行人檢測 概述:
行人檢測主要有兩種:傳統檢測演算法和基于深度學習檢測演算法,傳統檢測演算法的典型代表有Haar演算法+Adaboost演算法,Hog特征+SVM演算法,DPM演算法,而基于深度學習的行人檢測典型代表有RCNN系列,SDD系列,YOLO系列,
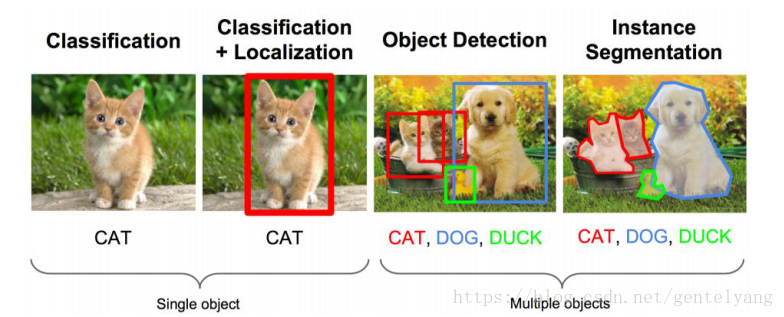
上圖是單目標檢測和多目標檢測的例子,單目標相對容易實作一些,但是多目標很容易出現遺漏,現在比較新的mask rcnn可以實作目標檢測和語意分割,相比FCN來說取得了更好的進步,
簡單對比:
RCN (Selective Search + CNN + SVM)
SPP-Net(Spatial Pyramid Pooling)
Fast R-CNN(Selective Search + CNN + ROI pooling)
Faster R-CNN(CNN + RPN + ROI pooling)
R-FCN
RCNN原理
論文:Rich feature hierarchies for accurate object detection and semantic segmentation
RCNN(Region with CNN feature)是卷積神經網路應用于目標檢測問題的一個里程碑的飛躍,CNN具有良好的特征提取和分類性能,采用RegionProposal方法實作目標檢測問題,演算法可以分為三步(1)候選區域選擇,(2)CNN特征提取,(3)分類與邊界回歸,
RCNN演算法流程:
- 一張影像生成1k~2k個候選區域(使用Selective Search)
- 對每個候選區域,使用深度網路提取特征
- 特征送入每一類的SVM分類器,判別是否屬于該類
- 使用回歸器精細修正候選框位置
(1)候選區域選擇:區域建議Region Proposal是一種傳統的區域提取方法,基于啟發式的區域提取方法,用的方法是ss(selective research),查看現有的小區域,合并兩個最有可能的區域,重復此步驟,直到影像合并為一個區域,最后輸出候選區域,然后將根據建議提取的目標影像標準化,作為CNN的標準輸入可以看作視窗通過滑動獲得潛在的目標影像,在RCNN中一般Candidate選項為1k-2k個即可,即可理解為將圖片劃分成1k~2k個網格,之后再對網格進行特征提取或卷積操作,這根據RCNN類演算法下的分支來決定,然后基于就建議提取的目標影像將其標準化為CNN的標準輸入,
