安裝分布式的Hadoop集群的環境
準備作業:在安裝分布式的Hadoop集群之前需要我們準備好若干臺能夠連接到網路的虛擬機,采用ifconfig命令可以查看該虛擬機的IP,最好通過apt命令安裝vim編輯器方便修改組態檔,
1.安裝JDK
找到對應的JDK的安裝包,我安裝的是JDK1.8_162版本的,如果大家需要的話,我會整理我用到的軟體上傳到網盤分享給大家,
cd /usr/local
sudo mkdir jvm #創建/usr/local/jvm目錄用來存放JDK檔案
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/local/jvm #把JDK檔案解壓到/usr/local/jvm目錄下之后采用vim編輯器 ,編輯該用戶的環境變數檔案,添加JDK目錄到環境變數中(注意需要在每臺虛擬機上都配置JAVA環境)
vim ~/.bashrc##打開該用戶的環境變數
#########在檔案末尾添加如下的內容
export JAVA_HOME=/usr/local/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source ~/.bashrc#使得新更改的內容立即生效之后可以使用如下命令查看是否安裝成功,若出現了Java的版本號則成功安裝,否則的話檢查前些步驟哪里有問題,
java -version
###若出現如下資訊,證明安裝成功
hadoop@ubuntu:~$ java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)2.配置 ssh無密碼登錄本機和訪問集群的機器
首先為了便于區分集群中的機器,需要修改其在shell環境中顯示的主機名,在各臺虛擬機中都執行如下的命令,在master主機中添加master,在slave01節點添加slave01.......,然后重啟虛擬機即可看見終端發生變化,
sudo vim /etc/hostname 修改集群中虛擬機的/etc/hosts檔案,將主機名與IP對應,添加如下的配置:
修改集群中虛擬機的/etc/hosts檔案,將主機名與IP對應,添加如下的配置:
127.0.0.1 localhost
10.13.0.33 master
10.13.0.34 slave01
10.13.0.35 slave02
10.13.0.36 slave03
10.13.0.37 slave04檢查是否可以登陸到本機,執行ssh localhost命令,若登陸失敗的話需要安裝openssh-server服務并且生成ssh密鑰(若登陸成功的話跳過此步驟)
sudo apt-get openssh-server
ssh-keygen -t rsa -P ""
cat $HOME/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#若提示authorized_keys檔案不存在時,需要自己創建一個這樣的空白檔案,該命令是將ssh密鑰添加到authorized_keys檔案中的,在保證了集群中的主機都可以連接到本地的localhost后,還需要讓master主機免密登錄到slave節點 ,執行如下命令將master主機生成的密鑰傳送給每臺slave主機,
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave03:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave04:/home/hadoop/
#scp命令是ssh協議傳輸檔案的,其格式為:scp 待傳輸的檔案 目標主機的用戶名@目標主機的IP:目標主機存盤位置 成功執行以上命令后,可以到每臺的slave節點上執行 ls ~命令可以查看到master主機傳輸的id_rsa.pub檔案,隨后需要將master主機的密鑰添加到各自的節點上 ,在每臺slave機器上執行如下命令即可:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub在這里提醒一下,一定要保證master節點和slave節點的登錄的用戶名一致,不一致的話會導致后續產生一些問題,這樣就可以在master主機實作了免密登錄到各臺slave節點,執行如下命令即可登錄到其他節點:
ssh slave01
exit#退出該連接3.安裝Hadoop2.7.1
我實驗環境使用的Hadoop的版本比較低,是2015年發布的2.7.1版本的Hadoop,我想Hadoop2.X版本的安裝以及配置的步驟相差不大,大家有興趣的話可以安裝一下較新版本的Hadoop,這里我就不再嘗試了,我們依舊選擇將Hadoop安裝在/usr/local/目錄下,如果獲取了Hadoop的安裝包的話就執行如下的命令在master節點上進行解壓縮(無需在slave節點上做操作),
sudo tar -zxf ~/下載/hadoop-2.7.1.tar.gz -C /usr/local # 解壓到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.7.1/ ./hadoop # 將檔案夾名改為hadoop
sudo chown -R hadoop ./hadoop # 修改hadoop檔案夾的所有者隨后編輯~/.bashrc檔案,添加如下內容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin隨后執行source ~/.bashrc使環境變數生效,
4.Hadoop集群配置
Hadoop的組態檔都在/usr/local/hadoop/etc/hadoop目錄下面,我們需要先修改slaves,添加如下內容:
slave01
slave02
slave03
slave04修改core-site.xml檔案,最終內容如下所示:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>修改hdfs-site.xml檔案,最終內容如下所示,其中3代表著是在hdfs上面有多少份資料的備份:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>修改mapred-site.xml(復制mapred-site.xml.template,再修改檔案名),最終內容如下所示:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml檔案,最終內容如下圖所示:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property><!--接下來兩個變數是防止因為資源不足而殺死yarn行程的-->
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
注:以上的組態檔只在master端進行配置,之后我們會復制到各個slave節點,如果在此之前跑過偽分布式的模式或者是local模式的話,在切換到集群模式之前,需要洗掉臨時檔案和日志檔案
cd /usr/local/
rm -rf ./hadoop/tmp # 洗掉臨時檔案
rm -rf ./hadoop/logs/* # 洗掉日志檔案完成后需要將位于~/目錄下面的hadoop.master.tar.gz檔案復制到所有的slave節點上,并進行解壓操作,執行如下命令:
scp ./hadoop.master.tar.gz slave01:/home/hadoop
scp ./hadoop.master.tar.gz slave02:/home/hadoop
scp ./hadoop.master.tar.gz slave03:/home/hadoop
scp ./hadoop.master.tar.gz slave04:/home/hadoop在slave節點上執行如下命令:
sudo rm -rf /usr/local/hadoop/
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop至此我們需要搭建的Hadoop的分布式集群就搭建完畢了,接下來我們進行測驗 ,在master端執行如下命令:
cd /usr/local/hadoop
bin/hdfs namenode -format #非常值得注意的是,在Hadoop集群中有節點正在運行時不要進行namenode的格式化,否則會產生非常不好的影響,會導致master端的ID與slave端的ID不一致,導致HDFS啟動不起來
