- 🎉粉絲福利送書:《 Java多執行緒與大資料處理實戰》
- 🎉點贊 👍 收藏 ?留言 📝 即可參與抽獎送書
- 🎉下周二(11月17日)晚上20:00將會在【點贊區和評論區】抽一位粉絲送這本北京大學出版社的書~🙉
- 🎉詳情請看最后的介紹嗷~?

實驗 1
1.1 題目
熟練掌握 scrapy 中 Item、Pipeline 資料的序列化輸出方法;
Scrapy+Xpath+MySQL資料庫存盤技術路線爬取當當網站圖書資料
候選網站:http://www.dangdang.com/
1.2 思路
1.2.1 setting.py
-
打開請求頭

-
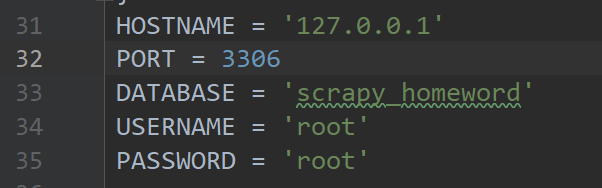
連接資料庫資訊
-
ROBOTSTXT_OBEY設定為False

-
打開pipelines

1.2.2 item.py
撰寫item.py的欄位
class DangdangItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
price = scrapy.Field()
detail = scrapy.Field()
1.2.3 db_Spider.py
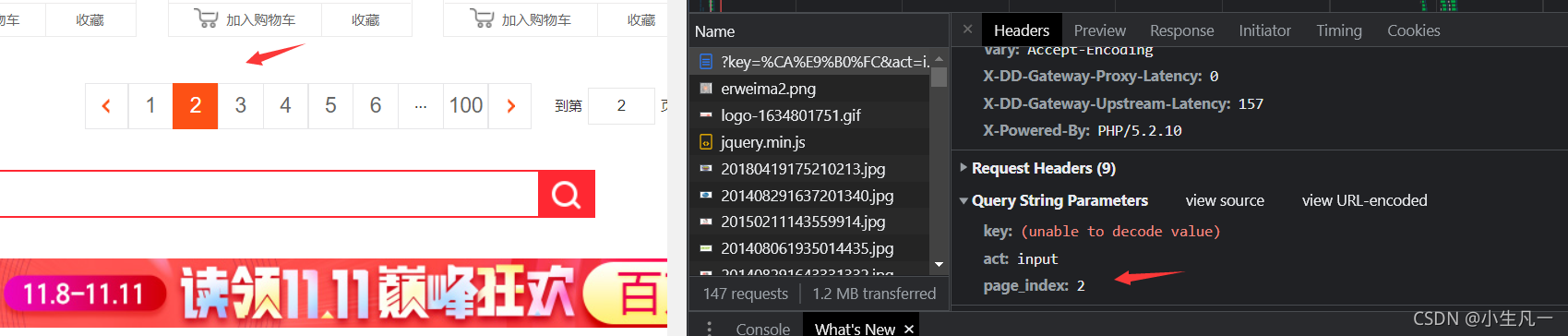
- 觀察網頁,查看分頁
第二頁
第三頁
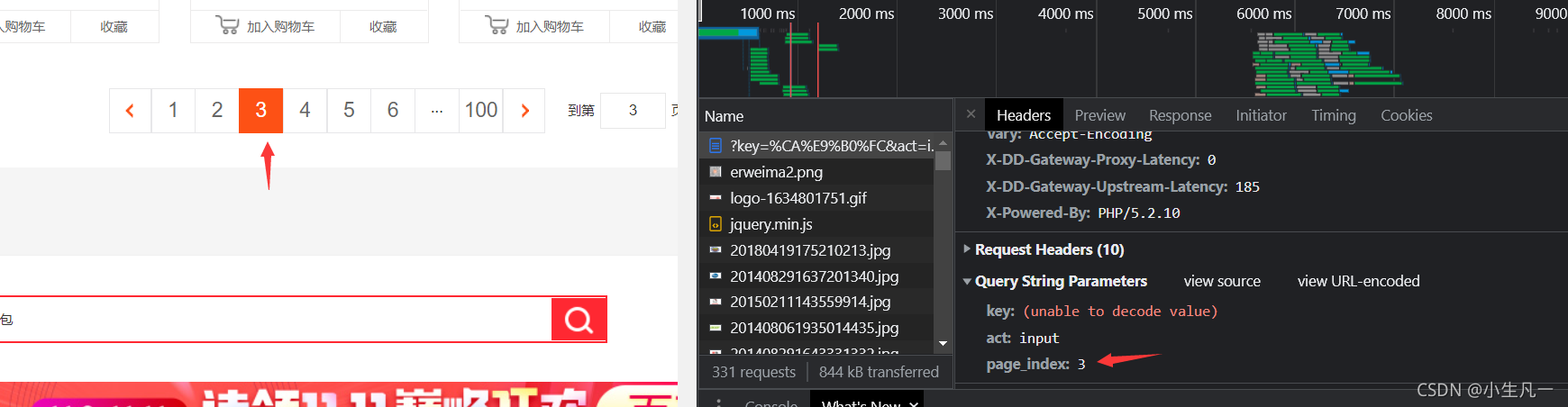
所以很容易發現這個page_index就是分頁的引數
- 獲取節點資訊
def parse(self, response):
lis = response.xpath('//*[@id="component_59"]')
titles = lis.xpath(".//p[1]/a/@title").extract()
authors = lis.xpath(".//p[5]/span[1]/a[1]/text()").extract()
publishers = lis.xpath('.//p[5]/span[3]/a/text()').extract()
dates = lis.xpath(".//p[5]/span[2]/text()").extract()
prices = lis.xpath('.//p[3]/span[1]/text()').extract()
details = lis.xpath('.//p[2]/text()').extract()
