回歸演算法
- 回歸演算法
- 線性回歸和非線性回歸:
- 線性回歸
- 線性回歸方程:
- 損失函式:
- 損失函式推理程序:
- 公式轉換:
- 誤差公式:
- 轉化為`θ`求解:
- 似然函式求`θ`:
- 對數似然:
- 損失函式:
- 梯度下降:
- 批量梯度下降(BGD):
- 隨機梯度下降(SGD):
- `mini-batch`小批量梯下降MBGD:
- 線性回歸案例:
- 正則化與嶺回歸:
- 總結:
- 邏輯回歸
- 精確率和召回率:
- 癌癥患者邏輯回歸案例:
- 邏輯回歸總結:
回歸演算法
資料型別分為連續型和離散型,離散型的資料經常用來表示分類,連續型的資料經常用來表示不確定的值,比如一個產品質量分為1類,2類,這是離散型,房價1.4萬/平,3.4萬/平,這是連續型,之前我們學的都是分類,那么對于一些連續型的資料,我們就可以通過回歸演算法來進行預測了,
回歸分析中,只包括一個自變數和一個因變數,且二者的關系可用一條直線近似表示,這種回歸分析稱為一元線性回歸分析,如果回歸分析中包括兩個或兩個以上的自變數,且因變數和自變數之間是線性關系,則稱為多元線性回歸分析,那么什么是線性關系和非線性關系?
線性回歸和非線性回歸:
比如說在房價上,房子的面積和房子的價格有著明顯的關系,那么X=房間大小,Y=房價,那么在坐標系中可以看到這些點:
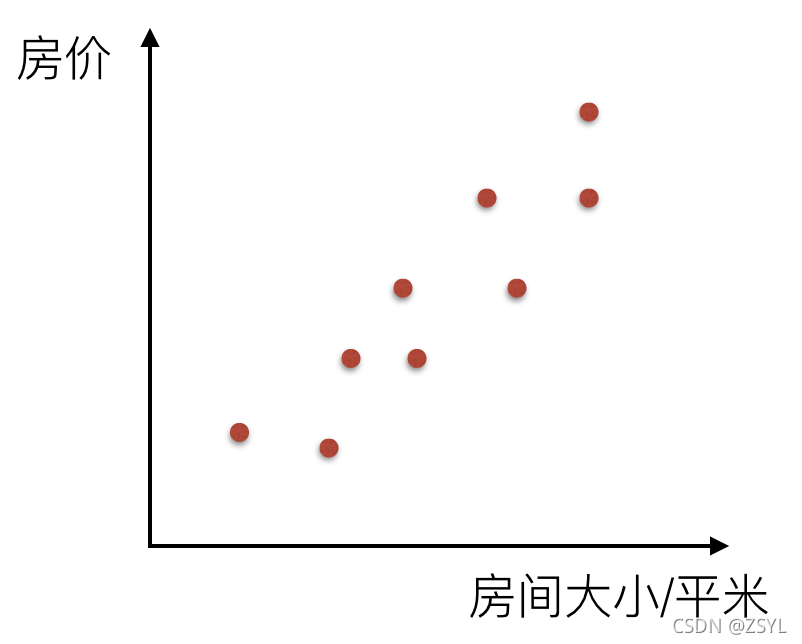