(2)CNN特征提取:標準卷積神經網路根據輸入執行諸如卷積或池化的操作以獲得固定維度輸出,也就是說,在特征提取之后,特征映射被卷積和匯集以獲得輸出,比如有VGG,ZF等,
(3)分類與邊界回歸:實際上有兩個子步驟,一個是對前一步的輸出向量進行分類(分類器需要根據特征進行訓練); 第二種是通過邊界回歸框回歸(縮寫為bbox)獲得精確的區域資訊,其目的是準確定位和合并完成分類的預期目標,并避免多重檢測,在分類器的選擇中有支持向量機SVM,Softmax等等(文中選擇SVM,附錄給出了解釋原因,但是目前多數還是以Softmax);邊界回歸有bbox回歸,多任務損失函式邊框回歸等 (文中使用帶正則化的交叉熵損失函式),
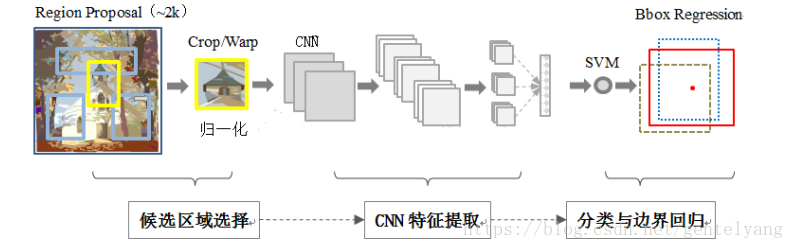
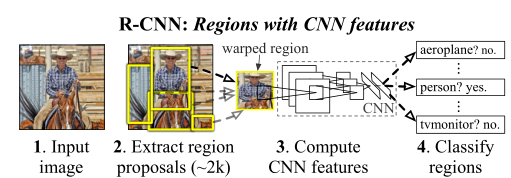

RCNN的缺點:
在RCNN剛剛被發明出來的2014年,RCNN在目標檢測與行人檢測上取得了巨大的成就,然而效率低下,花費時間長等一系列的問題的產生,還是導致了RCNN的運用并沒有取得大范圍的應用,其最大的問題有三:需要事先提取多個候選區域對應的影像,這一行為會占用大量的磁盤空間;針對傳統的CNN來說,輸入的map需要時固定尺寸的,而歸一化程序中對圖片產生的形變會導致圖片大小改變,這對CNN的特征提取有致命的壞處;每個region proposal都需要進入CNN網路計算,進而會導致過多次的重復的相同的特征提取,這一舉動會導致大大的計算浪費,在這之后,隨之而來的Fast RCNN逐漸進入了人們的眼簾,
改進RCNN:
- 提取候選框:Edge Boxes、RPN網路
- 共享卷積運算:SPPNet、Fast RCNN
- 兼容任意尺寸影像:SPP,ROI Pooling
- 預設長寬比:Anchor
- 網路結構:端對端
- 融合各層特征:FPN
Fast RCNN
Fast RCNN較之前的RCNN相比,有四個方面得到了提升:
- 測驗時的速度得到了提升,RCNN演算法與影像內的大量候選幀重疊,導致提取特征操作中的大量冗余,而Fast RCNN則很好的解決了這一問題(先提取輸入影像的特征向量,候選區域直接映射減少了重復提取相同的特征),
- 訓練時的速度得到了提升,
