Spark 概述
- 什么是Spark
- Spark是一種基于記憶體的快速,通用,可擴展的大資料分析計算引擎
- Spark 是一種由 Scala 語言開發的快速、通用、可擴展的大資料分析引擎
- Spark Core 中提供了 Spark 最基礎與最核心的功能
- Spark SQL 是 Spark 用來操作結構化資料的組件,通過 Spark SQL,用戶可以使用SQL 或者 Apache Hive 版本的 SQL 方言(HQL)來查詢資料,
- Spark Streaming 是 Spark 平臺上針對實時資料進行流式計算的組件,提供了豐富的
處理資料流的 API,
- Spark 與 Hadoop的對比:Hadoop 的 MR 框架和 Spark 框架都是資料處理框架,那么我們在使用時如何選擇呢?
- Hadoop MapReduce 由于其設計初衷并不是為了滿足回圈迭代式資料流處理,因此在多并行運行的資料可復用場景(如:機器學習、圖挖掘演算法、互動式資料挖掘演算法)中存在諸多計算效率等問題,所以 Spark 應運而生,Spark 就是在傳統的 MapReduce 計算框架的基礎上,利用其計算程序的優化,從而大大加快了資料分析、挖掘的運行和讀寫速度,并將計算單元縮小到更適合并行計算和重復使用的 RDD 計算模型,
- 機器學習中 ALS、凸優化梯度下降等,這些都需要基于資料集或者資料集的衍生資料
反復查詢反復操作,MR 這種模式不太合適,即使多 MR 串行處理,性能和時間也是一
