一、前情提要
上一篇文章介紹了MapReduce的Api呼叫方法以及eclipse的配置,這次我們就利用MapReduce對英語文章檔案進行單詞統計!
有需要的歡迎看看我的前一篇文章:MapReduce相關eclipse配置及Api呼叫
目錄
- 一、前情提要
- 二、前置條件
- 三、創建Maven工程
- 四、修改Windows系統變數
- 五、撰寫MapReduce的jar包程式
- 六、在Linux執行單詞統計排序
- 六、在Eclipse執行單詞統計排序
二、前置條件
| 需要安裝 | 下載方法 |
|---|---|
| IDEA | 自備 |
| hadoop-eclipse-plugin-2.7.0.jar | 百度網盤下載 , 提取碼:f259 |
| MobaXterm | 百度網盤下載,提取碼:f64v |
確保Hadoop集群搭建成功,若還沒搭建成功,歡迎看看我之前的文章:Hadoop集群搭建(步驟圖文超詳細版)
本次將會用到的,HDFS命令大全:Hadoop——HDF的Shell命令,建議大家在操作時看看!!
三、創建Maven工程
打開IDEA工具,在左上角點擊 “File”——“New”——“Project” ↓

選擇 Maven 專案↓
填寫專案資訊↓
創建專案成功之后,我們打開pom.xml↓
在組態檔中,增加 Hadoop 的相關依賴↓
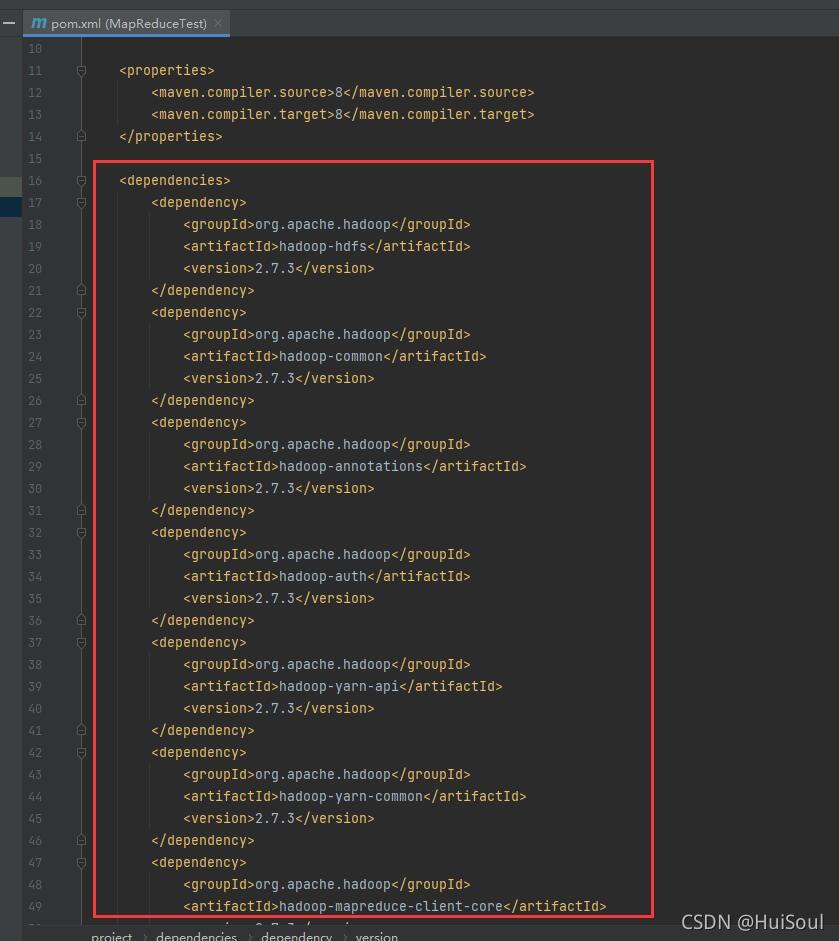
代碼如下↓
注意:< version >< /version >中替換你 Hadoop 的版本號,我這里是2.7.3!
