??本篇博客我要來和大家一起聊一聊資料結構中的樹的基本概念和一些相關名詞,與之前說的資料結構相比,樹是一種非線性的資料結構
??我會主要介紹二叉樹的基本性質和他的順序存盤結構及實作(堆)
??博客代碼已上傳至gitee:https://gitee.com/byte-binxin/data-structure/tree/master/Heap
文章目錄
- 樹的基本概念及結構
- 樹的概念
- 樹的相關概念
- 樹的表示——左孩子右兄弟表示法
- 二叉樹的概念及性質
- 二叉樹的概念
- 特殊的二叉樹
- 二叉樹的性質
- 二叉樹的順序結構及實作
- 二叉樹的順序結構
- 堆的概念及結構
- 堆的實作
- 堆的結構定義
- 堆的初始化
- 向下調整演算法
- 向上調整演算法
- 堆的創建
- 堆的插入
- 堆的洗掉
- 堆頂資料
- 堆的元素個數
- 判斷堆是否為空
- 堆的銷毀
- 建堆的時間復雜度
- 總結
樹的基本概念及結構
樹的概念
樹(tree)是包含 n(n≥0) [2] 個節點,當 n=0 時,稱為空樹,非空樹中條邊的有窮集,在非空樹中:
(1)每個元素稱為節點(node),
(2)有一個特定的節點被稱為根節點或樹根(root),
(3)除根節點之外的其余資料元素被分為個互不相交的集合,其中每一個集合本身也是一棵樹,被稱作原樹的子樹(subtree)(來源:百度百科)
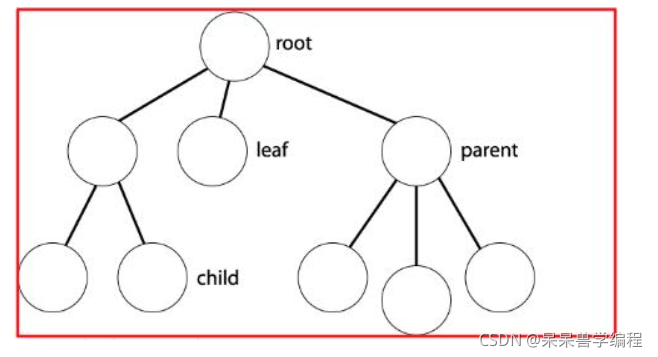
注意:樹形結構中,子樹之間不能有交集,否則就不是樹形結構
樹的相關概念
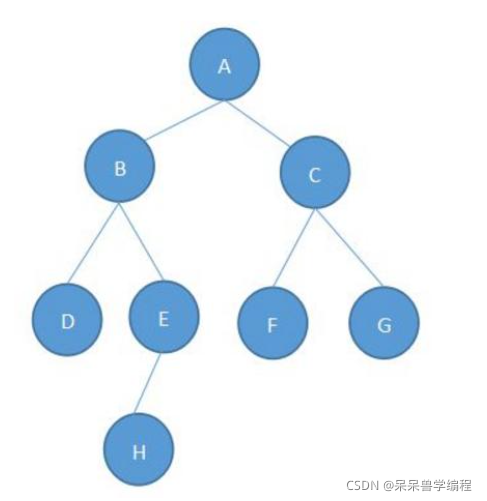
節點的度:一個節點含有的子樹的個數稱為該節點的度; 如上圖:A的為2
葉節點或終端節點:度為0的節點稱為葉節點; 如上圖:D、F、G、H為葉節點
非終端節點或分支節點:度不為0的節點; 如上圖:A、B…等節點為分支節點
