目錄
前言
一、Opencv采集數字影像
二、標記影像數字位置
三、yolov4-tiny機器學習訓練
四、jetson nano識別數字
前言
啊!四天三夜的電賽終于結束了,我們組做了兩輛送藥小車,先上作品圖!

兩輛車都能完成基礎任務,配合后發揮任務一和二也都能完成,現已推往國賽,唉,有點不是很想去啊,現在我來分享一下完成任務的程序,訓練識別這里可以參考我之前寫的第七屆全國大學生工程訓練大賽智能+賽道生活垃圾分類垃圾訓練步驟(win10+yolov4-tiny)
一、Opencv采集數字影像
我用Python撰寫了一個OpenCV拍照腳本,代碼如下:
import cv2
import os
print("=============================================")
print("= 熱鍵(請在攝像頭的視窗使用): =")
print("= z: 更改存盤目錄 =")
print("= x: 拍攝圖片 =")
print("= q: 退出 =")
print("=============================================")
print()
class_name = input("請輸入存盤目錄:")
while os.path.exists(class_name):
class_name = input("目錄已存在!請輸入存盤目錄:")
os.mkdir(class_name)
index = 1
cap = cv2.VideoCapture(0)
width = 640
height = 480
w = 360
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
crop_w_start = (width-w)//2
crop_h_start = (height-w)//2
print(width, height)
while True:
# get a frame
ret, frame = cap.read()
# show a frame
#frame = frame[crop_h_start:crop_h_start+w, 400]
#frame = cv2.flip(frame,1,dst=None)
cv2.imshow("capture", frame)
input = cv2.waitKey(1) & 0xFF
if input == ord('z'):
class_name = input("請輸入存盤目錄:")
while os.path.exists(class_name):
class_name = input("目錄已存在!請輸入存盤目錄:")
os.mkdir(class_name)
elif input == ord('x'):
cv2.imwrite("%s/%d.jpg" % (class_name, index),
cv2.resize(frame, (224, 224), interpolation=cv2.INTER_AREA))
print("%s: %d 張圖片" % (class_name, index))
