測驗業務需要:
1.現有a.xlsx
a.xlsx中有2個 sheet,分別是 a的data1,a的data2,

a的data2,如下圖
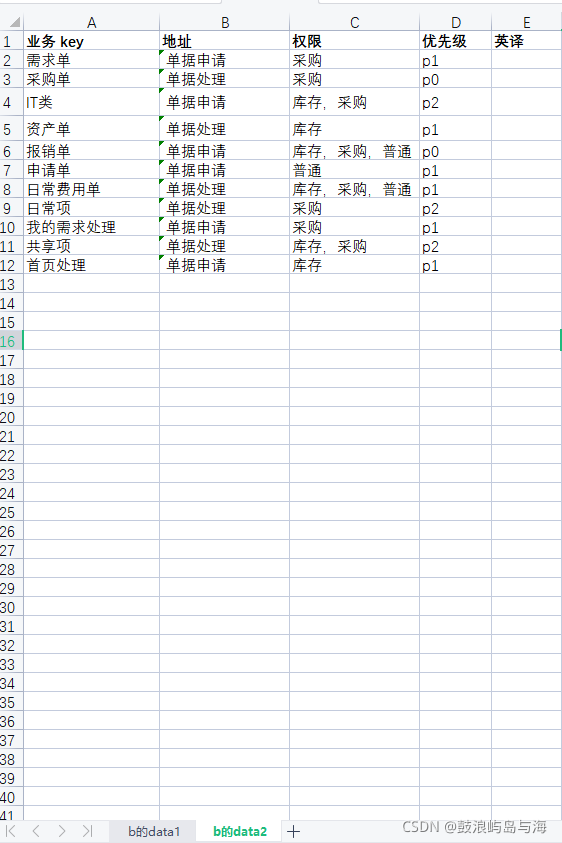
2.a.xlsx的 data1 和data2 都有A列,且A列資料值有部分是一樣的
現需要將 data1和data2匹配生成c.xlsx的data3,
匹配規則:把data2復制到c.xlsx的data3檔案中,data3中的E列值取值是 data1 和data2 都有A列匹配對應的data1的E列值
實作:
def test_data4():
file1 = "data/a.xlsx"
# 打開a.xlsx
wb1 = xlrd.open_workbook(filename=file1)
# a.xlsx要匹配的列索引
hid_index1 = 0
# a.xlsx目標資料列索引
target_index1 = 1
# a.xlsx的sheet=a的data1
sheet1 = wb1.sheet_by_name('a的data1')
# sheet=a的data1 的總行數
rowNum1 = sheet1.nrows
# sheet=a的data1的sheet的總列數
colNum1 = sheet1.ncols
# sheet=a的data1 要匹配的列索引( 就是sheet=a的data1中的B列)
hid_index2 = 1
# sheet=a的data2 目標資料列索引( 就是sheet=a的data2中的E列)
target_index2 = 4
# 獲取表格sheet=a的 data2
sheet2 = wb1.sheet_by_name('a的data2')
# sheet=a的 data2 的總行數
rowNum2 = sheet2.nrows
# sheet=a的 data2的總列數
colNum2 = sheet2.ncols
# xlwt準備生成一個新的檔案的sheet=b的data1
write_workbook = xlwt.Workbook()
write_sheet = write_workbook.add_sheet('b的data1', cell_overwrite_ok=True)
for index2 in range(0, rowNum2):
for col_index in range(0, colNum2):
# 遍歷表2的每一行每一列,把對應的單元設定到新的檔案中,即復制了表2的資料
write_sheet.write(index2, col_index, sheet2.cell_value(index2, col_index))
# 在遍歷列程序中,如果碰到目標資料列索引.即需要補充的欄位,則進行遍歷表1,判斷的id索引匹配
if col_index == target_index2:
for index1 in range(1, rowNum1):
hid1 = sheet1.cell_value(index1, hid_index1)
if hid1 == sheet2.cell_value(index2, hid_index2):
write_workbook,style_list = copy2(wb1)
xf_index = sheet2.cell_xf_index(1, rowNum1)
# 如果兩個表的id相同則把表1的單元內容設定到表2對應的單元格
write_sheet.write(index2, col_index,
sheet1.cell_value(index1,target_index1),style_list[xf_index])
# 保存新的檔案
write_workbook.save("data/b.xlsx")
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356093.html
標籤:其他