包含spark遠程除錯總結demo分享
用scala實作spark讀取并處理資料然后提交到mongodb案例
linux和windows環境:hadoop-2.7.5、spark2.1.2、jdk1.8、scala2.11、mongodb2.0.3 (linux和windows版本要保持一致如果不不一致,會報ClassNotFound等例外)
該文章將詳細敘述單機測驗,在spark運行,IDEA-spark除錯,三個部分,
1.環境簡述
這里我在開了三臺虛擬機,hadoop01、02、03,
hadoop01為namenode,02和03為datanode,
hadoop01為master和worker,02和03為worker,
2.集群開啟
首先需要開啟hadoop集群,然后開啟spark集群,這里要保證自己的集群節點都作業正常,并且你的windowsPC記憶體要大最好是16G要不然集群跑起來很卡,且如果不夠大的話在運行程序中會報記憶體溢位例外和outOfIndex,或者StackOverflow例外,然后開啟hadoop和spark的history服務,jps檢查一下是否都開起正常,
3.IDEA完成demo代碼本地除錯
// An highlighted block
package com.ynu.recommender
import com.mongodb.casbah.{MongoClient, MongoClientURI}
import com.mongodb.casbah.commons.MongoDBObject
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
case class Product( productId: Int, name: String, imageUrl: String, categories: String, tags: String )
case class Rating( userId: Int, productId: Int, score: Double, timestamp: Int )
case class MongoConfig( uri: String, db: String )
object DataLoader {
//在本地除錯的時候注意兩點
//1.必須配置和你pom檔案相同版本的hadoop環境
//2.在環境目錄下(hadoop-2.7.5/bin/)看是否有winutils.exe,如果沒有自己在Github上免費下載一個和自己版本最接近的,
System.setProperty("hadoop.home.dir", "你本機的hadoop環境路徑")
// 定義資料檔案路徑
val PRODUCT_DATA_PATH = "windows上檔案地址"
val RATING_DATA_PATH = "windows上檔案地址"
// 定義mongodb中存盤的表名
val MONGODB_PRODUCT_COLLECTION = "Product"
val MONGODB_RATING_COLLECTION = "Rating"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local",
"mongo.uri" -> "mongodb://mongodb主機的ip:27017/recommender",
"mongo.db" -> "recommender"
)
// 創建一個spark config
val sparkConf = new SparkConf().setMaster("spark.cores").setAppName("DataLoader").setJars(List("file:///D:/BigDataShow/XXX/target/DataLoader-1.0-SNAPSHOT.jar"))
//這里的setjars是windows上jar包的絕對路徑,加file表示絕對路徑,
// 創建spark session
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// 加載資料
val productRDD = spark.sparkContext.textFile(PRODUCT_DATA_PATH)
val productDF = productRDD.map( item => {
// product資料通過^分隔,切分出來
val attr = item.split("\\^")
// 轉換成Product
Product( attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim )
} ).toDF()
println("333")
val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH)
val ratingDF = ratingRDD.map( item => {
val attr = item.split(",")
Rating( attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt )
} ).toDF()
implicit val mongoConfig = MongoConfig( config("mongo.uri"), config("mongo.db") )
storeDataInMongoDB( productDF, ratingDF )
spark.stop()
}
def storeDataInMongoDB( productDF: DataFrame, ratingDF: DataFrame )(implicit mongoConfig: MongoConfig): Unit ={
// 新建一個mongodb的連接,客戶端
val mongoClient = MongoClient( MongoClientURI(mongoConfig.uri) )
// 定義要操作的mongodb表,可以理解為 db.Product
val productCollection = mongoClient( mongoConfig.db )( MONGODB_PRODUCT_COLLECTION )
val ratingCollection = mongoClient( mongoConfig.db )( MONGODB_RATING_COLLECTION )
// 如果表已經存在,則刪掉
productCollection.dropCollection()
ratingCollection.dropCollection()
// 將當前資料存入對應的表中
productDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_PRODUCT_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
ratingDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
// 對表創建索引
productCollection.createIndex( MongoDBObject( "productId" -> 1 ) )
ratingCollection.createIndex( MongoDBObject( "productId" -> 1 ) )
ratingCollection.createIndex( MongoDBObject( "userId" -> 1 ) )
mongoClient.close()
}
}
// An highlighted block
寫好之后就可以直接點擊右鍵然后run了,
4.IDEA完成demo代碼提交到集群運行
由于是提交到集群,我們有很多的依賴,所以必須要打包,怎么打包?