- 訓練所需的空間大,RCNN中分類器和回歸器需要大量特征作為訓練樣本,而Fast RCNN則不再需要額外儲存,
- 實作了單階段多任務損失函式,即端到端的訓練,
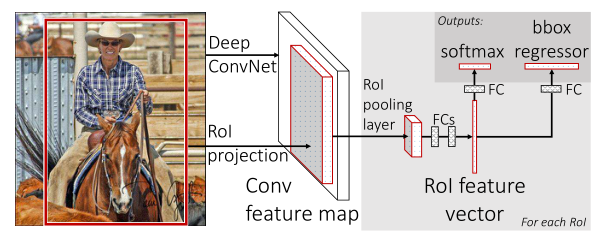

ROI pooling詳解
ROI pooling與SPPNet互聯關系
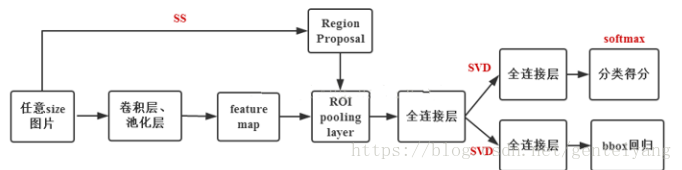
Fast RCNN的作業流程:
1.選擇性搜索Selective Search(SS)在圖片中獲得大約2k個候選框,
在第一步中所使用到的候選區域生成方法與RCNN無異,使用的方法都是Selective Search(SS),以此方式來生成2k個候選框,其基本思路如下所述:使用過分割方法將影像分成小區域,在此之后,觀察現有的區域,之后以最高概率合并這兩個區域,重復此步驟,直到所有影像合并為一個區域位置,注意,在此處的合并規則與RCNN是相同的,優先合并以下四種區域: ==顏色(顏色直方圖)相近的; 紋理(梯度直方圖)==相近的; 合并后總面積小的,最后,所有已經存在的區域都被輸出,并生成候選區域,
2.使用卷積網路提取圖片特征,類似于RCNN,在獲取特征映射之后,需要卷積神經網路來進行卷積操作, 在此處Fast RCNN使用的卷積神經網路為普通的fc7,但是有所改動,也有使用VGG16的神經網路, 前五個階段是conv + relu + pooling的基本形式,
3.在第二步進行的卷積操作過后可以得到feature map,根據之前RoI框選擇出對應的區域(可以理解為將feature map映射回原影像), 在最后一次卷積之前,使用 RoI池層來統一相同的比例(這里利用的是單層ssp),
在RCNN中,在進行卷積操作之前一般都是先將圖片分割與形變到固定尺寸,這也正是RCNN的劣勢之處,不得不說,這對檢測來說是十分不應該出現的,這會讓影像產生形變,或者影像變得過小,使一些特征產生了損失,繼而對之后的特征選擇產生巨大影響,Fast RCNN與RCNN不同,其不同之處如下:Fast RCNN在資料的輸入上并不對其有什么限制,而實作這一沒有限制的關鍵所在正是ROI Pooling層,該層的作用是可以在任何大小的特征映射上為每個輸入ROI區域提取固定的維度特征表示,然后確保每個區域的后續分類可以正常執行,