雙親節點或父節點:若一個節點含有子節點,則這個節點稱為其子節點的父節點; 如上圖:A是B的父節點
孩子節點或子節點:一個節點含有的子樹的根節點稱為該節點的子節點; 如上圖:B是A的孩子節點
兄弟節點:具有相同父節點的節點互稱為兄弟節點; 如上圖:B、C是兄弟節點
樹的度:一棵樹中,最大的節點的度稱為樹的度; 如上圖:樹的度為2
節點的層次:從根開始定義起,根為第1層,根的子節點為第2層,以此類推;
樹的高度或深度:樹中節點的最大層次; 如上圖:樹的高度為4(根節點的高度記為1)
堂兄弟節點:雙親在同一層的節點互為堂兄弟;如上圖:H、I互為兄弟節點
節點的祖先:從根到該節點所經分支上的所有節點;如上圖:A是所有節點的祖先
子孫:以某節點為根的子樹中任一節點都稱為該節點的子孫,如上圖:所有節點都是A的子孫
森林:由m(m>0)棵互不相交的樹的集合稱為森林
樹的表示——左孩子右兄弟表示法
樹的表示方法有很多,由于樹不是一種線性的結構,所以表示起來會顯得有些復雜,最常用的就是左孩子右兄弟表示法,
左孩子右兄弟表示法是節點中保存第一個孩子的節點的指標,還有一個指標指向下一個兄弟節點,
typedef int DataType;
struct Node
{
struct Node* firstChild; // 第一個孩子結點
struct Node* pNextBrother; // 指向其下一個兄弟結點
DataType data; // 結點中的資料域
}
這樣一種表示方法是十分的精妙,可以很好地遍歷到每一個節點,
二叉樹的概念及性質
二叉樹的概念
二叉樹是n個有限元素的集合,該集合或者為空、或者由一個稱為根(root)的元素及兩個不相交的、被分別稱為左子樹和右子樹的二叉樹組成,是有序樹,當集合為空時,稱該二叉樹為空二叉樹,在二叉樹中,一個元素也稱作一個結點,
