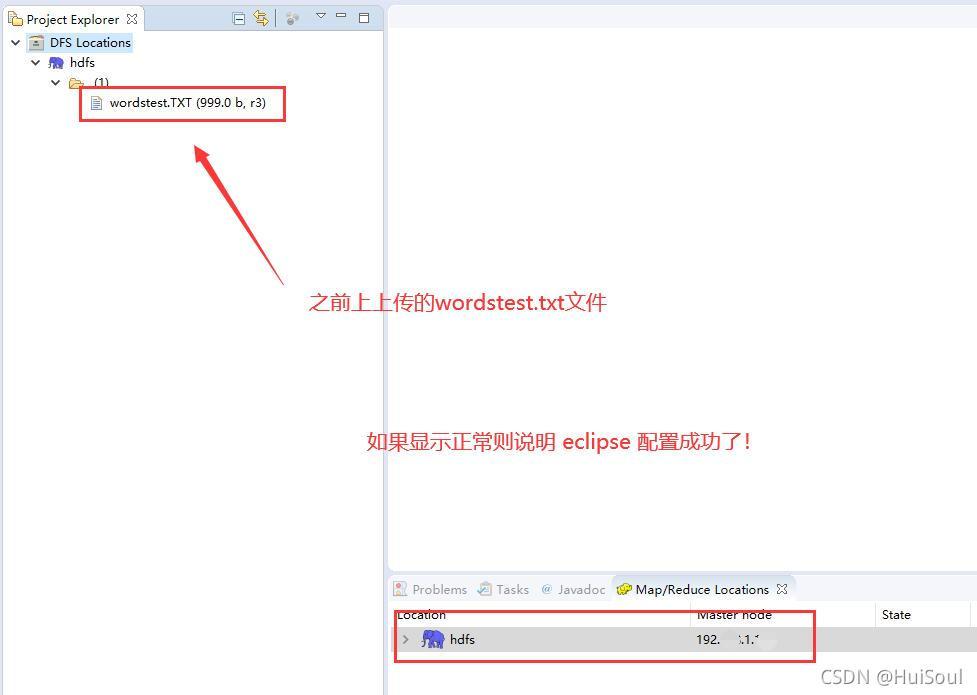
Tips:如果上面專案欄沒有正常顯示,而是顯示了 fail to connect 亂七八糟的,解決方法如下↓
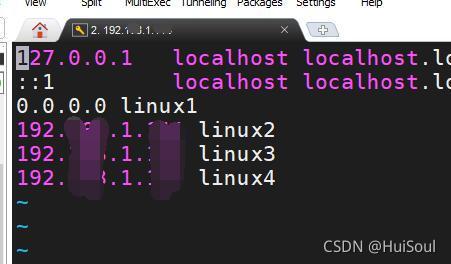
在 linux 的 hadoop 集群中的主節點下,修改 /etc/hosts 檔案,將主節點的 ip地址改為 0.0.0.0
再重啟網路和hadoop,總命令如下↓stop-all.sh vi /etc/hosts service network restart start-all.sh然后我們再回到 eclipse 中將原來專案洗掉,再重新建立一個,這時就會發現,哎!竟然成功了哈哈哈!
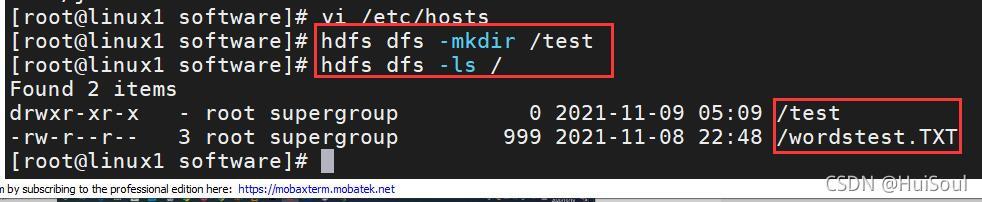
我們來嘗試操作一下!在 linux 的主節點中我們試著用命令在 HDFS 中創建一個檔案夾↓
然后在 eclipse 中重繪下,就能看到我們創建的 test 檔案夾了!
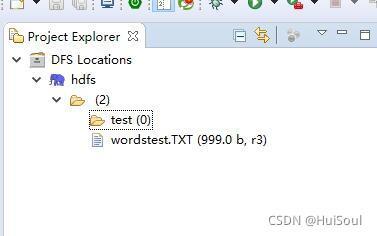
至此,我們的 ecplise 也已經配置成功了!!給點掌聲自己!!