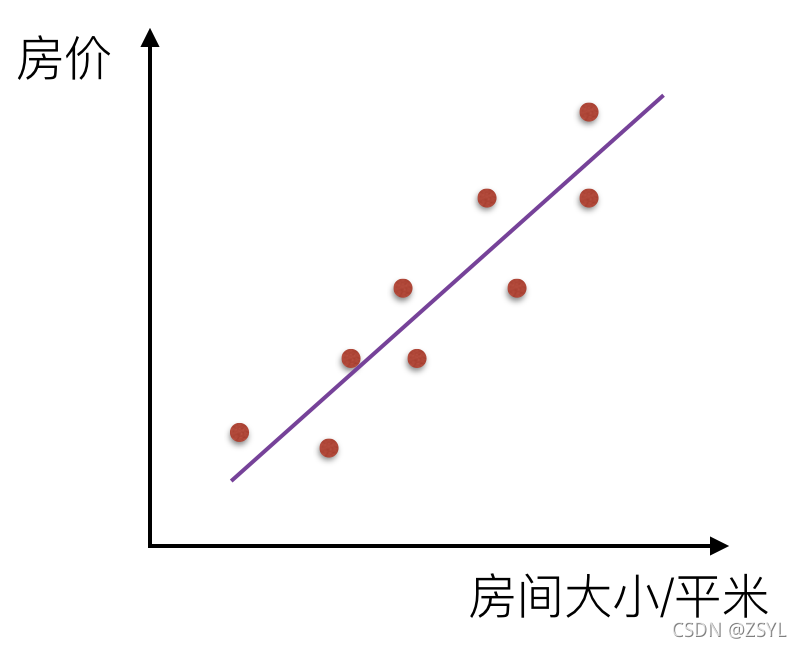
如果房間面積大小和房價的關系可以用一根直線表示,那么這就是線性關系:
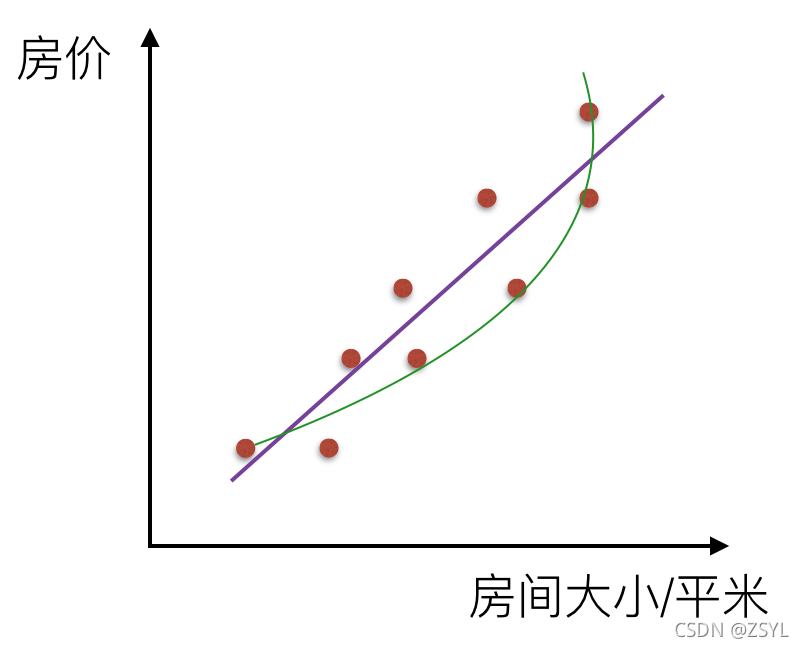
而如果不是一根直線,那么就是非線性關系:
線性回歸
線性回歸通過一個或者多個自變數與因變數之間進行建模的回歸分析,其中特點為一個或多個稱為回歸系數的模型引數的線性組合,
線性回歸方程:
線性回歸方程,就是有k個特征,然后每個特征都有相應的系數,并且在所有特征值為0的情況下,目標值有一個默認值,因此線性回歸方程如下:
h
(
𝑤
)
=
𝑤
?
+
𝑤
?
?
𝑥
?
+
𝑤
?
?
𝑥
?
+
…
?(𝑤)= 𝑤? + 𝑤?*𝑥? + 𝑤?*𝑥?+…
h(w)=w?+w??x?+w??x?+…
整合后的公式為:
h
(
w
)
=
∑
i
n
w
i
x
i
=
θ
T
x
h(w)=∑_i^nw_ixi=θ^Tx
h(w)=i∑n?wi?xi=θTx
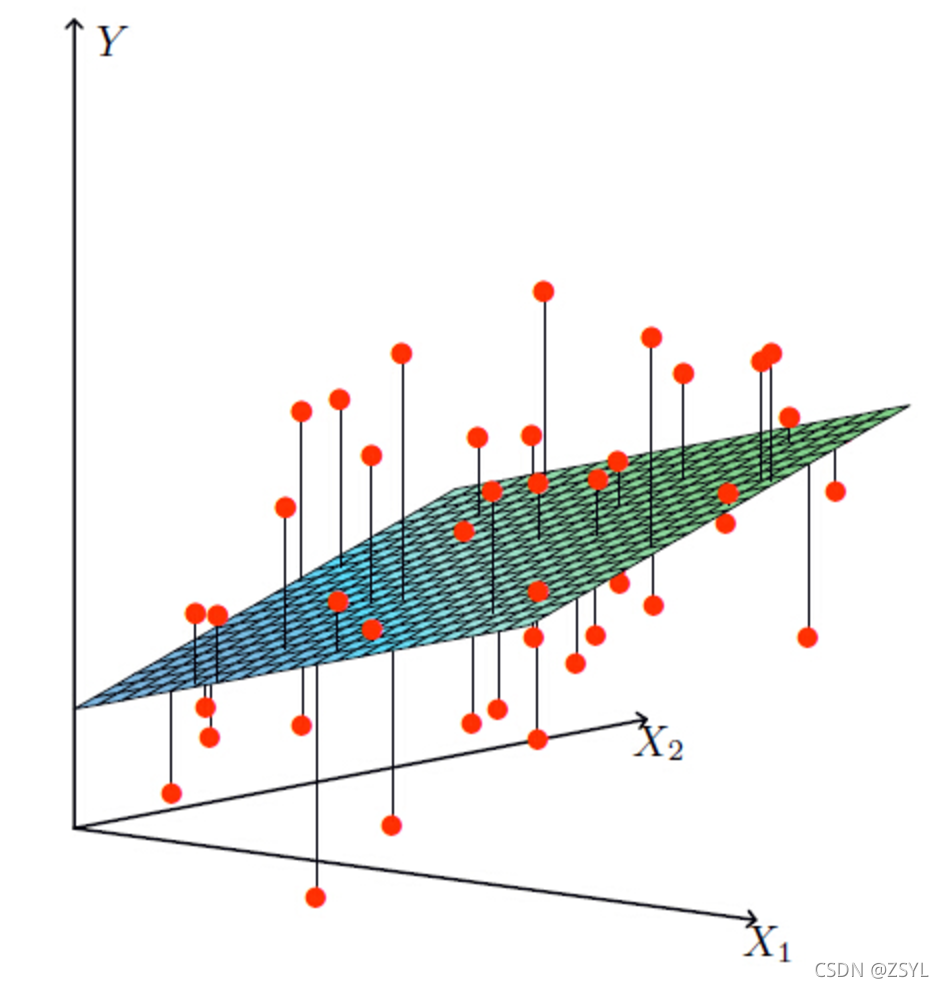
損失函式:
損失函式是一個貫穿整個機器學習重要的一個概念,大部分機器學習演算法都會有誤差,我們得通過顯性的公式來描述這個誤差,并且將這個誤差優化到最小值,
假設現在真實的值為y,預測的值為h,那么損失函式的公式如下:
J
(
θ
)
=
1
2
∑
i
m
(
y
(
i
)
?