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-annotations</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
點擊右上角的這個按鈕,重新加載依賴庫和組態檔↓
四、修改Windows系統變數
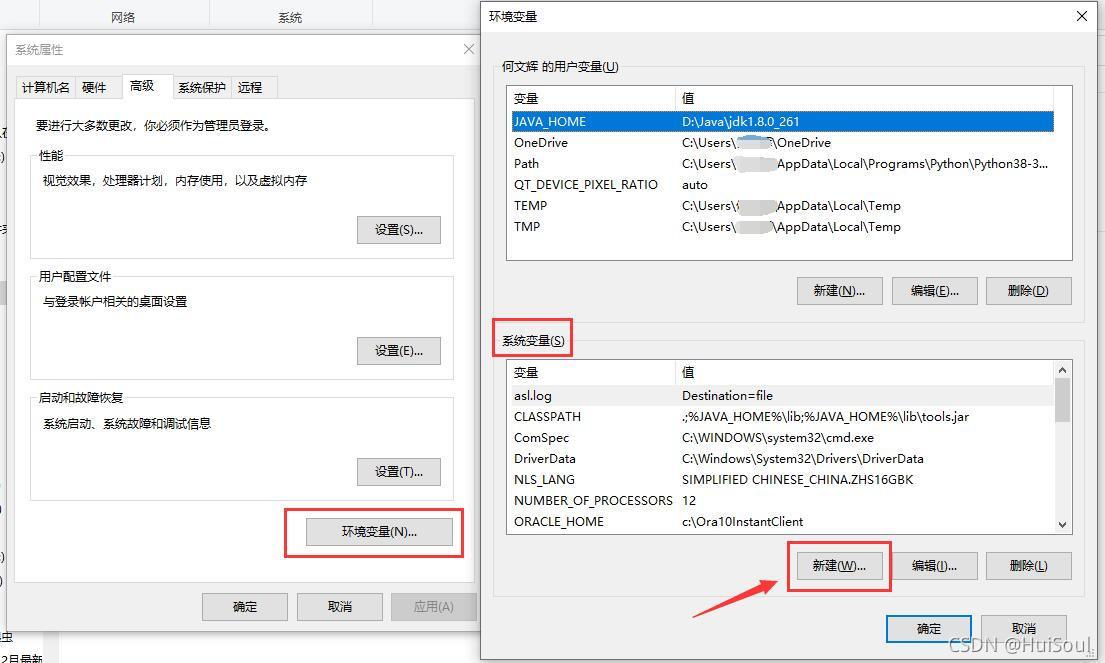
右鍵桌面上的 “此電腦” 圖示,點擊 “屬性” ,在環境變數中新建系統變數↓
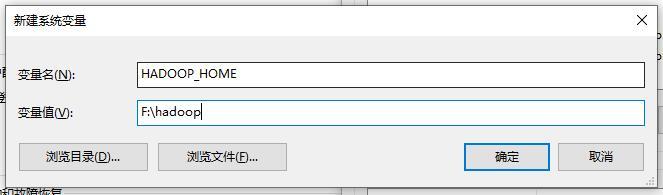
系統變數中添加hadoop檔案路徑↓
五、撰寫MapReduce的jar包程式
上一篇文章中,我們把 hadoop 整個檔案從 linux 系統上壓縮并解壓至 Windows 上,現在我們打開這個 hadoop 檔案,來到 /etc/hadoop/ 這個目錄下,將以下四個檔案拷貝復制到 IDEA 剛創建的專案中
四個檔案↓
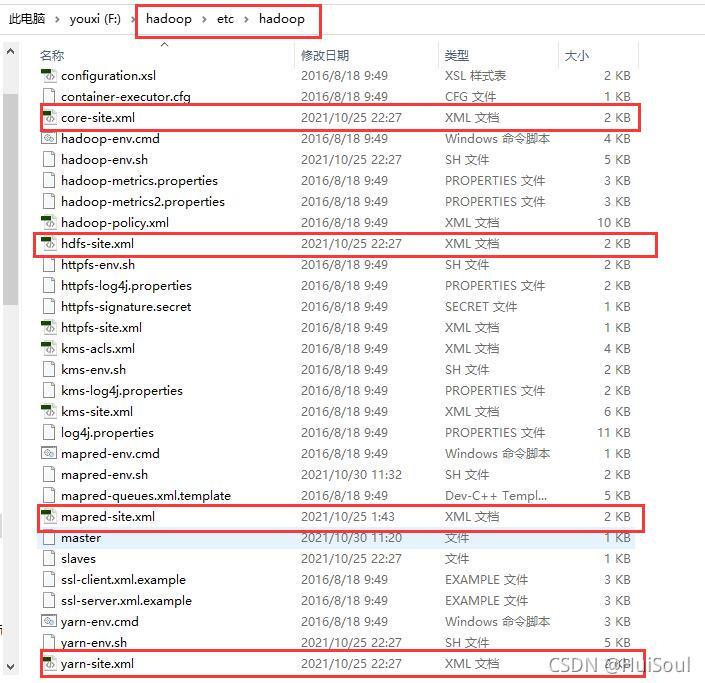
復制到專案的 resources 檔案夾下↓
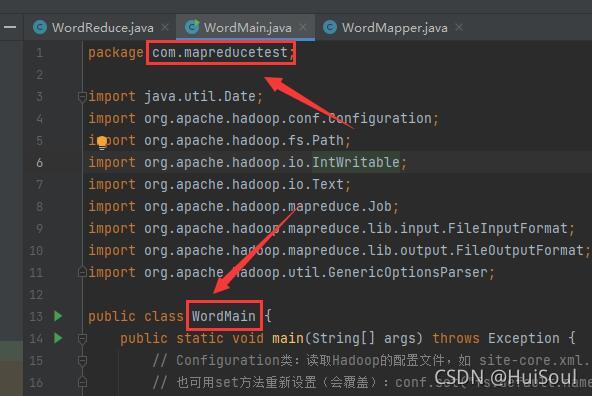
緊接著我們創建一個包和三個類:WordMain.java、WordMapper.java、WordReduce.java
在這里我先來解釋一下這三個包分別的用處↓
WordMain類是對任務的創建進行部分配置,主要是在Job中設定相應的Mapper類和Reduce類,這樣任務在運行時才知道使用相應類進行處理;WordMain驅動類還可以對 MapReduce程式進行相應配置,讓任務在haadoop集群運行所定義的配置中進行,