index += 1
if input == ord('q'):
break
首先將USB攝像頭固定在車上之后將車放在場地上進行拍照,每一個數字拍攝100-200張224*224的影像,然后保存在檔案夾中,
二、標記影像數字位置
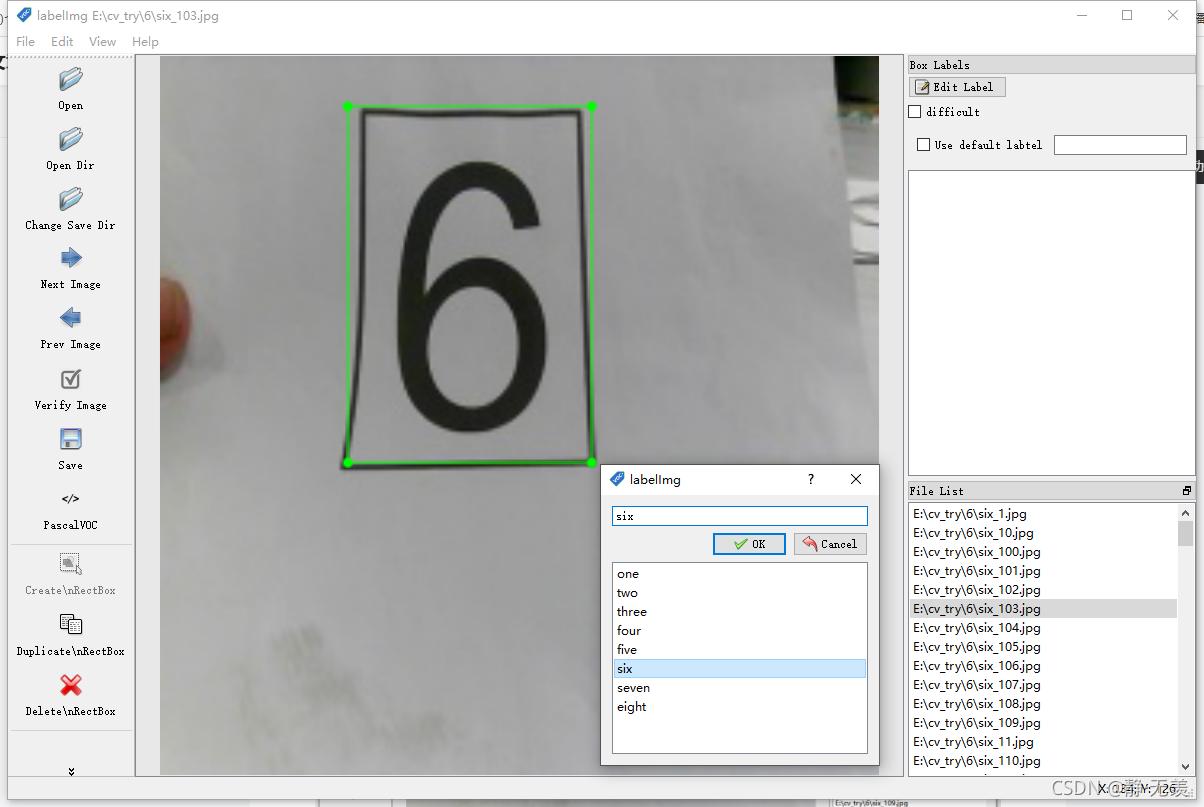
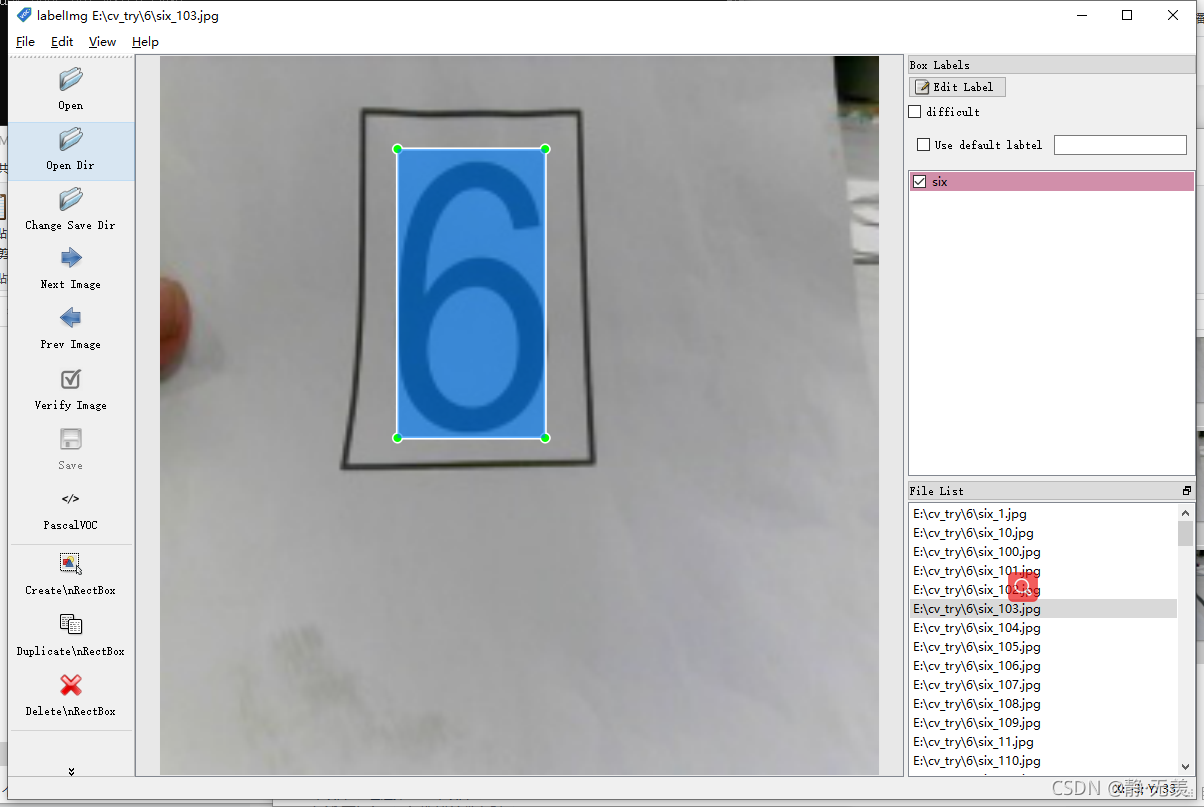
使用標記軟體labelImg進行,生成就能保存數字在影像中的坐標和物件名稱的xml標簽檔案:

三、yolov4-tiny機器學習訓練
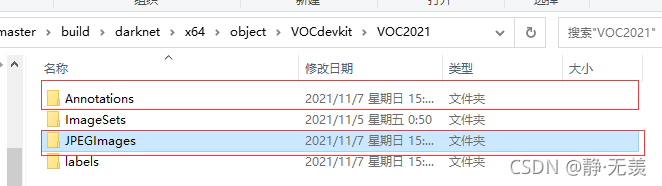
訓練框架采用輕量的yolov4-tiny,使用win10電腦進行訓練,將OpenCV攝像頭采集到的數字影像新建檔案夾JPEGImages保存,然后將標記好數字的xml標簽檔案新建一個Annotations檔案夾保存,
然后撰寫Python腳本txt.py隨機選擇訓練樣本圖片和對照樣本圖片,代碼如下:
import os
import random
trainval_percent = 0.5
train_percent = 0.5
xmlfilepath = 'VOCdevkit/VOC2021/Annotations'
txtsavepath = 'VOCdevkit/VOC2021/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
ptr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, ptr)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
然后撰寫Python腳本voc_label.py將標簽檔案中的名字和坐標位置提取出來生成一個txt檔案,代碼如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2021', 'train'), ('2021', 'val'), ('2021', 'test')]
classes = ["one","two","three","four","five","six","seven","eight"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb])+'\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2021_train.txt 2021_val.txt 2021_train.txt 2021_val.txt > train.txt")
os.system("cat 2021_train.txt 2021_val.txt 2021_test.txt 2021_train.txt 2021_val.txt > train.all.txt")
新建coco.name檔案記錄識別類別名字:

新建coco.data檔案記錄類別數量,訓練影像檔案位置,測驗影像檔案位置,類別名字物件檔案位置,生成權重檔案保存位置:
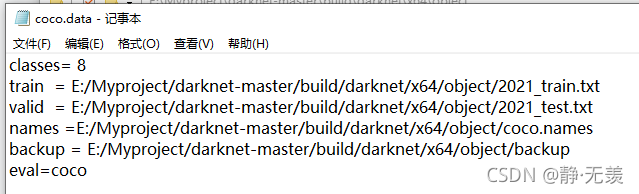
新建yolov4-tiny-train檔案記錄訓練影像大小,訓練迭代最大次數等:
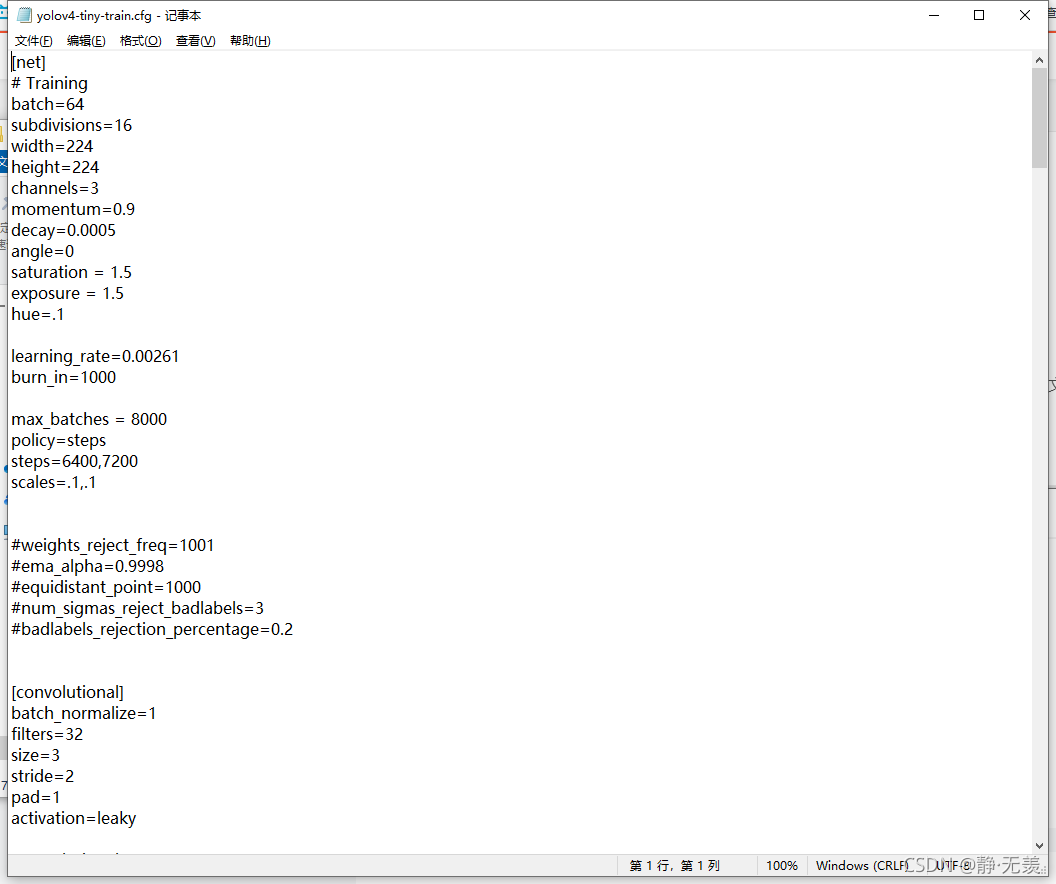
一切準備就緒后使用darknet.exe程式輸入指令:darknet detector train object/coco.data object/yolov4-tiny-train.cfg yolov4-conv.29開始訓練,
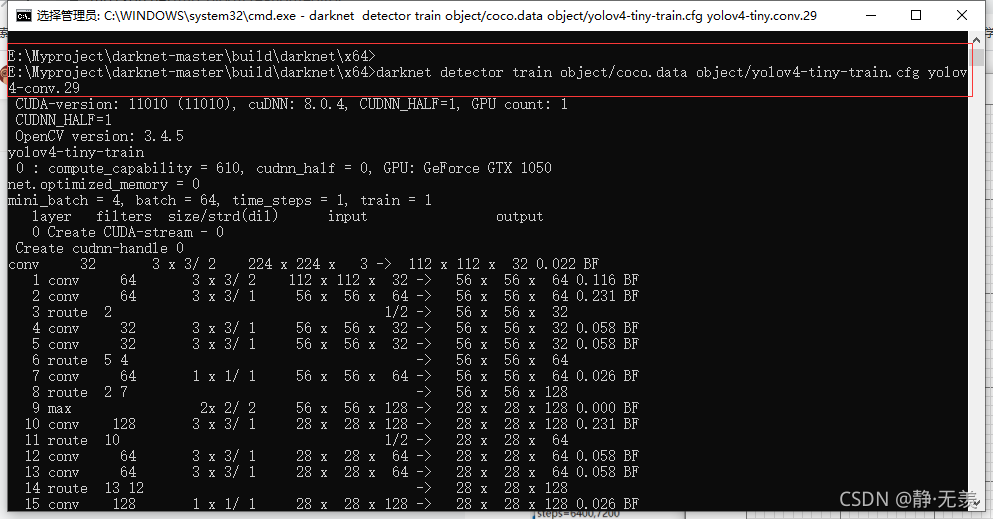
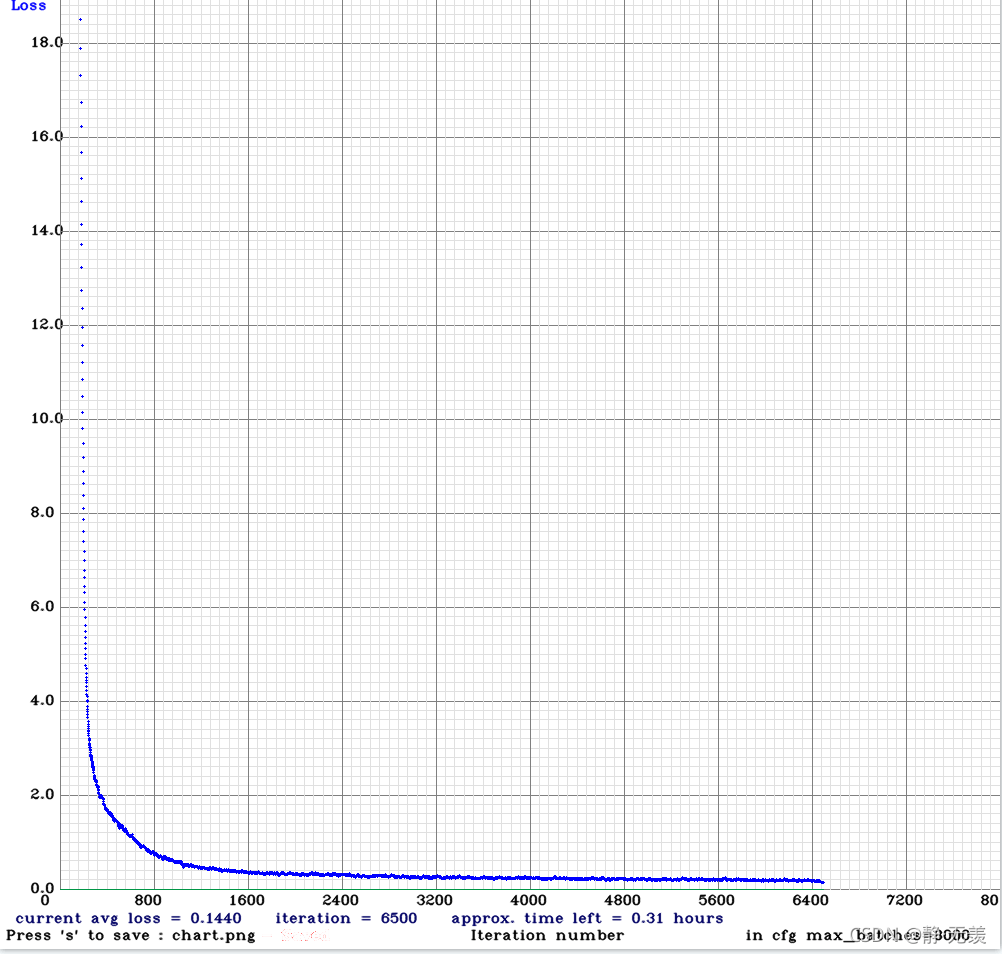
迭代6500次后loss損失度已經降低到0.1左右后停止訓練,得到權重檔案:

我會把訓練的圖片資料集還有生成的權重檔案放到最后的總結部分,需要的同學可以自行下載哈,
四、jetson nano識別數字
撰寫Python腳本testimage.py加載權重檔案識別數字,并將識別到的結果進行處理后將結果通過串口反饋給STM32F4單片機,識別流程:將第一次識別的數字作為目標變數target保存,在第二次識別到這個數字判斷數字所在位置(假如在左側),如果是近端或中端則通過串口發送字符i或r給單片機,i代表left在左側,r代表right在右側,如果是遠端則等待第三次識別target數字然后通過串口發送字符i或r給單片機,代碼如下:
def camera_thread():
network, class_names, class_colors = darknet.load_network('object2/yolov4-tiny-test.cfg', 'object2/coco.data',
'object2/backup/yolov4-tiny4.weights', batch_size=1)
cap = cv2.VideoCapture(0)
width = 640
height = 480
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
w = 480
crop_w_start = (width - w) // 2
crop_h_start = (height - w) // 2
while True:
numbers = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight']
number = [['number', 0], ['number', 0], ['number', 0], ['number', 0], ['number', 0], ['number', 0],
['number', 0], ['number', 0]]
x = [0.0, 0.0, 0.0, 0.0]
y = [0.0, 0.0, 0.0, 0.0]
worth = 0.0
s = 1
flag = 0
counts = 0
print("start")
while True:
input = cv2.waitKey(1) & 0xFF