θ
T
x
(
i
)
)
2
J(θ)=\frac{1}{2}∑_i^m(y^{(i)}-θ^Tx^{(i)})^2
J(θ)=21?i∑m?(y(i)?θTx(i))2
也就是所有誤差和的平方,損失函式值越小,說明誤差越小.這個損失函式也有一個專門的叫法,叫做最小二乘法,
損失函式推理程序:
公式轉換:
首先,我們是想要獲取到這樣一個公式:
h
(
θ
)
=
θ
0
+
θ
1
?
x
1
+
θ
2
?
x
2
+
…
?(θ)= θ_0 + θ_1*x_1 + θ_2*x_2+…
h(θ)=θ0?+θ1??x1?+θ2??x2?+…
那么為了更好的計算,我們將這個公式進行一些變形,將
w
0
w_0
w0?后面加個
x
0
x_0
x0?,只不過這個
x
0
x_0
x0?是為1,所以可以變化成以下:
h
(
θ
)
=
∑
i
n
θ
i
x
i
?(θ)= ∑_i^nθ_ix_i
h(θ)=i∑n?θi?xi?
而
θ
i
θ_i
θi?和
x
i
x_i
xi?可以寫成一個矩陣:
[
θ
0
θ
1
θ
3
.
.
.
]
\left[\begin{matrix} θ_0 θ_1 θ_3 ... \end{matrix} \right]
[θ0?θ1?θ3?...?] x
[
1
x
1
x
3
.
.
.
]
\left[\begin{matrix} 1 \\ x_1 \\ x_3 \\ ... \end{matrix} \right]
?????1x1?x3?...?????? =
∑
i
n
θ
i
x
i
∑_i^nθ_ix_i
∑in?θi?xi? =
θ
T
x
θ^Tx
θTx
用矩陣主要是方便計算,
誤差公式:
其次,以上求得的,只是一個預測的值,而不是真實的值,他們中間肯定會存在誤差,因此會有以下公式:
y
i
=
θ
i
x
i
+
?
i
y_i=θ_ix_i + ?_i
yi?=θi?xi?+?i?
我們要做的,就是找出最小的
?
i
?_i
?i?,使得預測值和真實值的差距最小,
轉化為θ求解:
然后,
?
i
?_i
?i?是存在正數,也存在負數,所以可以簡單的把這個資料集,看做是一個服從均值為0,方差為
σ
2
σ^2
σ2的正態分布,所以
?
i
?_i
?i?出現的概率為:
p ( ? i ) = 1 2 π σ e x p ? ( ? i ) 2 2 σ 2 p(?_i)=\frac{1}{\sqrt{2π}σ}exp{\frac{-(?_i)^2}{2σ^2}} p(?i?)=2π ?σ1?exp2σ2?(?i?)2?
把 ? i = y i ? θ i x i ?_i=y_i-θ_ix_i ?i?=yi??θi?xi?代入到以上高斯分布的函式中,變成以下式子:
p ( ? i ) = 1 2 π σ e x p ? ( y i ? θ i x i ) 2 2 σ 2 p(?_i)=\frac{1}{\sqrt{2π}σ}exp{\frac{-(y_i-θ_ix_i)^2}{2σ^2}} p(?i?)=2π ?σ1?exp2σ2?(yi??θi?xi?)2?
