開篇
? 型別一直是C++中最重要的部分,相比于其他高級語言,C++的型別會復雜許多,往往一個型別匹配錯誤就會導致程式報錯,本篇主要講解一些常用型別的概念以及細節,如果對于C++有一定基礎的,可以跳轉到思考部分,從中了解自己的掌握程度;
初始化與賦值
定義:初始化與賦值陳述句是程式中最基本的陳述句,功能是將某個值與一個物件關聯起來;
- 值:字面量、物件(變數或常量)所表示的值等
- 識別符號(物件):變數、常量、參考
初始化的基本操作:
1、在記憶體中開辟空間、保存相應的數值;
2、在編譯器中構造符號表、將識別符號與相關記憶體空間關聯起來;
型別概述
下面通過幾點概要說明:
1、型別是編譯期概念,可執行程式中不存在型別的概念;
2、C++是強型別語言;
-
強型別語言定義:一旦一個變數被定義型別,如果不經過強制轉換,那么它永遠就是該資料型別;
-
弱型別語言定義:某一變數被定義型別,該變數可根據環境變化自動進行轉換,不需要強轉;
3、引入型別是為了更好描述程式,防止誤用;
4、型別描述的資訊:
- 存盤所需要的大小(sizeof,標準沒有嚴格限制,根據硬體不同位元組數也不同)
- 取值空間(可用std::numeric_limits來判斷,超過范圍可能產生溢位)
#include<iostream>
#include<limits>
int main() {
int x = 10;
std::cout << std::numeric_limits<int>::min() << std::endl; //-2147483648
std::cout << std::numeric_limits<int>::max() << std::endl; //2147483647
std::cout << std::numeric_limits<unsigned int>::min() << std::endl; //0
std::cout << std::numeric_limits<unsigned int>::max() << std::endl; //4294967295
}
由上面程式運行結果可知,無符號int型別占4個位元組,也就是32個位元位,所以最大范圍為232,在不同的硬體下可能不同;
- 對齊資訊(一般存放在記憶體中按型別的對齊資訊的整數倍存盤,比如int的對齊資訊為4個位元組,那存盤的空間首地址為4的倍數,在結構體中,因為存在對齊資訊,char也會按4個位元組保存)
- 型別可執行的操作
型別分類
型別可以劃分為基本型別和復雜型別;
基本(內建)型別:C++語言中支持的型別,包含以下幾種:
1、數值型別
- 字符型別:char、wchar_t、char16_t、char32_t,通常為1個位元組,表示256個值,也就是ASCII編碼的字符;
- 整數型別:帶符號整數型別(short、int、long、long long),無符號整數型別(unsigned+帶符號整數型別)
- 浮點型別:float、double、long double
注意:在C++11中引入了固定尺寸的整數型別,如int32_t等,之前在針對開發板的程式中有見過該型別,主要是便于硬體的可移植性:
2、void型別
復雜型別:由基本型別組合、變種所產生的型別,可能是標準庫引入,或自定義型別;
字面值及其型別
字面值:在程式中直接表示為一個具體數值或字串的值;
每個字面值都有其型別,例子如下:
- 整數字面值(int):20(十進制)、024(八進制)、0x14(十六進制)
- 浮點數(double):1.3、1e8
- 字符字面值(char):‘c’、’\n’
- 字串字面值(char[4]):“cpp”,注意這里字串后會默認加/0,所以是四個字符長度
- 布爾字面值(bool):True、False
像如果想要定義float型別的數,可以加入后綴如1.3f;
C++提供了用戶創建自定義后綴的函式:
#include<iostream>
// 后綴可自行定義,我這里用_bang
int operator "" _bang(long double x)
{
return (int)x * 2;
}
int main() {
int x = 7.14_bang;
std::cout << x << std::endl;
}
上面代碼將7.14的浮點型別轉換成整型并增大一倍,可自行定義后綴試一下;
變數及其型別
變數:對應一段存盤空間,可以改變其中內容;
宣告與定義的區別:不能重定義已經初始化的變數,需要加入extern用來宣告;
初始化:全域變數會默認初始化為0,區域變數會預設初始化(亂數值);
復合型別
1、指標:一種間接型別;
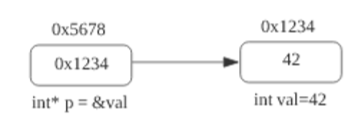
如上圖為一個指標p指向一段記憶體,p保存的為val的地址,我們通過列印尺寸可知,指標p為8個位元組;
特點:
- 可以"指向"不同的物件;
- 具有相同的尺寸;
- 指標與bool的隱式轉換:非空指標可以轉換為true、空指標可以轉換為false;
注意兩個符號:*(解參考符)、&(取地址符);
解參考符在不同環境下含義不同,看如下代碼:
int x = 10;
int* p = &x; // 表示p為一個int指標型別
*p; // 表示解參考,獲取指標指向地址的值
關于nullptr:
- 一個特殊的物件(型別為nullptr_t),表示空指標;
- 類似于C中的NULL,但更加安全;
void 指標*:沒有記錄物件的尺寸,可以表示任意型別指標,一般作為形參或回傳值;
指標對比物件:指標復制成本低,參考成本高;
總結:指標在程式中的作用,最重要的就是作為引數傳入,由于資料型別可能很大,傳入指標大小固定為8個位元組,并且指標值為地址可復制,復制成本低,并且可在函式中改變變數的值;
2、參考:
取地址符&也有兩個含義:
int x = 10;
&x; // 取地址符
