PyTorch學習筆記
- 基本術語
- 演算法利弊
- 梯度下降演算法
- 隨機梯度下降演算法
- 鞍點
- 畫圖函式
- PyTorch入門
- 生成張量矩陣
- 加法 * - /類似
- 求均值
- 判斷相等 只是比較資料
- 切片
- 改變張量的形狀 ,保證元素的總數量不變
- torch 的 Tensor 與 NumPy 陣列的相互轉換
- Nympy操作
- pytorch 對a進行轉置
- 求實際存盤的相距位置
- 查看存盤的地址
- 查看storage的資料
- 轉換成連續存盤的
- view 與 reshape 的區別
- PyTorch Autograd自動求導
- 求梯度例子
- 關于文本處理
- 構建計算圖
- 構建模型的模板
- pytroch中的各種優化器
- 相應的模型函式
- 各種函式模型
- 1、Linear Unit
- 2、Logistic Regression Unit (sigmoid)
- 3、Binary Cross
- 4、SGD
- 5、Softmax
- 6、Softmax 計算公式
- 7、NLLLOSS
- 8、CrossEntropyLoss
- 9、Relu
- 模型構建的四部
- 卷積神經網路CNN
- Conv2d 卷積層
- MaxPool2d 池化層
- 1x1的卷積
- 回圈神經網路RNN
基本術語
(會一直更新)
數乘:矩陣對應元素相乘,乘出結果相加 ,得到的結果是一個數
演算法利弊
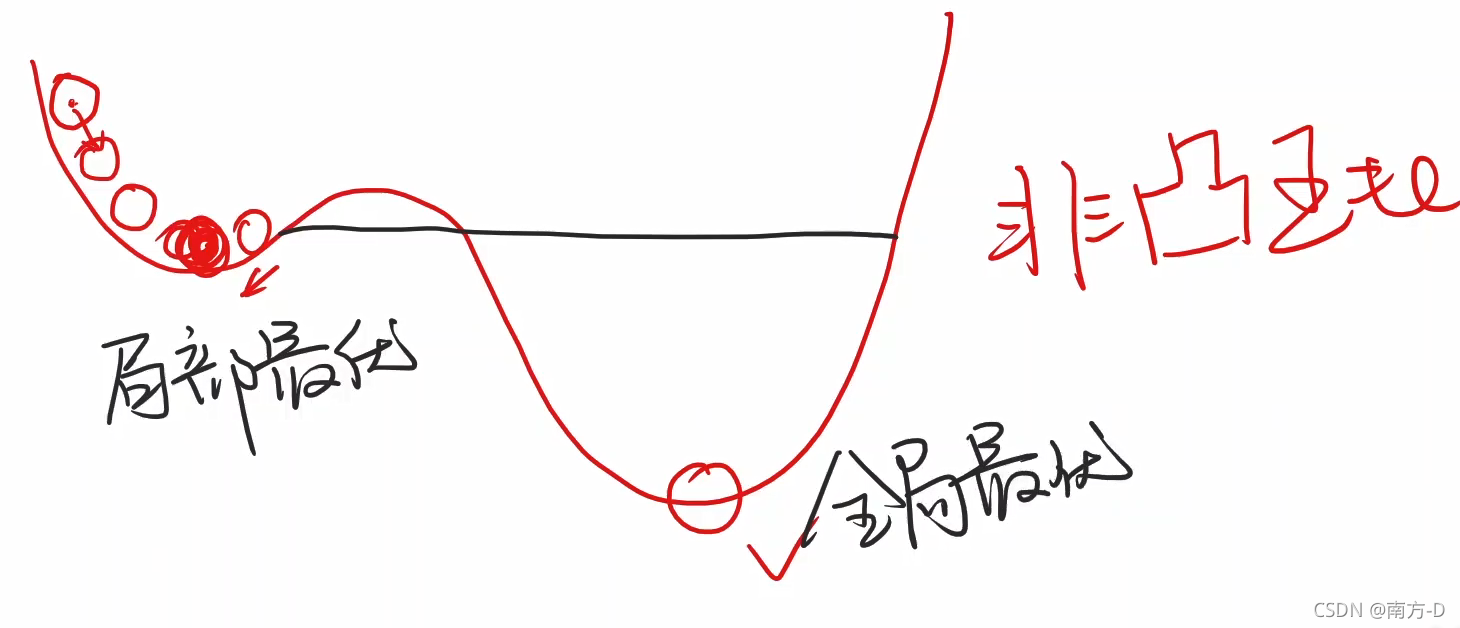
梯度下降演算法
只能找到區域最優,不能找到全域最優
但是神經網路中經常使用梯度下降法,因為神經網路中區域最優點很少
(對每一個點求loss,求和后再更新w的值,因此可以并行計算)
隨機梯度下降演算法
對每一個點求loss后立刻更新w的值,不能并行計算,計算速度相對梯度下降來說比較慢,可以克服區域最優的缺陷
鞍點
O點為鞍點,導數為0
畫圖函式
import matplotlib.pyplot as plt
plt.plot(w_list,mse_list) #填入橫縱坐標資料
plt.ylabel("loss") #縱坐標名稱
plt.xlabel("w") #橫坐標名稱
plt.show()
PyTorch入門
生成張量矩陣
torch.empty(5,3) #生成一個未初始化的5行3列矩陣
torch.rand(5,3) #生成一個初始化的5行3列矩陣
torch.zeros(5,3,dtype=torch.long) #生成一個全零的5行3列矩陣, 資料型別為long,也可設定為int
x=torch.tensor([2.5,3.5]) #直接將資料封裝為張量
y=torch.rand_like(x,dtype=torch.float) #復制張量x得到相同尺寸的新張量,但是資料隨機初始化
torch.ones(2,2) # 生成一個2*2 全為1的矩陣
x.new_ones(5,3,dtype=torch.float) #生成一個5行3列全為1的矩陣
x.size() #或者使用x.shape() 得出張量的尺寸
加法 * - /類似
a+b
torch.add(a,b)
torch.add(a,b, out=result) #將結果存到result中,并列印結果
