原始碼下載鏈接
鏈接:百度網盤 請輸入提取碼
提取碼:jvfk
B站視頻操作程序
Hadoop實戰——對單詞文本進行統計和排序_嗶哩嗶哩_bilibili
目錄
一、前提準備作業
啟動hadoop集群
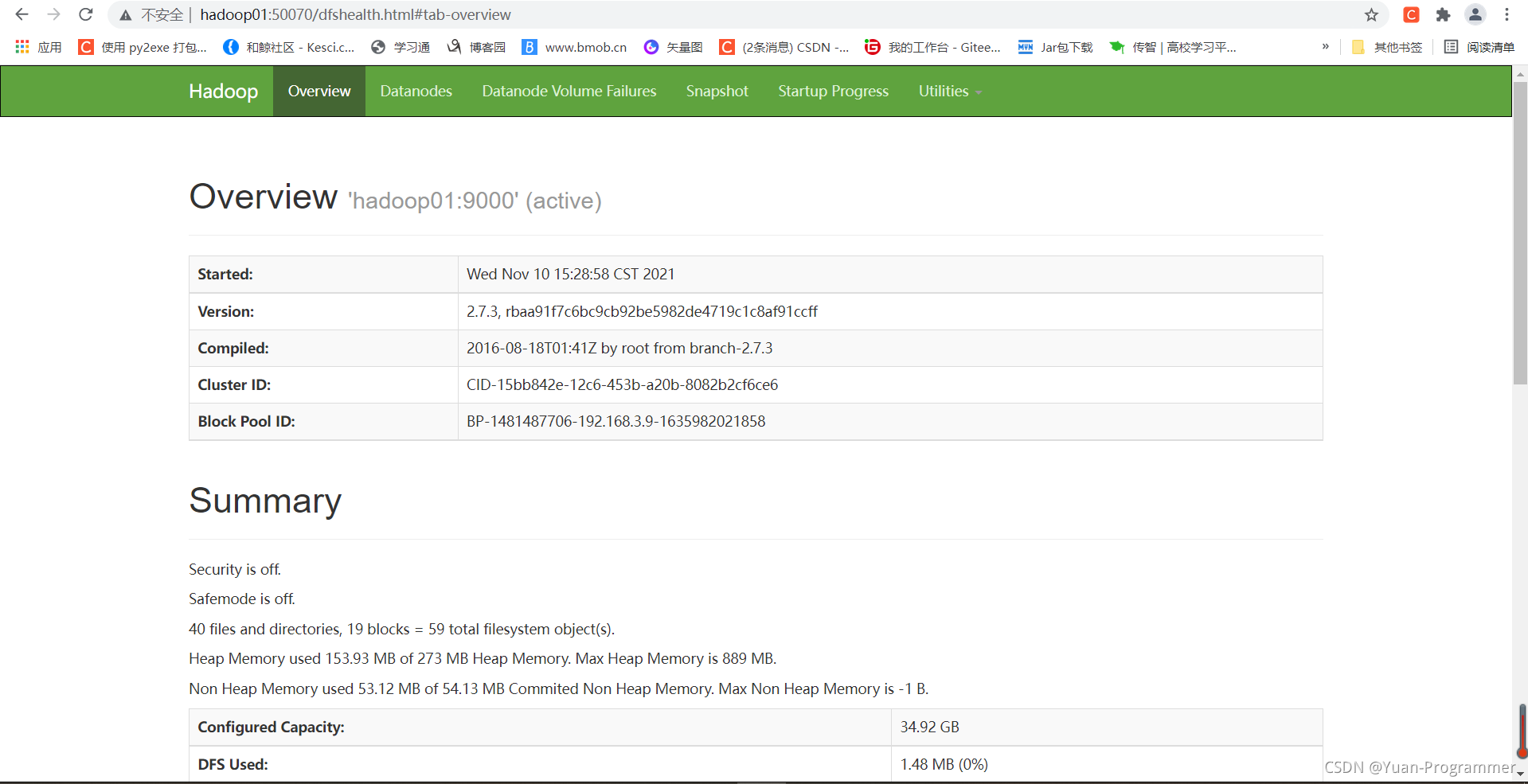
windows可以訪問
二、整體流程
三、核心代碼講解
四、生成jar包上傳
五、運行程式
一、前提準備作業
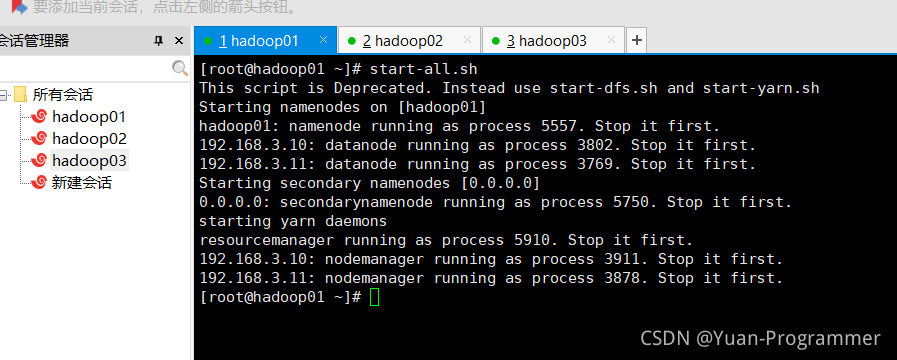
啟動hadoop集群
