本教程系列將從模型訓練開始,從0開始帶領你部署Yolov5模型到jetson nano上
這是本系列的第一部分內容

1.Yolov5介紹
Yolov5是一種目標檢測演算法,是ultralytics公司在yolov4的基礎上加以改進誕生的,本教程基于讓小白從0開始學會訓練自己的yolov5模型,從而感受到人工智能的樂趣,對一些演算法的細節不做過多討論,并對訓練環節做了簡化處理,不嚴謹的地方還望各位技術大佬諒解,
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLO V5 在性能上稍弱于YOLO V4,但是在靈活性與速度上遠強于YOLO V4,在模型的快速部署上具有極強優勢,雖然現在的研究成果還達不到“下一代”YOLO的高度,但是被稱作YOLO V4.5或者Above YOLO 是沒問題的,其次還有人認為YOLO V5只是YOLO V4的Pytorch實作加上調參結果,你在沒有實際閱讀代碼和運行之前發表這樣的評論,是極不負責任的,
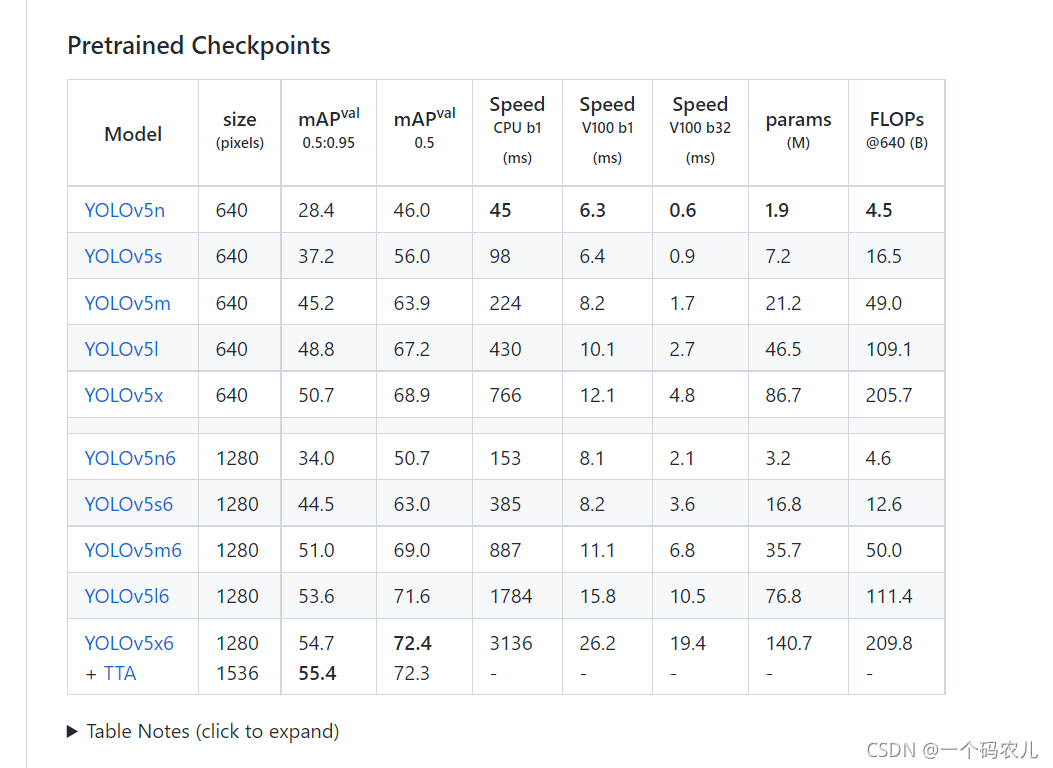
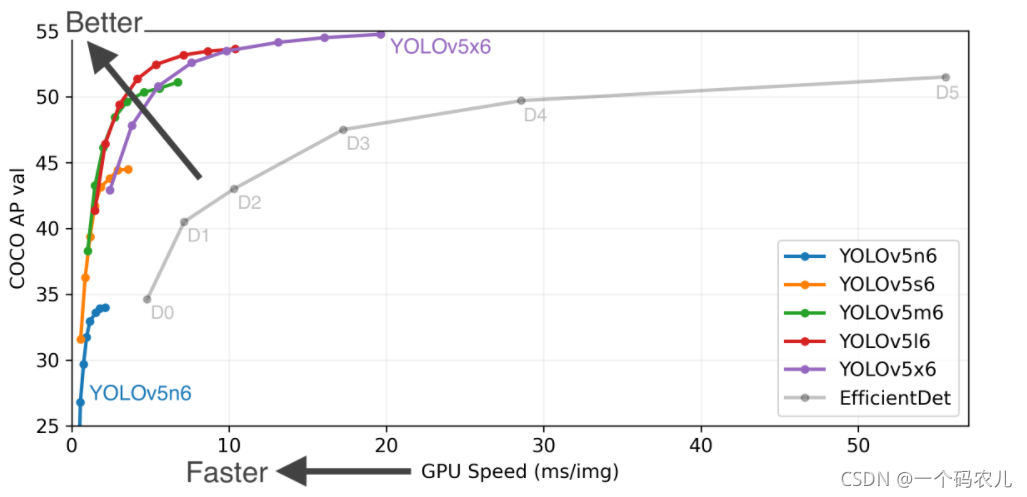
從上圖的結果可以看出,YOLO V5確實在物件檢測方面的表現非常出色,尤其是YOLO V5s 模型140FPS的推理速度非常驚艷,
2.資料集制作
2.1公開資料集