b.add_(a) # a+b的結果直接賦給b ,并列印結果
求均值
x.mean()
判斷相等 只是比較資料
# 判斷里面的每一個值是否相等
x.eq(y)
# 判斷所有是否相等
x.eq(y).all()
切片
a[1:3,1:3] # 行和列都可以進行切片
改變張量的形狀 ,保證元素的總數量不變
torch.view()
# 或者 torch.reshape()
torch 的 Tensor 與 NumPy 陣列的相互轉換
b=a.numpy() # 將Tensor 轉換為Nympy陣列 b和a共享記憶體
b=torch.from_numpy(a) # 將Nympy陣列 轉換為Nympy陣列Tensor b和a共享記憶體
Nympy操作
np.add(a,1,out=a) #Nympy在自己基礎上加一,與torch中 a.add_(1)相同
!! 所有在CPU上的Tensors,除了CharTensor,都可以轉換為Numpy array并可以反向轉換.
pytorch 對a進行轉置
# 轉置后 b和a仍然用同一個存盤區
b=a.permute(1,0)
求實際存盤的相距位置
a.stride()
#例子
# a=tensor([[0, 1, 2],
# [3, 4, 5],
# [6, 7, 8]])
# a.stride() =(3,1)
#行資料相距3個,列資料相距1個 (在實際的存盤結構中)
查看存盤的地址
a.data_ptr()
查看storage的資料
a.storage()
轉換成連續存盤的
# 轉置,并轉換為符合連續性條件的tensor ,contiguous 會開辟一個新的存盤空間
b = a.permute(1, 0).contiguous()
view 與 reshape 的區別
# reshape方法更強大,可以認為a.reshape = a.view() + a.contiguous().view()
#滿足tensor連續性條件時,a.reshape回傳的結果與a.view()相同,否則回傳的結果與a.contiguous().view()相同
PyTorch Autograd自動求導
autograd包為Tensors上的所有操作提供了自動求導機制
# 注意
w.requires_grad=True # Tensor has to be set to True
# 可以通過.detach()獲得一個新的Tensor,擁有相同的內容但不需要自動求導.
print(x.requires_grad) # true
y=x.detach()
print(y.requires_grad) # false
# 終止對計算機圖的回溯
# 方式一:
with torch.no_grad(): # 建議使用這種方式
# 操作
# 方式二:
x=x.detach()
求梯度例子
>>> y = x + 2
>>> z = y * y * 3
>>> out = z.mean()
>>> out.backward()
>>> out
tensor(27., grad_fn=<MeanBackward0>) # grad_fn 表示執行了哪些操作
>>> x.grad
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
## out對x求導
out.backward()