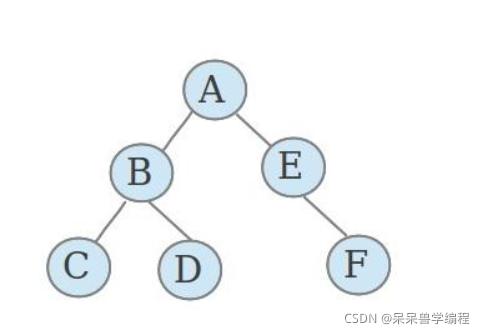
注意
- 二叉樹的度不超過2
- 二叉樹的子樹有左右之分,次序不能顛倒,因此二叉樹是有序樹
特殊的二叉樹
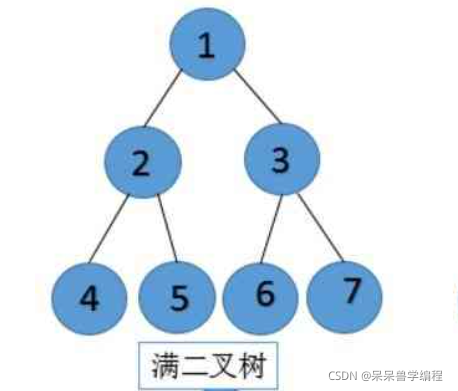
滿二叉樹:一個二叉樹,如果每一個層的結點數都達到最大值,則這個二叉樹就是滿二叉樹,也就是說,如果一個二叉樹的層數為K,且結點總數是(2^k) -1 ,則它就是滿二叉樹,
完全二叉樹:一棵深度為k的有n個結點的二叉樹,對樹中的結點按從上至下、從左到右的順序進行編號,如果編號為i(1≤i≤n)的結點與滿二叉樹中編號為i的結點在二叉樹中的位置相同,則這棵二叉樹稱為完全二叉樹,
二叉樹的性質
-
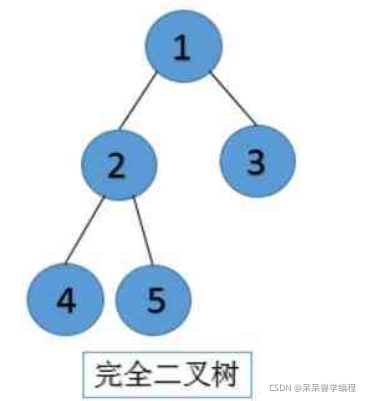
若規定根節點的層數為1,則一棵非空二叉樹的第n層上最多有**2^(n-1)**個結點
-
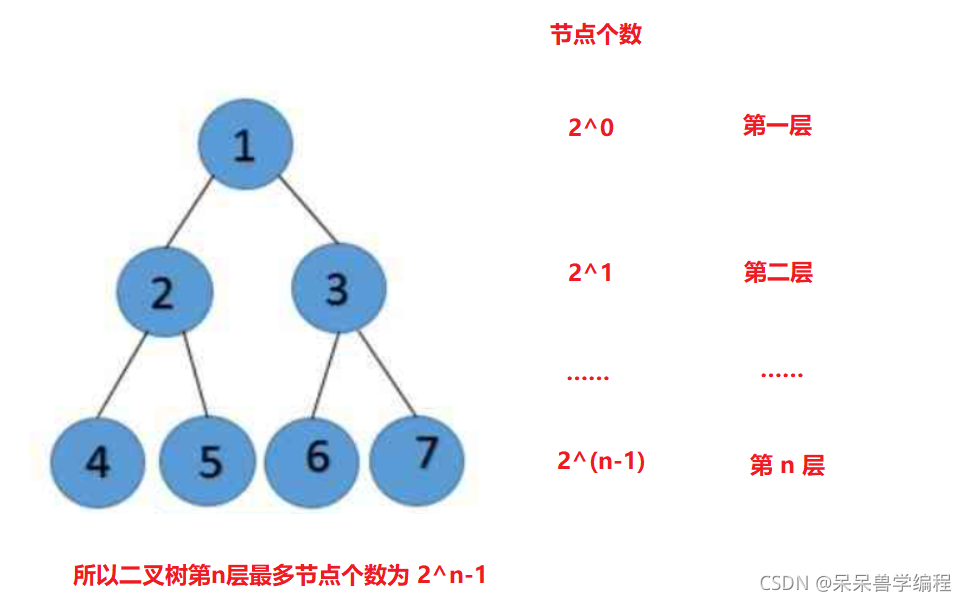
若規定根節點的層數為1,則深度為n的二叉樹的最大結點數是2^n-1
-
對任何一棵二叉樹, 如果度為0其葉結點個數為 , 度為2的分支結點個數為 ,則有n0 = n2+1,

- 樹中父節點與子節點的關系:
- leftChild = parent*2+1
- rightChild = parent*2+1
- parent = (child-1)/2
二叉樹的順序結構及實作
二叉樹的順序結構
普通的二叉樹是不適合用陣列來存盤的,因為可能會存在大量的空間浪費,而完全二叉樹更適合使用順序結構存盤,
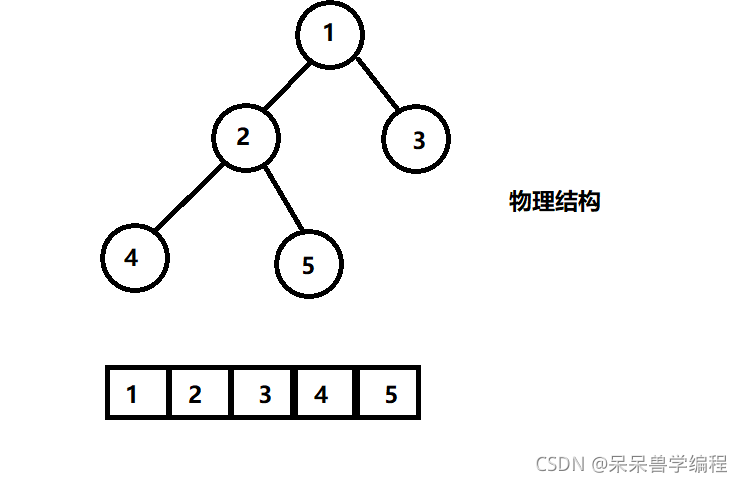
可以看出,只有完全二叉樹可以很充分地利用空間,普通二叉樹會浪費很大的空間,
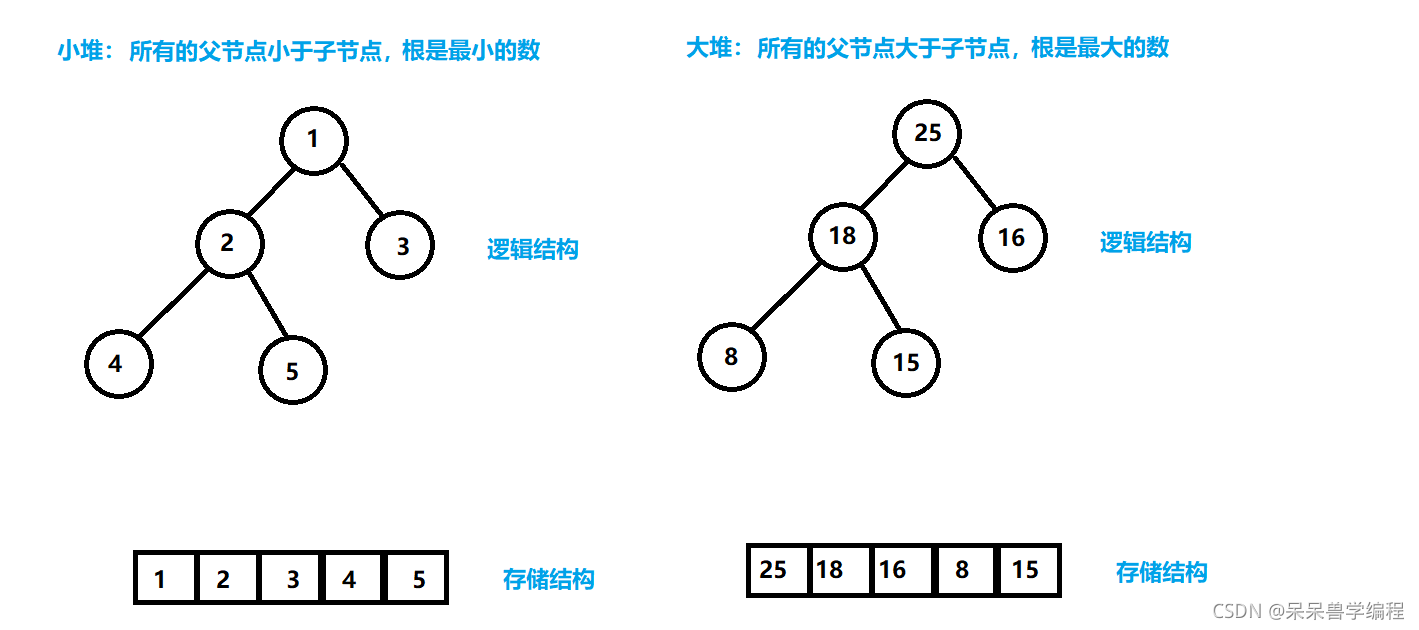