個問題,資料的共享依賴于磁盤,另外一種是互動式資料挖掘,MR 顯然不擅長,而
Spark 所基于的 scala 語言恰恰擅長函式的處理, - Spark 是一個分布式資料快速分析專案,它的核心技術是彈性分布式資料集(Resilient Distributed Datasets),提供了比 MapReduce 豐富的模型,可以快速在記憶體中對資料集進行多次迭代,來支持復雜的資料挖掘演算法和圖形計算演算法,
- Spark 和Hadoop 的根本差異是多個作業之間的資料通信問題 : Spark 多個作業之間資料
通信是基于記憶體,而 Hadoop 是基于磁盤,
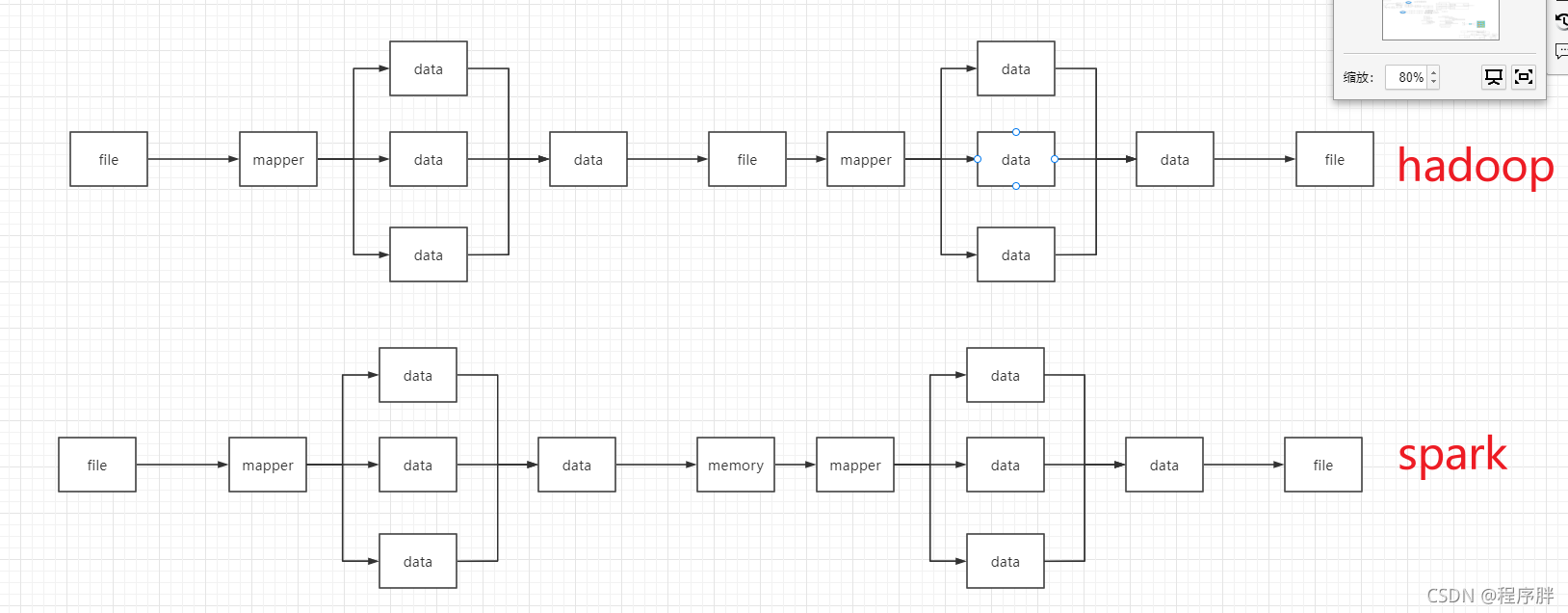
- Spark Task 的啟動時間快,Spark 采用 fork 執行緒的方式,而 Hadoop 采用創建新的行程的方式,
- Spark 只有在 shuffle 的時候將資料寫入磁盤,而 Hadoop 中多個 MR 作業之間的資料互動都要依賴于磁盤互動
- Spark 的快取機制比 HDFS 的快取機制高效,
- 經過上面的比較,我們可以看出在絕大多數的資料計算場景中,Spark 確實會比 MapReduce
更有優勢,但是 Spark 是基于記憶體的,所以在實際的生產環境中,由于記憶體的限制,可能會
由于記憶體資源不夠導致 Job 執行失敗,此時,MapReduce 其實是一個更好的選擇,所以 Spark
并不能完全替代 MR,
- Spark 核心模塊