# 獲得求導后的結果
w.grad
## 防止產生計算圖
w.data 獲得的還是Tensor,但是可以防止產生計算圖
#例如,權重更新要使用data,不能直接使用張量
w.data=w.data-0.01 * w.grad.data
# 獲取Tensor的數值
w.item() 獲得的是數值 不是Tensor
# 例如 a 是 tensor([-8.])
a.item() # 得到 -8
# 清空w的梯度值(把w的導數清零)
w.grad.data.zero_()
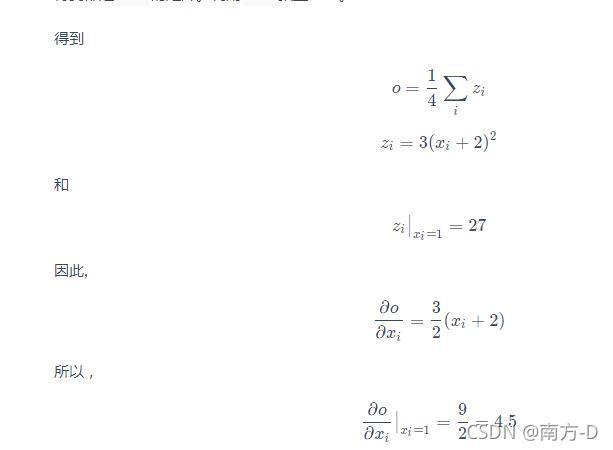
關于文本處理



構建計算圖

構建模型的模板

pytroch中的各種優化器

相應的模型函式
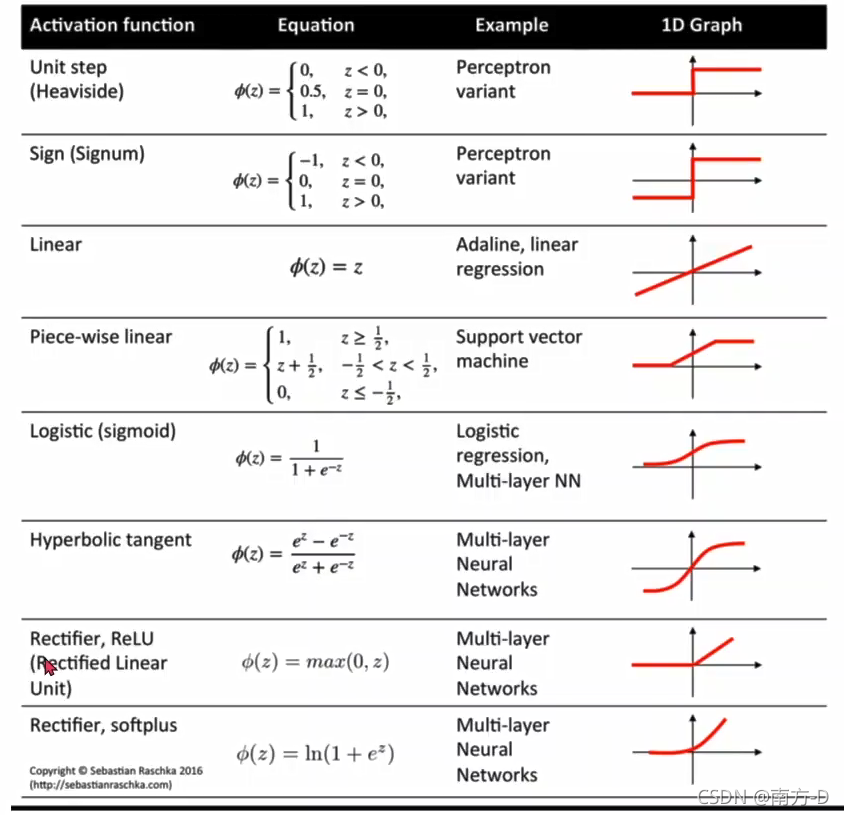
各種函式模型
模型函式看上圖 “相應的模型函式”
1、Linear Unit
公式: y = x* wT+ b (wT表示w的轉置)
torch.nn.Linear(2,3) ## 生成一個3行 2列的weight ,weight的值是隨機產生的位于 -1 ~ 1之間
2、Logistic Regression Unit (sigmoid)
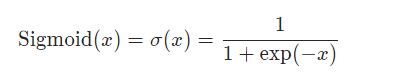

y_pred=torch.sigmoid(x)
3、Binary Cross
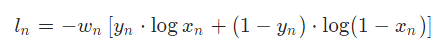
torch.nn.BCELoss(x,y)
4、SGD
Implements stochastic gradient descent (optionally with momentum).