必須已經成功搭建好了hadoop集群,打開主節點和子節點全部虛擬機,啟動hadoop
windows可以訪問
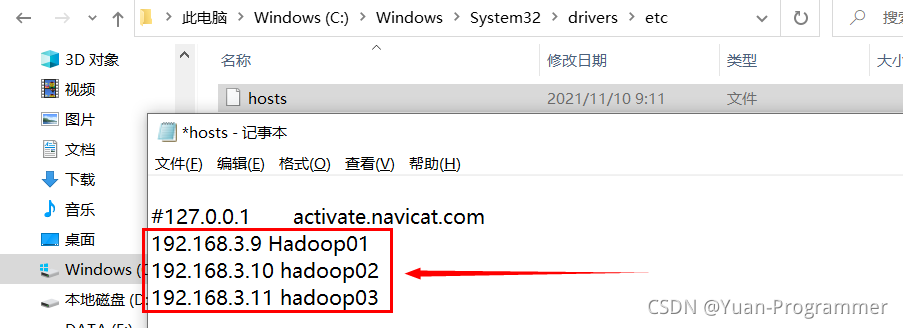
關閉主節點虛擬機的防火墻,在windows的hosts檔案添加配置資訊
二、整體流程
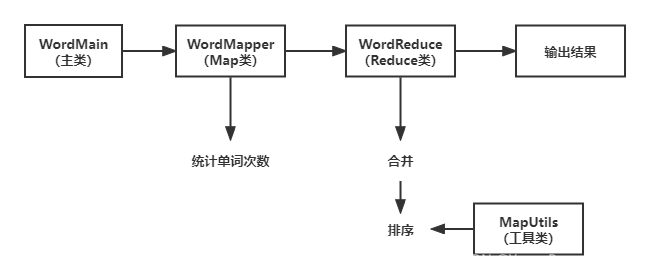
整體流程如下

程式內部執行程序如下
三、核心代碼講解
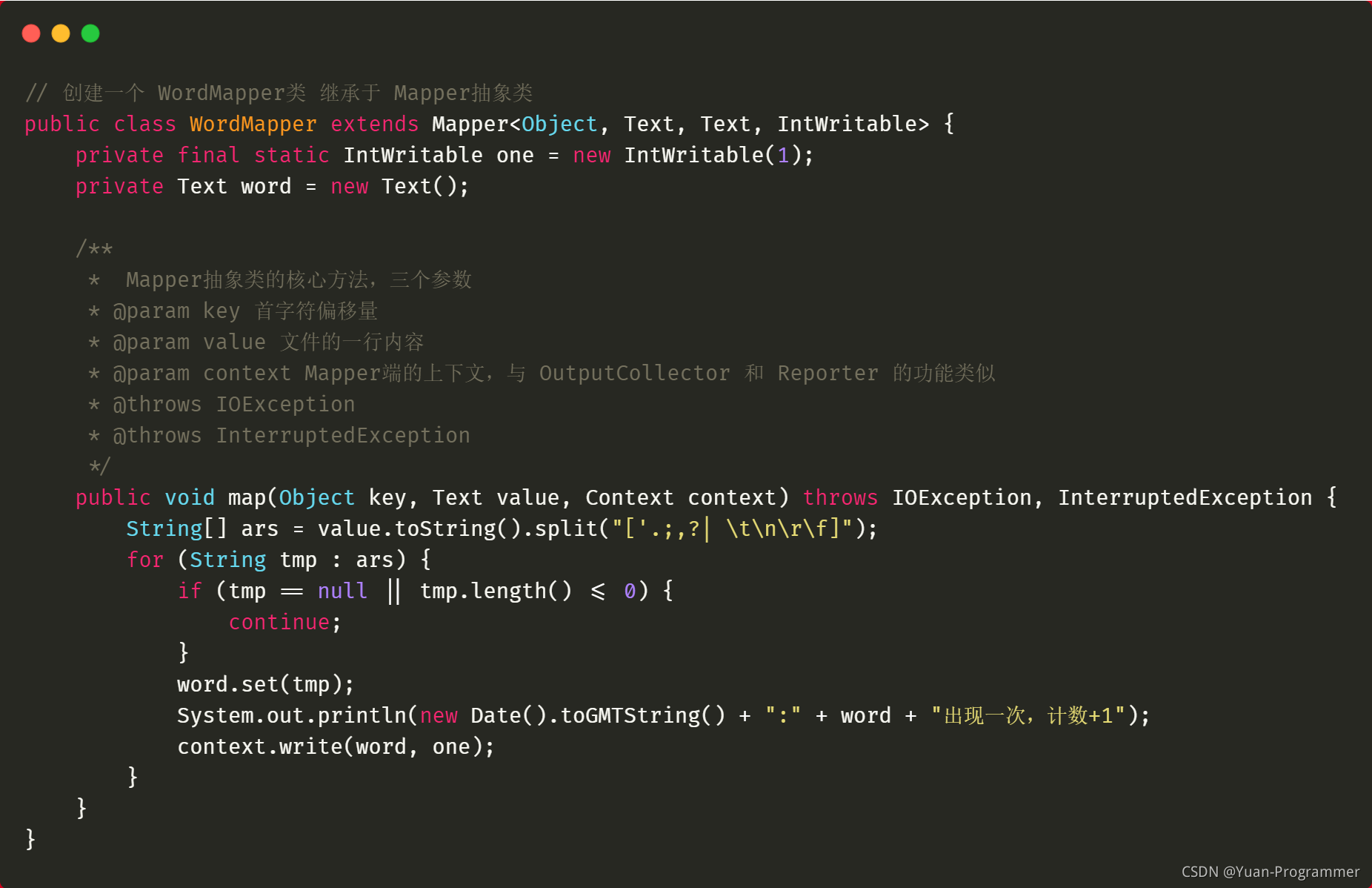
Mapper類
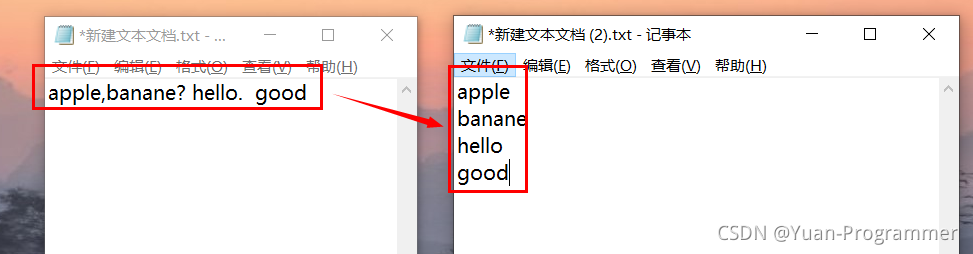