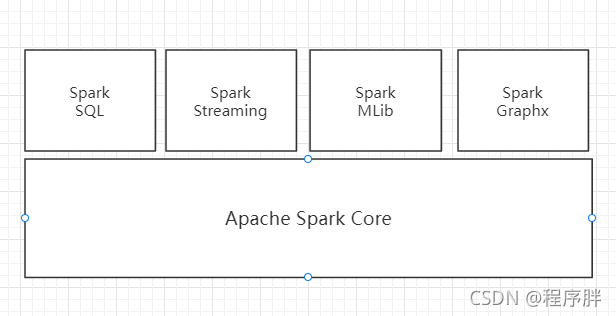
- Spark Core : Spark Core 中提供了 Spark 最基礎與最核心的功能,Spark 其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基礎上進行擴展的
- Spark SQL:Spark SQL 是 Spark 用來操作結構化資料的組件,通過 Spark SQL,用戶可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)來查詢資料,
- Spark Streaming:Spark Streaming 是 Spark 平臺上針對實時資料進行流式計算的組件,提供了豐富的處理資料流的 API,
- Spark MLlib:MLlib 是 Spark 提供的一個機器學習演算法庫,MLlib 不僅提供了模型評估、資料匯入等額外的功能,還提供了一些更底層的機器學習原語,
- Spark GraphX:GraphX 是 Spark 面向圖計算提供的框架與演算法庫,
Spark快速上手
創建Maven專案
- 第一步創建工程
- 創建好了之后,因為要學習多個模塊,所以我們這個創建好的專案當作父類,所以將src洗掉
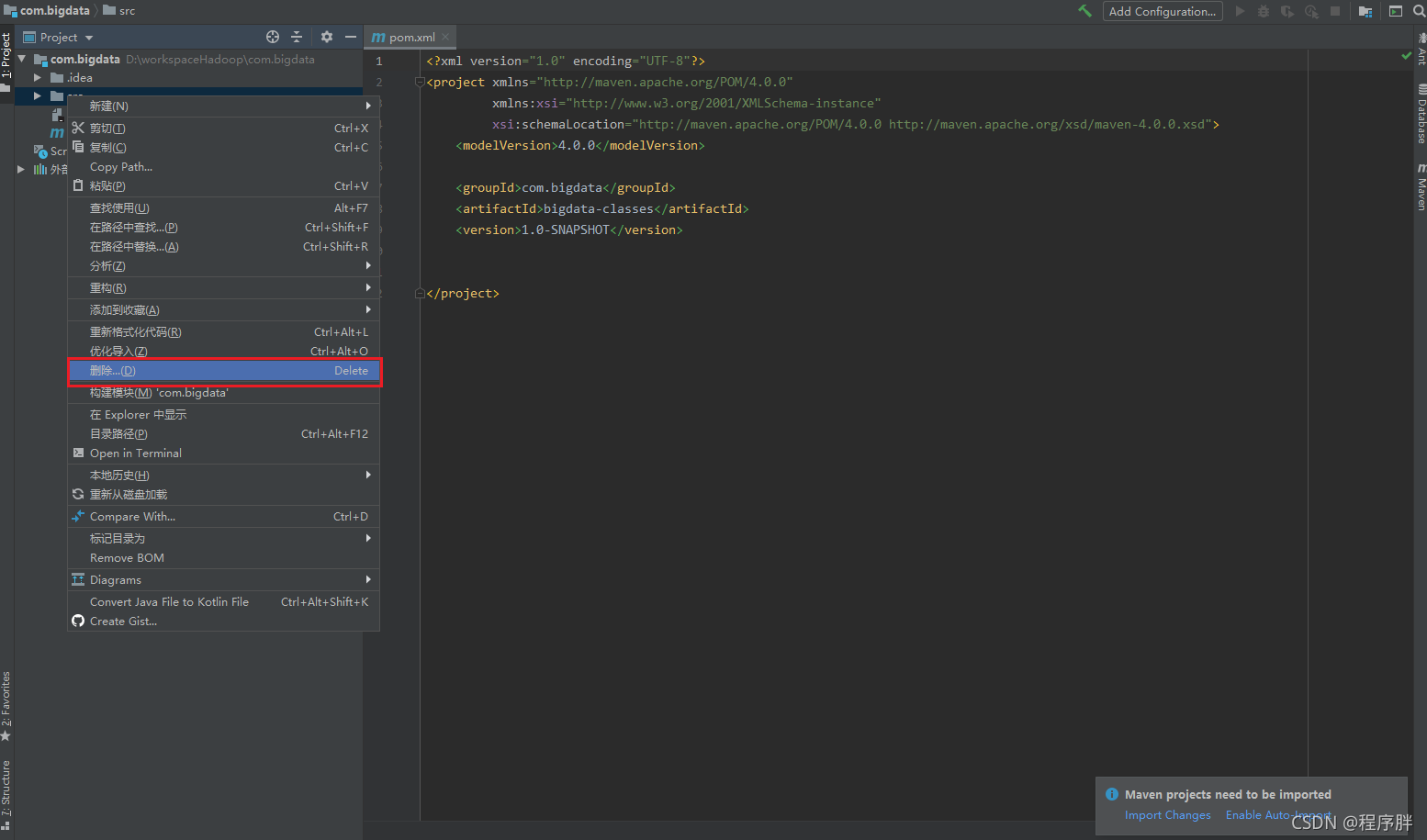
- 然后點擊父目錄,新建模塊,下一步后,因為首先先學習的是sparkcore,所以先創建sparkcore模塊
