文章目錄
- 說在前面
- 人話模式
- 1.探索前的熱身
- 2.探索ing
- 原始碼
- 說在后面
說在前面
? 今天的視頻在講解原始碼,不出意外的我又在迷糊中聽了大半,老師在后面搖了好幾下我才醒,然后就被安排了一個偉大而艱巨的任務——學會自己看原始碼……
? 怎么辦呢?那就看嘛!在看之前我還不忘百度搜索一下看原始碼的好處,下方為知乎某大佬原話
“我為什么讀原始碼”
很多人一定和我一樣的感受:原始碼在作業中有用嗎?用處大嗎?很長一段時間內我也有這樣的疑問,認為哪些有事沒事扯原始碼的人就是在裝,只是為了提高他們的逼格而已,
那為什么我還要讀原始碼呢?一剛開始為了面試,后來為了解決作業中的問題,再后來就是個人喜好了,說的好聽點是有匠人精神;說的委婉點是好奇(底層是怎么實作的);說的不自信點是對黑盒的東西我用的沒底,怕用錯;說的簡單直白點是提升自我價值,為了更高的薪資待遇(這里對真正的技術迷說聲抱歉),
原始碼中我們可以學到很多東西,學習別人高效的代碼書寫、學習別人對設計模式的熟練使用、學習別人對整個架構的布局,等等,如果你還能找出其中的不足,那么恭喜你,你要飛升了!會使用固然重要,但知道為什么這么使用同樣重要,從模仿中學習,從模仿中創新,
讀原始碼不像圍城(外面的人想進來,里面的人想出去),它是外面的人不想進來,里面的人不想出去;當我們跨進城內,你會發現(還是城外好,皮!)城內風光無限,原始碼的海洋任我們遨游!

走!看原始碼!看原始碼!
人話模式
1.探索前的熱身
一個結論:
FileInputFormat 是InputFormat的子實作類,實作切片邏輯
TextInputFormat是FileInputFormat的子實作類,實作讀取資料邏輯
先探索一下TextInputFormat怎么就實作了讀取資料的邏輯吧!
故事得從提交作業開始說起……
腦海里對提交作業后有個大概的思路:提交job–>然后……->mapreduce,中間省略若干步驟(為什么不寫大家懂得都懂)
在提交job的方法檔案注釋上我發現了以下珍貴文案,于是三年沒學英語的我站出來了!
/**
* Internal method for submitting jobs to the system.
譯:系統提交檔案的內部方法,
*
* <p>The job submission process involves:
譯:作業提交程序涉及到:
* <ol>
* <li>
* Checking the input and output specifications of the job.
譯:檢查作業的輸入和輸出的規格,
* </li>
* <li>
* Computing the {@link InputSplit}s for the job.
譯:計算作業的輸入切片,
* </li>
* <li>
* Setup the requisite accounting information for the
* {@link DistributedCache} of the job, if necessary.
譯:如果必要的話,為作業的分布式快取設定必要的計算資訊,
* </li>
* <li>
* Copying the job's jar and configuration to the map-reduce system
* directory on the distributed file-system.
譯:拷貝作業的jar包和配置到hdfs的MapReduce系統的目錄
* </li>
* <li>
* Submitting the job to the <code>JobTracker</code> and optionally
* monitoring it's status.
譯:提交作業到jobTracker(大概是作業追蹤器)然后可選地追蹤它的狀態,
所以!大概思路就是上面的譯文了!
總結一下:
-
作業提交程序涉及到: 1. **檢查作業的輸入和輸出的規格,** 2. **計算作業的輸入切片,** 3. **如果必要的話,為作業的分布式快取設定必要的計算資訊,** 4. **拷貝作業的jar包和配置到hdfs的MapReduce系統的目錄** 5. **提交作業到jobTracker(大概是作業追蹤器)然后可選地追蹤它的狀態,**
讓我們把今天的目光聚焦到切片機制,我們往下找啊找….終于找到了寫切片的地方啦,進入writeSplits方法,

方法體如下:
writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
你還別說,確實…看不大懂,不過我們看第6、7行還是沒問題的,這個邏輯判斷就是看你使用的Mapper是舊版的還是新版的,好,我們走進writeNewSplits……
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
代碼依舊那么復雜呀,不過我還記得第一步是檢查輸入檔案的規格,因此我們要看看它是怎么檢查的,于是走進第六行job.getInputFormatClass方法,

顯然這是個介面方法,我們要做的是找到它具體的實作邏輯,因此點擊左邊框內的小綠點找它的具體實作類,如下:

我們知道現在提交的job與map和reduce無關,而最有可能的是最JobContext的實作方法,因此點進去
/**
* Get the {@link InputFormat} class for the job.
*
* @return the {@link InputFormat} class for the job.
*/
@SuppressWarnings("unchecked")
public Class<? extends InputFormat<?,?>> getInputFormatClass()
throws ClassNotFoundException {
return (Class<? extends InputFormat<?,?>>)
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}
注意力只要放在第十行代碼那里,INPUT_FORMAT_CLASS_ATTR的值為TextInputFormat.class,所以,當我們不指定輸入檔案規格的時候呢,默認的規格是文本輸入規格,這也就是為什么我們在對檔案做Mapreduce的時候需要指定輸入和輸出檔案規格了!
這也佐證了為什么TextInputFormat負責讀取資料的邏輯了!
看似沒用, 其實鍛煉了我們探索的能力!
2.探索ing
探索1的結論還記得嗎?
FileInputFormat 是InputFormat的子實作類,實作切片邏輯,
TextInputFormat是FileInputFormat的子實作類,實作讀取資料邏輯,
怎么樣通過抽象方法找到它的實作呢?這就用到啦!
教你們個小技巧,首先找到InputFormat這個抽象類,我們通過(ALT+7)類結構驚奇的發現:
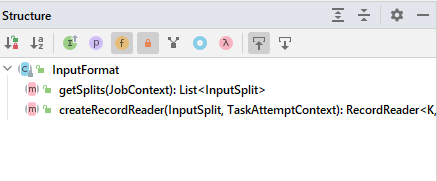
它定義了兩個抽象方法恰恰是切片(getSplits)和讀取資料(createRecordReader),我們目的專一,

點擊左框綠點,找到它的實作邏輯—-FileInputFormat類

準備好了嗎?準備好了!
各單位注意!!!原始碼來啦!!!
現在是2021年11月12日21:37:56,會是什么時候搞完睡覺呢?
原始碼
各單位注意,中文注釋是小鵬自己理解來寫的,其他都是原始碼作者寫的,
public List<InputSplit> getSplits(JobContext job) throws IOException {
//StopWtch是測時單位,可以以納秒為單位,這里開始計時,到結尾我們可以觀察到有對應的stop方法,用作統計該切分使用的時間,不用關注
StopWatch sw = new StopWatch().start();
/*將兩個變數較大值作為切片的最小值,前者是固定值1,后者可以配置,如果沒有配置的話使用默認值,可以在mapred-site.xml的"mapreduce.input.fileinputformat.split.minsize"
查看到,默認值為0,
*/
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//切片最大值默認為Long型別的最大邊界值2**63-1,也可以通過"mapreduce.input.fileinputformat.split.maxsize"設定,
long maxSize = getMaxSplitSize(job);
// generate splits
//新建一個InputSplit型別的集合用來存放所有切片物件,也將splits作為本方法的回傳值
List<InputSplit> splits = new ArrayList<InputSplit>();
//通過job提供的輸入路徑拿到當前目錄下所有檔案的詳情
List<FileStatus> files = listStatus(job);
//顧名思義,忽略檔案夾
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
//遍歷串列中檔案的詳情
for (FileStatus file: files) {
//如果是目錄或者是忽略檔案夾則跳過
if (ignoreDirs && file.isDirectory()) {
continue;
}
//獲取檔案路徑
Path path = file.getPath();
//獲取檔案的內容大小
long length = file.getLen();
//如果不是空檔案
if (length != 0) {
//BlockLocation[]包括塊的網路位置、包含塊副本的主機的資訊以及其他塊元資料(例如與塊關聯的檔案偏移量、長度、是否損壞等)
BlockLocation[] blkLocations;
//判斷instanceof左邊顯式宣告的型別與右邊操作元是否是同種類或存在繼承關系
//如果是本地檔案
if (file instanceof LocatedFileStatus) {
//獲取塊位置資訊
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
//否則是集群檔案
FileSystem fs = path.getFileSystem(job.getConfiguration());
//獲取塊位置資訊
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
//是否可切片,通常是正確的,但如果檔案是流壓縮的,則不會,
if (isSplitable(job, path)) {
//獲取資料塊大小
long blockSize = file.getBlockSize();
//計算切片的大小-->一般情況下永遠都是塊大小 128M
//方法內部通過 默認的最大切片值和資料塊大小的較小值 與最小切片大小 比較的較大值作為切片大小
/*方法如下
*protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
*/
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
//將檔案的剩余大小賦值
long bytesRemaining = length;
//判斷當前檔案的剩余內容是否要繼續切片,公式:bytesRemaining)/splitSize > SPLIT_SLOP
//解讀:檔案剩余大小/切片的大小 是否> split_slop(值為1.1) 如果除出來的值>1.1就會繼續切,否則就將剩余內容作為一個片處理,目的是為了讓每一個MapTask處理的資料更加的均衡,
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//獲取需要切分的塊在檔案中的偏移量,從此處開始切
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
//制作一個切片物件并加入到存放切片物件的陣列中
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
//檔案剩余內容減去該切片的大小
bytesRemaining -= splitSize;
}
//這里的邏輯判斷是建立在檔案剩余大小/切片的大小 <= split_slop(值為1.1) 的情況,也就是說只剩下最后一點點了,這個時候再創建一個片并添加到切片物件的陣列中本次切片就圓滿完成了
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
}
//這里的else對應的是上訪的是否可以切分,不能的話就會開始日志或者debug來襲,,
else { // not splitable
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
//這里是在檔案長度不為0但不能切分的條件下執行的只創建一個切片物件(因為不能切分說明該檔案很小)
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
}
//這里對應的是檔案長度為0的情況
else {
//Create empty hosts array for zero length files
//創建一個空的物件陣列
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
//保存輸入檔案的數量作為加載源
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
//停止計時,并列印切片數目和花費時間
//回傳切分后的物件
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
說在后面
現在的時間是2021年11月12日23:30:42,
第一次認真的探索原始碼,我有點喜歡上了這種探索的感覺,一定會有下一次,下下次以及很多次的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356938.html
標籤:其他