國內外有很多公開很優秀的資料集,很多都是開源且免費的,這里推薦幾個資料集的網站,排名不分先后
1.帕依提提
2.Mo資料中心
3.和鯨社區
4.AI studio 百度
2.2 制作自己的資料集
當然,很多情況下我們需要制作自己的資料集滿足相應的需求,資料集的制作會占用大量的時間
2.2.1下載標注軟體
來到資料集標注工具Labelimg的官方releases網站
當然如果你進不去的話,我這里提供一份1.8.1版本的軟體
鏈接:https://pan.baidu.com/s/1ZeJaTafbZv965wFLYziHgw
提取碼:1234 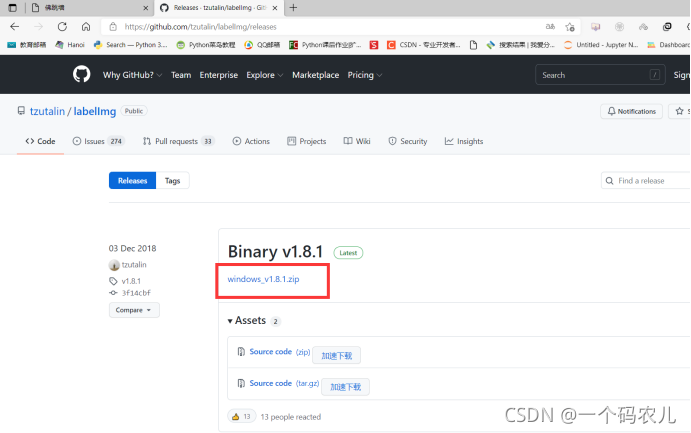
點擊下載最新的windows版本
2.2.2標注資料集
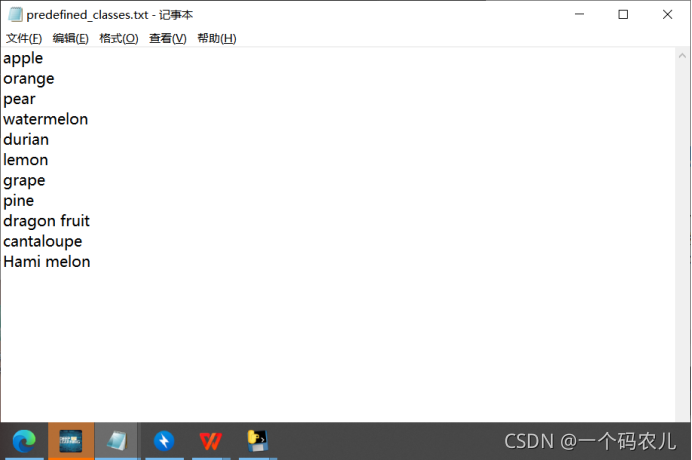
解壓后來到目錄下,依次點開data->predefined_classes.txt


打開后可以更改你的種類名稱,從上到下依次更改
回到程式目錄,點開labelimg,筆者有遇到點不開的情況(windows11可能用不了),此時建議更換一臺設備或者管理員模式打開
選擇圖片資料目錄
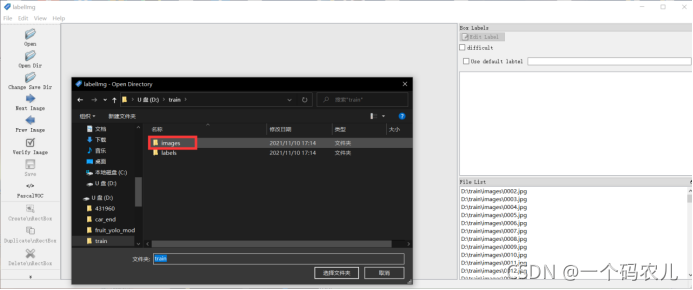
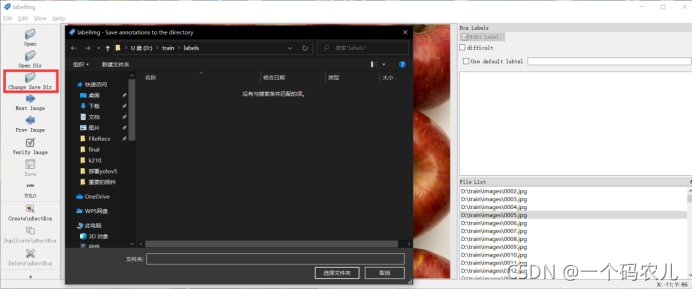