WordMapper類繼承了Mapper方法,作用是將單詞從大寫到小寫和a到z的規律進行排序
WordReduce類則是繼承了Reducer方法,作用是將單詞利用正則運算式進行拆分統計
WordMain驅動類代碼↓
package com.mapreducetest;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordMain {
public static void main(String[] args) throws Exception {
// Configuration類:讀取Hadoop的組態檔,如 site-core.xml...;
// 也可用set方法重新設定(會覆寫):conf.set("fs.default.name", "hdfs://xxxx:9000")
Configuration conf = new Configuration();
// 將命令列中引數自動設定到變數conf中
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
/**
* 這里必須有輸入輸出
*/
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count"); // 新建一個 job,傳入配置資訊
job.setJarByClass(WordMain.class); // 設定 job 的主類
job.setMapperClass(WordMapper.class); // 設定 job 的 Mapper 類
job.setCombinerClass(WordReduce.class); // 設定 job 的 作業合成類
job.setReducerClass(WordReduce.class); // 設定 job 的 Reducer 類
job.setOutputKeyClass(Text.class); // 設定 job 輸出資料的關鍵類
job.setOutputValueClass(IntWritable.class); // 設定 job 輸出值類
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); // 檔案輸入
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); // 檔案輸出
boolean result = false;
try {
result = job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(new Date().toGMTString() + (result ? "成功" : "失敗"));
System.exit(result ? 0 : 1); // 等待完成退出
}
}
WordMapper類代碼↓
package com.mapreducetest;
import java.io.IOException;
import java.util.Date;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// 創建一個 WordMap類 繼承于 Mapper抽象類
public class WordMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// Mapper抽象類的核心方法,三個引數