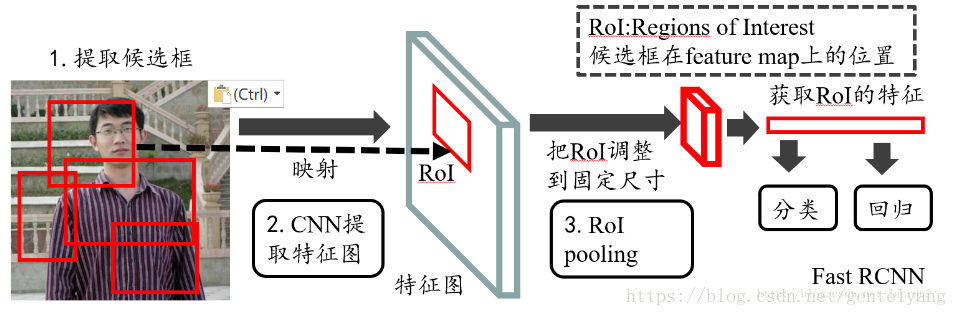
Faster R-CNN (RPN+Fast R-CNN)
從RCNN到Fast RCNN,再到Faster RCNN,一直都有效率上的提升 ,而對于Faster RCNN來講,與RCNN和Fast RCNN最大的區別就是,目標檢測所需要的四個步驟,即候選區域生成,特征提取,分類器分類,回歸器回歸,這四步全都交給深度神經網路來做,并且全部運行在 GPU上,這大大提高了操作的效率,
Faster RCNN可以說是由兩個模塊組成的:區域生成網路RPN候選框提取模塊+Fast RCNN檢測模塊
RPN是全卷積神經網路,其內部與普通卷積神經網路不同之處在于是將CNN中的全連接層變成卷積層,Faster RCNN是基于RPN提取的proposal檢測并識別proposal中的目標,其具體流程大致可概括為:
1.輸入影像,
2.通過區域生成網路RPN生成候選區域,
3.提取特征,
4.分類器分類,
5.回歸器回歸并進行位置調整,
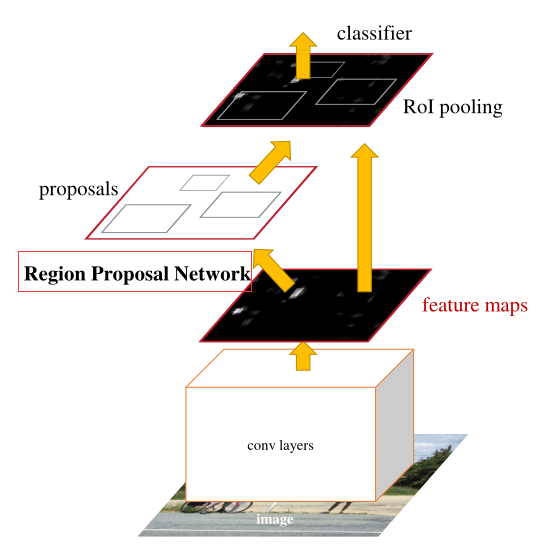
詳細講解:
1.Conv layers,作為一種CNN網路目標檢測方法,Faster RCNN首先使用一組基礎的conv+relu+pooling層提取image的feature maps,該feature maps被共享用于后續RPN層和全連接層,
2.Region Proposal Networks,RPN網路用于生成region proposals,該層通過softmax判斷anchors屬于positive或者negative,再利用bounding box regression修正anchors獲得精確的proposals,
3.RoI Pooling,該層收集輸入的feature maps和proposals,綜合這些資訊后提取proposal feature maps,送入后續全連接層判定目標類別,
4.Classification,利用proposal feature maps計算proposal的類別,同時再次bounding box regression獲得檢測框最終的精確位置,
借助大佬的影像進一步細節分析:
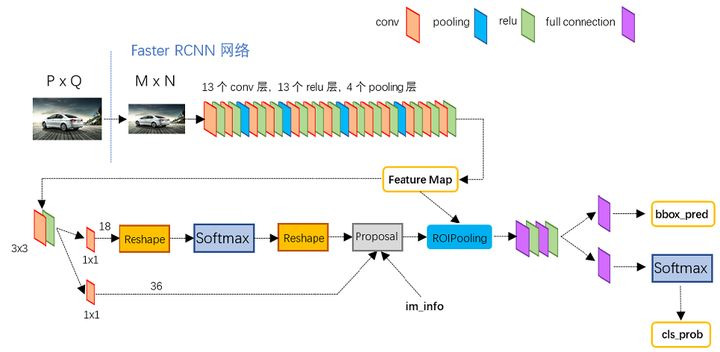
- 首先縮放至固定大小MxN,然后將MxN影像送入網路;