隨后會彈出讓你選擇標簽目錄,如果沒有彈出也可以點擊Change Save Dir 選擇標簽目錄
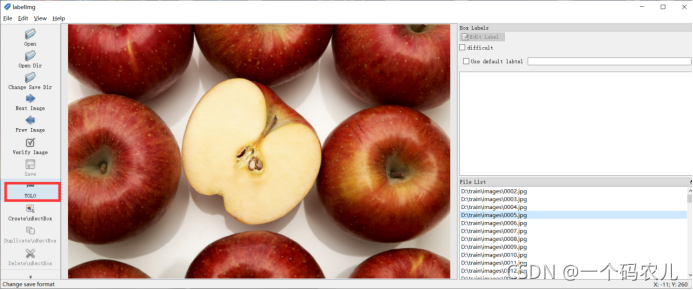
一定記得單擊此處使其為YOLO,保證標注檔案為TXT格式的,以此簡化資料集格式的復雜程度
單擊Create RectBox
也可以在英文輸入下按W,框選目標物品,在一旁的小視窗中選擇目標種類的名稱,點擊OK
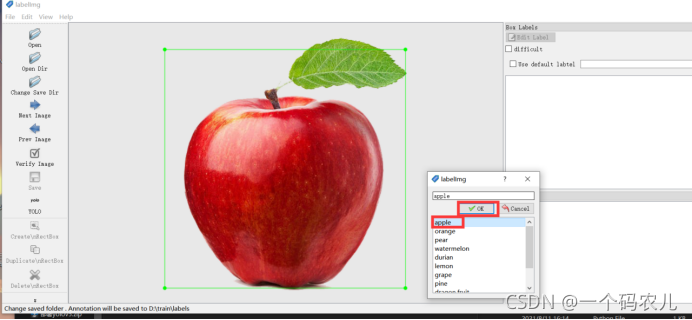
重復上述步驟,直到完成所有資料的標注(這是一個漫長的程序,如果是一個團隊可以幾個人輪著來制)
把所有的資料集都準備好,保證目錄下包含imgages(圖片)、labels(對應標簽)、yaml檔案

Yaml檔案的簡單格式如下:
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ./images #訓練集
# number of classes #類別數量
nc: 11
# class names
names: ['apple','orange','pear','watermelon','durian','lemon','grape','pine','dragon fruit','cantaloupe','Hami melon'] #種類有哪些