for title,author,publisher,date,price,detail in zip(titles,authors,publishers,dates,prices,details):
item = DangdangItem(
title=title,
author=author,
publisher=publisher,
date=date,
price=price,
detail=detail,
)
self.total += 1
print(self.total,item)
yield item
self.page_index += 1
yield scrapy.Request(self.next_url % (self.keyword, self.page_index),
callback=self.next_parse)
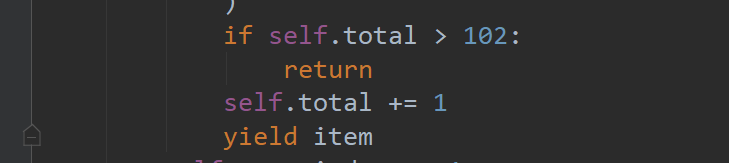
- 指定爬取數量
爬取102條
1.2.4 pipelines.py
- 資料庫連接
def __init__(self):
# 獲取setting中主機名,埠號和集合名
host = settings['HOSTNAME']
port = settings['PORT']
dbname = settings['DATABASE']
username = settings['USERNAME']
password = settings['PASSWORD']
self.conn = pymysql.connect(host=host, port=port, user=username, password=password, database=dbname,
charset='utf8')
self.cursor = self.conn.cursor()
- 插入資料
def process_item(self, item, spider):
data = dict(item)
sql = "INSERT INTO spider_dangdang(title,author,publisher,b_date,price,detail)" \
" VALUES (%s,%s, %s, %s,%s, %s)"
try:
self.conn.commit()
self.cursor.execute(sql, [data["title"],
data["author"],
data["publisher"],
data["date"],
data["price"],