public void map(Object key, // 首字符偏移量
Text value, // 檔案的一行內容
Context context) // Mapper端的背景關系,與 OutputCollector 和 Reporter 的功能類似
throws IOException, InterruptedException {
String[] ars = value.toString().split("['.;,?| \t\n\r\f]");
for (String tmp : ars) {
if (tmp == null || tmp.length() <= 0) {
continue;
}
word.set(tmp);
System.out.println(new Date().toGMTString() + ":" + word + "出現一次,計數+1");
context.write(word, one);
}
}
}
WordReducer類代碼↓
package com.mapreducetest;
import java.io.IOException;
import java.util.Date;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// 創建一個 WordReduce類 繼承于 Reducer抽象類
public class WordReduce extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable(); // 用于記錄 key 的最終的詞頻數
// Reducer抽象類的核心方法,三個引數
public void reduce(Text key, // Map端 輸出的 key 值
Iterable<IntWritable> values, // Map端 輸出的 Value 集合(相同key的集合)
Context context) // Reduce 端的背景關系,與 OutputCollector 和 Reporter 的功能類似
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values) // 遍歷 values集合,并把值相加
{
sum += val.get();
}
result.set(sum); // 得到最終詞頻數
System.out.println(new Date().toGMTString()+":"+key+"出現了"+result);
context.write(key, result); // 寫入結果
}
}
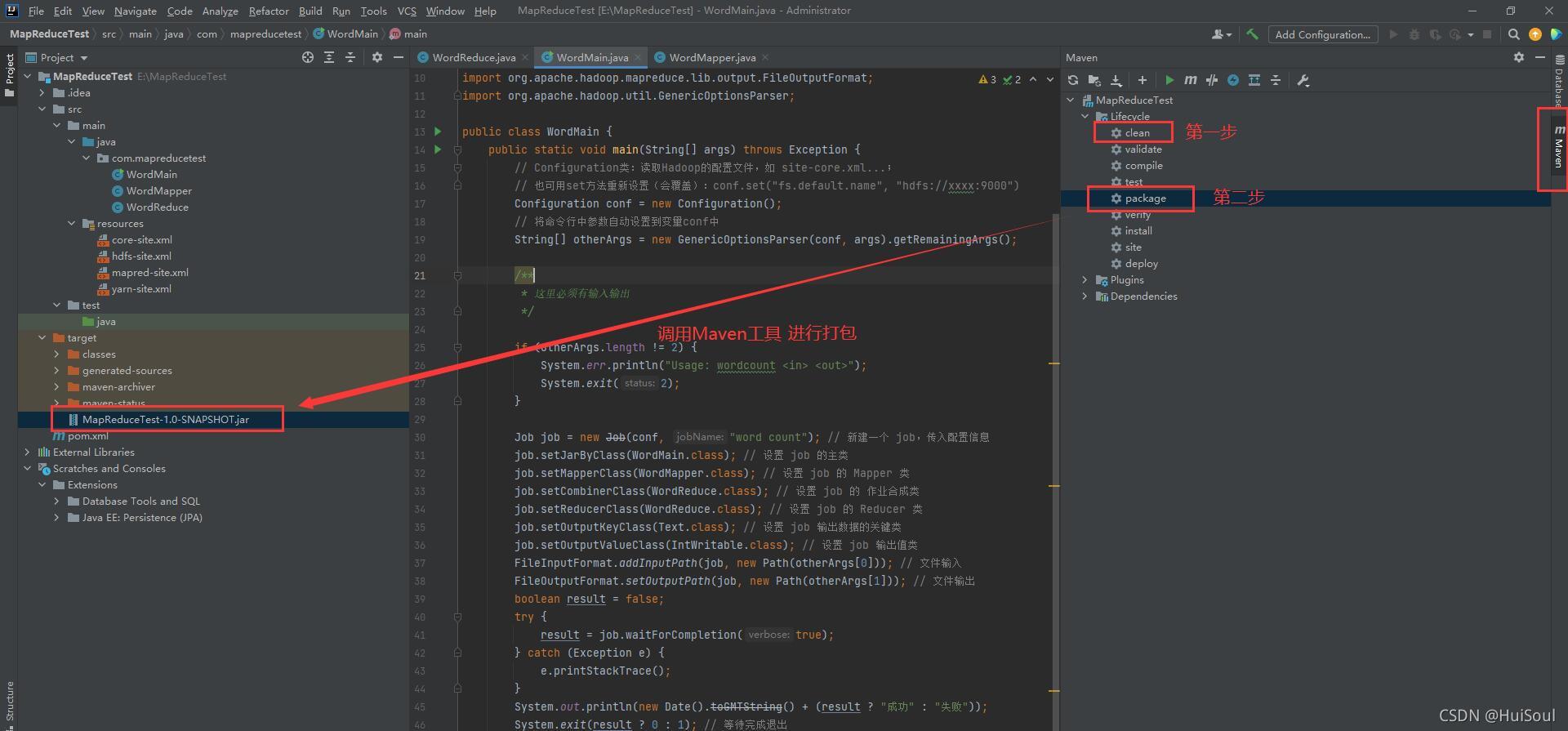
三個檔案都弄好后,在IDEA最右側有一欄 Maven工具列,打開它后在 Lifecycle 找到 “clean” 和 “package” 兩個指令,先雙擊 clean 待程式完后,再雙擊 package 進行打包!接著就能在專案的 target 檔案中看到我們打包好的 jar 包檔案,
六、在Linux執行單詞統計排序
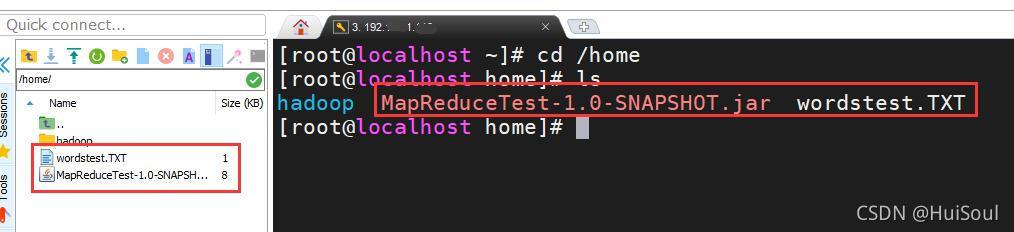
我們來到 linux 的 hadoop 主節點中,將剛剛打包的jar包和單詞文本檔案一同放 /home 目錄下↓
啟動hadoop集群,命令↓