所以我們就成功的將誤差的求解,轉換成了θ的求解了,
我們應該求
p
(
?
i
)
p(?_i)
p(?i?)最大的時候的θ,(PS:用貸款的例子理解一下,銀行給人貸款,多貸或少貸幾百,都是很正常的,但是如果多貸或者少貸太多,從正態分布來說,概率很小,而把銀行貸款,多貸和少貸看成是誤差,那么我們肯定是想要誤差小的,因此也就是要求出現的最大的概率的誤差值,
似然函式求θ:
似然函式的主要作用,就是在已經知道變數x的情況下,調整θ,使得概率y的值最大,
以拋硬幣為例,假設你拿到了一枚硬幣,正常來說一列舉勻的硬幣出現正反面的概率應該相同,都是 0.5 ,但是你不確定這枚材質、重量分布情況,需要判斷其是否真的是均勻分布,
所以,這里假設這枚硬幣有 θ 的概率會正面向上,有 1-θ 的概率反面向上,為了獲得 θ 的值,你做了一個實驗:將硬幣拋 10 次,得到了一個正反序列 x=HHTTHTHHHH ,這次實驗滿足二項分布,那么出現這個序列的概率為 θθ(1-θ)(1-θ)θ(1-θ)θθθθ = θ7(1-θ)3 ,
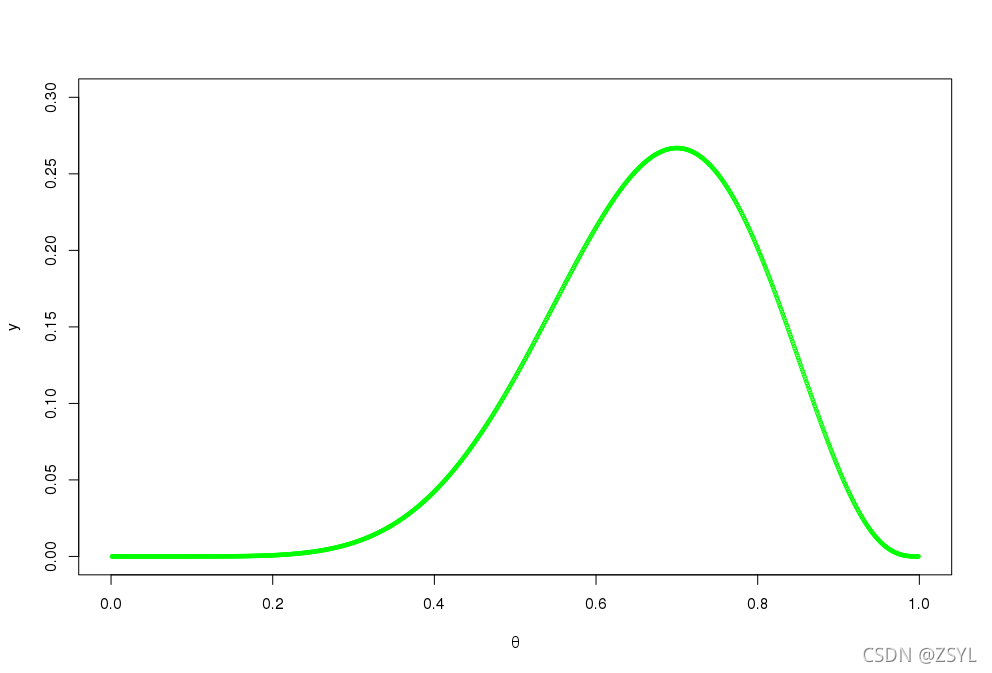
到此為止,我們根據一次簡單的二項分布實驗,得到了一個關于 θ 的函式,這實際上就是一個似然函式,當 θ 為 0 或者 1 時,對應的概率為 0 ;而當 θ 值為 1/2 時,對應的概率為 1/1024 … …
可以根據不同的 θ 值,繪制出一條曲線,這個曲線就是 θ 的似然函式,而 y 軸表示出現這一現象的概率,單純對于這次實驗來說,因為這一現象已經出現,那么可以相信,在似然函式最大值所在的 θ 評估為目前認為的合理 θ 值,也即是 0.7 ,但是,你不能得出最終的結論 θ = 0.7,因為這里僅僅試驗了一次,得到的樣本太少,所以最終求出的最大似然值偏差較大,如果經過多次試驗,擴充樣本空間,則最終求得的最大似然估計可能將接近真實值 0.5 ,
參考自:
https://jin-yang.github.io/post/math-statistics-likelihood-function-introduce.html,
所以以上,我們可以得出求θ的似然函式為:
L ( θ ) = ∏ i m 1 2 π σ e x p ? ( y i ? θ i x i ) 2 2 σ 2 L(θ) = ∏_i^m\frac{1}{\sqrt{2π}σ}exp{\frac{-(y_i-θ_ix_i)^2}{2σ^2}} L(θ)=i∏m?2π ?σ1?exp2σ2?(yi??θi?xi?)2?
對數似然:
累乘的方式不太方便我們去求解θ,那么我們可以轉換成對數似然,也就是將以上公式放到對數中,然后就可以轉換成一個加法運算:
l o g ( L ( θ ) ) = l o g ∏ i m 1 2 π σ e x p ? ( y i ? θ i x i ) 2 2 σ 2 = ∑ i n l o g 1 2 π σ e x p ? ( y i ? θ i x i ) 2 2 σ 2 log(L(θ)) = log∏_i^m\frac{1}{\sqrt{2π}σ}exp{\frac{-(y_i-θ_ix_i)^2}{2σ^2}} = ∑_i^nlog\frac{1}{\sqrt{2π}σ}exp{\frac{-(y_i-θ_ix_i)^2}{2σ^2}} log(L(θ))=logi∏m?2π ?σ1?exp2σ2?(yi??θi?xi?)2?=i∑n?log2π ?σ1?exp2σ2?(yi??θi?xi?)2?