- 而Conv layers中包含了13個conv層+13個relu層+4個pooling層;
- RPN網路首先經過3x3卷積,再分別生成positive anchors和對應bounding box regression偏移量,然后計算出proposals;
- 而Roi Pooling層則利用proposals從feature maps中提取proposal feature送入后續全連接和softmax網路作classification(即分類proposal到底是什么object),
區域代網路RPN的核心思想是直接使用卷積神經網路CNN生成候選區域region proposal區域提議,本節主要來對RPN的具體流程進行講解,RPN使用的方法實際上是在最后一個卷積層上滑動視窗,
RPN的具體操作流程如下:使用小型網路在最后的卷積特征地圖feature map上執行滑動掃描,每當滑動網路完全連接到特征地圖上的 n* n視窗,然后將其映射到低維矢量,最后將這個低維矢量發送到兩個完全連接的層,即 bbox回歸層( reg)和 box分類層( cls), 滑動視窗處理確保reg層和cls層與conv5-3的整個特征空間相關聯,在其中,reg層的作用是預測proposal的anchor對應的proposal的(x,y,w,h),cls層的作用是判斷該proposal是前景(object)還是背景(non-object)(注:這里作者使用的是多分類交叉熵損失函式,因為是2k Scores,如果是二分類交叉熵損失函式,則 應該結果為k Score),詳解區分
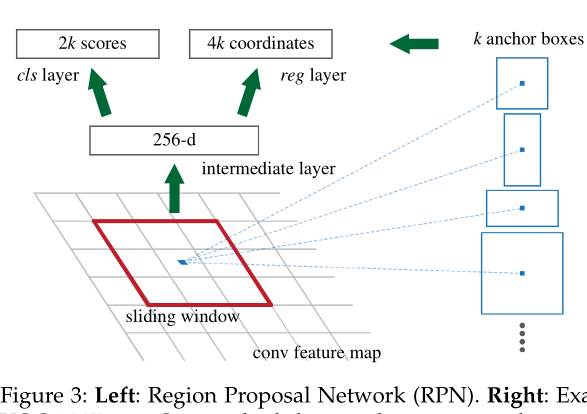
在候選區域(錨點anchor)部分,該特征可以被視為大小為51 * 39的256通道影像:三種面積{128128,256256,512512}×三種比例{1:1,1:2,2:1},這些候選視窗稱為anchors即錨點,下圖示出5139個anchor中心,以及3x3 = 9種anchor示例,

在RPN中,reg與cls層分別是進行了視窗分類與位置精修,分類層(cls_score)輸出9個錨點屬于每個位置的前景和背景的概率,在每個位置的bbox_pred輸出中,9個錨點對應點應該是泛化的(x,y,w,h),對于每個位置來說,分類層從256維特征輸出屬于前景和背景的概率,而回歸圖層則是從256維特征中輸出4個平移和縮放引數,