start-all.sh
接著我們 HDFS 上創建一個 ainput 檔案夾用于存放上傳的檔案,然后我們把單詞檔案上傳HDFS↓
別忘了給檔案夾賦予可修改可讀取可執行的權限,命令↓
hdfs dfs -mkdir /ainput
hdfs dfs -put /home/wordstest.TXT /ainput
hdfs dfs -chmod 777 /ainput

重頭戲來了!!我們利用上傳的單詞統計驅動jar包對單詞檔案進行單詞統計,命令↓
hadoop jar MapReduceTest-1.0-SNAPSHOT.jar com.mapreducetest.WordMain /ainput /aoutput
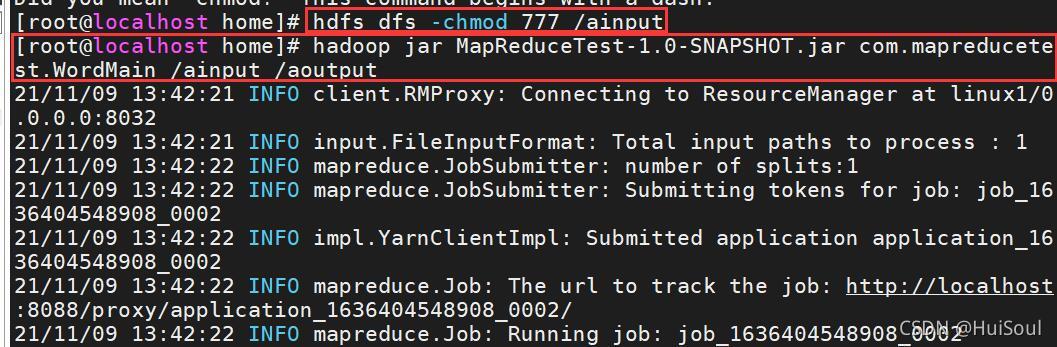
決議命令↓
格式:hadoop jar [jar檔案位置] [jar主類] [HDFS輸入位置] [HDFS輸出位置]
Tips:目前我就在jar所在目錄,所以只需要填寫jar包名稱就好了,如果不在同目錄下,記得加路徑+jar包名
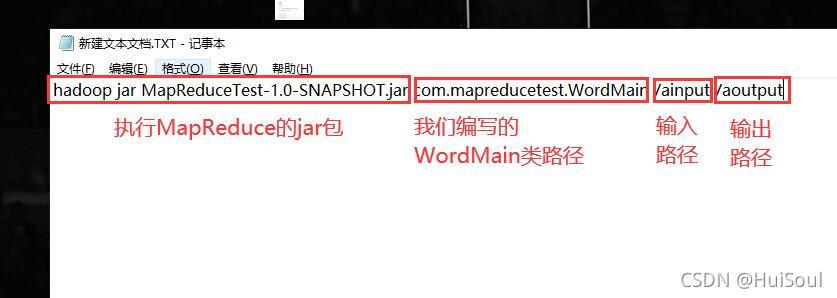
如何找到WordMain類路徑↓
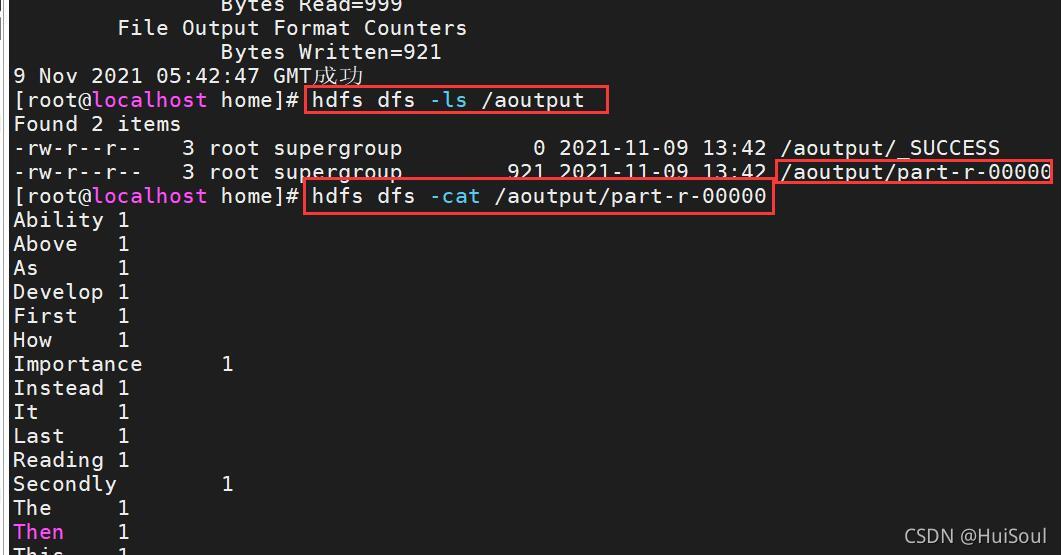
單詞排序統計結果↓
Tips:其中part-r-00000檔案保存的是運行結果,能看到檔案中的單詞已從大寫到小寫和a到z的規律進行排序好了↓
六、在Eclipse執行單詞統計排序
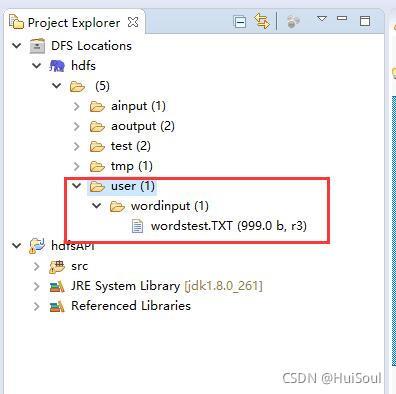
我們在Eclipse HDFS檔案系統中,在 /user目錄下新建一個檔案夾 user,在 user 檔案夾下,新建 wordinput 檔案夾,上傳 英文 檔案↓