以上公式進行化簡后得出:
l o g ( L ( θ ) ) = n l o g 1 2 π σ ? 1 σ 2 ? 1 2 ∑ i n ( y i ? θ i x i ) 2 log(L(θ)) = nlog\frac{1}{\sqrt{2π}σ} - \frac{1}{σ^2}*\frac{1}{2}∑_i^n(y_i-θ_ix_i)^2 log(L(θ))=nlog2π ?σ1??σ21??21?i∑n?(yi??θi?xi?)2
在這里我們不用去關心log后的值會改變,因為我們不是要去求極值,而是要去求極值點,
損失函式:
我們是想要把上面式子求得最大值,然后再獲取最大值時候的θ,而上面式子中減號前面的
n
l
o
g
1
2
π
σ
nlog\frac{1}{\sqrt{2π}σ}
nlog2π
?σ1?是一個常數項,所以只要把減號后面的變得最小即可,而減號后面的部分,可以把常數項
1
σ
2
\frac{1}{σ^2}
σ21?去掉,因此得到最終的損失函式為:
J ( θ ) = 1 2 ∑ i n ( y i ? θ i x i ) 2 J(θ) = \frac{1}{2}∑_i^n(y_i-θ_ix_i)^2 J(θ)=21?i∑n?(yi??θi?xi?)2
可能有的同學會說,上面其他常數項都能直接約掉,為什么1/2不約掉,原因是為了方便后期求偏導留下的,
損失函式越小,那么說明預測的值是越接近真實值,這個損失函式也叫作最小二乘法,
梯度下降:
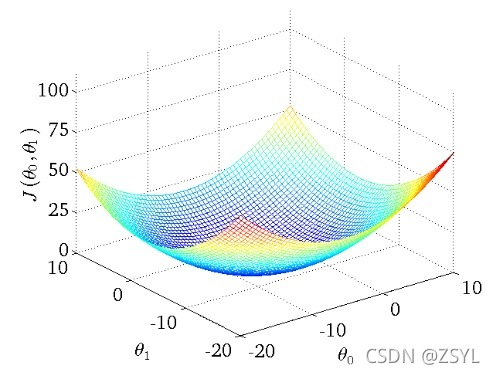
梯度下降,非常通俗的理解就是,把對以上“損失函式”最小值的求解,形象的比喻成梯子,然后不斷的下降,直到找到最低的值,我們以上圖為例,上圖中有兩個維度,我們要做的,就是求出兩個維度上 θ 0 θ_0 θ0?和 θ 1 θ_1 θ1?,使得損失函式最小,
批量梯度下降(BGD):
批量梯度下降,是在每次求解程序中,把所有資料都進行考察,因此損失函式應該要在損失函式中加上一個
m
m
m,來求平均值:
J
(
θ
)
=
1
2
m
∑
i
m
(
θ
i
x
i
?
y
i
)
2
J(θ) = \frac{1}{2m}∑_i^m(θ_ix_i-y_i)^2
J(θ)=2m1?∑im?(θi?xi??yi?)2
我們要去求一個點的方向,也就是要去求他的斜率,而對這個點求導數,就是他的斜率,所以我們只要求出J(θ)的導數就知道他要往哪個方向下降了,J(θ)的導數為:
? J ( θ ) ? θ j = ? 1 m ∑ i m ( y j ? h θ ( x i ) ) x j i \frac{?J(θ)}{?θ_j} = -\frac{1}{m}∑_i^m(y^j-h_θ(x^i))x_j^i ?θj??J(θ)?=?m1?i∑m?(yj?hθ?(xi))xji?
導數的方向,都是往上走的,現在我們要往梯度下降,因此在以上式子前面加個負號,就得到了下降的方向,而下降是在當前點的基礎之上下降的,因此下降后的點為:
θ j ‘ = θ j + 1 m ∑ i m ( y j ? h θ ( x i ) ) x j i θ_j^` = θ_j+\frac{1}{m}∑_i^m(y^j-h_θ(x^i))x_j^i θj‘?=θj?+m1?i∑m?(yj?hθ?(xi))xji?
以此回圈,直到找到最低的點,
隨機梯度下降(SGD):
以上是批量梯度下降,每次下降一個點,都要把所有資料都計算一遍,如果資料量少還可以說,但是如果資料量特別大,那么會導致訓練的程序會非常耗時,因此我們有另外一種解決方法叫做隨機梯度下降:
θ j ‘ = θ j + ( y j ? h θ ( x i ) ) x j i θ_j^` = θ_j+(y^j-h_θ(x^i))x_j^i θj‘?=θj?+(yj?hθ?(xi))xji?