inorder to update w.data
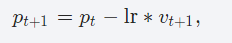
torch.optim.SGD(model.parameters(),lr=0.01)
5、Softmax
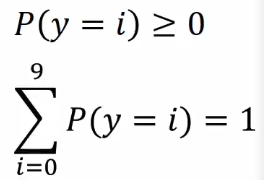
6、Softmax 計算公式
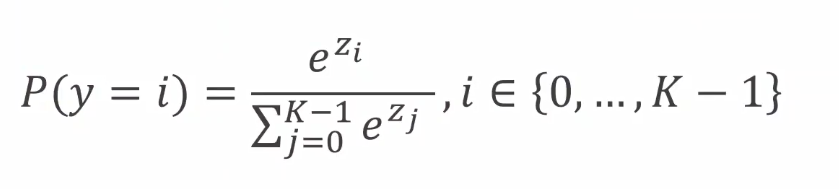
7、NLLLOSS
# 結果只與輸入的 資料有關
## 將選取input_softmax中與 target對應的資料加負號 求和 取平均數
output = nn.NLLLoss(input_softmax, target)
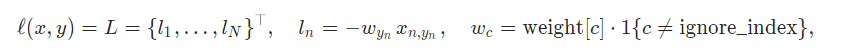
where x is the input, y* is the target, w* is the weight, and N is the batch size. If reduction is not 'none' (default 'mean'), then
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-sJrGWtxa-1636725888431)(F:\Desktop\NLP\編程學習\編程\img\image-20211102191241343.png)]
8、CrossEntropyLoss
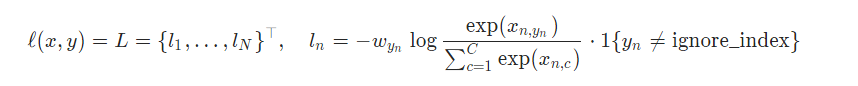
where x is the input, y is the target, w is the weight, C* is the number of classes, and N* spans the minibatch dimension as well as d*1,…,d**k for the K-dimensional case. If reduction is not 'none' (default 'mean'), then
