文章目錄
- 1. 題目
- 1.1 示例
- 1.2 說明
- 1.3 限制
- 2. 解法一
- 2.1 分析
- 2.2 實作
- 2.3 復雜度
1. 題目
給定一棵二叉樹的根節點,請回傳所有的重復子樹,對于每一類重復子樹,你只需要回傳其中任意一個的根節點即可,如果兩棵二叉樹擁有相同的結構和節點值,則稱這兩棵二叉樹是重復的,
1.1 示例
-
示例 1 1 1 :
- 輸入:
root = [1, 2, 3, 4, null, 2, 4, null, null, 4] - 輸出:
[[2, 4], [4]]
- 輸入:
-
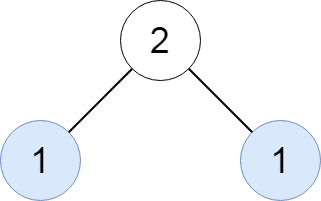
示例 2 2 2 :
- 輸入:
root = [2, 1, 1] - 輸出:
[[1]]
- 輸入:
-
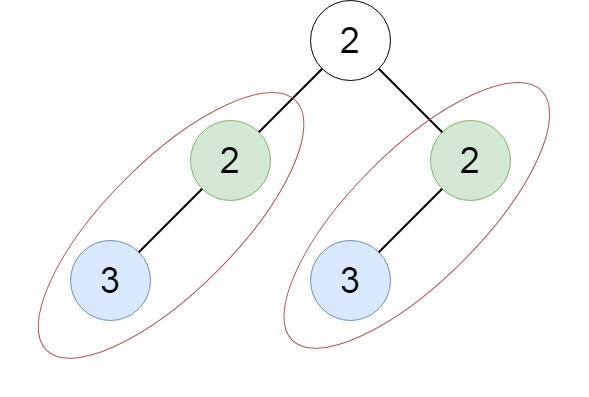
示例 3 3 3 :
- 輸入:
root = [2, 2, 2, 3, null, 3, null] - 輸出:
[[2, 3], [3]]
- 輸入:
1.2 說明
- 來源: 力扣(LeetCode)
- 鏈接: https://leetcode-cn.com/problems/find-duplicate-subtrees
1.3 限制
- 二叉樹中的節點數量在 [ 1 , 1 0 4 ] [1,\textit{ }10^4] [1, 104] 之間;
-200 <= Node.val <= 200,
2. 解法一
2.1 分析
想要正確解答本題,只需要知道如何給出二叉樹的某種唯一性表達即可,接下來首先獲得以給定二叉樹的所有節點為根節點的子二叉樹的表達形式,然后得到所有重復表達形式對應子樹的根節點即可,
實際上,所謂給出二叉樹的某種唯一表達其實就是對二叉樹進行序列化,而在【LeetCode 二叉樹專項】二叉樹的序列化與反序列化(297)中,我們給出了基于二叉樹深度優先搜索(前序遍歷、后序遍歷)以及廣度優先搜索實作的二叉樹序列化,
接下來,需要確定就是具體采用哪種方式序列化,本題采用二叉樹的后序遍歷對給定二叉樹的所有子樹進行序列化,
2.2 實作
from json import dumps
from typing import Optional, List, Set, Dict, Union
class TreeNode:
def __init__(self, val=0, left: 'TreeNode' = None, right: 'TreeNode' = None):
self.val = val
self.left = left
self.right = right
class Solution:
def _find_duplicate_subtrees(self, root: TreeNode,
memorandum: Dict[str, int],
results: List[TreeNode]) -> Optional[List[int]]:
if not isinstance(root, TreeNode):
return
left = self._find_duplicate_subtrees(root.left, memorandum, results)
right = self._find_duplicate_subtrees(root.right, memorandum, results)
postorder = []
if left:
postorder = postorder + left
else:
postorder.append(left)
if right:
postorder = postorder + right
else:
postorder.append(right)
postorder.append(root.val)
dumped = dumps(postorder)
# if dumped in memorandum.keys() and memorandum[dumped] == 1:
if memorandum.get(dumped, 0) == 1: # The above commented if-clause is a pedantic counterpart.
