2021SC@SDUSC
本篇我將對hadoop-tools中的Gridmix進行分析
GridMix
概念
GridMix是Hadoop集群的基準,它提交多種合成作業,對從生產負載中挖掘的概要進行建模,
基本使用
Gridmix作為hadoop子命令提供,不帶配置引數的基本命令列用法:
$ hadoop gridmix [-generate <size>] [-users <users-list>] <iopath> <trace>配置引數的基本命令列用法:
$ hadoop gridmix \
-Dgridmix.client.submit.threads=10 -Dgridmix.output.directory=foo \
[-generate <size>] [-users <users-list>] <iopath> <trace>這 <iopath>路徑是GridMix的作業目錄,需要注意的是,這可以在本地檔案系統上,也可以在HDFS上,但大多數情況下它都與原始作業組合相同,以便GridMix分別在本地檔案系統和HDFS上加載相同的負載,
這 -generate選項用于為合成作業生成輸入資料和分布式快取檔案,它接受大小后綴的標準單位,例如100克將生成100 * 230次方位元組作為輸入資料,壓縮格式輸入資料的最小大小(默認為128兆位元組)由下式定義gridmix.min.file.size,<iopath>/input是生成的輸入資料的目標目錄和/或從中讀取輸入資料的目錄,基于HDFS的分布式快取檔案是在分布式快取目錄下生成的 <iopath>/distributedCache. 分布式快取,如果分布式快取目錄中已經存在一些所需的分布式快取檔案,則在以下情況下,僅生成剩余的不存在的分布式快取檔案-生成選項已指定,
這<trace>引數是由Rumen生成的作業跟蹤的路徑,此跟蹤可以壓縮(必須使用群集支持的壓縮編解碼器之一可讀)或解壓縮,如果要傳遞一個未壓縮的通過GridMix的標準輸入流進行跟蹤,
常見引數配置

作業型別
GridMix將作業跟蹤作為輸入,本質上是一個JSON編碼的作業描述流,對于每個作業描述,提交客戶端獲取原始作業提交時間,對于該作業中的每個任務,讀取和寫入的位元組和記錄計數,給定這些資料,它構建一個合成作業,其位元組和記錄模式與跟蹤中記錄的相同,它構建兩種型別的作業:


Job Submission Policies
GridMix控制作業提交的速率,該控制元件可以基于跟蹤資訊,也可以基于它從ResourceManager收集的統計資訊,根據用戶定義的提交策略,GridMix使用相應的演算法來控制作業提交,目前有三種型別的策略:
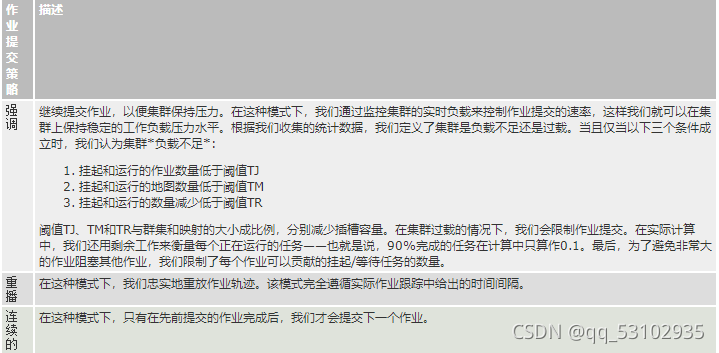
 Emulating Users and Queues
Emulating Users and Queues
典型的生產集群通常由不同的用戶共享,集群容量通過作業佇列在不同的部門之間分配,確保來自所有用戶的作業之間的公平性、遵守佇列容量分配策略以及避免不良作業接管集群增加了Hadoop軟體的復雜性,為了能夠充分測驗和發現這些領域的缺陷,GridMix必須模擬來自不同用戶和/或提交到不同佇列的作業的爭用,
模擬多個佇列很容易-我們只需用與生產集群相同的佇列配置設定基準集群,然后配置合成作業,使它們提交到跟蹤中記錄的相同佇列,但是,并非跟蹤中顯示的所有用戶在基準集群中都有帳戶,相反,我們設定了許多測驗用戶帳戶,并以回圈方式將跟蹤中的每個唯一用戶與測驗用戶相關聯,
以下配置引數會影響用戶和佇列的模擬:

模擬分布式快取加載
默認情況下,Gridmix為LOADJOB型別的作業模擬分布式快取加載,這是通過為所有模擬作業預創建所需的分布式快取檔案來完成的,這些檔案是單獨的MapReduce作業的一部分,
通過配置屬性,可以禁用gridmix模擬作業中分布式快取加載的模擬grid mix . distributed-cache-仿真. enable到錯誤的,但是gridmix生成分布式快取資料的驅動力是-生成選項,并且獨立于此配置屬性,
如果出現以下情況,分布式快取檔案的生成和分布式快取負載的模擬都將被禁用:
- 輸入跟蹤來自標準輸入流,而不是檔案,或者
- <iopath>指定在本地檔案系統上,或者
- 分布式高速快取目錄的任何上升目錄, i.e. <iopath>/distributedCache分布式快取(包括分布式快取目錄)對其他人沒有執行權限,
模擬作業的配置
Gridmix3在它提交的模擬作業中設定一些配置屬性,以便它們可以映射回輸入作業跟蹤中的相應作業,這些配置引數包括:
| 引數 | 描述 |
|---|---|
| gridmix.job.original-job-id | 對應于此模擬作業的原始群集作業的作業id, |
| gridmix.job.original-job-name | 對應于此模擬作業的原始群集作業的作業名稱, |
模擬壓縮/解壓縮
MapReduce支持資料壓縮和解壓縮,可以壓縮對MapReduce作業的輸入,同樣,地圖和縮小任務的輸出也可以壓縮,GridMix中的壓縮/解壓縮仿真很重要,因為仿真壓縮/解壓碩訓影響任務的CPU和記憶體使用,模擬壓縮/解壓縮的任務將影響同一節點上運行的其他任務和守護程式,
壓縮仿真在以下情況下啟用grid mix . compression-仿真. enable設定為真實的,默認情況下,壓縮仿真對以下型別的作業啟用LOADJOB,啟用壓縮模擬后,GridMix現在將生成具有恒定壓縮比的壓縮文本資料,因此,模擬的GridMix作業現在將使用可壓縮文本資料(具有恒定的壓縮比)來模擬壓縮/解壓縮,而不考慮實際作業中觀察到的壓縮比,
典型的MapReduce作業在以下階段處理資料壓縮/解壓縮
-
作業輸入資料解壓縮:啟用壓縮仿真時,GridMix會生成可壓縮的輸入資料,基于原始作業的配置,模擬的GridMix作業將使用解壓縮器來讀取壓縮的輸入資料,目前,GridMix使用MapReduce . input . file input format . input dir以確定原始作業是否使用了壓縮的輸入資料,如果原始作業的輸入檔案是未壓縮的,那么模擬作業將讀取壓縮的輸入檔案,而不使用解壓縮器,
-
中間資料壓縮和解壓縮:如果原始作業啟用了地圖輸出壓縮,那么GridMix也會為模擬作業啟用地圖輸出壓縮,因此,減壓器將使用解壓縮器來讀取地圖輸出資料,
-
作業輸出資料壓縮:如果原始作業的輸出被壓縮,那么GridMix也將為模擬作業啟用作業輸出壓縮,
以下配置引數會影響壓縮仿真
| 引數 | 描述 |
|---|---|
| grid mix . compression-仿真. enable | 在模擬的GridMix作業中啟用壓縮仿真,默認值為真, |
打開壓縮仿真后,GridMix將生成壓縮的輸入資料,因此,輸入資料的總大小將小于預期大小,一組gridmix.min.file.size較小的值(大約為的10gridmix.gen.bytes.per.file)以使GridMix能夠正確模擬壓縮.
模擬高記憶體作業
MapReduce允許用戶將作業定義為高記憶體作業,來自高記憶體作業的任務可能會在任務行程中占據更大的記憶體份額,模擬這種行為很重要,原因如下,
-
對調度程式的影響:高記憶體作業的任務調度會影響調度行為,因為它可能導致資源預留和利用,
-
對節點的影響:由于高記憶體任務占用較大的記憶體,節點管理器會為這些任務分配額外的資源,因此,這成為記憶體仿真的先驅,在記憶體仿真中,需要將具有高記憶體需求的任務視為高記憶體任務,
高記憶體特性仿真可以通過設定來禁用
grid mix . highlam-仿真. enable到錯誤的,
模擬資源使用
像中央處理器、物理記憶體、虛擬記憶體、JVM堆等資源的使用由MapReduce使用其任務計數器記錄,GridMix使用這些資訊來模擬模擬任務中的資源使用情況,模擬資源使用將有助于GridMix在測驗集群上施加與實際集群相似的負載,
MapReduce任務在其整個生命周期內都會耗盡資源,GridMix還試圖通過在模擬任務的整個生命周期中跨越資源使用仿真來模仿這種行為,每個要模擬的資源都應該有一個仿真器與之相關的,每一個這樣的仿真器應該實作org . Apache . Hadoop . mapred . grid mix .仿真器. resourceusage,ResourceUsageEmulatorPlugin介面,資源仿真器在GridMix中有插件可以在每次運行前配置(插入或拔出),GridMix用戶可以配置多個仿真器插件通過傳遞逗號分隔的仿真器作為的值gridmix .仿真器.資源使用.插件引數,
串列仿真器隨GridMix一起提供:
-
累計CPU使用量仿真器:GridMix使用瘤胃公布的累計CPU使用率值,并確保模擬任務的總累計CPU使用率接近瘤胃公布的值,可以配置GridMix來模擬累積的CPU使用,方法是添加org . Apache . Hadoop . mapred . grid mix .仿真器. resourceusage,累積量到模擬器串列插件為配置gridmix .仿真器.資源使用.插件引數,CPU使用模擬器的設計方式是,它只在任務的特定進度邊界進行模擬,該時間間隔可通過以下方式配置gridmix .仿真器.資源-使用率. cpu .仿真-間隔,此引數的默認值為0.1即10%,
-
總堆使用量仿真器:GridMix使用瘤胃發布的總堆使用率值,并確保模擬任務的總堆使用率接近瘤胃發布的值,GridMix可以配置為通過添加org . Apache . Hadoop . mapred . grid mix .仿真器. resourceusage,TotalHeapUsageEmulatorPlugin到模擬器串列插件為配置gridmix .仿真器.資源使用.插件引數,堆使用模擬器的設計方式是,它只在任務的特定進度邊界上進行模擬,該時間間隔可通過以下方式配置gridmix .仿真器.資源使用.堆.仿真-間隔,此引數的默認值為0.1即10%進度間隔,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355761.html
標籤:其他
上一篇:Linux vim的基本使用