右鍵->Run As->Run Configurations->Arguments,在左邊的導航串列點擊Java Application選擇WordMain Java程式↓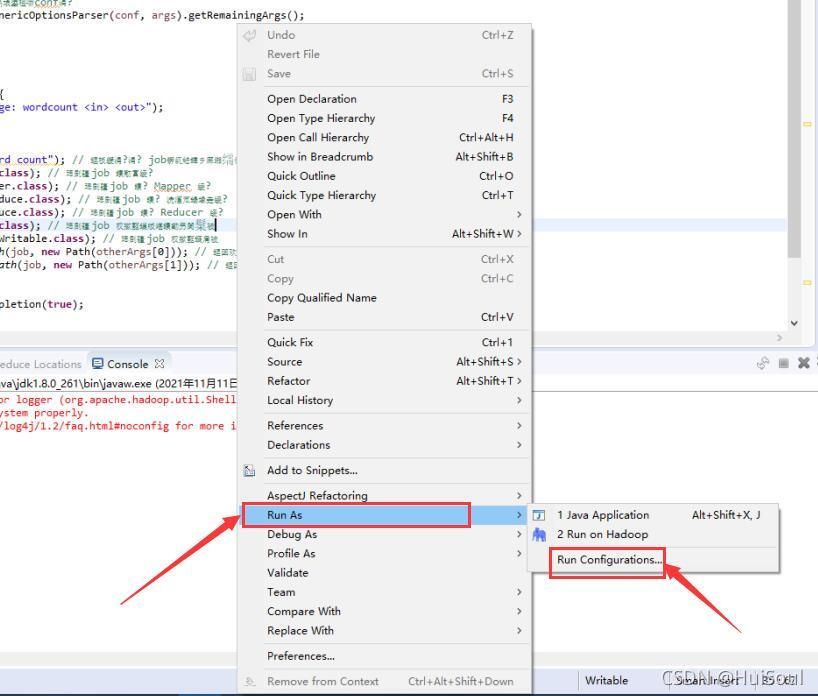
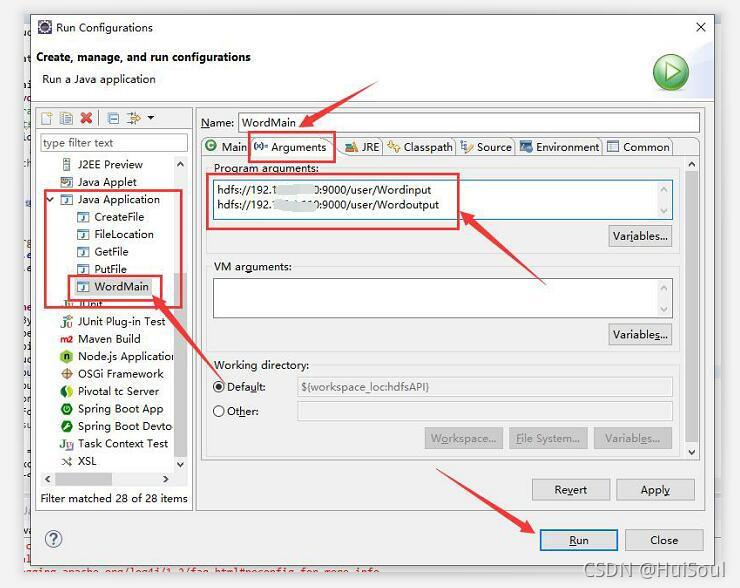
設定運行引數↓
輸入路徑:hdfs://linux主機IP地址:9000/user/wordinput
輸出路徑:hdfs://linux主機IP地址:9000/user/wordoutput
然后點擊運行↓
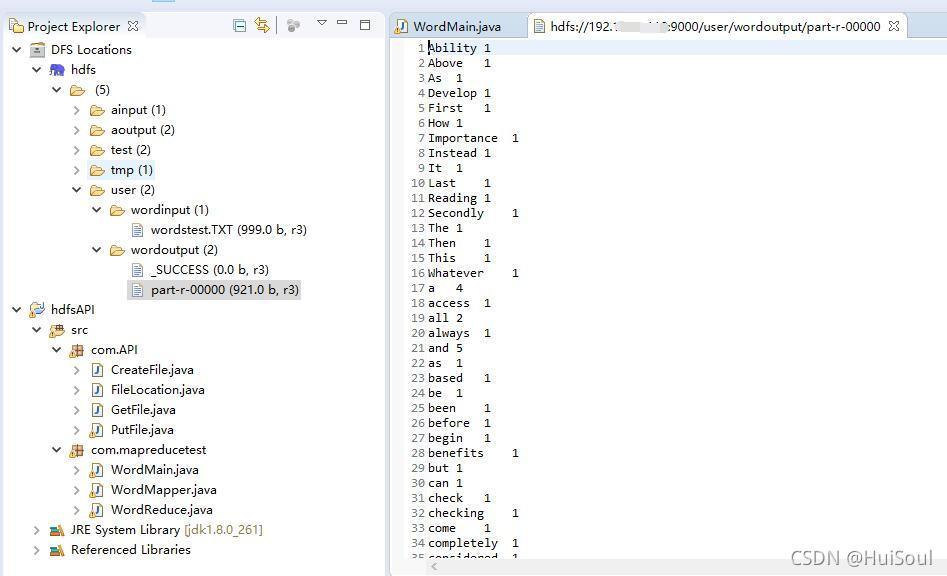
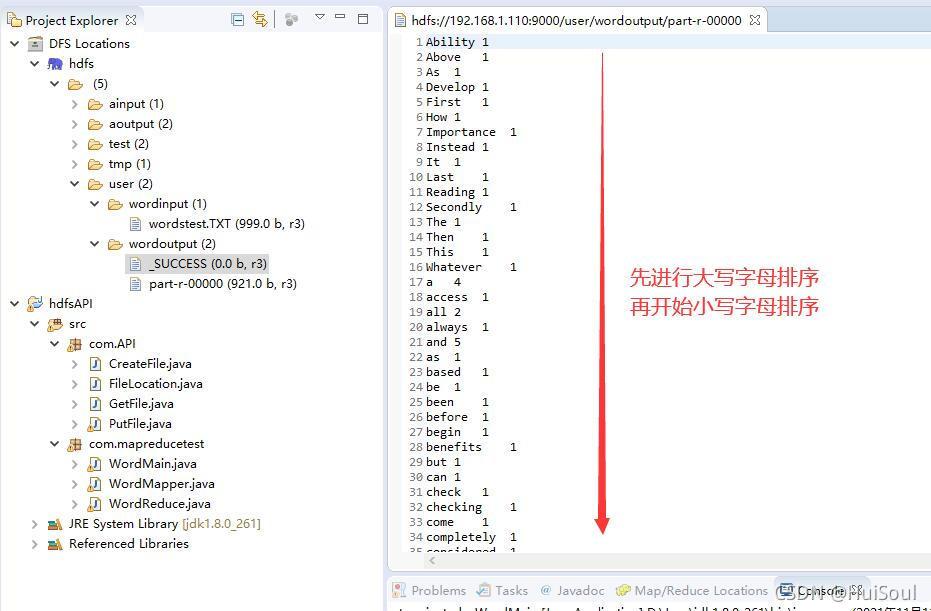
單詞排序統計結果↓
Tips:如果運行后,終端報錯:java.io.IOException: (null) entry in command string: null chmod 0700 E:\tmp\hadoop\mapred\staging\te
解決方法:在C:\Windows\System32 目錄下添加hadoop.dll 檔案即可,hadoop.dll檔案github下載地址
結果分析:我們打開 part-r-00000 這個檔案,里面保存的是統計排序后的運行結果,能看到檔案中的單詞已從大寫到小寫和a到z的規律進行排序好了↓
本次分享到此結束,謝謝大家閱讀!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356073.html
標籤:其他