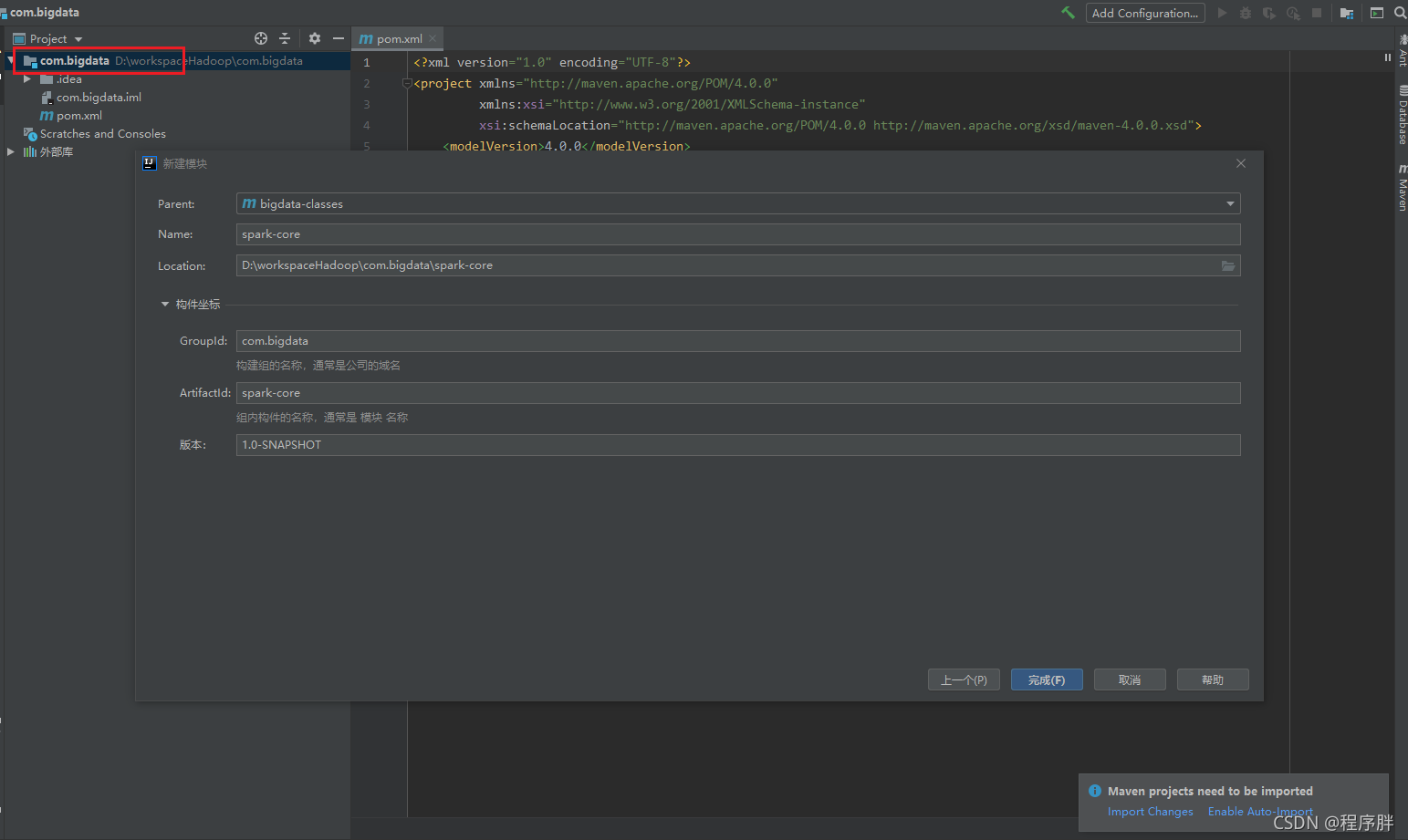
- 配置好scala,網上有這里就不多贅述,但是要在模塊上添加scala框架支持,所以就要提娜姬添加
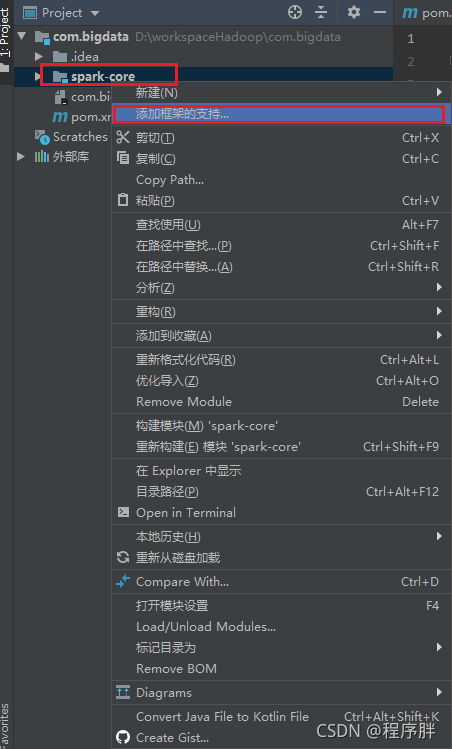
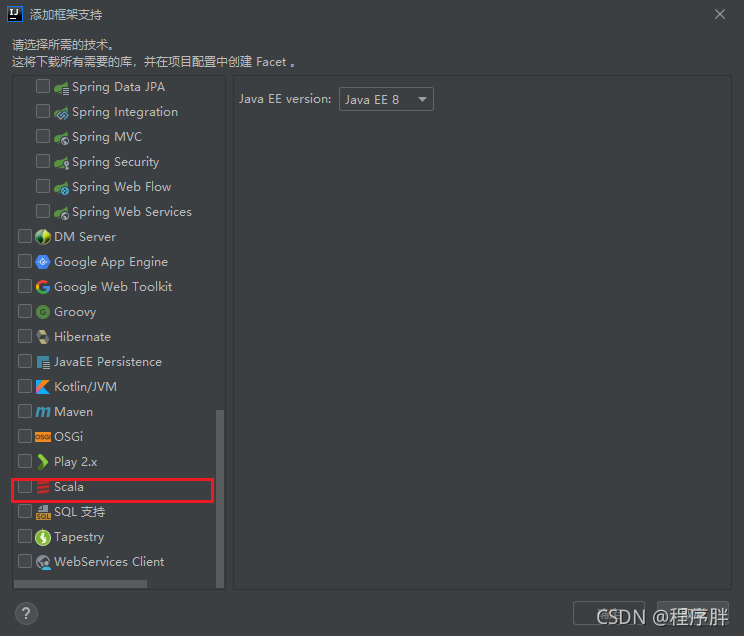
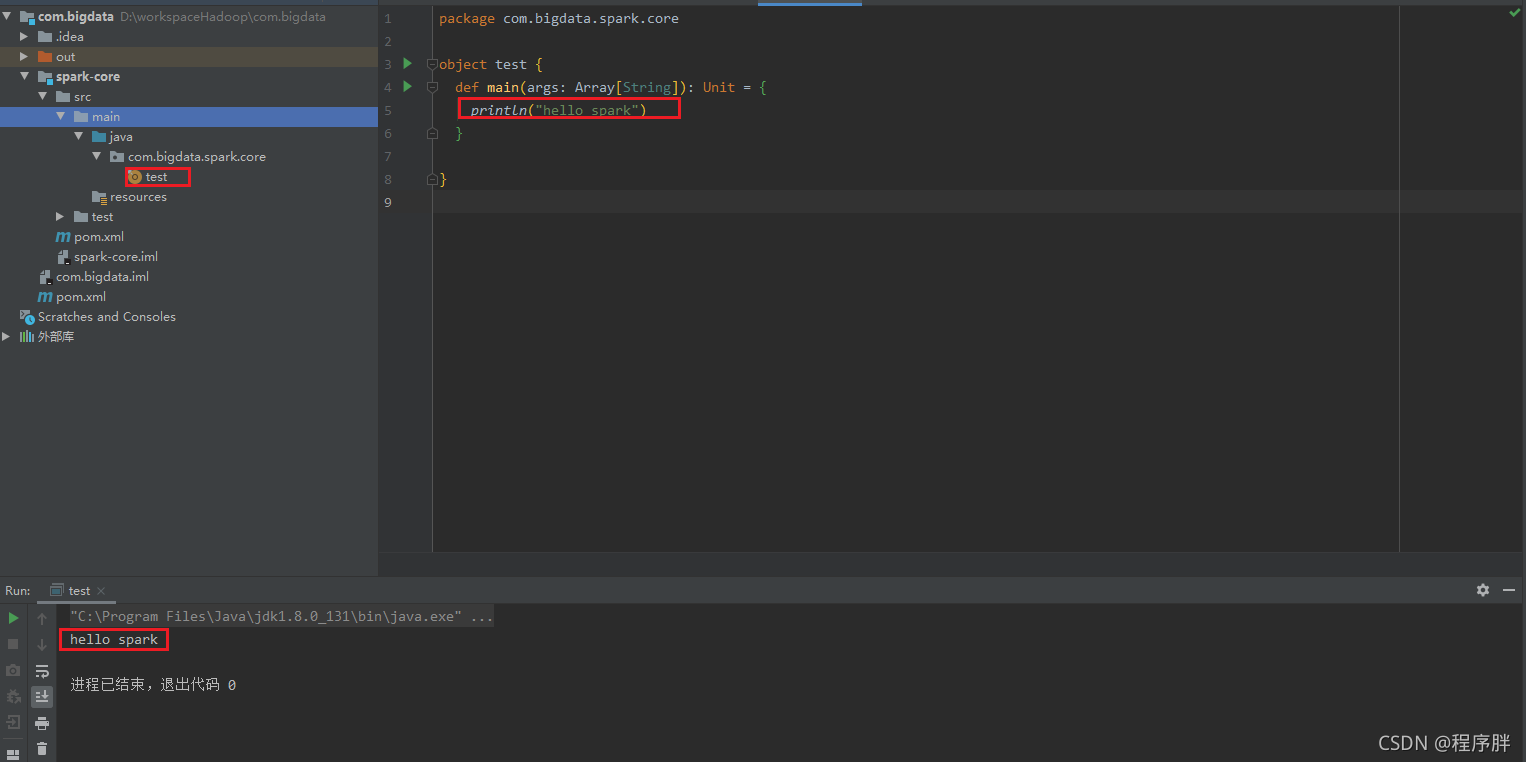
- 點開src目錄,來到Java目錄下創建目錄,并創建scala檔案,測驗一下環境是否正確,
- 在專案的pom.xml下引入依賴
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 該插件用于將 Scala 代碼編譯成 class 檔案 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 宣告系結到 maven 的 compile 階段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
WordCount案例
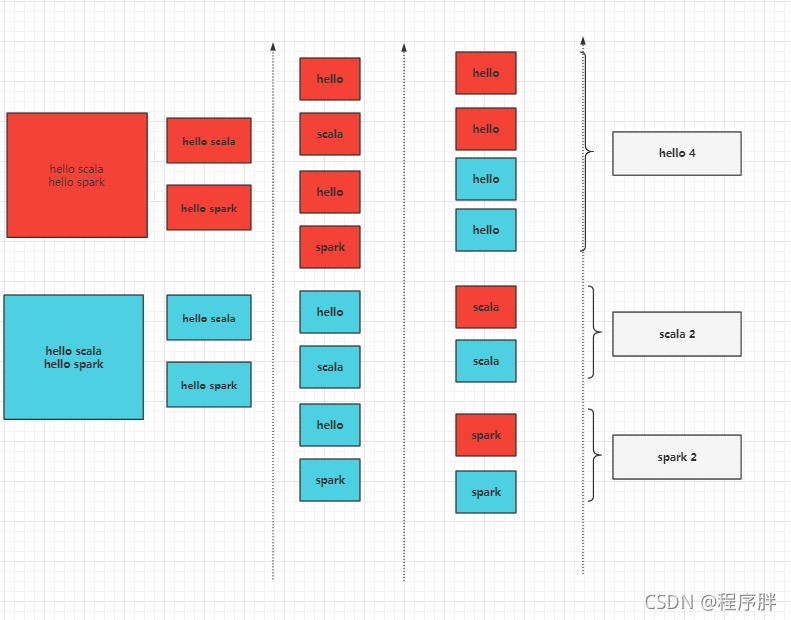
- 通過獲取檔案夾下的檔案,將檔案中的資料進行整合,得到每個單詞的數量
- 流程圖:
- 代碼:
- 第一種方式
object WordCount {
def main(args: Array[String]): Unit = {