將單詞文本進行切割,切割成一個個的單詞,寫入到背景關系中
(1)按行讀取,通過split函式進行切割,將切割出來的一個個單詞放到陣列ars中
(2)遍歷陣列ars,將存在的單詞資料存盤到word中,然后將word寫入到context背景關系(使Redcue程式能訪問到資料)
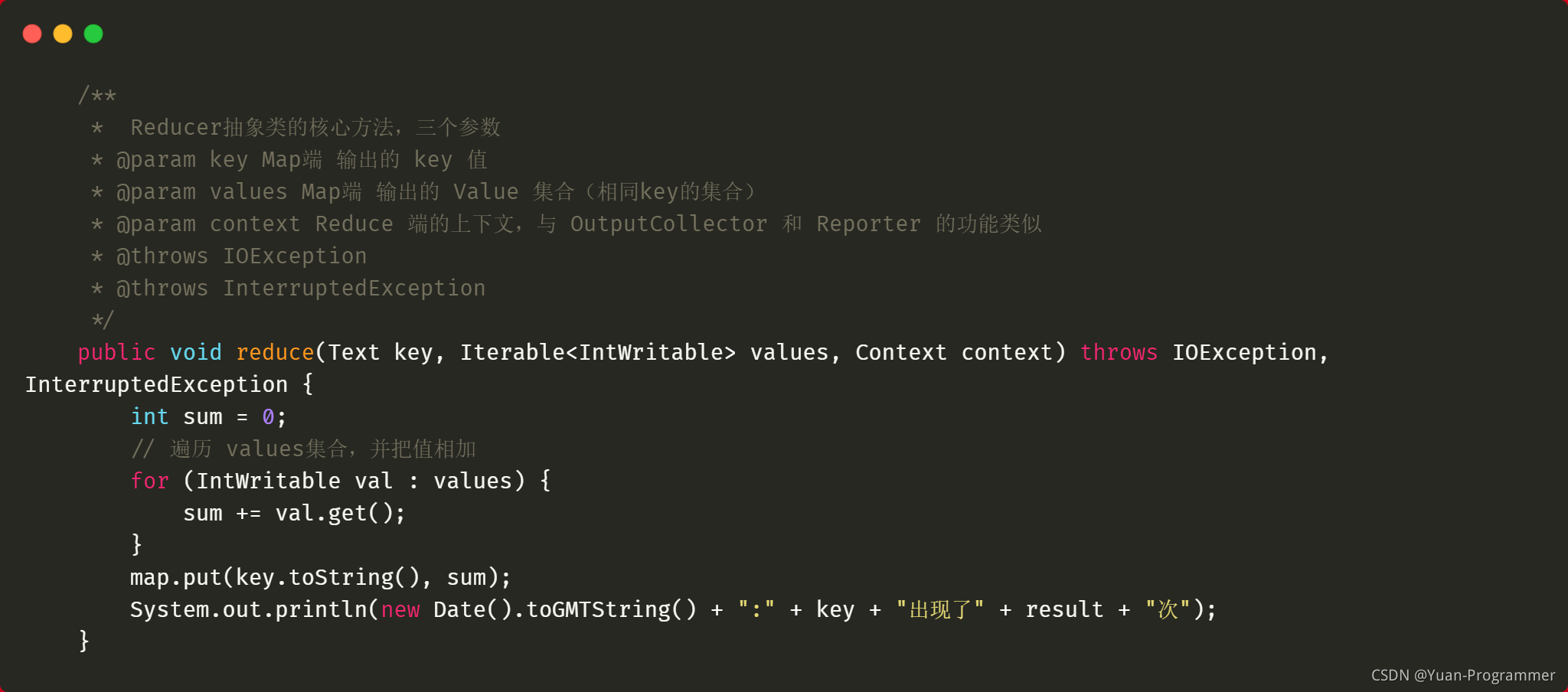
Reduce類(部分代碼展示)
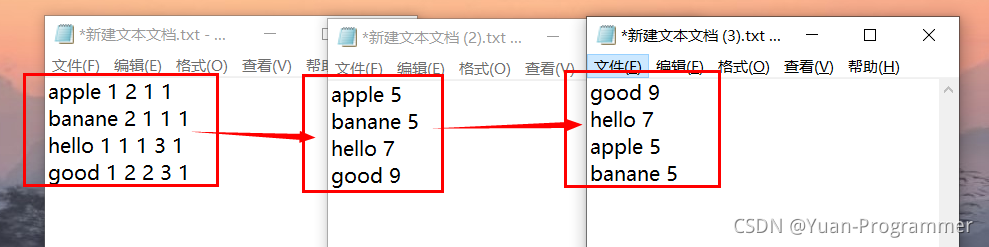
(1)將每個單詞統計次數結果進行求和合并,寫入到map集合里