隨機梯度下降是通過每個樣本來迭代更新一次,對比上面的批量梯度下降,迭代一次需要用到所有訓練樣本(往往如今真實問題訓練資料都是非常巨大),一次迭代不可能最優,如果迭代10次的話就需要遍歷訓練樣本10次,但是,SGD伴隨的一個問題是噪音較BGD要多,使得SGD并不是每次迭代都向著整體最優化方向,
mini-batch小批量梯下降MBGD:
我們從上面兩種梯度下降法可以看出,其各自均有優缺點,那么能不能在兩種方法的性能之間取得一個折衷呢?即,演算法的訓練程序比較快,而且也要保證最終引數訓練的準確率,而這正是小批量梯度下降法(Mini-batch Gradient Descent,簡稱MBGD)的初衷,
θ j ‘ = θ j + α 1 n ∑ i n ( y j ? h θ ( x i ) ) x j i θ_j^` = θ_j+α\frac{1}{n}∑_i^n(y^j-h_θ(x^i))x_j^i θj‘?=θj?+αn1?i∑n?(yj?hθ?(xi))xji?
這里面有一個α,用來表示學習速率,每次下降的多少,
線性回歸案例:
我們用線性回歸來預測波士頓房價,正規方程的線性回歸用的是sklearn.linear_model.LinearRegression,梯度下降用的是sklearn.linear_model.SGDRegressor,并且在預測完成后,我們想要知道預測的好壞的指標,可以通過以下幾種方式進行判別:
- 均方誤差:
sklearn.metrics.mean_squared_error(y_true, y_pred),(誤差平方和的均值), - 平均絕對誤差:
sklearn.metrics.mean_absolute_error(y_true, y_pred)(誤差的平均),
都是越小越好,
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_squared_error
# 加載資料
boston = load_boston()
# 分割資料
feature_train,feature_test,target_train,target_test = train_test_split(boston.data,boston.target)
# 標準化資料
scaler_feature = StandardScaler()
feature_train = scaler_feature.fit_transform(feature_train)
feature_test = scaler_feature.transform(feature_test)
scaler_target = StandardScaler()
target_train = scaler_target.fit_transform(target_train.reshape(-1,1))
target_test = scaler_target.transform(target_test.reshape(-1,1))
# 線性回歸(正規方程)
linear = LinearRegression()
linear.fit(feature_train,target_train)
predict_target_test = scaler_target.inverse_transform(linear.predict(feature_test))
# 計算下正規方程的效果
mean_squared_error(scaler_target.inverse_transform(target_test),predict_target_test)
平均誤差: 3.5551177273809675
均方誤差: 23.398991931904934
# 線性回歸(梯度下降)
sgd = SGDRegressor()
sgd.fit(feature_train,target_train)
# inverse_transform(X_scaled)是將標準化后的資料轉換為原始資料,
predict_target_test = scaler_target.inverse_transform(sgd.predict(feature_test))
# 計算下梯度下降的效果
mean_squared_error(scaler_target.inverse_transform(target_test),predict_target_test)
sgd = SGDRegressor()
sgd.fit(X_train,y_train)
y_predict = sgd.predict(X_test)
print("平均誤差:",mean_absolute_error(y_test,y_predict))
print("均方誤差:",mean_squared_error(y_test,y_predict))
print(sgd.coef_)
print(sgd.intercept_)
平均誤差: 3.529515670299321
均方誤差: 26.251415587814122
[-0.87227423 0.37914079 -0.40098034 0.53969983 -0.58406232 3.51620633
-0.53168955 -1.77872109 0.64529551 -0.49328478 -1.86208871 1.16501472
-3.19140456]
[21.95477955]
正則化與嶺回歸:
正則化出現的目標,就是為了防止過擬合的現象,公式如下:
J ( θ ) = M S E ( θ ) + λ 1 2 ∑ i n θ i 2 J(θ)=MSE(θ) + λ\frac{1}{2}∑_i^nθ_i^2 J(θ)=MSE(θ)+λ21?i∑n?θi2?