堆的概念及結構
n個元素的序列{k1,k2,ki,…,kn}當且僅當滿足下關系時,稱之為堆,
Ki<=K2i且Ki<=K2i+1 或 Ki>=K2i且Ki>=K2i+1
堆的性質:
- 堆中某個結點的值總是不大于或不小于其父結點的值;
- 堆總是一棵完全二叉樹,
堆的實作
堆的結構定義
由于堆是用陣列來進行存盤的,所以這里的結構和順序表有些類似,邏輯上是堆,物理上是一種陣列的形式,
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int capacity;
int size;
}HP;
堆的初始化
堆的初始化和順序表的很相似基本上什么都不用做,只要指標置空,大小和容量置0即可,
void HeapInit(HP* hp)
{
assert(hp);
hp->a = NULL;
hp->capacity = hp->size = 0;
}
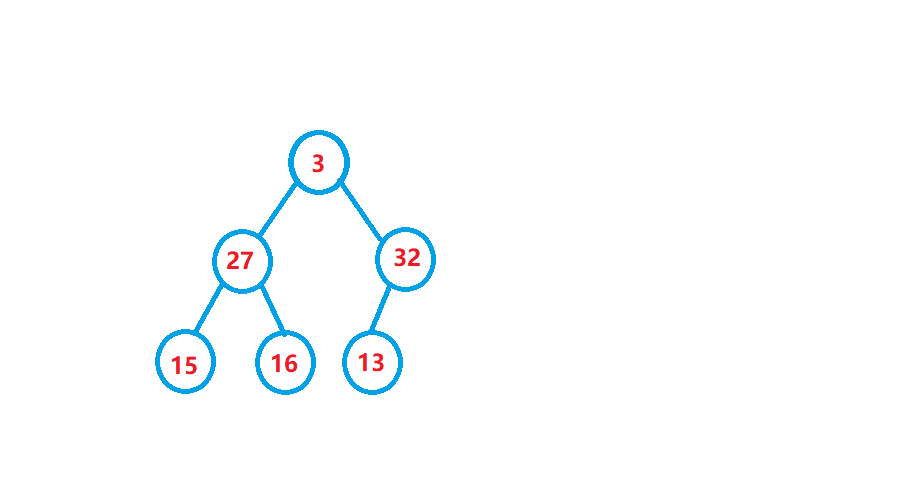
向下調整演算法
從根節點開始的向下調整演算法可以把它調整成一個小堆,向下調整演算法有一個前提:左右子樹必須是一個堆,才能調整,
先看動圖演示:
代碼實作如下:
void AdjustDown(HPDataType* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
//選小孩子
if (child + 1 < n && a[child + 1] < a[child])//< 建小堆 > 建大堆
{
child++;
}
if (a[child] < a[parent])//< 建小堆 > 建大堆
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
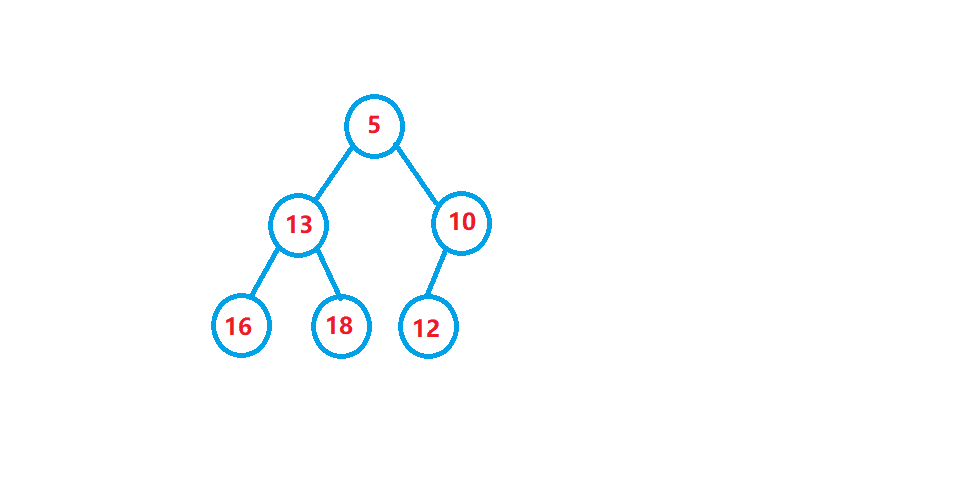