train就是訓練集的圖片目錄,nc是類別的數量,names是類別的名稱(要按標注的順序)
致此,資料集的制作完成,下一步就是訓練了
3.訓練模型
終于到了我們期待的一步了,很多時候我們的電腦都是windows的系統,但是作為未來的人工智能演算法工程師,Linux系統的操作是需要且必須掌握了,本訓練教程只對在Linux系統上訓練做詳細介紹,windows系統較為復雜,網上有更多優秀的教程
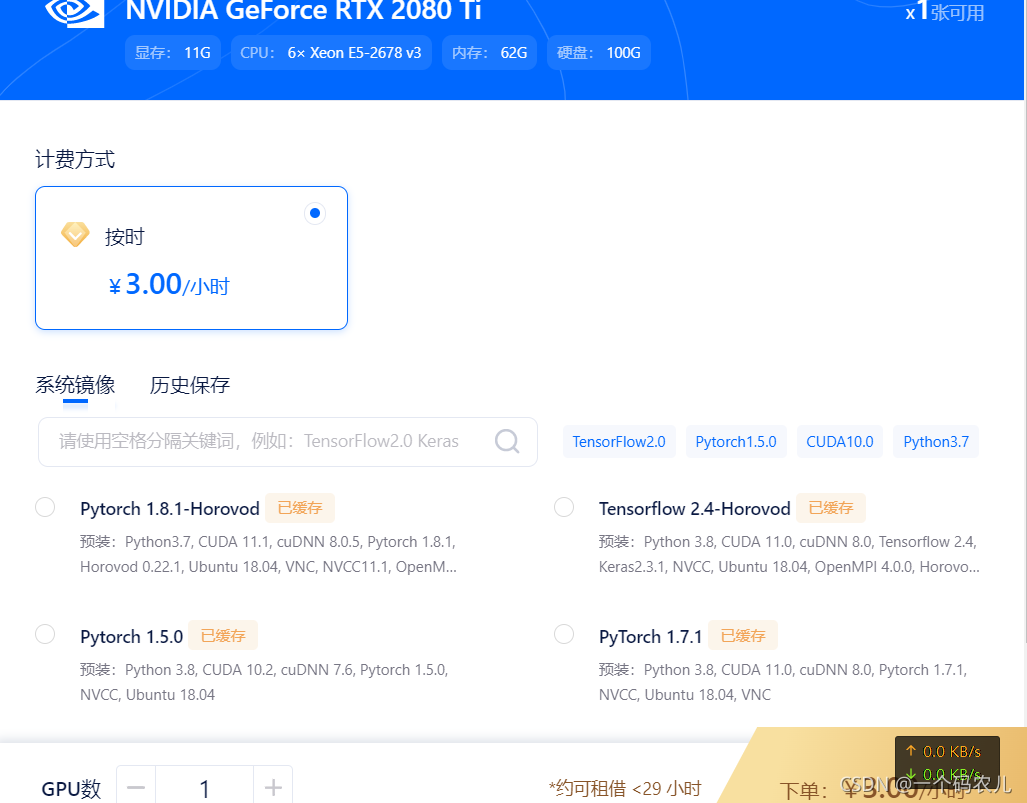
訓練模型需要好的GPU和配置好環境,筆者受不了訓練時主機那快要起飛的聲音,因此筆者更喜歡在云上訓練模型,平臺我推薦使用矩池云,K80的GPU一個小時只需要1元(晚上的時候使用GPU資源的人比較少),新人還送5元時長,更重要的是它自帶配置好的各種人工智能環境,如Tensorflow、Pytorch等(此處不是恰飯哈)
3.1下載Yolov5-5.0版本
此教程系列訓練模型的最終目的是為了部署到jetson nano上,因此需要利用tensorrtx做加速處理,題主所有tensorrt版本只更新到了yolov5-5.0,雖然新版本的yolov5已經更新到6.0,我們這里依然使用5.0版本的yolov5
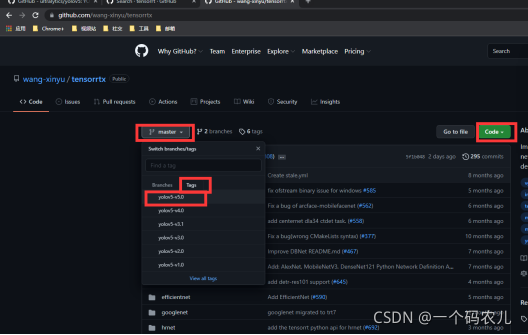
選擇Tags->v5.0下載yolov5代碼 5.0的代碼
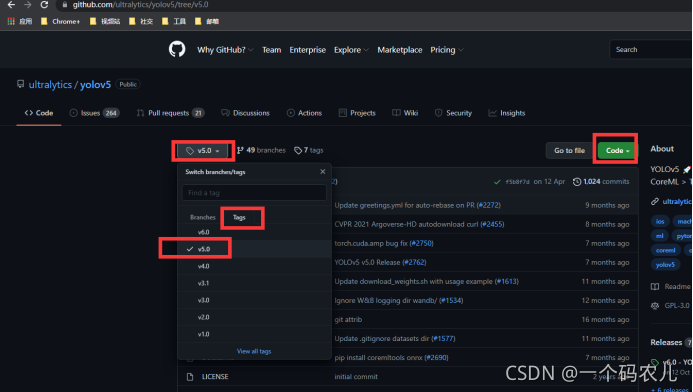