六、HDFS呼叫Api
在 eclipse 創建一個 MapReduce 專案↓
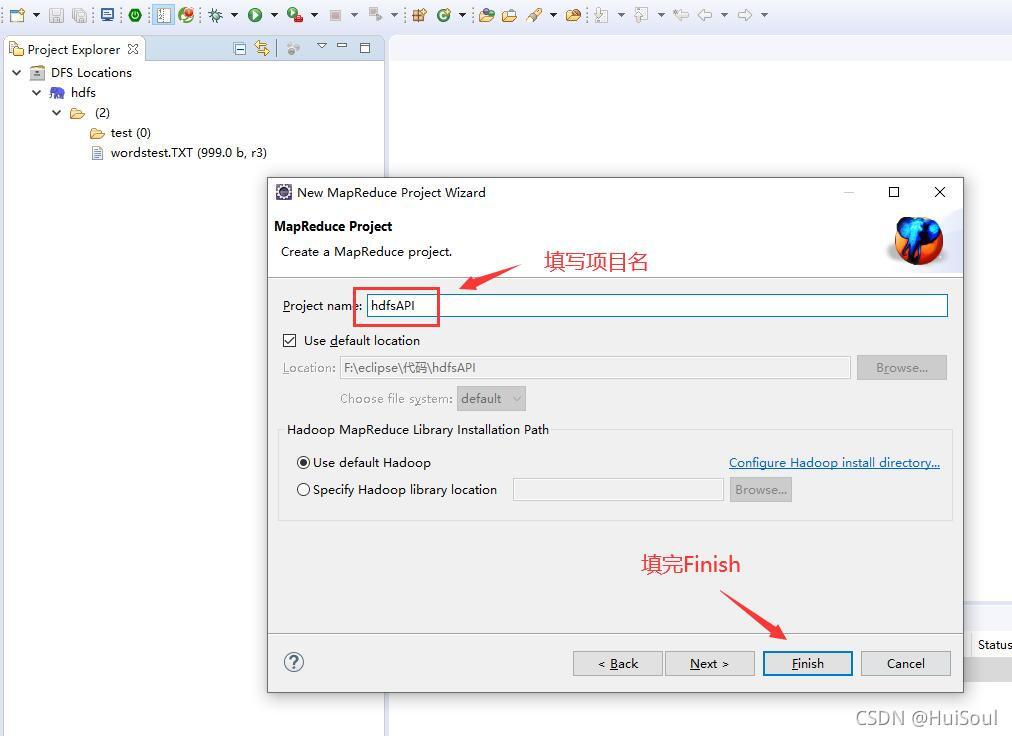
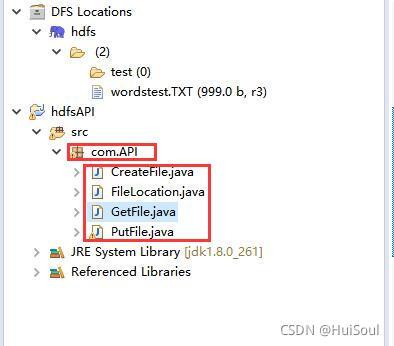
在專案的 src 目錄下創建包和包下的四個 java 檔案:CreateFile(創建檔案) 、GetFile(獲取檔案) 、PutFile(上傳檔案)、FileLocation(查看檔案路徑)
代碼如下↓
注意:別忘了修改代碼中你們自己的Linux主機IP地址!上傳檔案名也要選對你們放檔案的路徑!!