向上調整演算法
向上調整演算法就是在插入一個節點后為了使堆依舊保持原來的大堆或者小堆的一個調整演算法,先將該節點與父親節點比較,如果比父親節點大就交換(原本是大堆)否則就不交換,直到交換到根節點為止,
看一個動圖演示:
代碼實作如下:
void AdjustUp(HPDataType* a, int child)
{
assert(a);
int parent = (child - 1) / 2;
while (child >= 0)
{
if (a[child] < a[parent])//< 建小堆 > 建大堆
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
堆的創建
對于給定的一個陣列,我們如何把他構建成大堆或者小堆呢?
堆的構建有兩種方法:
第一種:從第二個節點往后開始向上調整
第二種:從最后一個非葉子節點開始向下調整
第一種代碼實作:
void HeapCreate(HP* hp, int n)
{
assert(hp);
int i = 0;
//建小堆 排降序 建大堆 排升序
for (i = 1; i < n; i++)
{
//建大堆 向下調整
AdjustUp(hp->a, i);
}
}
第二種代碼實作:
void HeapCreate(HP* hp, int n)
{
assert(hp);
//找到最后一個父親節點
int parent = (n - 1 - 1) / 2;
int i = 0;
//建小堆 排降序 建大堆 排升序
for (i = parent; i >= 0; i--)
{
//建大堆 向下調整
AdjustDown(hp->a, n, i);
}
}
堆的插入
堆的插入和順序表的尾插有些相似,要考慮擴容的問題,有一點不同的是堆在插入后要進行向上調整,也就是向上調整演算法,保持原來的堆的性狀,