打開矩池云的JuypteLabr鏈接,此時你就已經進入你剛剛租用的服務器了
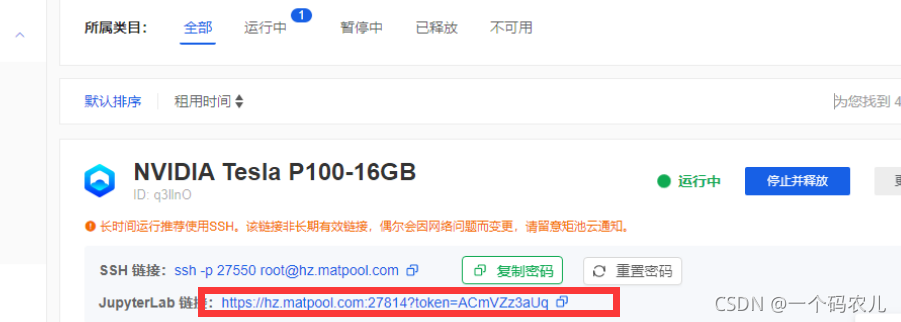
上傳剛剛下載的yolov5-5.0版本
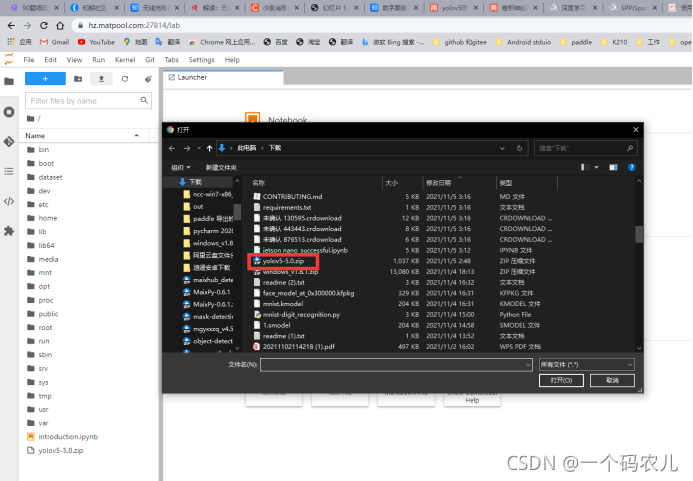
3.2配置訓練時各類需求
點擊左邊的+號,點擊terminal打開終端
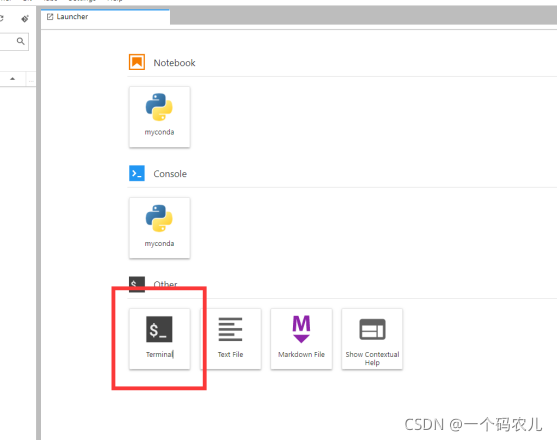
解壓上傳的yolov5-5.0檔案夾
unzip yolov5-5.0.zip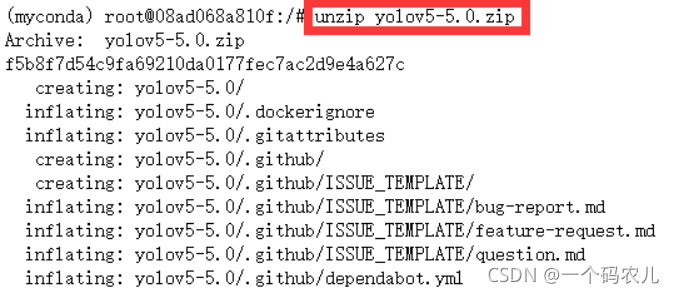
切到yolov5目錄
cd yolov5-5.0
安裝訓練所需要的依賴
pip install -r requirements.txt 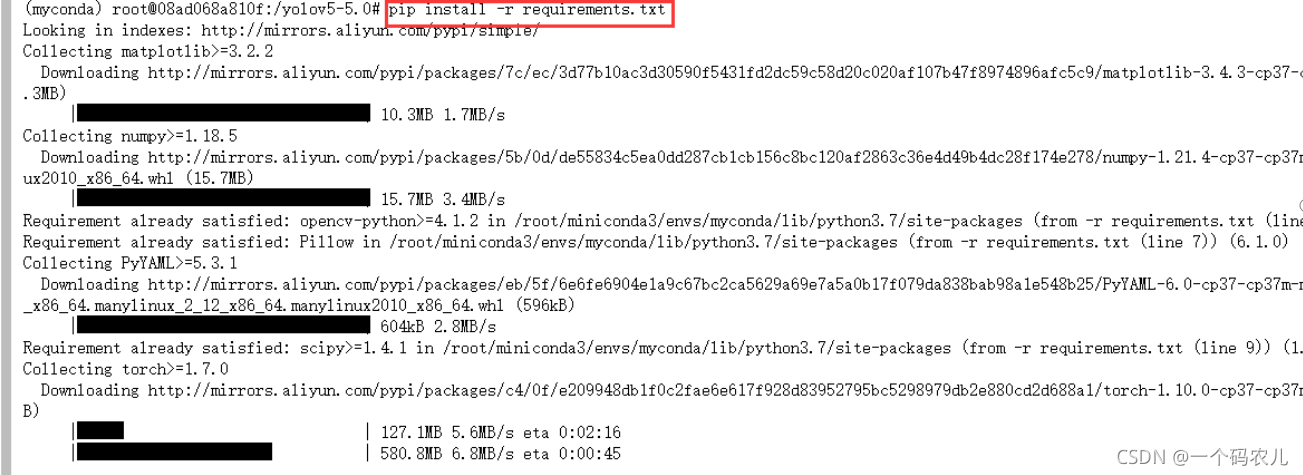
云上默認換了國內源,稍作等待下載完成

解壓資料集到目錄下,我已經提前將做好的資料集上傳到了網盤目錄/mnt
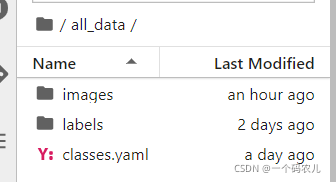
unzip /mnt/fruits_yolo.zip -d /all_data ![]()
此時根目錄的all_data下多出了三個檔案夾 ,就是我們之前整理好的資料集