(2)呼叫Utils工具類的sortValue方法對map集合進行排序
(3)遍歷排序好的map集合,依次寫入到context背景關系中
Utils類(對map進行排序)
(1)繼承Comparable類,復寫compare方法
(2)通過map<k,v>集合的value(也就是單詞次數)進行排序
(3)將排序好的map回傳
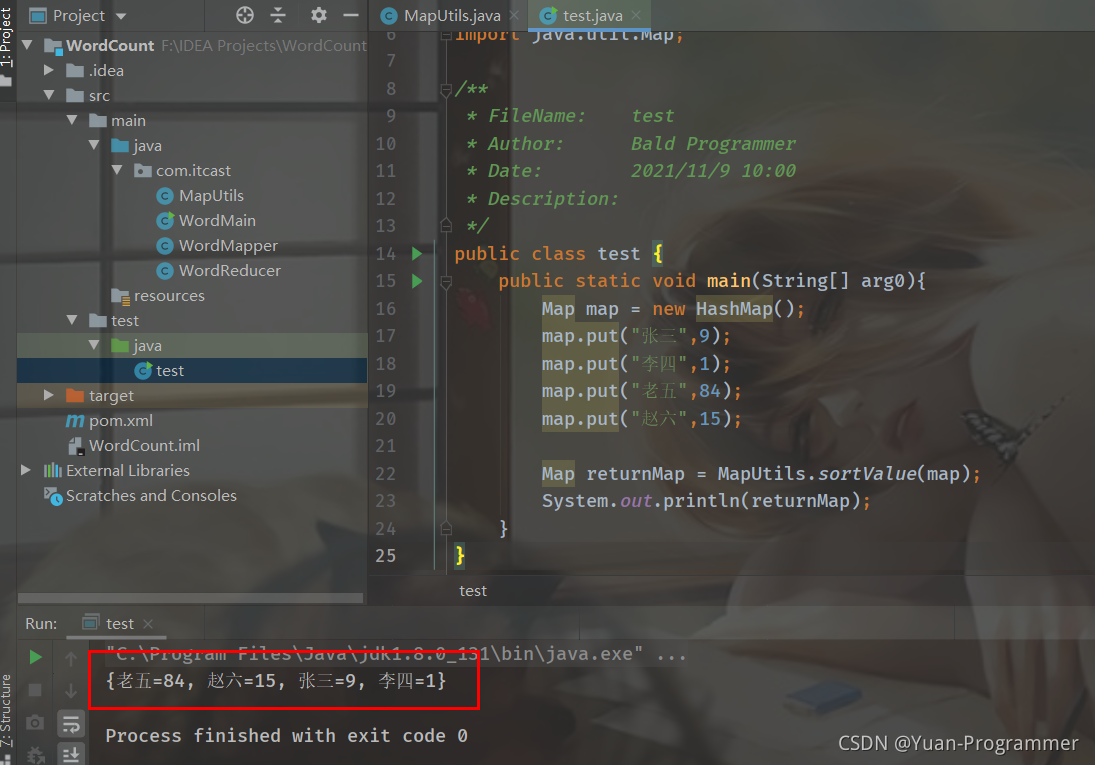
新建一個測驗類測驗一下,可以看到排序OK
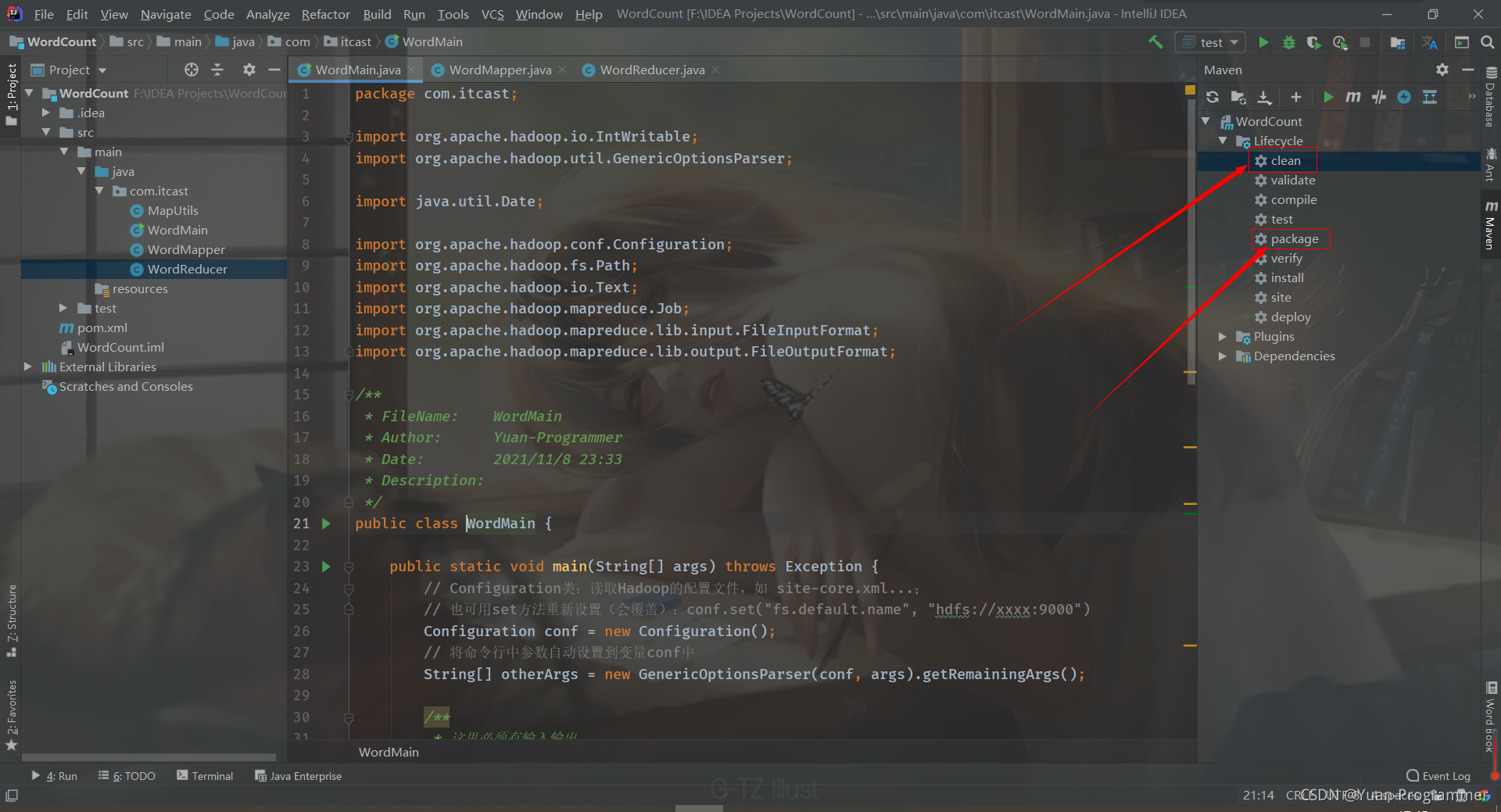