if input == ord('x'):
print("stop")
break
ret, frame = cap.read()
# frame = frame[crop_h_start:crop_h_start+w+60,crop_w_start:crop_w_start+w+60]
image, detections = image_detection(frame, network, class_names, class_colors, 0.25)
# darknet.print_detections(detections, True)
cv2.imshow('Inference', image)
counts = len(detections)
# print("檢測到",counts,"個數字")
for i in range(0, counts, 1):
# print(detections[i][0], detections[i][1], detections[i][2][0])
# str,str,float,float,float,float
# print(type(detections[i][0]),type(detections[i][1]),type(detections[i][2][0]),type(detections[i][2][1]),type(detections[i][2][2]),type(detections[i][2][3]))
number[i][0] = detections[i][0]
number[i][1] = int(detections[i][2][0])
# print(numbers.index(number[i][0]))
s = int(s + (detections[i][2][2] * detections[i][2][3]))
worth = worth + float(detections[i][1])
if s > counts and counts != 0:
# serial_port.write(('d'+(str(s/counts))).encode())
# print('distence:',s/counts)
s = 0
else:
s = 0
if worth > counts and counts >= 0:
if worth / counts >= 70:
number_sort = sorted(number, key=lambda x: x[1])
# serial_port.write(('n'+(str(counts))).encode())
for i in range(0, counts, 1):
print(numbers.index(number_sort[7 - i][0]), number_sort[7 - i][1])
# serial_port.write((str(numbers.index(number_sort[7-i][0]))).encode())
if flag == 1 and target == numbers.index(number_sort[7 - i][0]):