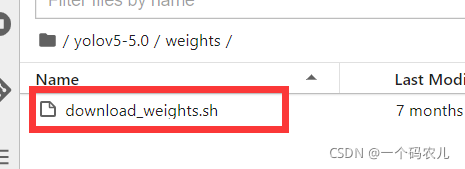
還有一步,由于我們是下載的yolov5-5.0版本,官網的GitHub上面已經把5.0版本的權重檔案給移除了,因此weights檔案夾里面是一個shell腳本,用于下載權重檔案,通常下載速度會很慢,因此我這里把原來的pt檔案放網盤了
鏈接:https://pan.baidu.com/s/1YFtNxZjHZzD_d1PeXt1dNg
提取碼:1234
一共有四個,推薦優先使用最下那個yolov5s.pt

把yolov5s.pt上傳到weights檔案夾
3.3開始訓練
輸入命令就可以訓練了
python train.py --img 640 --batch 16 --epochs 200 --data /all_data/classes.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt
#python train.py --img 640 --bath (GPU越好數字填越大) --epochs (訓練的輪數,我這里是200論) --data (yaml檔案的路徑) --weights (權重檔案的路徑)
下面可以看到每一論訓練的進度條
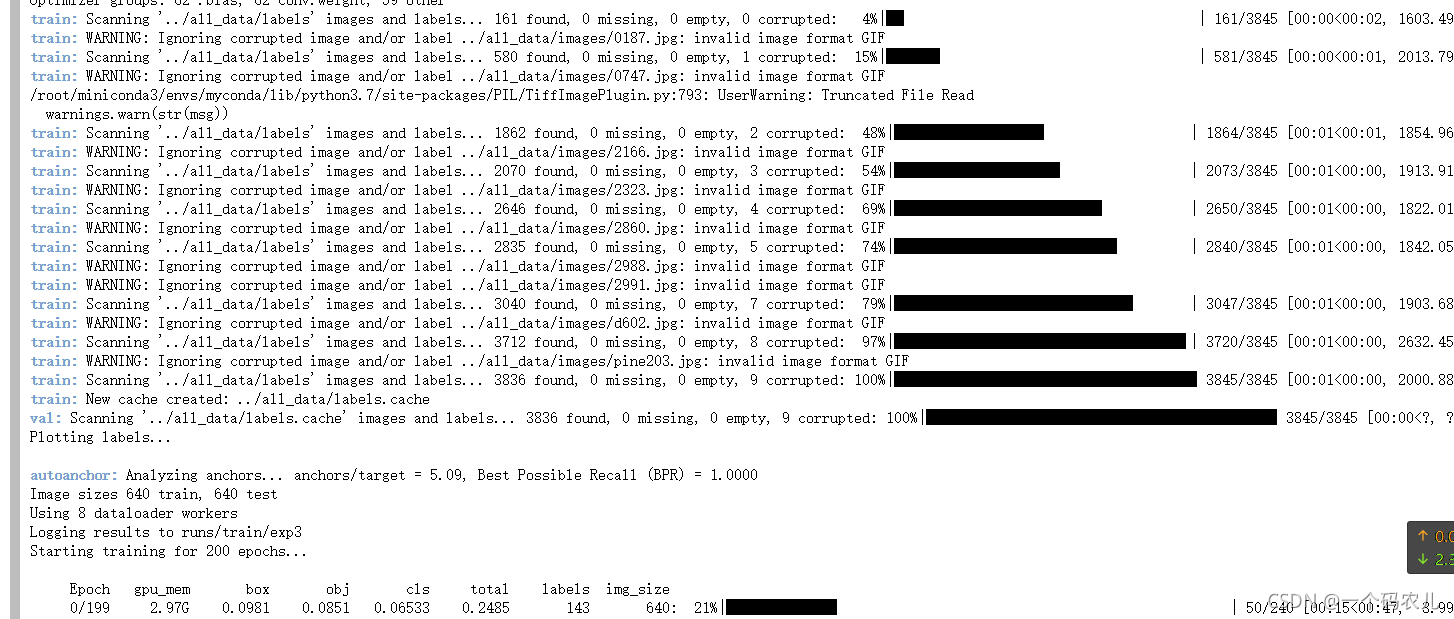
選擇越好的 GPU,訓練的速度越快