int& ret = x; // 定義ret為一個參考型別
特點:
- 是物件的別名,不能系結字面值(指標也不能指向字面值);
- 構造時系結物件,在其生命周期內不能系結其他物件(賦值操作會改變物件內容);
- 不存在空參考,但可能存在非法參考,總體比指標安全;
- 屬于編譯期概念,在底層還是通過指標實作;
常量型別
- 使用關鍵字const宣告常量物件;
- 是編譯期概念,由編譯器保證,作用為防止非法操作、優化程式邏輯;
常量指標(頂層常量):
int* const p = &x;
常量指標表示指標為常量,指標不能更改指向;
底層常量:
const int* p = &x;
底層常量表示指標指向的地址的內容不能發生改變,指標指向可改變;
常量參考:
- 用const int&定義一個常量參考;
- 主要用于函式形參(對于較復雜的資料型別);
- 可以系結字面值;
常量運算式:
constexpr int x = 1; // x的型別仍為const int
- 宣告的是編譯期的常量,編譯器可以對其進行優化;
型別別名
型別別名:引入特殊的含義或便于使用,例如size_t;
-
引入型別別名的兩種方式:
1、typedef int Mytype;
2、using Mytype = int;(C++11后)
第二種方式更好;
-
應將指標型別別名視為一個整體,引入常量const表示指標為常量的型別;
-
不能通過型別別名構造參考的參考;
型別自動推導
定義:通過初始化運算式定義物件型別,編譯器會自動推導得到;(C++11開始)
-
推導得到的型別還是強型別,并不是弱型別;
-
自動推導的幾種形式:
1、auto:最常用的形式,會產生型別退化(由于左值右值的型別區別);
2、const auto、constexpr auto:推匯出的是常量、常量運算式型別;
3、auto&:推匯出參考型別,避免型別退化;
4、decltype(exp):回傳exp運算式的型別(左值加參考);
5、decltype(val):回傳val的型別;
6、decltype(auto):簡化decltype的使用,C++14開始支持;
補充:型別退化表示一個變數作為左值和右值時型別不同,例如陣列作為右值為指標;
域與物件宣告周期
域(scope):表示程式中的一部分,其中的名稱有唯一含義,有全域域、塊域等;
- 域可以嵌套,嵌套域中定義的名稱可以隱藏外部域中定義的名稱;
- 物件的生命周期起始于被初始的時刻,終止于被銷毀的時刻;
- 全域物件的生命周期是整個程式運行期間,區域物件終止在所在域執行完成;
思考
1、思考下下面關于指標的兩行代碼的含義:
int x = 1;
int* p = &x;
int y = 0;
*p = y; // 第一行
p = &y; // 第二行
這兩行表明了指標的一個特定,可改變性,每一行的含義如下:
第一行:將指標p指向的記憶體地址的值改變為y;
第二行:不改變x的值,而是將指標p的指向改成y;
2、經過指標的思考后,我們看看關于參考的思考:
int x = 1;
int& f = x;
int y = 0;
f = y; // 思考一下這一行的作用,是改變了參考f的系結嗎?
上面這行代碼并不改變f的系結,而是改變了f的值,同時參考物件x的值也發生改變;
3、經過了指標和參考的思考,下面思考下兩者在底層有什么關聯:
int x;
int* p = &x; *p = 1;
int& f = x; f = 1;
分析下上面兩行代碼,他們底層實作會相同嗎?
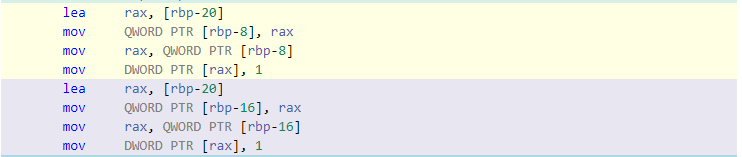
這是兩者的匯編代碼實作,可以發現是完全相同的,參考底層也是通過指標實作的;
4、思考以下代碼中&x是什么資料型別?
int x = 1;
const int* p = &x;
如果我們只考慮&x的話,這是一個int*的型別,但由于第二行代碼執行拷貝構造,隱式地將&x轉換為左值所需要的 const int *型別;
5、思考下面函式傳參的區別?
void fun(int x){}
void fun(const int& x){}
從本質上來說,上面兩種傳參實作的作用是一致的,第一個進行拷貝構造傳遞,所以在函式內部無法改變外部x變數的值,而下面的傳參傳入參考可以在函式內部改變外部x的值,加入const強制成變數;第二種其實是畫蛇添足地做法,但常量參考對于復雜的資料型別來說,是能夠節省很多空間的,比如自定義的結構體;
6、下面常量表示底層常量還是頂層常量?
using mytype = int*;
int x = 1;
const mytype p = &x;
這里我們容易誤導,還會認為這是一個底層常量,但由于別名的定義,這里其實是一個頂層常量,我們可以將mytype看作一個整體,那么指標的指向不可發生改變;
7、下面auto&自動推匯出的y是什么型別?
const int x = 1;
auto& y = x;
相信大部分人會認為x會型別退化,從而y為int&型別,實際上這里型別不會退化,所以y為const int&型別;
8、下面來看看decltype自動推導的型別是什么?
int x = 1;
decltype(x); // 1
decltype((x)); // 2
decltype在傳入引數為左值時加入參考,那么第一行為一個變數,所以為int型別,第二行為運算式,所以加入參考為int&型別;
總結
? 本篇講解的型別知識點很雜,并且涵蓋很多小的知識點,很多細節部分在實際工程中不一定會接觸到,當然在工程中也會遇到很多自己不理解的型別轉換,需要多通過debug模式來查看型別;
? 本篇知識點較多,可以選擇自己想了解的部分進行查看,后續會繼續推出更深層次的內容;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356738.html
標籤:其他