9、Relu
負數改為0,正數不變
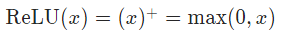

- Input :(?), where *? means any number of dimensions.
- Output : (?), same shape as the input.
模型構建的四部
-
Prepare dataset
-
Design model using Class
inherit from nn.Module
-
Construct loss and optimizer
using PyTorch API
-
Training cycle
forward , backward , update
卷積神經網路CNN
Conv2d 卷積層
torch.nn.Conv2d()
卷積核與input內資料直接點乘,相加求和
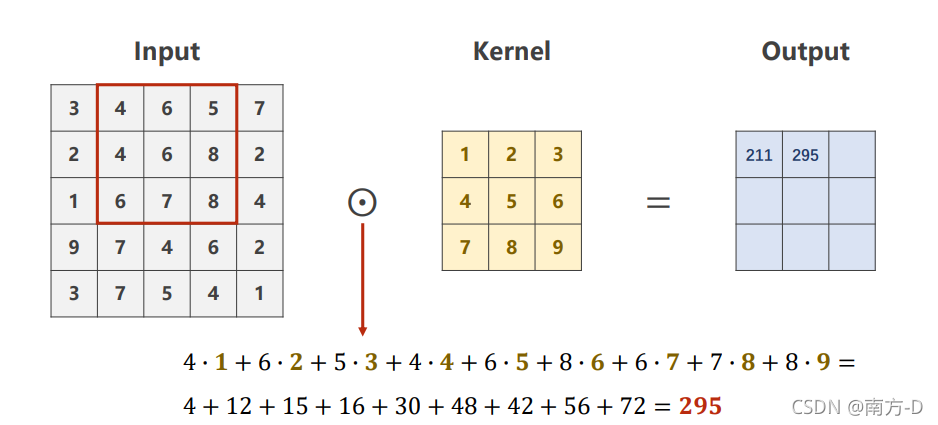
# 輸出測驗結果,kernel_size=3 , (padding=0 填充 , strid=1 步長 :都是默認值)
input: torch.Size([1, 2, 5, 5])
output: torch.Size([1, 10, 3, 3])
weight: torch.Size([10, 2, 3, 3])
MaxPool2d 池化層
torch.nn.MaxPool2d()
直接獲得卷積核內的最大值,作為結果

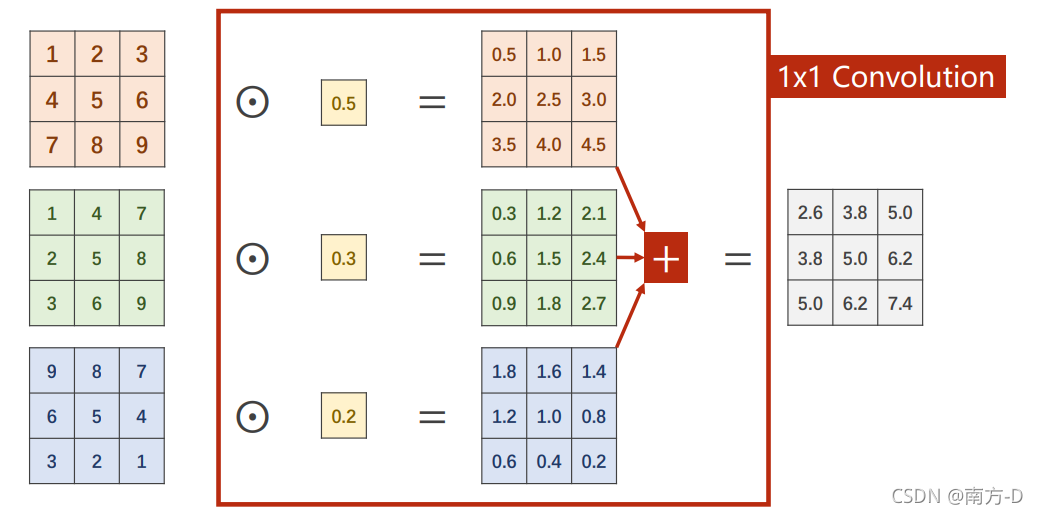
1x1的卷積
對應相乘、相加,不改變寬和高
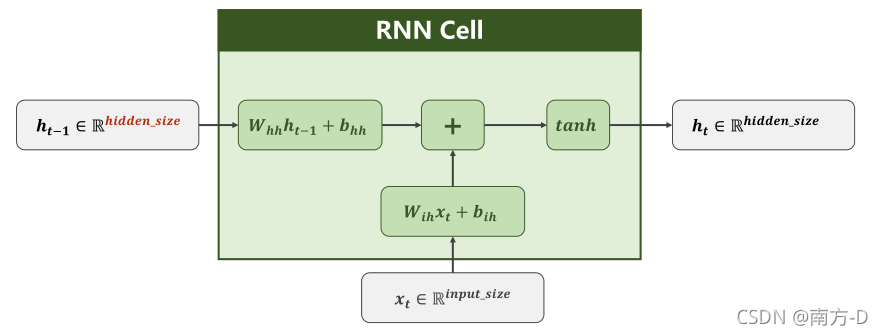
回圈神經網路RNN
RNNCell,只執行一次
RNN會自動幫你做回圈
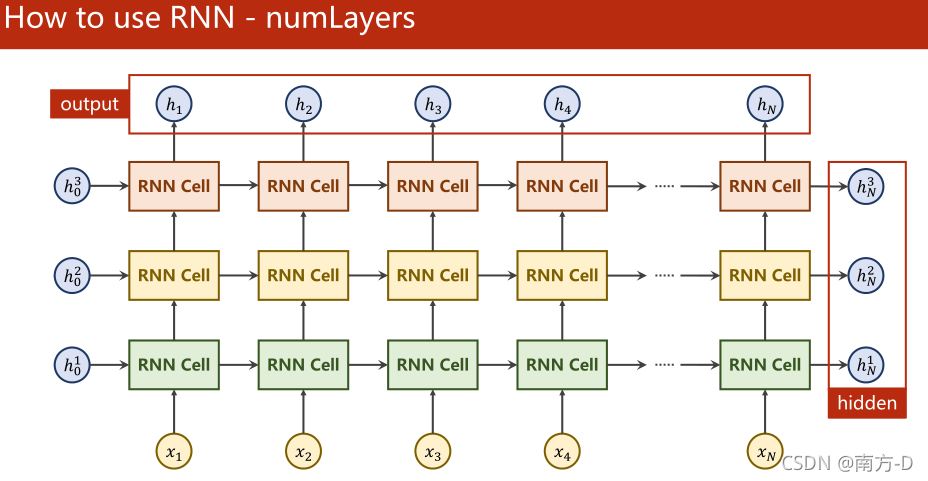
RNN的輸入輸出形狀

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356887.html
標籤:AI