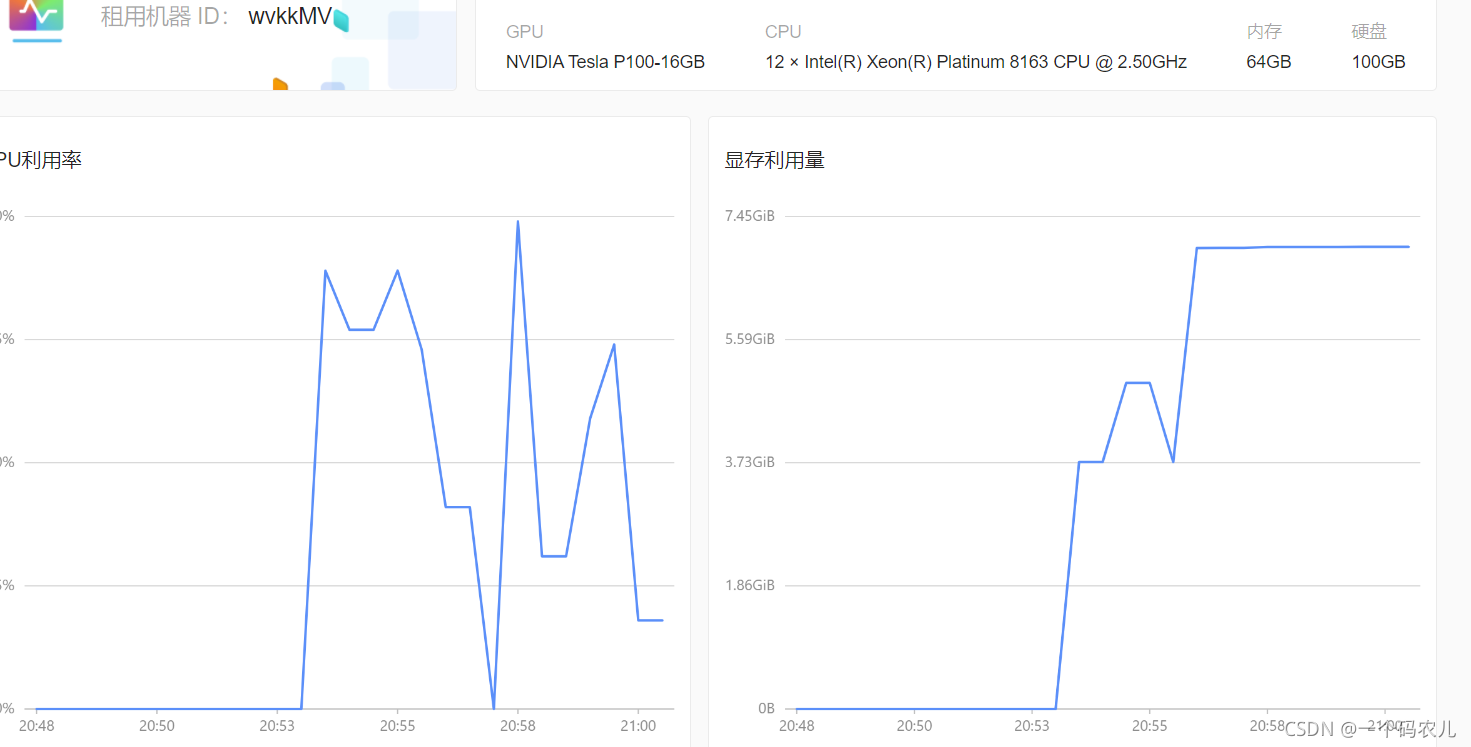
點擊詳情可以查看使用情況
當出現Optimizer stripped from 這句話時就說明已經訓練完畢,模型已經匯出
打開訓練完成后的路徑,可以看到訓練的各類結果
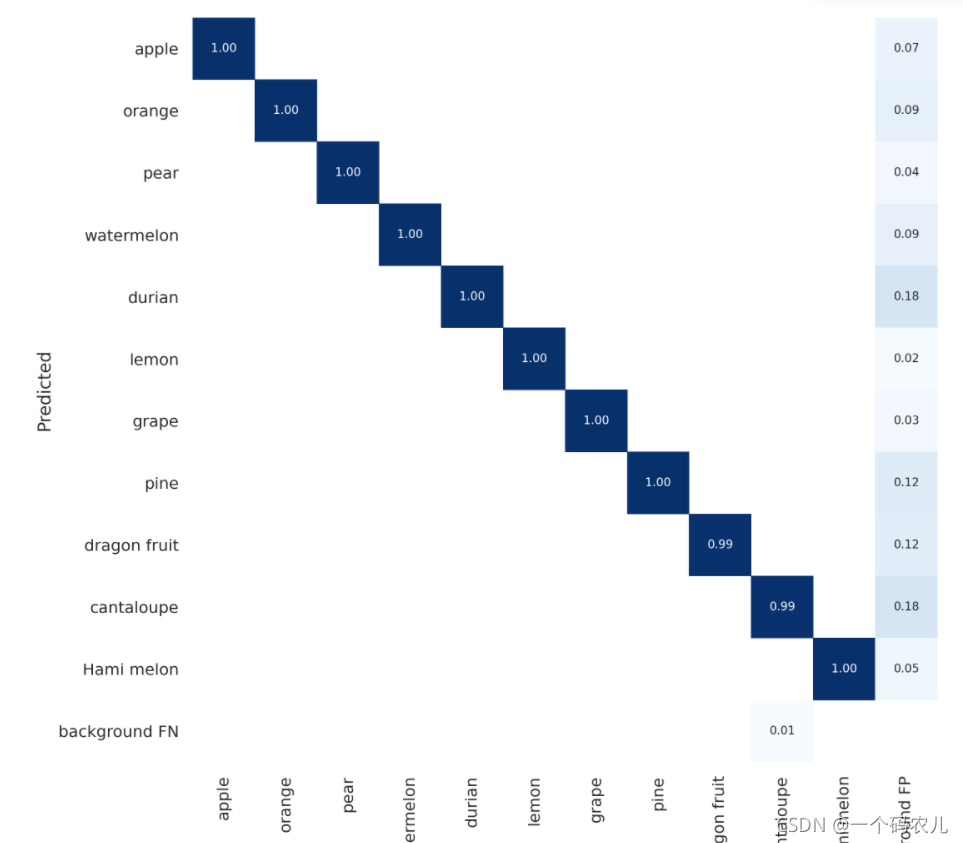
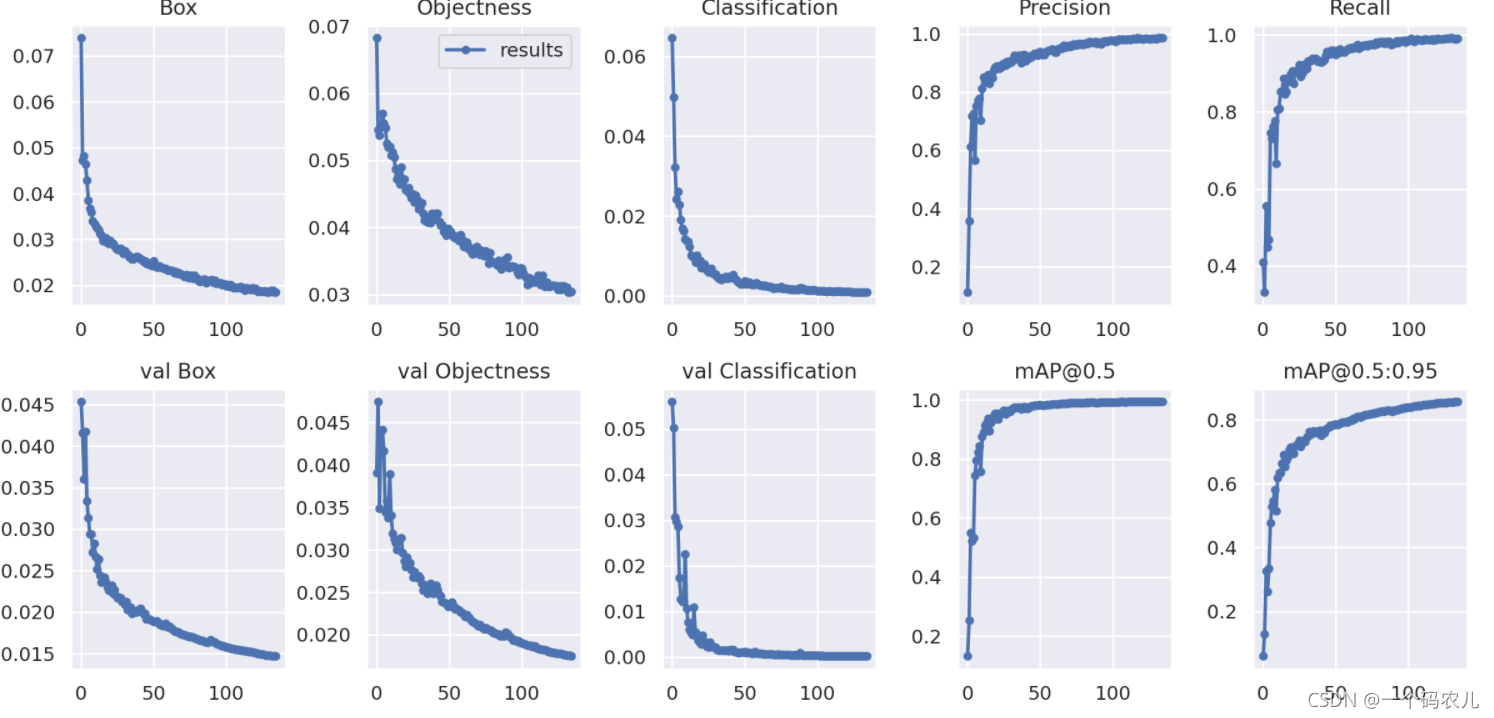
這些結果能直觀的反映訓練的情況,很多時候訓練的結果和你的資料集有很大的關系
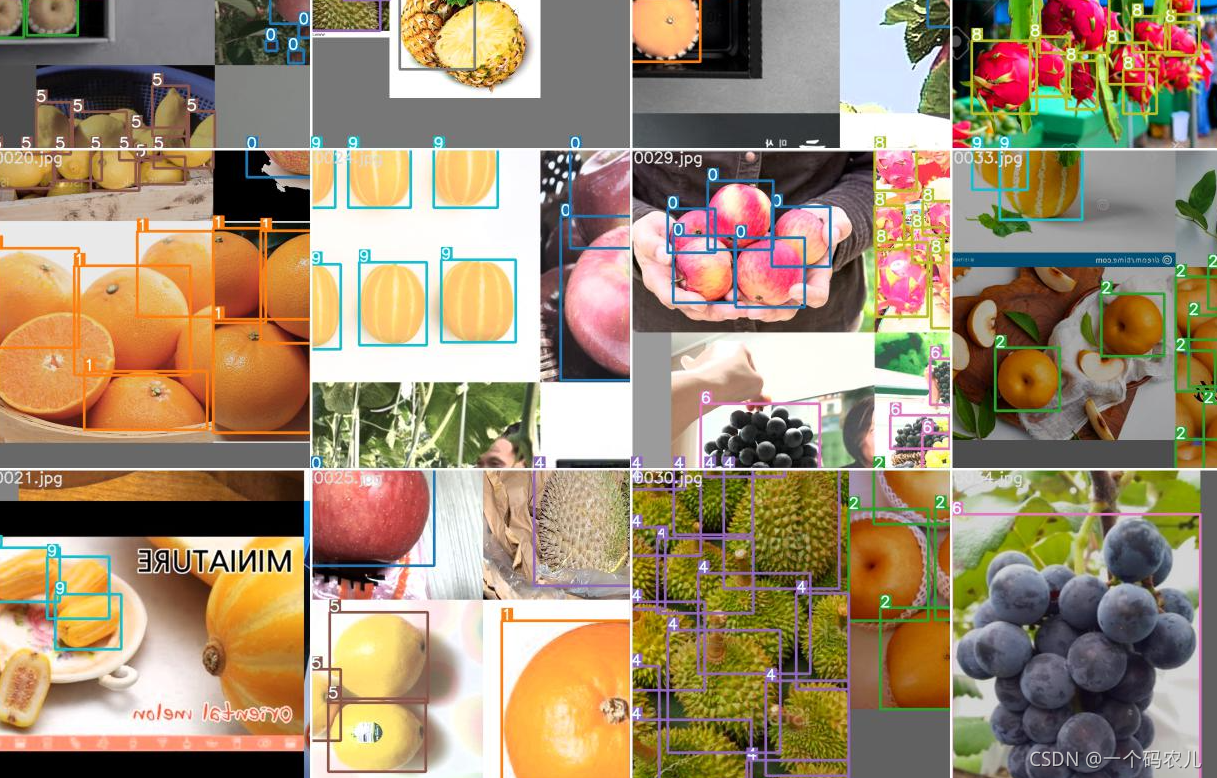
3.4模型轉化
我們訓練后得到的模型是pt格式的檔案,想要部署在jetson nano上,需要將其轉化未wts檔案
首先將得到的模型檔案best.pt放到yolov5-5.0檔案夾中
新建一個檔案,命名未pt_to_wts.py,輸入以下代碼
import torch
import struct
# utils.torch_utils from yolov5 github: https://github.com/ultralytics/yolov5
from utils.torch_utils import select_device
# Initialize
device = select_device('cpu')