四、生成jar包上傳
先點擊右邊的 clean 清理一下,然后點擊 package 生成打包jar包
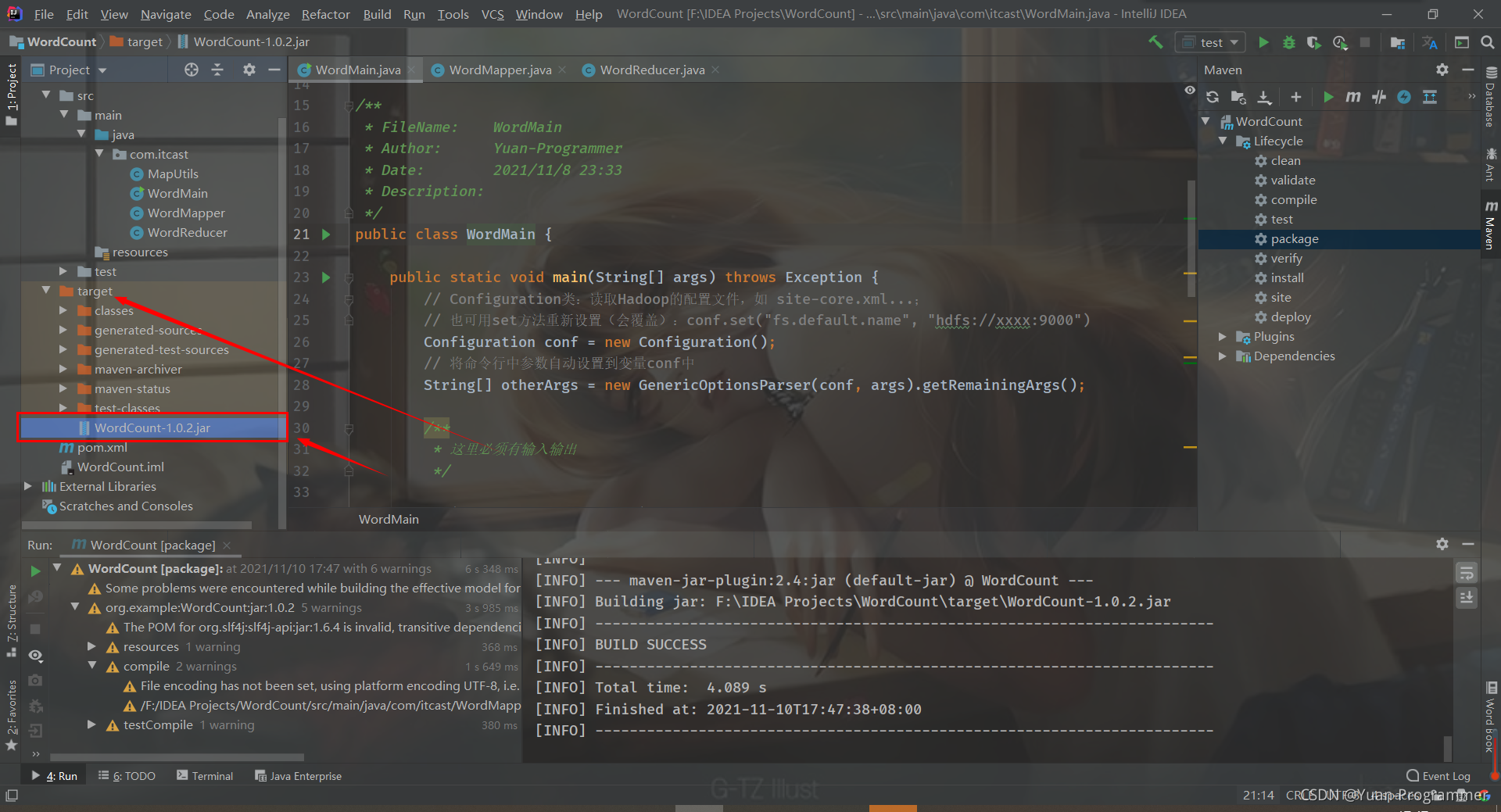
運行完畢,會在左邊生成一個 target 的檔案夾,展開可以看到生成jar包程式
選中jar包,右鍵選擇復制,粘貼到桌面
打開 winscp 工具,連接主節點虛擬機,將剛剛粘貼在桌面的jar包拷貝到虛擬機里(路徑自己選,知道在哪就行)
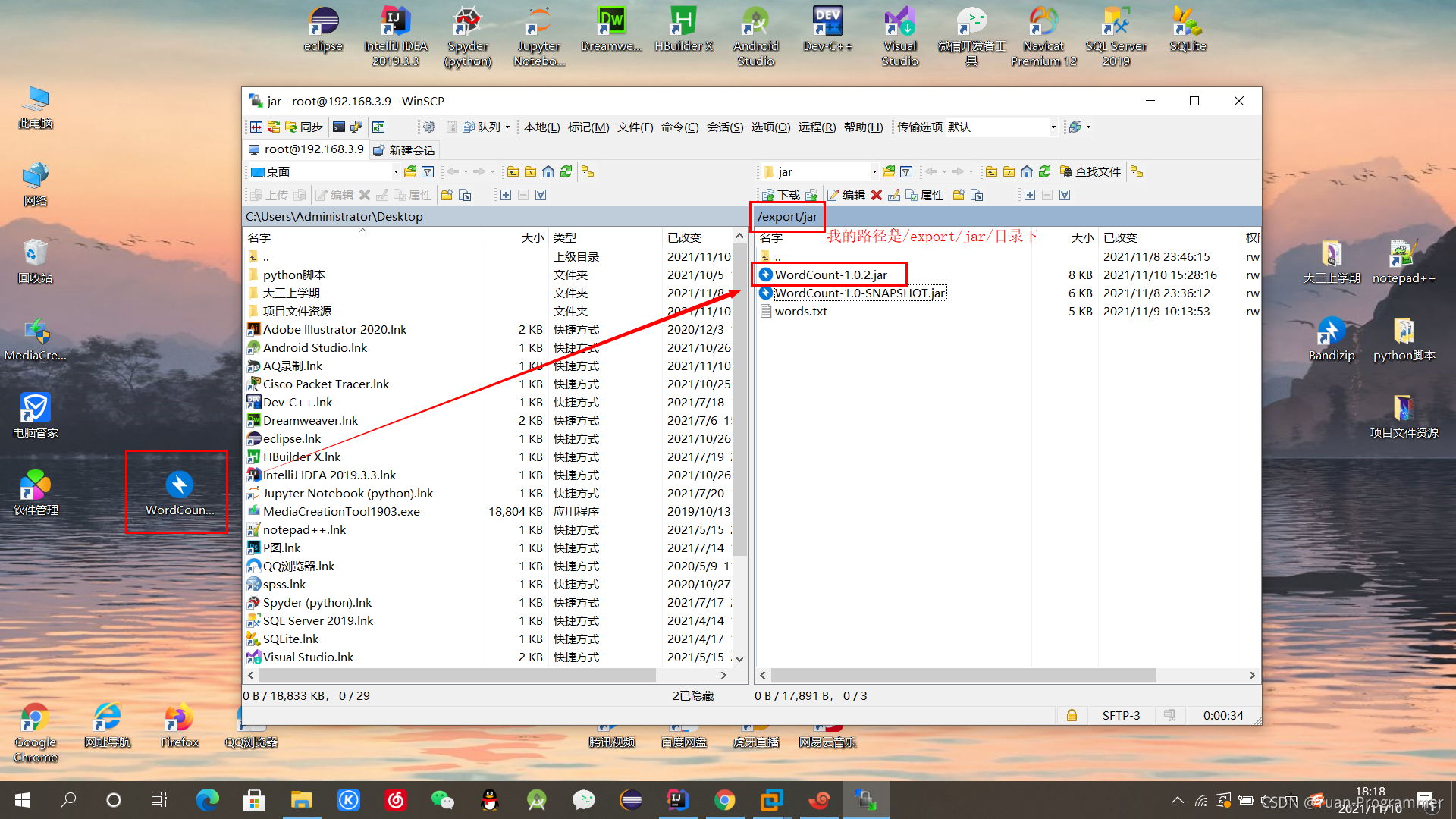
打開虛擬機,跳轉到剛剛復制的路徑目錄下,可以看到已經拷貝進來了