sbin/start-all.sh在輸出一些列的INFO之后,若未出現error,則證明成功啟動了Hadoop集群,大多數會出現JAVA_HOME is not set 的字樣,這時不要驚慌,先停止了Hadoop集群,使用vim編輯器打開位于/usr/local/hadoop/etc/hadoop/hadoop-env.sh檔案,找到JAVA_HOME=${JAVA-HOME}修改為自己的java安裝路徑即可(每個節點上都需要此操作),如下圖所示: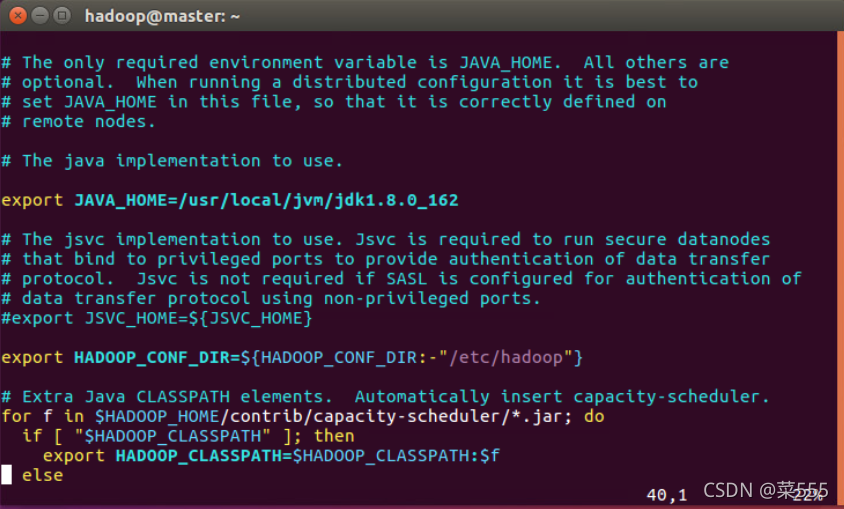
這樣保存以后再重新啟動Hadoop集群就能夠成功啟動了,
這時我們可以運行jps命令來分別觀察master端和slave端的正在運行的行程,正常情況下如下圖: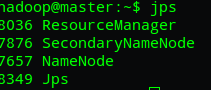

若出現了resourcemanager和nodemanager不存在的情況,建議關閉hadoop集群再重新啟動一次看一下,
若出現了datanode經常性掉線的問題的話,建議看一下其他的博客,好像還挺常見的,大概率是多次格式化namenode節點導致的clusterID不一致導致的,可以查看master和slave節點位于hadoop安裝目錄下的tmp/dfs/下的name或者data檔案夾下面的VERSSION檔案,里面有clusterID,修改為一致就可以,但是我沒有遇到過以上的問題,嘻嘻0.0,
再次強調一下,除了第一次格式化namenode之后不要隨便進行namenode進行格式化操作,如果需要對namenode進行格式化時應該先停止Hadoop集群,并且洗掉Hadoop安裝目錄下的tmp和logs檔案夾(在所有節點上都進行此步驟),再進行格式化,
5.Hadoop的一些常用的命令
1.啟動關閉Hadoop集群
cd /usr/local/hadoop
sbin/start-all.sh #啟動hadoop集群
sbin/stop-all.sh #關閉hadoop集群2.查看HDFS檔案的使用情況,正常的話會出現如下圖的資訊:
#所有命令都需要在hadoop的安裝目錄下使用
hadoop dfsadmin -report #這樣會顯示HDFS集群的使用情況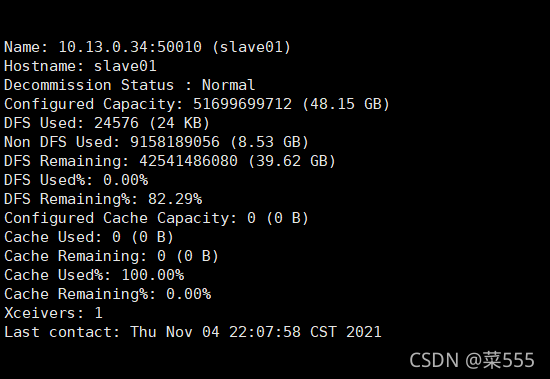
如果以上所有資訊都是0的話,就是HDFS例外了,查看日志檔案來定位錯誤資訊,具體問題具體分析,我之前是因為節點的用戶名不一致導致了datanode連接不到master主機而導致的HDFS初始化失敗,慘重的教訓,
3.上傳到HDFS中檔案,以及讀取位于HDFS中的檔案
hdfs dfs -ls / #查看hdfs中位于/下的檔案
hdfs dfs -mkdir /aaa #在hdfs中新建aaa檔案夾
hadoop fs -put /usr/local/hadoop/README.md /aaa #上傳位于本地的README.md檔案到hdfs系統中的/aaa路徑下
hadoop fs -ls /aaa #查看是否上傳成功
file:///usr/local/Spark/data/graphx/followers.txt #這樣的路徑讀取的是本地檔案
hdfs:///usr/local/Spark/data/graphx/followers.txt #這樣的路徑讀取的是存在hdfs中的檔案
4.附上學習大資料學習的一個好用的網站,是廈門大學林子雨老師團隊做的一些學習資料,大家可以上去學習一下,拓展一下自己的知識,好用的網站
寫在本節最后的話,因為作者也是初學大資料不久的菜鳥,有很多東西也是靠自己不斷地百度,查看博客得來的,也有部分問題未能得到妥善的解決,只是分享一下作者面臨的諸多問題以及分享一下解決的經驗,所以有同學在實驗程序中遇到了不一樣的問題時,歡迎各位在本文下面評論區留言,大家也可以互相討論學習一下,我也會積極回復大家的問題的,祝愿大家在趙老師帶的大資料原理與技術的課程中學到很多對自己有幫助的知識,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356067.html
標籤:其他