λ越大,加號后面部分越大,而我們想要的是最小的,因此λ越大,說明懲罰力度是越大的,但是并不是越大越好,太大了,可能會導致模型處理擬合得不好,導致最終預測評分更低,
嶺回歸,就是加入了正則懲罰項的回歸,可以用sklearn.linear_model.Ridge來實作:
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1)
ridge.fit(X_train,y_train)
y_predict = ridge.predict(X_test)
print("平均誤差:",mean_absolute_error(y_test,y_predict))
print("均方誤差:",mean_squared_error(y_test,y_predict))
平均誤差: 3.5483844638304287
均方誤差: 23.582466794809744
[-0.87227423 0.37914079 -0.40098034 0.53969983 -0.58406232 3.51620633
-0.53168955 -1.77872109 0.64529551 -0.49328478 -1.86208871 1.16501472
-3.19140456]
[21.95477955]
總結:
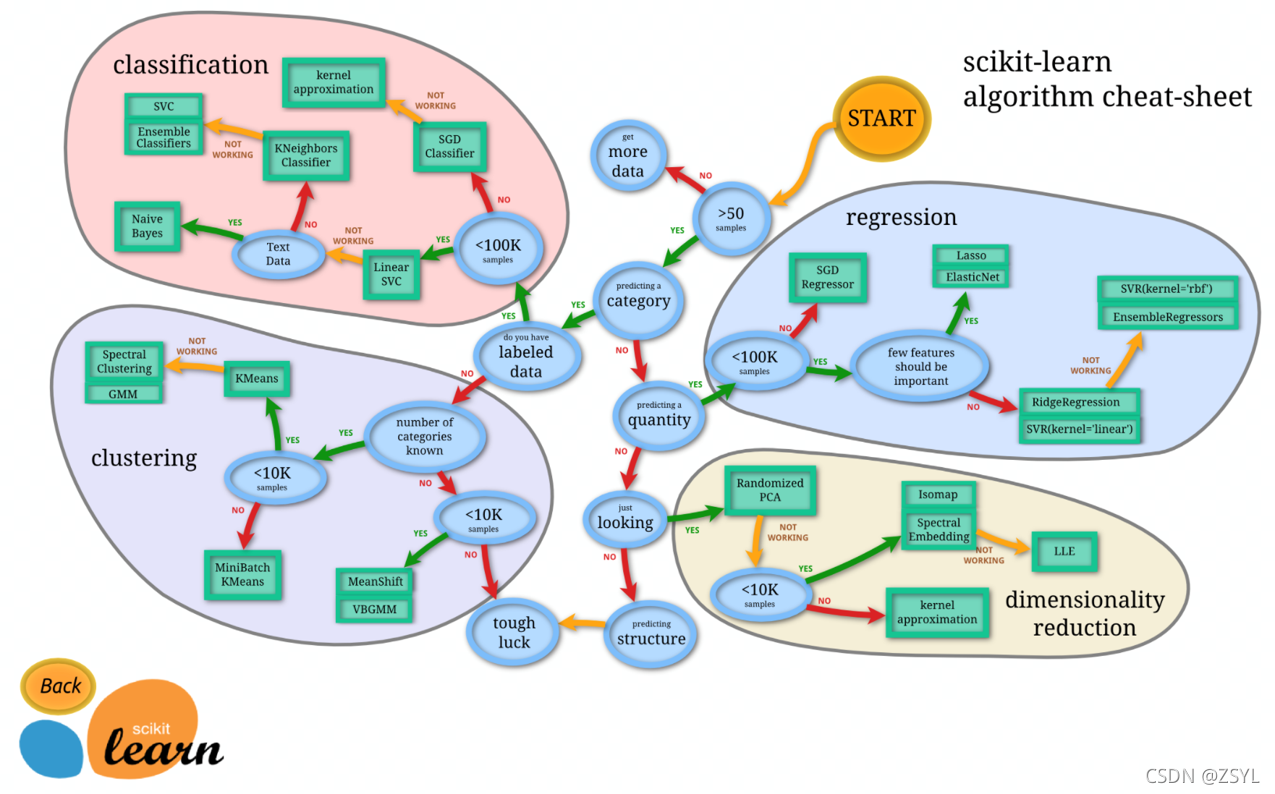
通過上圖我們可以發現,當資料量小于10W的時候,正規方程,否則就選擇SGD,也就是說在資料量比較少的情況下,正規方程更有優勢,在資料量比較大的時候SGD會更加準確,
邏輯回歸
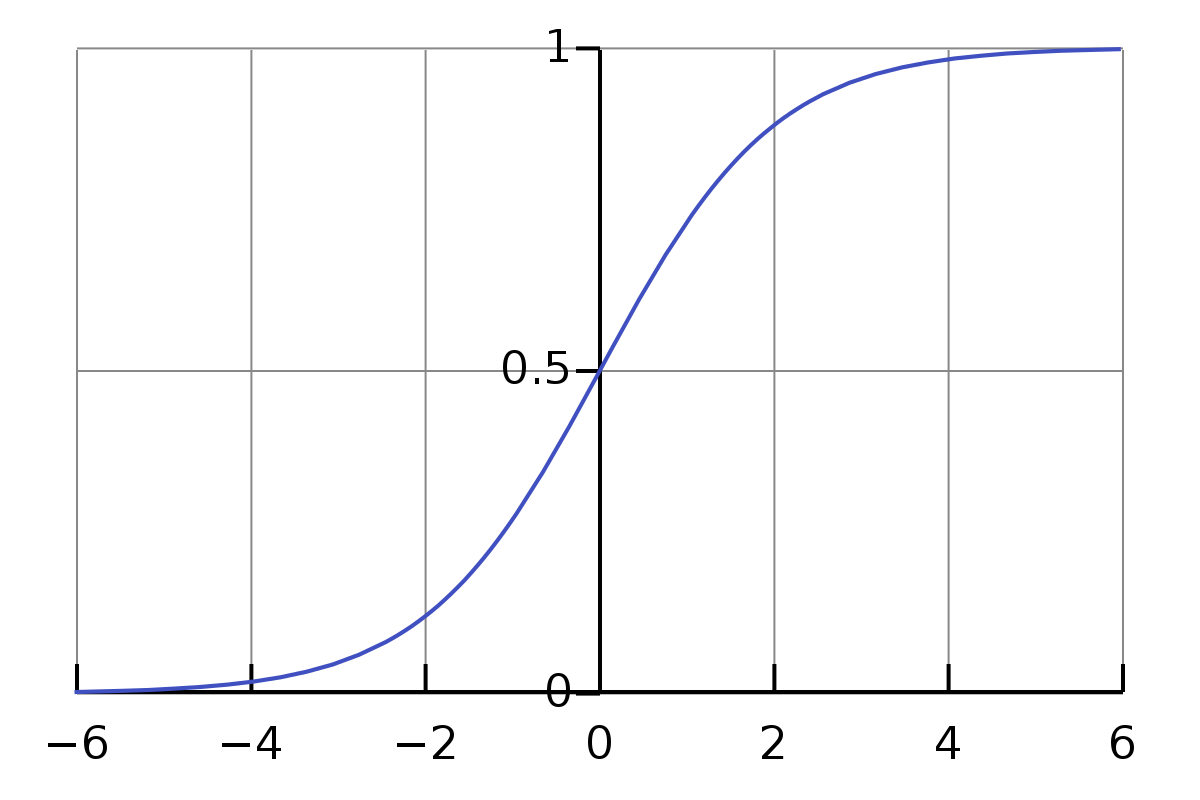
邏輯回歸(Logistic Regression),簡稱LR,它的特點是能夠是我們的特征輸入集合轉化為0和1這兩類的概率,一般來說,回歸不用在分類問題上,但邏輯回歸卻在二分類問題上表現很好,邏輯回歸本質上是線性回歸,只是在特征到結果的映射中加入了一層Sigmod函式映射,即先把特征線性求和,然后使用Sigmoid函式將最為假設函式來概率求解,再進行分類,
Sigmoid函式為:
g
(
z
)
=
1
1
+
e
?
z
g(z) = \frac{1}{1+e^{-z}}
g(z)=1+e?z1?
其中的z就是我們使用模型預測的結果,
精確率和召回率:
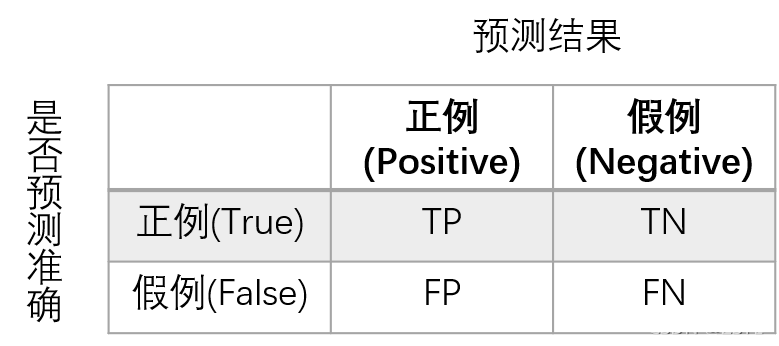
- 精確率:預測結果為正例樣本中真實為正例的比例(查得準),公式為:P=TP/(TP+FP)
- 召回率:真實為正例的樣本中預測結果為正例的比例(查的全,對正樣本的區分能力),公式為:R=TP/(TP+FN)
- 綜合指標
F1:P和R指標有時候會出現的矛盾的情況,這樣就需要綜合考慮他們,最常見的方法就是F-Measure,公式為: F 1 = 2 ? P ? R P + R F1=\frac{2*P*R}{P+R} F1=P+R2?P?R?,
癌癥患者邏輯回歸案例:
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
# 地址路徑
names = ["Sample code number ","Clump Thickness","Uniformity of Cell Size","Uniformity of Cell Shape","Marginal Adhesion","Single Epithelial Cell Size","Bare Nuclei","Bland Chromatin","Mitoses","Class"]
breast = pd.read_csv("./data/breast-cancer-wisconsin.data",names=names)
breast = breast.replace(to_replace="?",value=np.nan)
breast = breast.dropna()
# 切分資料
x_train,x_test,y_train,y_test = train_test_split(breast[names[1:-1]],breast[names[-1]],test_size=0.25)
# 標準化資料
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# 邏輯回歸
lg = LogisticRegression(C=1.0)
lg.fit(x_train,y_train)
y_predict = lg.predict(x_test)
print("準確率:",lg.score(x_test,y_test))
print("召回率:",classification_report(y_test,y_predict,labels=[2,4],target_names=['良性','惡性']))
準確率: 0.9415204678362573
precision recall f1-score support
良性 0.94 0.97 0.95 104
惡性 0.95 0.90 0.92 67
micro avg 0.94 0.94 0.94 171
macro avg 0.94 0.93 0.94 171
weighted avg 0.94 0.94 0.94 171
邏輯回歸總結:
- 優點:適合需要得到一個分類概率的場景,簡單,速度快,
- 缺點:只能用來處理二分類問題,不好處理多分類問題,
- 應用:是否患病、金融詐騙、是否為虛假賬號,
加油!
感謝!
努力!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356889.html
標籤:AI
上一篇:EDG奪冠,用爬蟲+資料分析+自然語言處理(情感分析)+資料可視化分析3萬條資料:粉絲都瘋了(唯一原創)
下一篇:【推薦系統論文精讀系列】(四)--Practical Lessons from Predicting Clicks on Ads at Facebook