data["detail"],
])
print("插入成功")
except Exception as err:
print("插入失敗", err)
return item
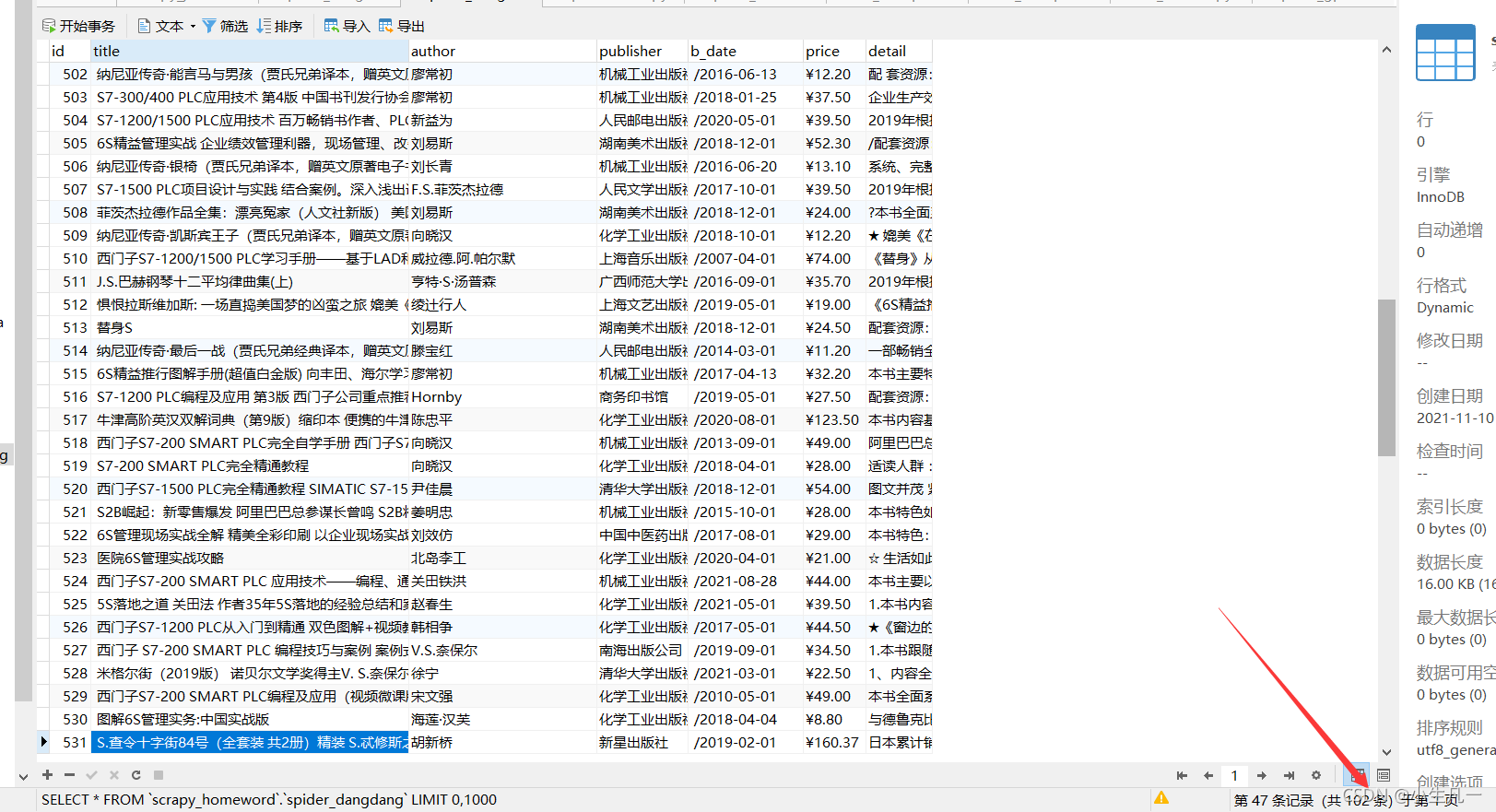
結果查看,一共102條資料,這個id我是設定自動自增的,因為有之前測驗的資料插入,所以id并沒有從1開始
實驗 2
2.1 題目
要求:熟練掌握 scrapy 中 Item、Pipeline 資料的序列化輸出方法;使用
scrapy框架+Xpath+MySQL資料庫存盤技術路線爬取外匯網站資料,
候選網站:招商銀行網:http://fx.cmbchina.com/hq/
2.2 思路
2.2.1 setting.py
與1.2.1的setting.py相似,就不過多展示了
2.2.2 item.py
撰寫item.py
class CmbspiderItem(scrapy.Item):
currency = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()
2.2.3 db_Spider.py
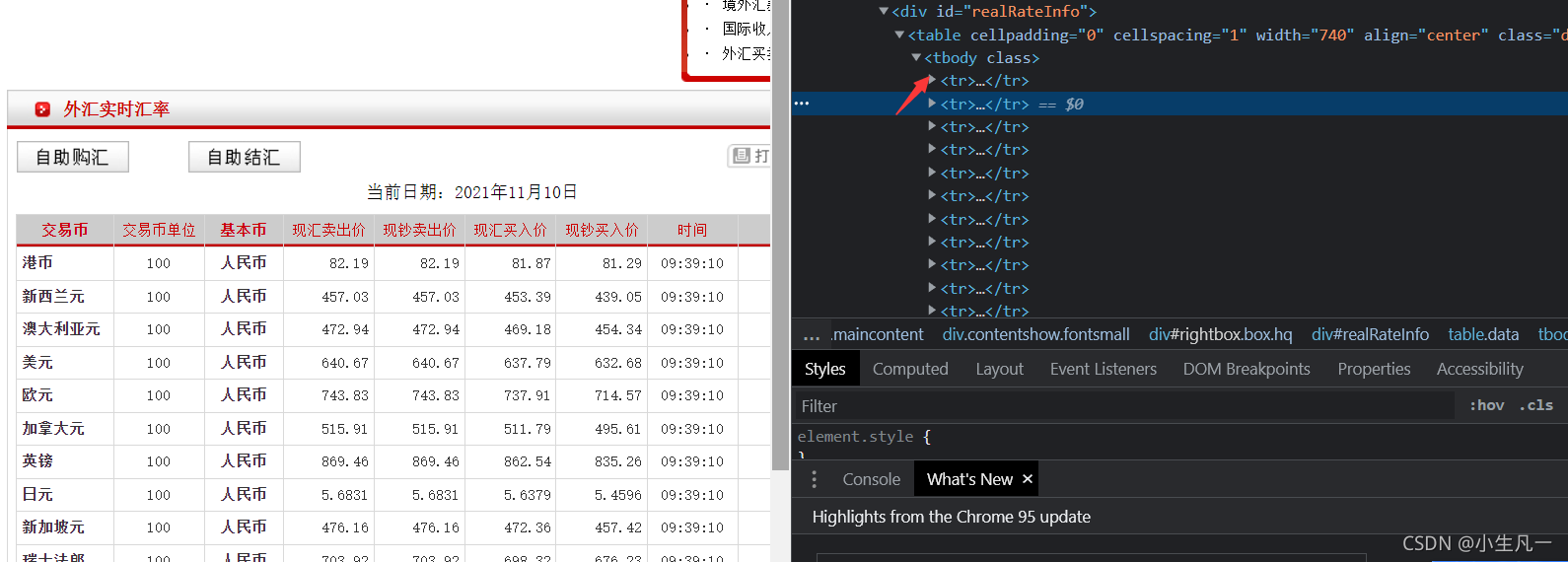
- 資料決議
lis = response.xpath('//*[@id="realRateInfo"]/table')
currencys = lis.xpath(".//tr/td[1]/text()").extract()
tsps = lis.xpath(".//tr/td[4]/text()").extract()
csps = lis.xpath(".//tr/td[5]/text()").extract()
tbps = lis.xpath(".//tr/td[6]/text()").extract()
cbps = lis.xpath(".//tr/td[7]/text()").extract()
times = lis.xpath(".//tr/td[8]/text()").extract()
注意: 這里有一個坑點,因為這個table后面應該是有一個tbody的!
但是我們如果加了的話,就爬不下來了!所以要刪掉這個tbody,然后下面的元素全從\改成\\
- 資料處理
去除資料的前后空格和一些'\r\n'
for currency, tsp, csp, tbp, cbp, time in zip(currencys, tsps, csps, tbps, cbps, times):