我存放檔案的目錄↓(以供參考,具體根據你們所定)
PutFile.java(上傳檔案)↓
package com.API;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class PutFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://linux主機IP地址:9000");
FileSystem fs = FileSystem.get(uri, conf);
//本地檔案
Path src = new Path("F:\\wordstest2.txt");
//HDFS存放位置
Path dst = new Path("/test/test.txt");
fs.copyFromLocalFile(src, dst);
System.out.println("Upload to " + conf.get("fs.defaultFS"));
//以下相當于執行hdfs dfs -ls /
FileStatus files[] = fs.listStatus(dst);
for (FileStatus file : files) {
System.out.println(file.getPath());
}
}
}
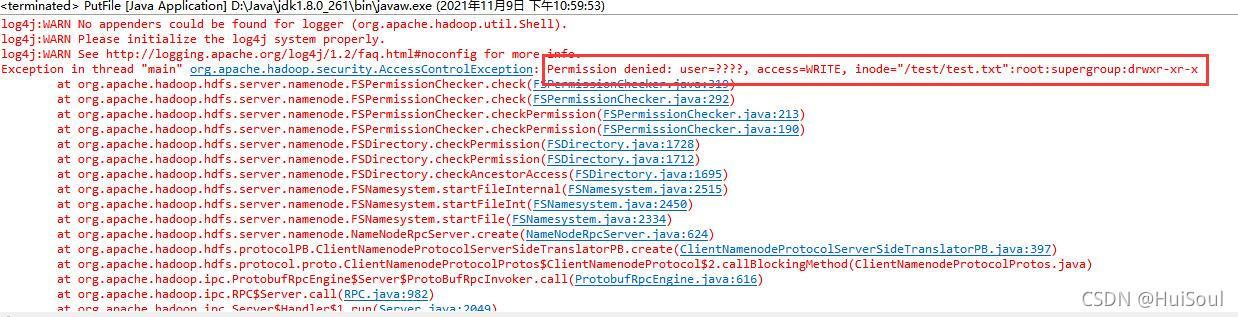
Tips:如果操作會有關于目錄的,別忘了給目錄加上可修改可讀取可執行的權限,如這里就涉及到了/test目錄,命令↓
hadoop fs -chmod 777 /檔案夾名如果沒有添加權限,eclipse報錯如下↓
接著我們運行程式,方法如下↓
后面運行程式也是這么個步驟
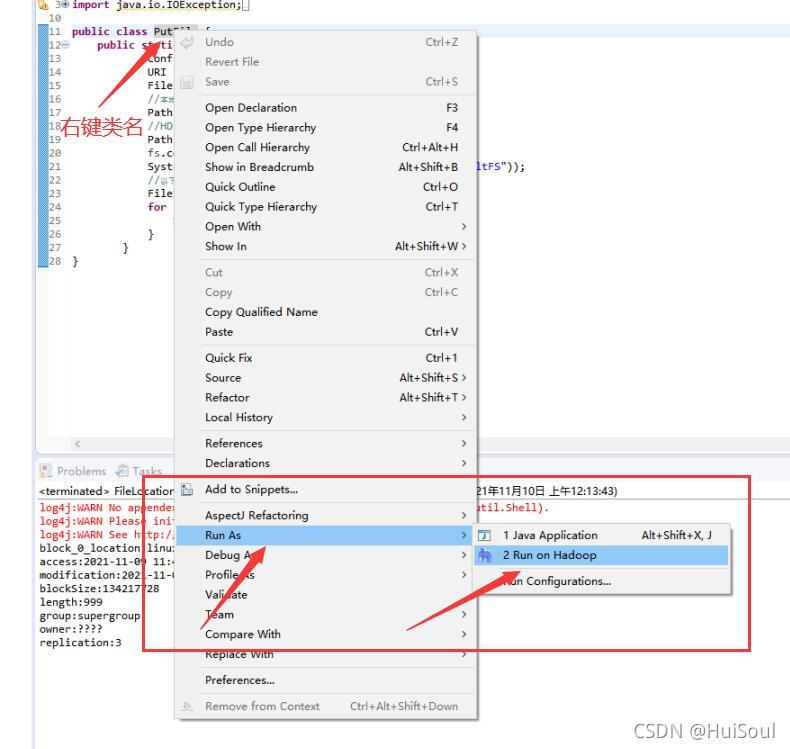
輸出結果↓
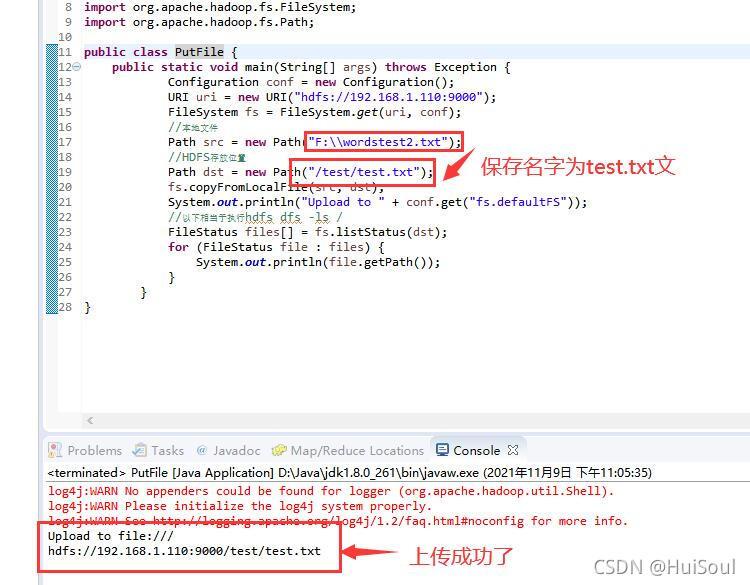
hdfs目錄重繪一下,新增的txt檔案就顯示了
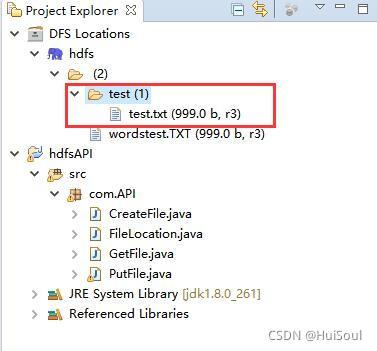
CreateFile.java(創建檔案)↓
package com.API;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
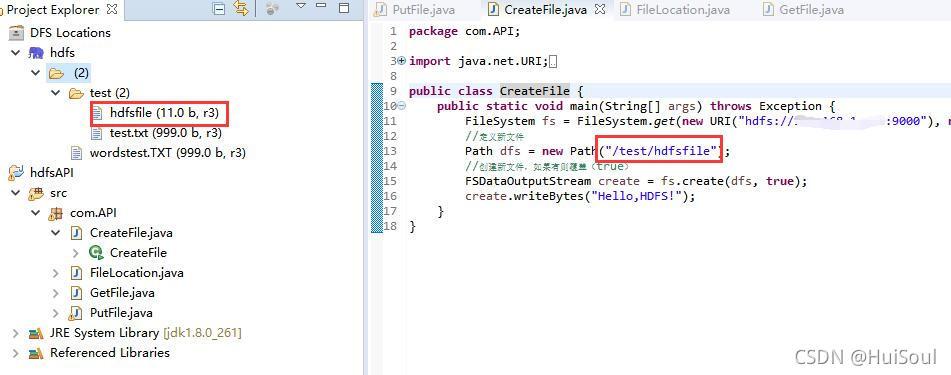
public class CreateFile {
public static void main(String[] args) throws Exception {
FileSystem fs = FileSystem.get(new URI("hdfs://linux主機IP地址:9000"), new Configuration());
//定義新檔案
Path dfs = new Path("/test/hdfsfile");
//創建新檔案,如果有則覆寫(true)