if (counts == 4 and (i == 0 or i == 1)) or (counts == 2 and (i == 0)):
GPIO.output(13, GPIO.LOW)
print("right")
serial_port.write(str(target).encode())
serial_port.write('r'.encode())
while True:
if serial_port.inWaiting() > 0:
data = serial_port.read()
# print(data)
if data == 'o':
flag = 2
break
input = cv2.waitKey(1) & 0xFF
if input == ord('q'):
break
# time.sleep(5)
elif (counts == 4 and (i == 2 or i == 3)) or (counts == 2 and (i == 1)):
GPIO.output(15, GPIO.LOW)
print("left")
serial_port.write('l'.encode())
while True:
if serial_port.inWaiting() > 0:
data = serial_port.read()
# print(data)
if data == 'o':
flag = 2
elif data == 'k':
flag = 0
break
input = cv2.waitKey(1) & 0xFF
if input == ord('q'):
break
print(i)
elif flag == 2 and target == numbers.index(number_sort[7 - i][0]):
if (counts == 4 and (i == 0 or i == 1)) or (counts == 2 and (i == 0)):
GPIO.output(13, GPIO.LOW)
print("right")
serial_port.write('r'.encode())
while True:
if serial_port.inWaiting() > 0:
data = serial_port.read()
# print(data)
if data == 'o':
flag = 3
elif data == 'k':
flag = 0
break
input = cv2.waitKey(1) & 0xFF
if input == ord('q'):
break
# time.sleep(5)
elif (counts == 4 and (i == 2 or i == 3)) or (counts == 2 and (i == 1)):
GPIO.output(15, GPIO.LOW)
print("left")
serial_port.write('l'.encode())
while True:
if serial_port.inWaiting() > 0:
data = serial_port.read()
# print(data)
if data == 'o':
flag = 3
break
input = cv2.waitKey(1) & 0xFF
if input == ord('q'):
break
print(i)
elif flag == 0 and counts == 1:
target = numbers.index(number[0][0])
print("target:", target)
if target == 1:
serial_port.write('1'.encode())
while True:
if serial_port.inWaiting() > 0:
data = serial_port.read()
# print(data)
if data == 'o':
flag = 3
break
input = cv2.waitKey(1) & 0xFF
if input == ord('q'):
break
elif target == 2:
serial_port.write('2'.encode())
while True:
if serial_port.inWaiting() > 0:
data = serial_port.read()
# print(data)
if data == 'o':
flag = 3
break
input = cv2.waitKey(1) & 0xFF
if input == ord('q'):
break
else:
serial_port.write('t'.encode())
serial_port.write('t'.encode())
serial_port.write('t'.encode())
# time.sleep(1)p
flag = 1
# serial_port.write('o'.encode())
print("counts:", counts)
number = [['number', 0], ['number', 0], ['number', 0], ['number', 0], ['number', 0], ['number', 0],
['number', 0], ['number', 0]]
worth = 0
else:
worth = 0
k = cv2.waitKey(1)
time.sleep(0.05)總結
總結起來四天三夜做出來兩輛車還是很困難的,更別說還需要搭建場地還有除錯,中途還有很多問題,整個團隊都是每天睡覺不到4小時,還好最后的結果還算令人滿意,題目一開始看著不難,但是做的程序中就有很多莫名其妙的問題,在有限的時間內解決也是考驗選手的一點,
最后附上數字識別的資料集還有權重檔案:
數字識別訓練資料集和權重
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357228.html
標籤:其他
下一篇:【青龍面板搭建教程全套】青龍面板+xdd-plus保姆級教程+nolanjdc短信登錄教程+多容器配置-第一部分