//建立和spark框架的連接
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
//執行業務操作
//1. 讀取檔案,獲取一行一行的資料
val lines = sc.textFile("datas")
//2. 將一行資料進行才分,形成一個一個的單詞
val words = lines.flatMap(_.split(" "))
//3. 將資料根據單詞進行分組
val wordLists = words.groupBy(word => word)
//4. 對分組后的資料進行準換
val wordToCount = wordLists.map {
case (word, list) => {
(word, list.size)
}
}
//5. 將轉換結構列印
val result = wordToCount.collect()
result.foreach(println)
//關閉連接
sc.stop()
}
}
- 第二種方式
object WordCount {
def main(args: Array[String]): Unit = {
//建立和spark框架的連接
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
//執行業務操作
//1. 讀取檔案,獲取一行一行的資料
val lines = sc.textFile("datas")
//2. 將一行資料進行才分,形成一個一個的單詞
val words = lines.flatMap(_.split(" "))
//3. 將資料根據單詞進行分組
val wordToOne = words.map(
word => (word, 1)
)
val wordLists = wordToOne.groupBy{
t => t._1
}
//4. 對分組后的資料進行準換
val wordToCount = wordLists.map {
case (word, list) => {
list.reduce(
(t1,t2) => {
(t1._1, t1._2 + t2._2)
}
)
}
}
//5. 將轉換結構列印
val result = wordToCount.collect()
result.foreach(println)
//關閉連接
sc.stop()
}
}
- 第三種方式:利用spark自帶的方法
object WordCount {
def main(args: Array[String]): Unit = {
//建立和spark框架的連接
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
//執行業務操作
//1. 讀取檔案,獲取一行一行的資料
val lines = sc.textFile("datas")
//2. 將一行資料進行才分,形成一個一個的單詞