FSDataOutputStream create = fs.create(dfs, true);
create.writeBytes("Hello,HDFS!");
}
}
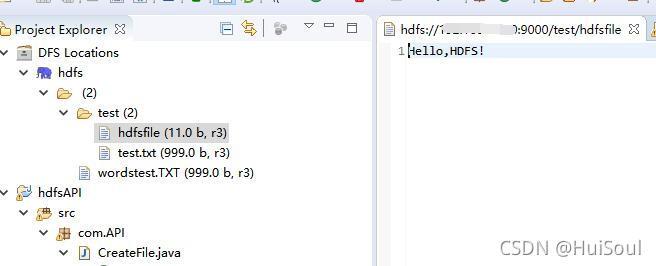
運行程式后左邊hdfs目錄下的test檔案夾中多了一個hdfsfile檔案↓
hdfsfile檔案內容↓
GetFile.java(獲取檔案)↓
package com.API;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class GetFile {
public static void main(String[] args) throws Exception{
FileSystem fs = FileSystem.get(new URI("hdfs://linux主機IP地址:9000"), new Configuration());
//hdfs 上檔案
Path src = new Path("/test/hdfsfile");
//下載到本地的檔案名
Path dst = new Path("D:\\test\\newfile.txt");
fs.copyToLocalFile(false,src,dst,true);
}
}
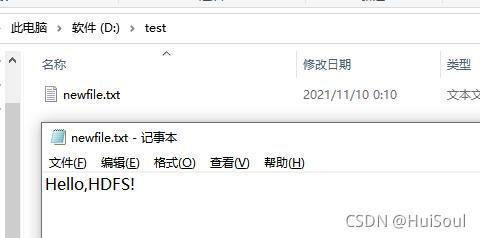
運行程式后會選擇下載到本地路徑的D盤下創建一個test檔案夾,并存放我們索要獲取檔案的副本↓
FileLocation.java(查看檔案路徑)↓
package com.API;
import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileLocation {
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
FileSystem fs = FileSystem.get(new URI("hdfs://linux主機IP地址:9000"), new Configuration());
Path fpath = new Path("/test/test.txt");
FileStatus filestatus = fs.getFileStatus(fpath);
/*獲取檔案在HDFS集群位置:
* FileSystem.getFileBlockLocations(FileStatus file,long start,long
len);
*可查找指定檔案在HDFS集群上的位置,其中file為檔案的完整路徑,start和len來表識查找的檔案路徑
*/
BlockLocation[] blkLocations = fs.getFileBlockLocations(filestatus, 0, filestatus.getLen());