代碼實作如下:
void HeapPush(HP* hp, HPDataType x)
{
assert(hp);
if (hp->capacity == hp->size)
{
int newCapacity = hp->capacity == 0 ? 4 : 2 * hp->capacity;
HPDataType* tmp = (HPDataType*)realloc(hp->a, newCapacity * sizeof(HPDataType));
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
hp->a = tmp;
hp->capacity = newCapacity;
}
hp->size++;
hp->a[hp->size - 1] = x;
//向上調整
AdjustUp(hp->a, hp->size - 1);
}
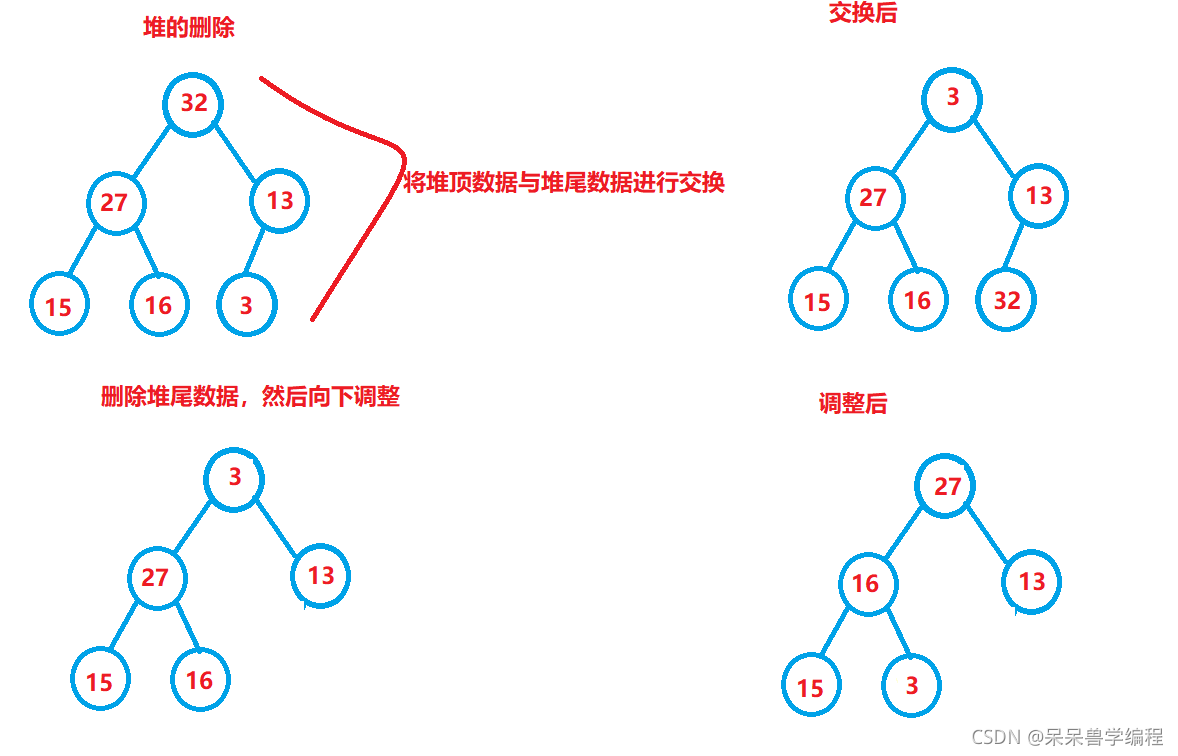
堆的洗掉
我們規定,堆的洗掉在頭部進行,所以堆的洗掉也和順序表的頭刪有些相似,要對大小進行斷言,確保堆的大小不為0,但是堆不能直接在頭部進行洗掉,這樣會破壞堆的結構,又要重新建堆的時間復雜度是O(n)(后面會證明),這樣就顯得很麻煩,
于是就有新的一種方法,把堆頂的資料和堆尾的資料先進行交換,然后再把堆尾的資料洗掉,這樣堆的結構就沒有完全破壞,因為堆頂的左子樹和右子樹都是大堆,我們可以進行向下調整就可以恢復堆的形狀了,向下調整演算法的時間復雜度是堆的高度次,即O(log(h+1)),顯然,下面這種演算法更優,
代碼實作如下:
void HeapPop(HP* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