val words = lines.flatMap(_.split(" "))
//3. 將資料根據單詞進行分組
val wordToOne = words.map(
word => (word, 1)
)
//4. spark方式對分組后的資料進行準換
//reduceByKey:相同的KEY的資料,可以對value進行reduce聚合
val wordToCount = wordToOne.reduceByKey(_ + _)
//5. 將轉換結構列印
val result = wordToCount.collect()
result.foreach(println)
//關閉連接
sc.stop()
}
}
- 教學版本:
// 創建 Spark 運行配置物件
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 創建 Spark 背景關系環境物件(連接物件)
val sc : SparkContext = new SparkContext(sparkConf)
// 讀取檔案資料
val fileRDD: RDD[String] = sc.textFile("input/word.txt")
// 將檔案中的資料進行分詞
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
// 轉換資料結構 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))
// 將轉換結構后的資料按照相同的單詞進行分組聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)
// 將資料聚合結果采集到記憶體中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 列印結果
word2Count.foreach(println)
//關閉 Spark 連接
sc.stop()
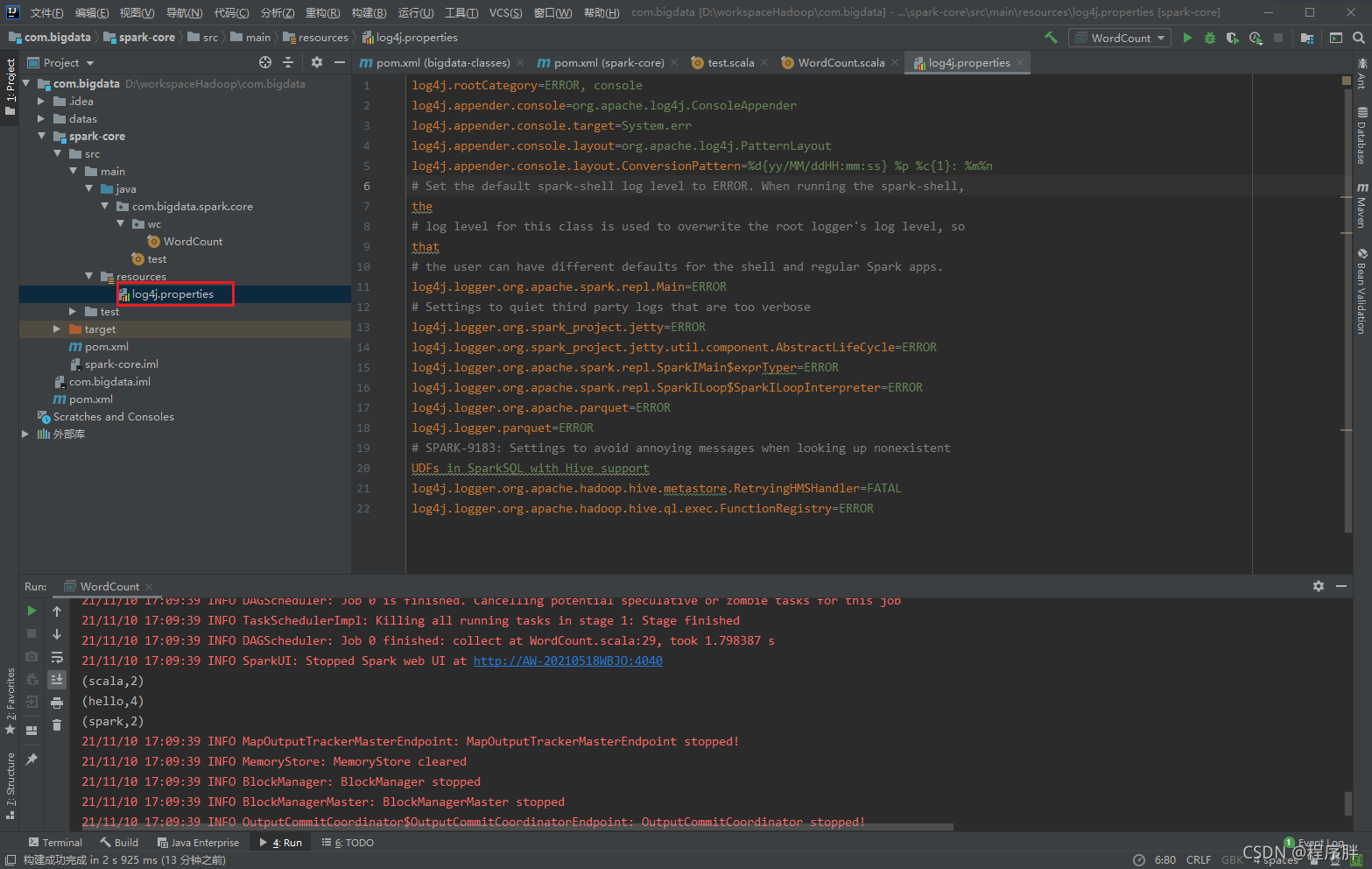
- 管理日志資訊,再在專案的 resources 目錄中創建 log4j.properties 檔案,并添加日志配置資訊:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd
HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell,
the
# log level for this class is used to overwrite the root logger's log level, so
that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent
UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356070.html
標籤:其他
下一篇:搭建Hadoop集群