filestatus.getAccessTime();
for (int i = 0; i < blkLocations.length; i++) {
String[] hosts = blkLocations[i].getHosts();
System.out.println("block_" + i + "_location:" + hosts[0]);
}
//格式化日期輸出
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//獲取檔案訪問時間,回傳 long
long accessTime = filestatus.getAccessTime();
System.out.println("access:" + formatter.format(new Date(accessTime)));
//獲取檔案修改時間,回傳long
long modificationTime = filestatus.getModificationTime();
System.out.println("modification:" + formatter.format(new Date(modificationTime)));
//獲取塊的大小,單位為B
long blockSize = filestatus.getBlockSize();
System.out.println("blockSize:" + blockSize);
//獲取檔案大小,單位為B
long len = filestatus.getLen();
System.out.println("length:" + len);
//獲取檔案所在用戶組
String group = filestatus.getGroup();
System.out.println("group:" + group);
//獲取檔案擁有者
String owner = filestatus.getOwner();
System.out.println("owner:" + owner);
//獲取檔案拷貝數
short replication = filestatus.getReplication();
System.out.println("replication:" + replication);
}
}
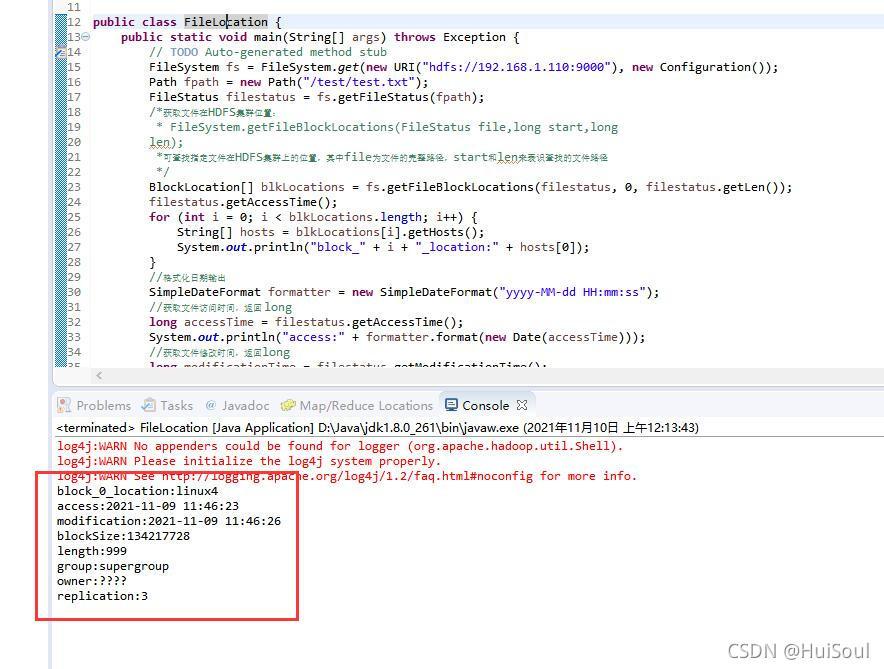
運行程式后,輸出包括訪問時間、修改時間、檔案長度、所占塊大小、檔案擁有者、檔案用戶組和檔案復制數等資訊↓
本次分享到此結束,謝謝大家閱讀!!
歡迎大家看看我下一篇MapReduce——單詞統計:Hadoop——MapReduce實作單詞統計(圖文超詳細版)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355282.html
標籤:其他
上一篇:08-hive中的函式