count+=1
currency = currency.replace(' ', '')
tsp = tsp.replace(' ', '')
csp = csp.replace(' ', '')
tbp = tbp.replace(' ', '')
cbp = cbp.replace(' ', '')
time = time.replace(' ', '')
currency = currency.replace('\r\n', '')
tsp = tsp.replace('\r\n', '')
csp = csp.replace('\r\n', '')
tbp = tbp.replace('\r\n', '')
cbp = cbp.replace('\r\n', '')
time = time.replace('\r\n', '')
if count ==1 :
continue
item = CmbspiderItem(
currency=currency, tsp=tsp, csp=csp, tbp=tbp, cbp=cbp, time=time
)
yield item
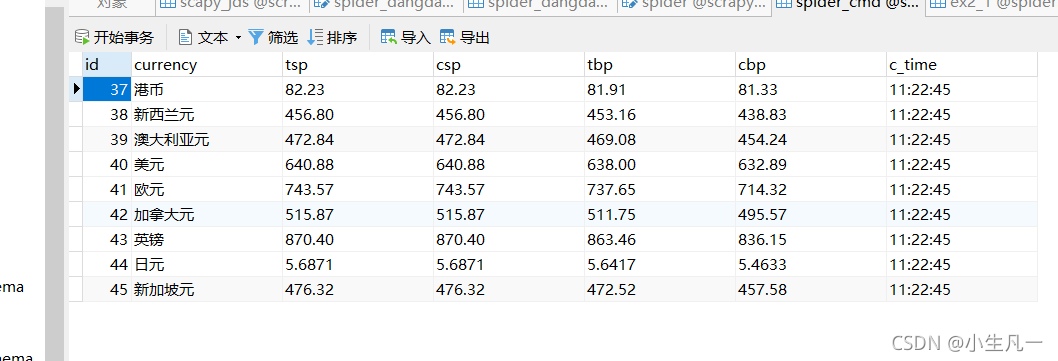
2.2.4 pipelines.py
與1.2.4的操作相似,不再過多描述
實驗 3
3.1 題目
熟練掌握 Selenium 查找HTML元素、爬取Ajax網頁資料、等待HTML元素等內容;
使用Selenium框架+ MySQL資料庫存盤技術路線爬取“滬深A股”、“上證A股”、“深證A股”3個板塊的股票資料資訊,
候選網站:東方財富網:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
3.2 思路
3.2.1 發送請求
- 引入驅動
chrome_path = r"D:\Download\Dirver\chromedriver_win32\chromedriver_win32\chromedriver.exe" # 驅動的路徑
browser = webdriver.Chrome(executable_path=chrome_path)
- 保存需要爬取的版塊
target = ["hs_a_board", "sh_a_board", "sz_a_board"]
target_name = {"hs_a_board": "滬深A股", "sh_a_board": "上證A股", "sz_a_board": "深證A股"}