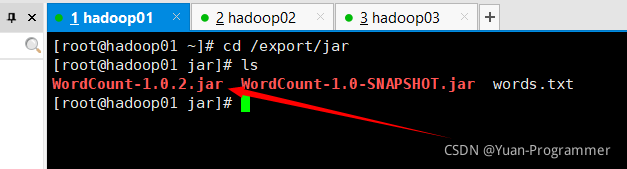
五、運行程式
(1)創建單詞文本并上傳
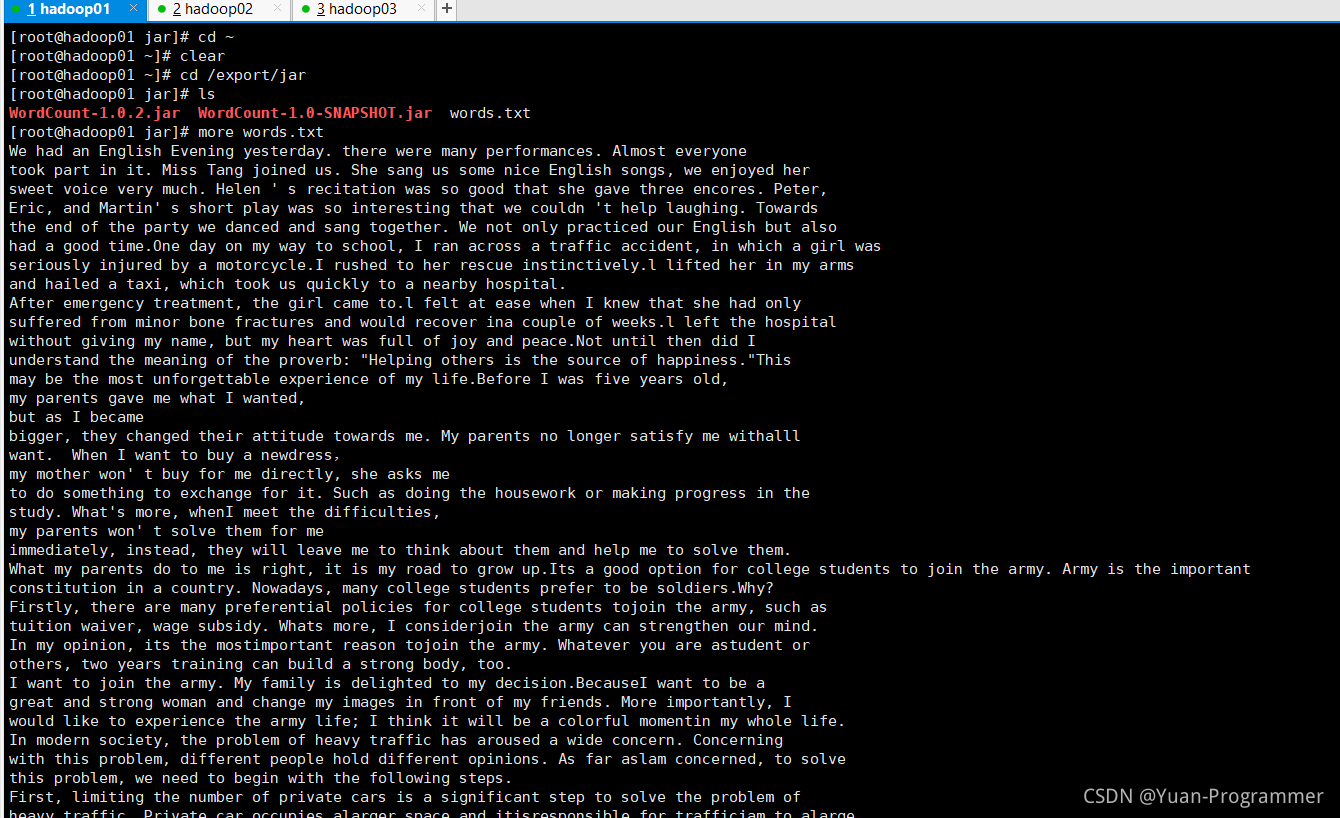
在下面可以看到有一個words.txt文本,這是我之前創好的
more指令查看文本,可以看到文本里有很多的英文單詞
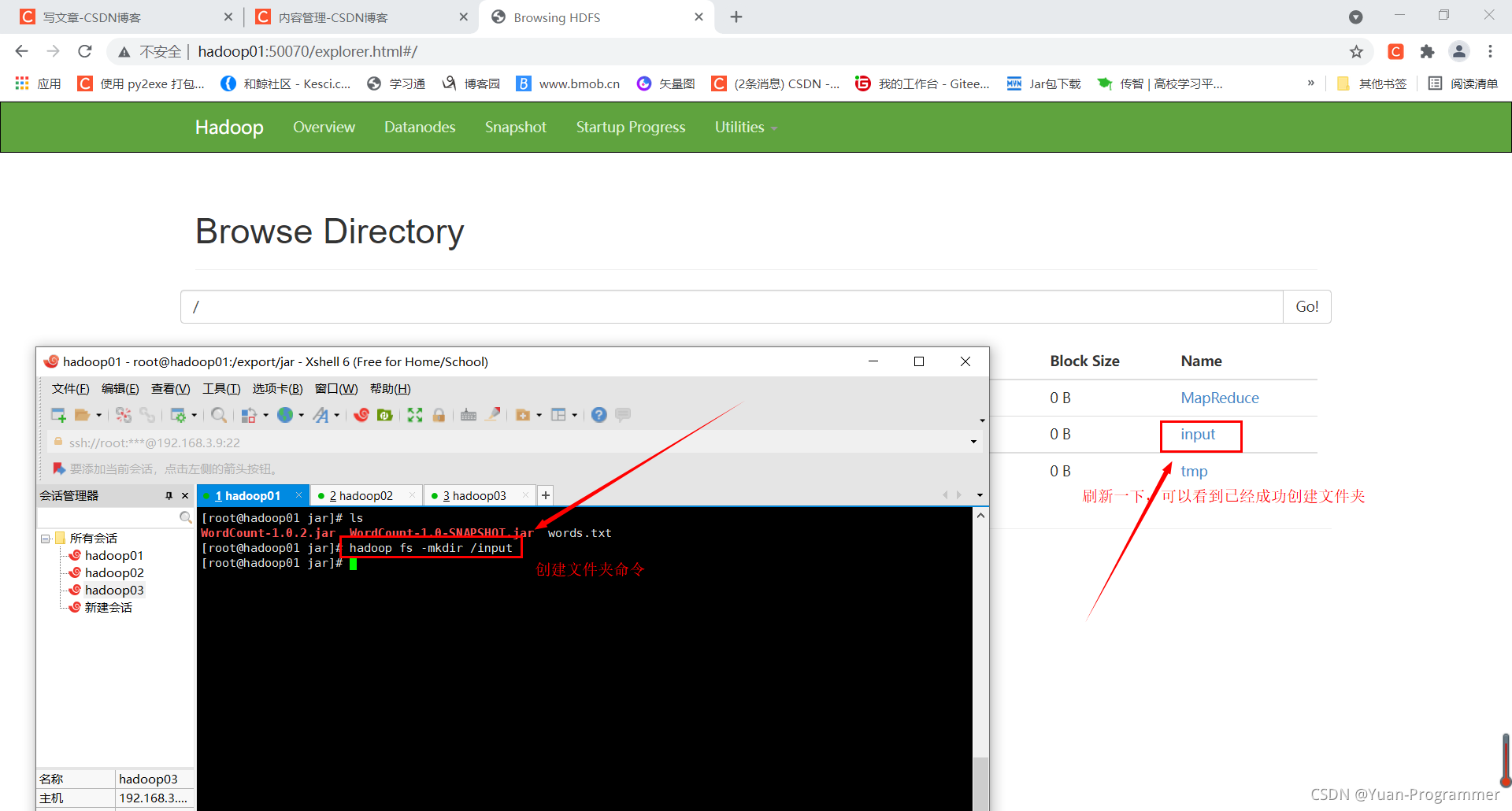
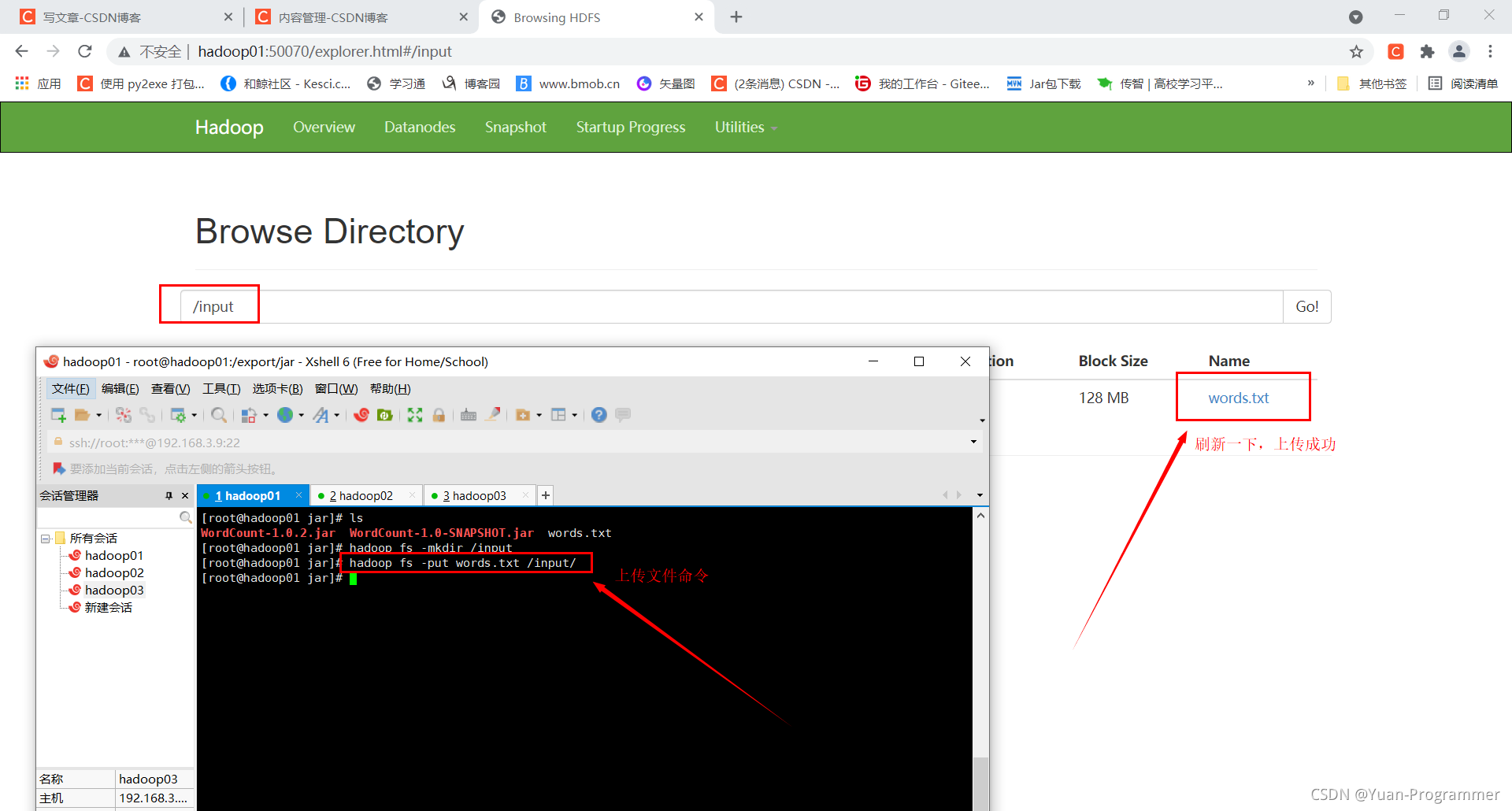
(2)上傳到HDFS檔案系統