# Load model
model = torch.load('best.pt', map_location=device)['model'].float() # load to FP32
model.to(device).eval()
f = open('best.wts', 'w')
f.write('{}\n'.format(len(model.state_dict().keys())))
for k, v in model.state_dict().items():
vr = v.reshape(-1).cpu().numpy()
f.write('{} {} '.format(k, len(vr)))
for vv in vr:
f.write(' ')
f.write(struct.pack('>f',float(vv)).hex()) 
在終端輸入
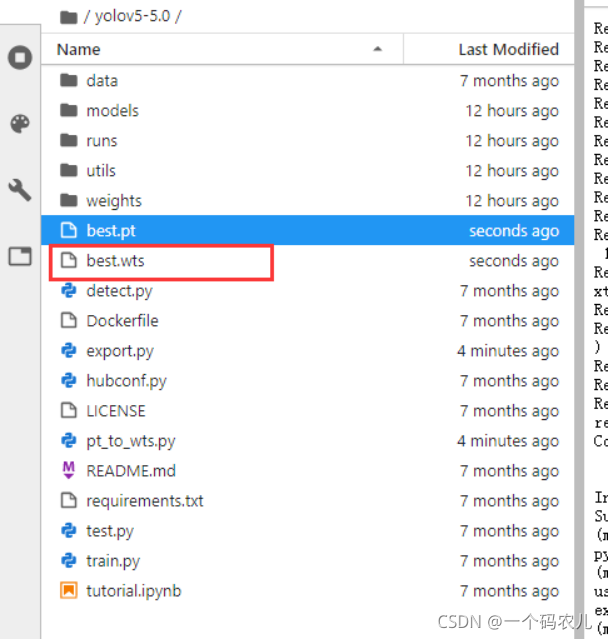
python pt_to_wts.py目錄下會多出一個best.wts檔案,這個就是我們要的權重檔案了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356715.html
標籤:AI
上一篇:pandas生成新的累加資料列、pandas生成新的累加資料列(資料列中包含NaN的情況)、pandas計算整個dataframe的所有資料列的累加