計劃是爬取三個模板的兩頁資訊,
- 發送請求
for k in target:
browser.get('http://quote.eastmoney.com/center/gridlist.html#%s'.format(k))
for i in range(1, 3):
print("-------------第{}頁---------".format(i))
if i <= 1:
get_data(browser, target_name[k])
browser.find_element_by_xpath('//*[@id="main-table_paginate"]/a[2]').click() # 翻頁
time.sleep(2)
else:
get_data(browser, target_name[k])
注意: 這里的翻頁一點要time.sleep(2)
不然他會請求會很快,以至于你雖然翻到第二頁了,但是還是爬取第一頁的資訊!!
3.2.2 獲取節點
- 決議網頁的時候也要
implicitly_wait等待一下
browser.implicitly_wait(10)
items = browser.find_elements_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr')
然后這個items就是所以的資訊了
for item in items:
try:
info = item.text
infos = info.split(" ")
db.insertData([infos[0], part, infos[1], infos[2],
infos[4], infos[5],
infos[6], infos[7],
infos[8], infos[9],
infos[10], infos[11],
infos[12], infos[13],
])
except Exception as e:
print(e)
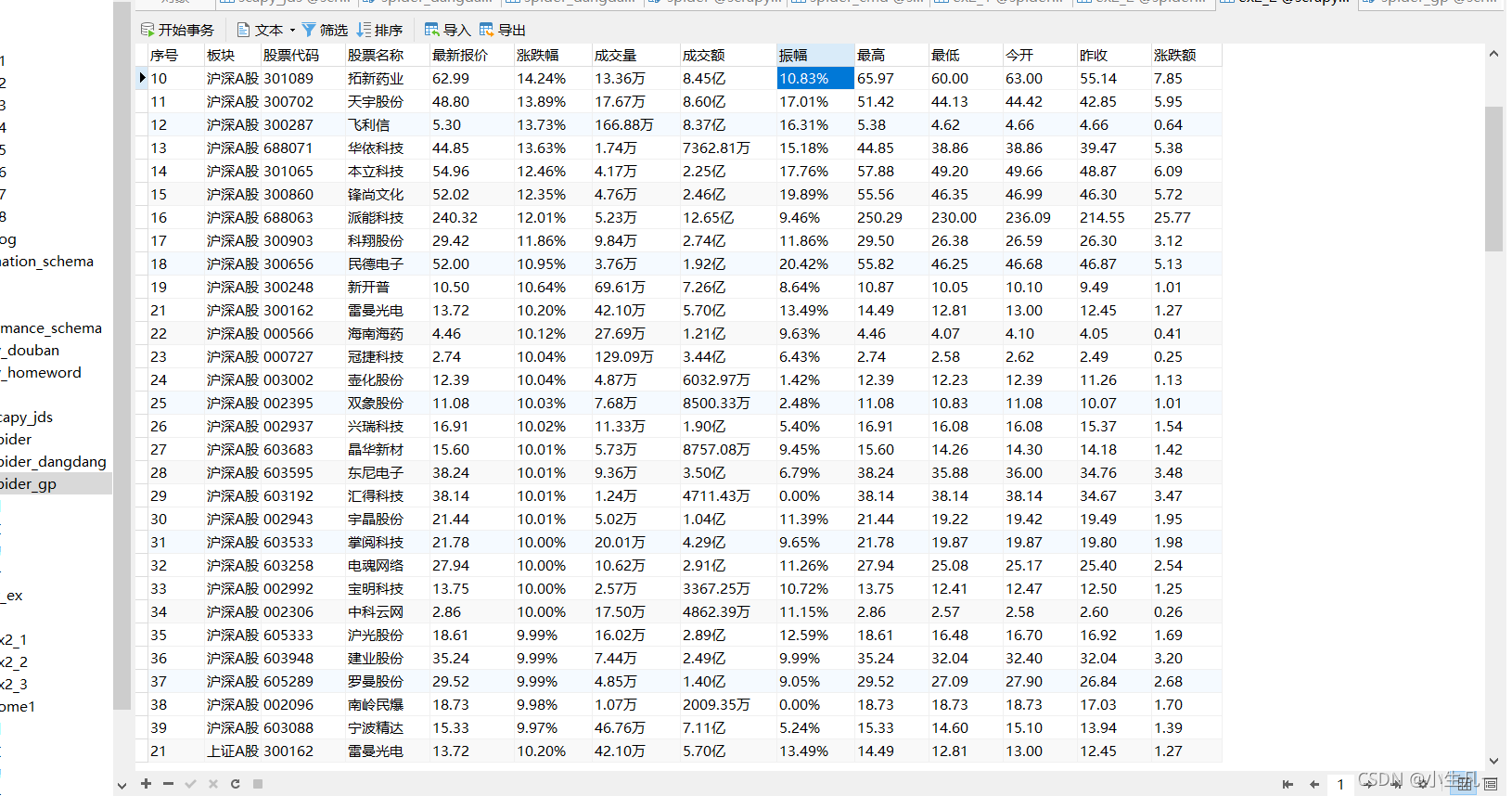
3.2.3 保存資料
- 資料庫類,封裝了初始化和插入操作
class database():
def __init__(self):
self.HOSTNAME = '127.0.0.1'
self.PORT = '3306'
self.DATABASE = 'scrapy_homeword'
self.USERNAME = 'root'