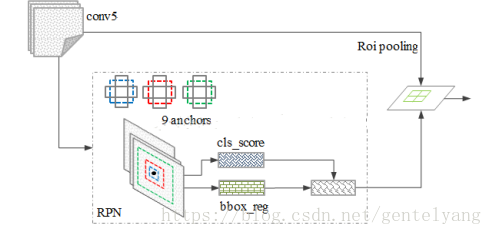

Faster RCNN演算法流程可分為3個步驟
- 將影像輸入網路得到相應的特征圖
- 使用RPN結構生成候選框,將RPN生成的候選框投影到特征圖上獲得相應的特征矩陣
- 將每個特征矩陣通過ROI pooling層縮放到7x7大小的特征圖,接著將特征圖戰平通過一些列全連接層得到預測結果
注:
目前,是直接采用RPN Loss + Fast R-CNN Loss的聯合訓練方法訓練Faster RCNN的
原論文中采用分別訓練RPN及Fast R-CNN的方法
(1) 利用ImageNet預訓練分類模型初始化前置卷積網路層引數,并開始單獨訓練RPN網路引數;
(2) 固定RPN網路獨有的卷積層以及全連接層引數,再利用
lmageNet預訓練分類模型初始化前置卷積網路引數,并利用RPN網路生成的目標建議框去訓練Fast RCNN網路引數,
(3) 固定利用Fast RCNN訓練好的前置卷積網路層引數,去微調RPN網路獨有的卷積層以及全連接層引數,
(4) 同樣保持固定前置卷積網路層引數,去微調Fast RCNN網路的全連接層引數,最后RPN網路與Fast RCNN網路共享前置卷積網路層引數,構成一個統一網路,
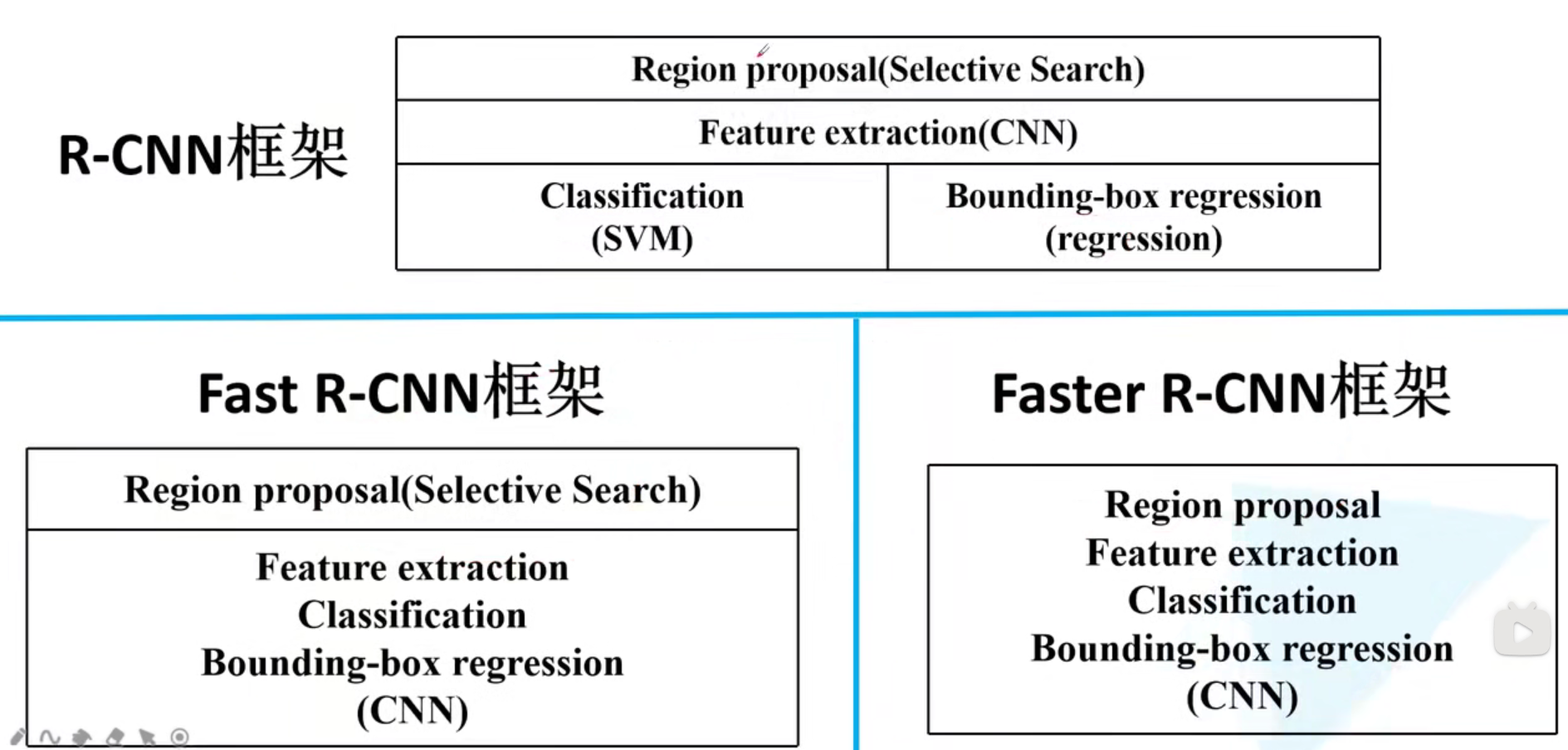
最后,給出一張三張網路的結構對比圖,可以看到從各個模塊的分散到集中,實作端到端,并且在空間和時間效率上都得到了很大的提升,
參考鏈接:https://blog.csdn.net/gentelyang/article/details/80469553
參考鏈接:https://zhuanlan.zhihu.com/p/31426458
B站:https://www.bilibili.com/video/BV1af4y1m7iL?from=search&seid=10038516019441925384&spm_id_from=333.337.0.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355424.html
標籤:其他
上一篇:【影像融合】基于matlab GUI高斯金字塔+拉普拉斯金字塔彩色影像融合【含Matlab原始碼 1506期】
下一篇:python 如何安裝cv2庫