results.append(root)
memorandum[dumped] = memorandum.get(dumped, 0) + 1
return postorder
def find_duplicate_subtrees(self, root: Optional[TreeNode]) -> Optional[List[TreeNode]]:
if not isinstance(root, TreeNode):
return
memorandum = dict()
results = []
self._find_duplicate_subtrees(root, memorandum, results)
print('memorandum =', memorandum)
return results
def postorder(root: TreeNode, tree: List[Union[int, None]]):
if not root:
tree.append(None)
return
postorder(root.left, tree)
postorder(root.right, tree)
tree.append(root.val)
def main():
node7 = TreeNode(4)
node6 = TreeNode(4)
node5 = TreeNode(2, left=node7)
node4 = TreeNode(4)
node3 = TreeNode(3, node5, node6)
node2 = TreeNode(2, left=node4)
node1 = TreeNode(1, node2, node3)
root = node1
sln = Solution()
for root in sln.find_duplicate_subtrees(root):
tree = []
postorder(root, tree)
print('postorder =', dumps(tree))
if __name__ == '__main__':
main()
運行上述解答的輸出結果為:
memorandum = {'[null, null, 4]': 3, '[null, null, 4, null, 2]': 2, '[null, null, 4, null, 2, null, null, 4, 3]': 1, '[null, null, 4, null, 2, null, null, 4, null, 2, null, null, 4, 3, 1]': 1}
postorder = [null, null, 4]
postorder = [null, null, 4, null, 2]
實際上, LeetCode 官方通過使用 collections 模塊中的 Counter 類,給出了一個如下的非常優雅的解答,其中關于 Counter 類的使用,可以參考【原始碼共讀】Python 標準模塊 collections 中 Counter 類詳解,
from typing import Optional, List, Dict, Union
from collections import Counter
class TreeNode:
def __init__(self, val=0, left: 'TreeNode' = None, right: 'TreeNode' = None):
self.val = val
self.left = left
self.right = right
class Solution:
def _collect(self, node: TreeNode, duplicates: List[TreeNode], count: Counter):
if not node:
return '#'
serial = "{},{},{}".format(self._collect(node.left, duplicates, count),
self._collect(node.right, duplicates, count),
node.val)
count[serial] += 1
if count[serial] == 2:
duplicates.append(node)
return serial
def elegantly_find_duplicate_subtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]:
count = Counter()
duplicates = []
self._collect(root, duplicates, count)
return duplicates
def postorder(root: TreeNode, tree: List[Union[int, None]]):
if not root:
tree.append(None)
return
postorder(root.left, tree)
postorder(root.right, tree)
tree.append(root.val)
def main():
node7 = TreeNode(4)
node6 = TreeNode(4)
node5 = TreeNode(2, left=node7)
node4 = TreeNode(4)
node3 = TreeNode(3, node5, node6)
node2 = TreeNode(2, left=node4)
node1 = TreeNode(1, node2, node3)
root = node1
sln = Solution()
for root in sln.elegantly_find_duplicate_subtrees(root):
tree = []
postorder(root, tree)
print('postorder =', dumps(tree))
if __name__ == '__main__':
main()
實際上,在上述解答的 第
15
15
15 行中,如果將 return '#' 改為 return 也是正確的,但不為何此時在 LeetCode 上提交時,執行耗時和記憶體消耗的資料都非常差,希望看到這篇題解而且知道緣由的有緣人可以在評論區留下你的指導,
2.3 復雜度
- 時間復雜度: O ( N 2 ) O(N^2) O(N2) ,當給定二叉樹的所有節點呈一條鏈狀時,比較容易分析其最壞時間復雜度: 1 + 2 + ? + N 1+2+\cdots+N 1+2+?+N;
- 空間復雜度: O ( N 2 ) O(N^2) O(N2) ,當給定二叉樹的所有節點呈一條鏈狀時,比較容易分析其最壞空間復雜度: 1 + 2 + ? + N 1+2+\cdots+N 1+2+?+N,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357038.html
標籤:其他