self.PASSWORD = 'root'
# 打開資料庫連接
self.conn = pymysql.connect(host=self.HOSTNAME, user=self.USERNAME, password=self.PASSWORD,
database=self.DATABASE, charset='utf8')
# 使用 cursor() 方法創建一個游標物件 cursor
self.cursor = self.conn.cursor()
def insertData(self, lt):
sql = "INSERT INTO spider_gp(序號,板塊,股票代碼 , 股票名稱 , 最新報價 ,漲跌幅 ,漲跌額,成交量,成交額 , 振幅, 最高 , 最低 , 今開 , 昨收 ) " \
"VALUES (%s,%s, %s, %s, %s, %s,%s, %s, %s, %s, %s,%s,%s,%s)"
try:
self.conn.commit()
self.cursor.execute(sql, lt)
print("插入成功")
except Exception as err:
print("插入失敗", err)
福利送書

【內容簡介】
- 《Java多執行緒與大資料處理實戰》對 Java 的多執行緒及主流大資料中間件對資料的處理進行了較為詳細的講解,
- 本書主要講了
Java的執行緒創建方法和執行緒的生命周期,方便我們管理多執行緒的執行緒組和執行緒池,設定執行緒的優先級,設定守護執行緒,學習多執行緒的并發、同步和異步操作,了解 Java 的多執行緒并發處理工具(如信號量、多執行緒計數器)等內容, - 引入了
Spring Boot、Spring Batch、Quartz、Kafka等大資料中間件,這為學習Java 多執行緒和大資料處理的讀者提供了良好的參考,多執行緒和大資料的處理是許多開發崗位面試中容易被問到的知識點, - 學好
多執行緒的知識點,無論是對于日后的開發作業,還是正要前往一線開發崗位的面試準備,都是非常有用的, - 本書既適合高等院校的計算機類專業的學生學習,也適合從事軟體開發相關行業的初級和中級開發人員,
【評論區】和 【點贊區】 會抽一位粉絲送出這本書籍嗷~
當然如果沒有中獎的話,可以到當當,京東北京大學出版社的自營店進行購買,
也可以關注我!每周都會送一本出去噠~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356760.html
標籤:其他