首先創建一個檔案夾存放統計前的單詞文本(words.txt)
將單詞文本(words.txt)上傳到剛剛創建的檔案夾下
執行jar包程式,hadoop jar jar包名稱 包名稱+主類名 輸入路徑 輸出路徑
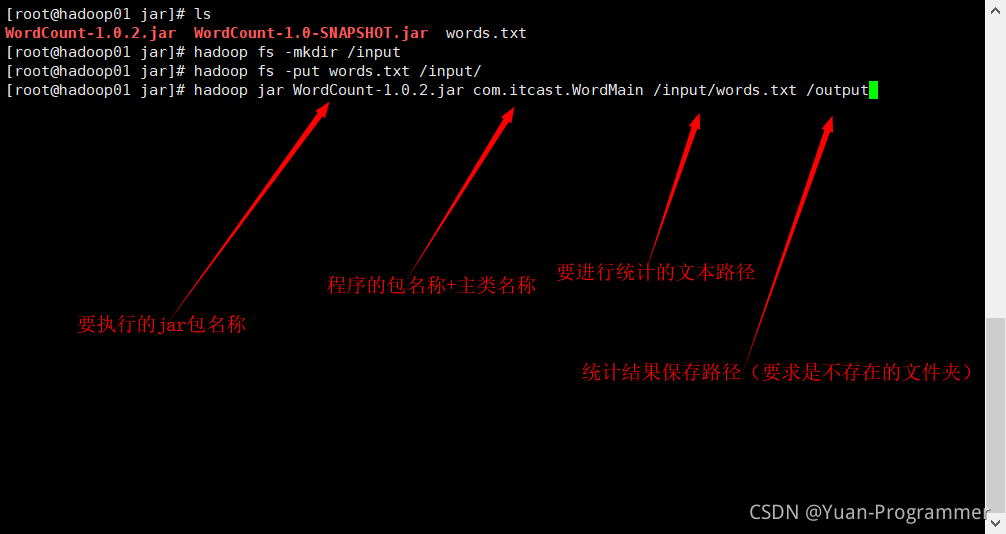
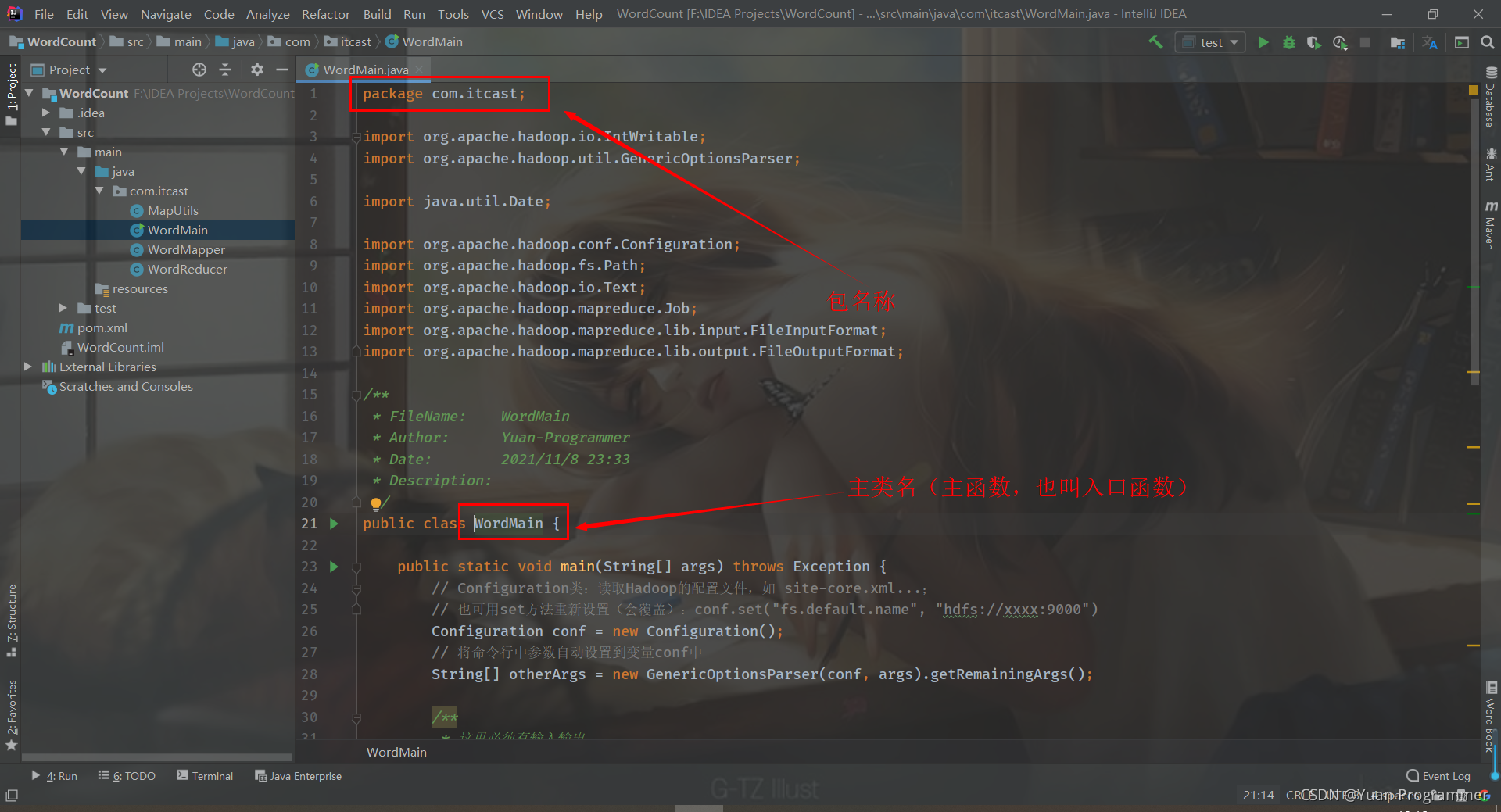
包名稱+主類名如下
回車執行命令,等待提示運行完畢,運行結束后
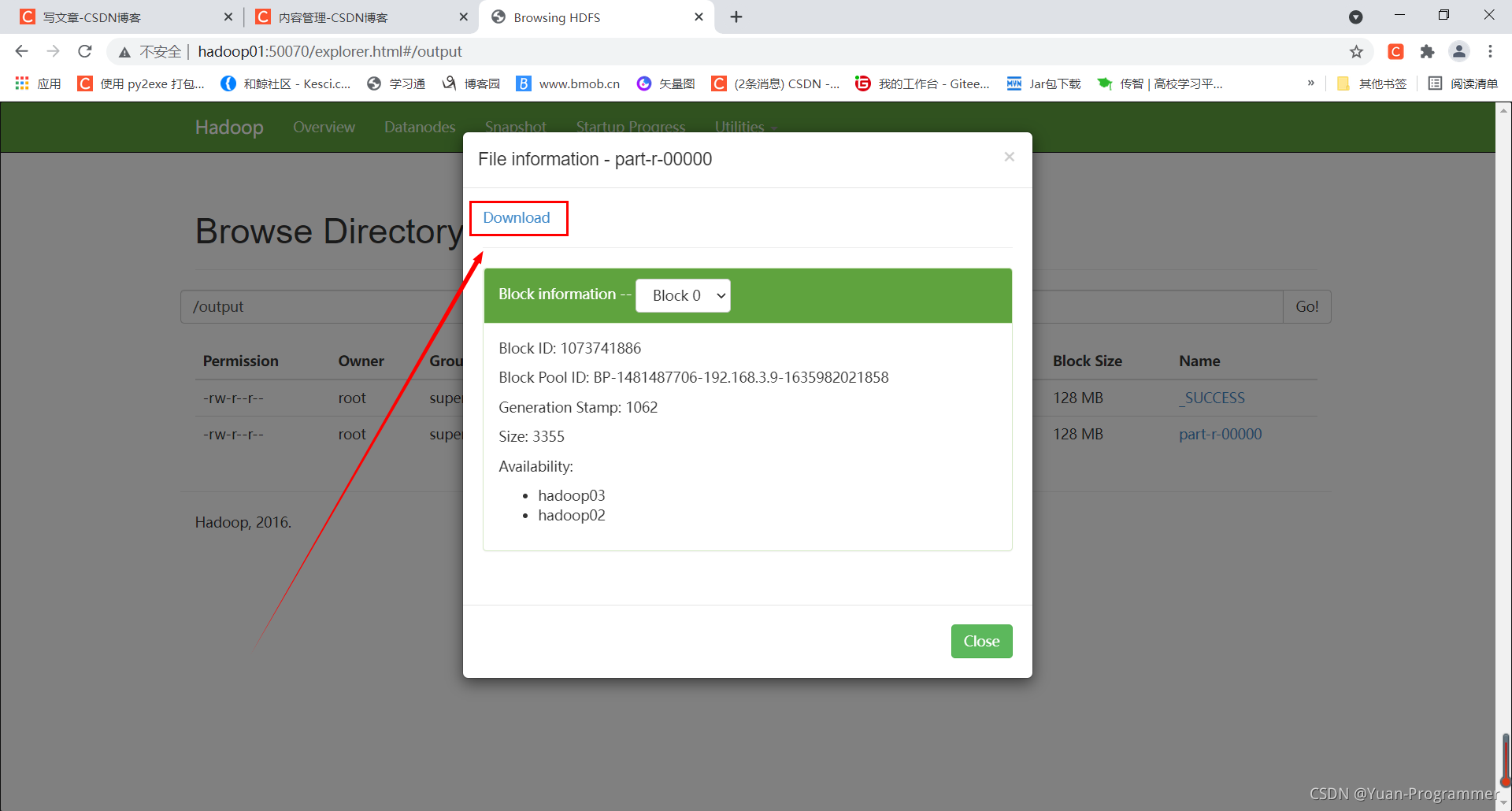