//把最后一個數替換堆頂的數,然后再進行向下調整
Swap(&hp->a[0], &hp->a[hp->size - 1]);
hp->size--;
//向下調整
AdjustDown(hp->a, hp->size, 0);
}
堆頂資料
直接回傳第一個資料即可,但要確保堆不為空,
代碼實作如下:
HPDataType HeapTop(HP* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
return hp->a[0];
}
堆的元素個數
直接回傳size的大小即可,
代碼實作如下:
int HeapSize(HP* hp)
{
assert(hp);
return hp->size;
}
判斷堆是否為空
利用邏輯運算式hp->size == 0進行判斷,然后回傳其值即可,
代碼實作如下:
int HeapEmpty(HP* hp)
{
assert(hp);
return hp->size == 0;
}
堆的銷毀
堆的銷毀就是對動態申請的空間進行釋放,防止記憶體泄漏,其實和順序表的銷毀很相似,
代碼實作如下:
void HeapDestory(HP* hp)
{
assert(hp);
free(hp->a);
hp->a = NULL;
hp->capacity = hp->size = 0;
}
建堆的時間復雜度
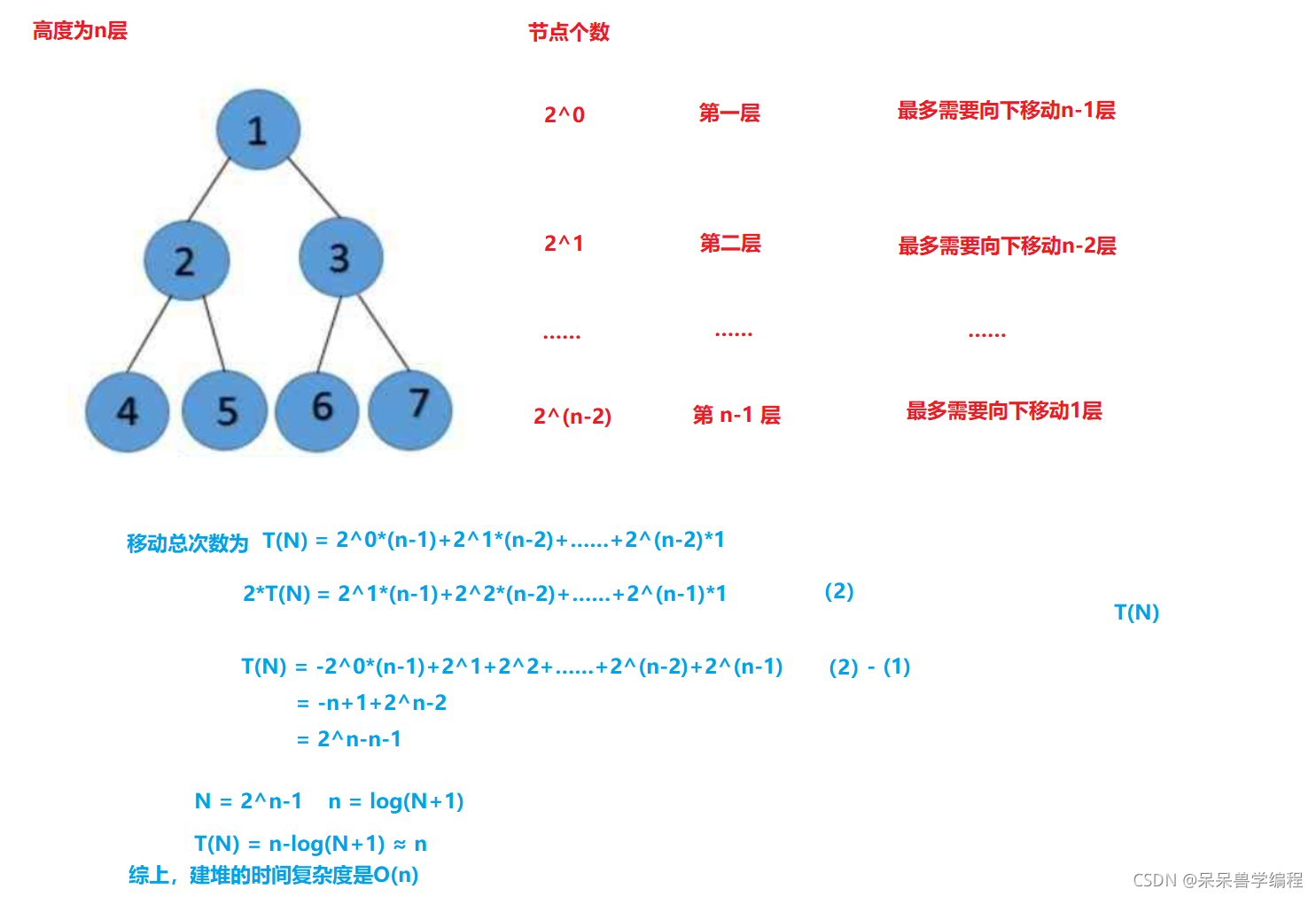
總結
本篇博客就先到這里就結束了,下一篇博客我會跟大家聊一聊有關堆的順序結構的應用的問題,堆排序和Top-K問題,喜歡的話,歡迎大家點贊支持和指正~

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355330.html
標籤:其他
上一篇:帶你深入理解 歸并排序
下一篇:C語言基礎題...持續更新