打開HDFS檔案系統的output目錄下,就能看到輸出結果,打開檔案點擊Download下載
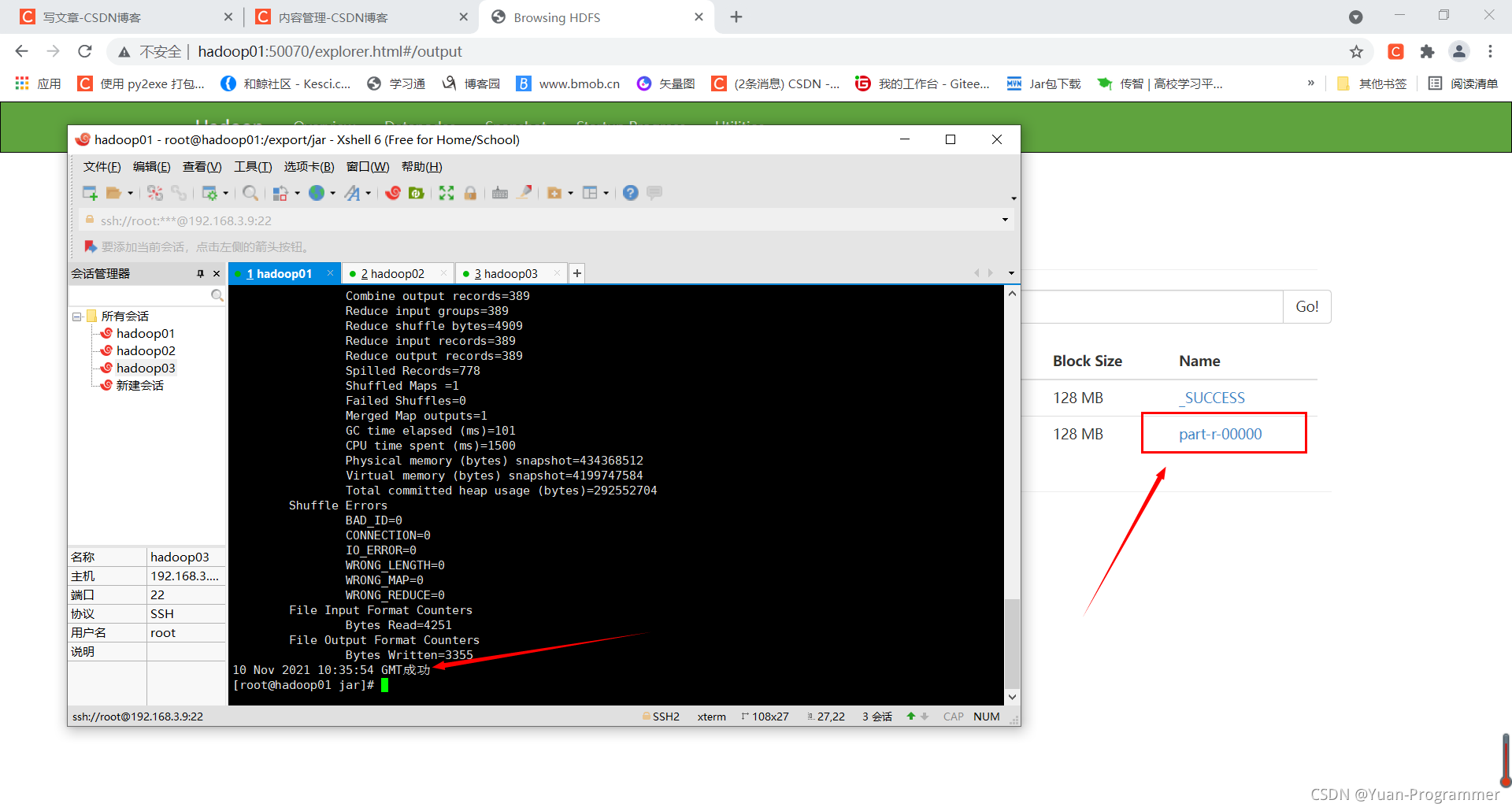
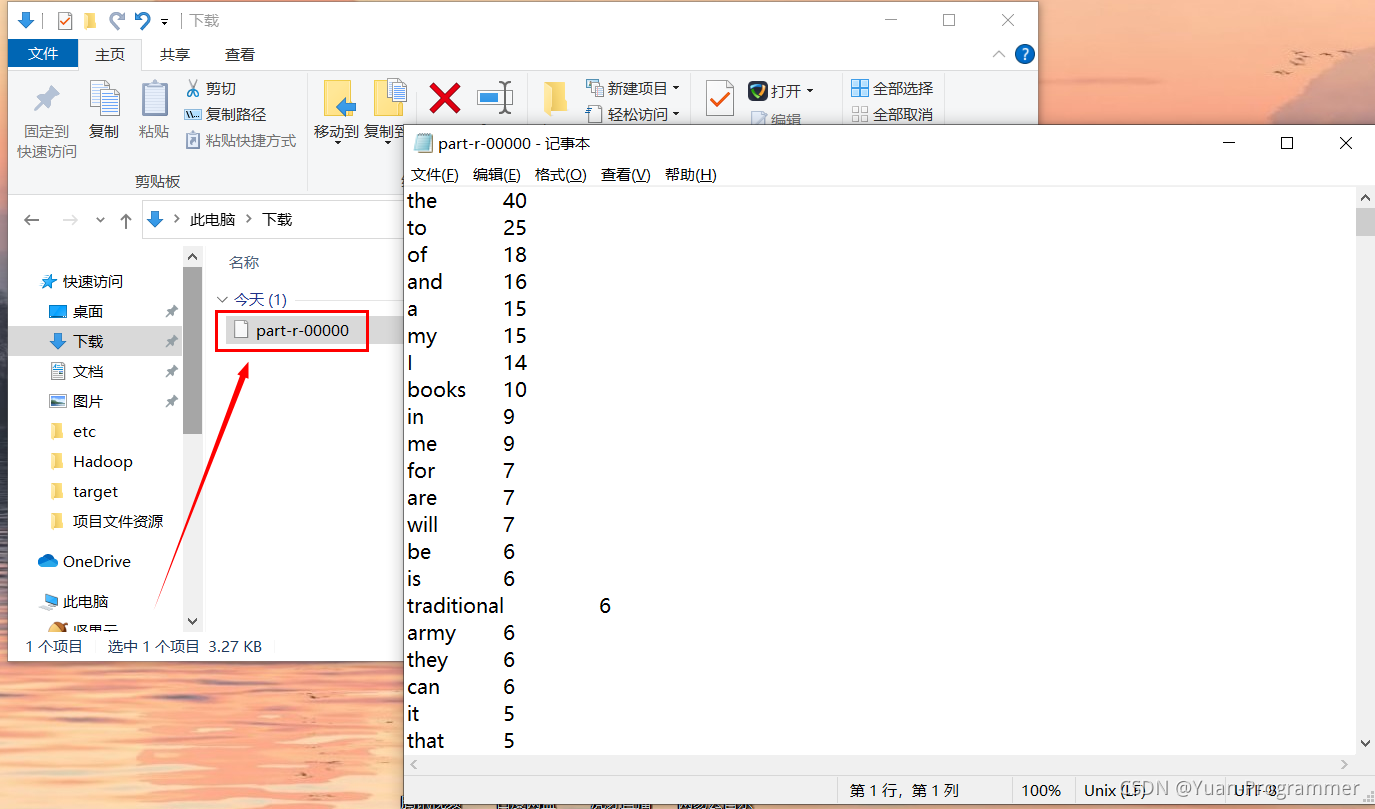
以文本方式打開,可以看到已經對單詞進行了統計并且對其進行降序操作
- 本次文章分享就到這,有什么疑問或有更好的建議可在評論區留言,也可以私信我
- 感謝閱讀~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356077.html
標籤:其他