我這里是用maven-plugin打包,需要在pom中添加如下的依賴
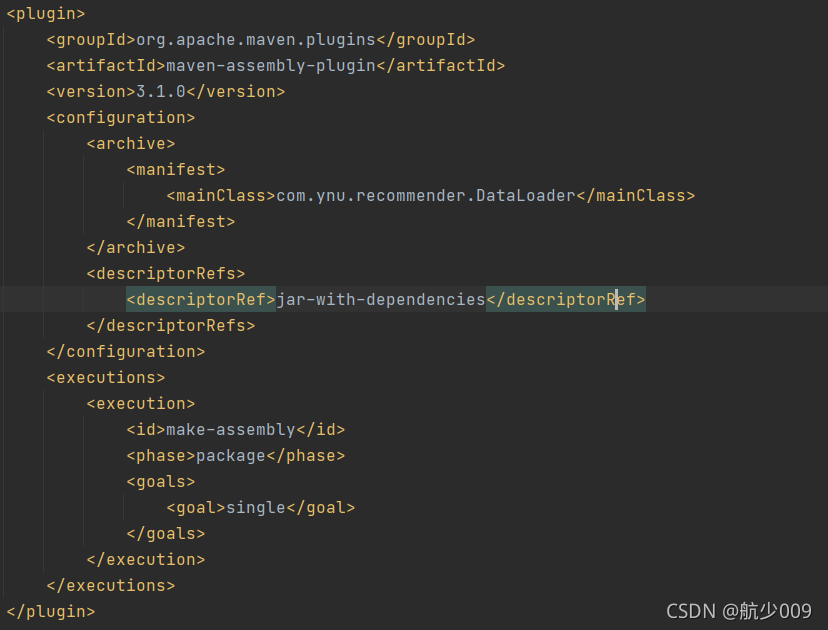
這樣的話你打包的話就可以在IDEA 用maven命令:mvn package,把demo用到的依賴都打進去,大概有100多M的樣子,否則你運行就會報類找不到例外,下面是代碼:
// An highlighted block
package com.ynu.recommender
import com.mongodb.casbah.{MongoClient, MongoClientURI}
import com.mongodb.casbah.commons.MongoDBObject
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
case class Product( productId: Int, name: String, imageUrl: String, categories: String, tags: String )
case class Rating( userId: Int, productId: Int, score: Double, timestamp: Int )
case class MongoConfig( uri: String, db: String )
object DataLoader {
//在本地除錯的時候注意兩點
//1.必須配置和你pom檔案相同版本的hadoop環境
//2.在環境目錄下(hadoop-2.7.5/bin/)看是否有winutils.exe,如果沒有自己在Github上免費下載一個和自己版本最接近的,
System.setProperty("hadoop.home.dir", "你虛擬機的hadoop環境路徑")
// 定義資料檔案路徑
//注意這些csv檔案每個節點都要有,要不然filenotfound例外
val PRODUCT_DATA_PATH = "hdfs://hadoop01:9000/user/XXX.CSV"
val RATING_DATA_PATH = "hdfs://hadoop01:9000/user/XXXX.CSV"
// 定義mongodb中存盤的表名
val MONGODB_PRODUCT_COLLECTION = "Product"
val MONGODB_RATING_COLLECTION = "Rating"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "spark://hadoop01:7077",
"mongo.uri" -> "mongodb://mongodb主機的ip:27017/recommender",
"mongo.db" -> "recommender"
)
// 創建一個spark config
val sparkConf = new SparkConf().setMaster("spark.cores").setAppName("DataLoader").setJars(List("/opt/XXX/test/DataLoader-1.0-SNAPSHOT.jar"))
//這里的setjars改為master主機(hadoop01)上的絕對路徑
//jar包只要在master節點有就行,他會分發到worker中,當然你也可以都放,
// 創建spark session
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// 加載資料
val productRDD = spark.sparkContext.textFile(PRODUCT_DATA_PATH)
val productDF = productRDD.map( item => {
// product資料通過^分隔,切分出來
val attr = item.split("\\^")
// 轉換成Product
Product( attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim )
} ).toDF()
val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH)
val ratingDF = ratingRDD.map( item => {
val attr = item.split(",")
Rating( attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt )
} ).toDF()
implicit val mongoConfig = MongoConfig( config("mongo.uri"), config("mongo.db") )
storeDataInMongoDB( productDF, ratingDF )
spark.stop()
}
def storeDataInMongoDB( productDF: DataFrame, ratingDF: DataFrame )(implicit mongoConfig: MongoConfig): Unit ={
// 新建一個mongodb的連接,客戶端
val mongoClient = MongoClient( MongoClientURI(mongoConfig.uri) )
// 定義要操作的mongodb表,可以理解為 db.Product
val productCollection = mongoClient( mongoConfig.db )( MONGODB_PRODUCT_COLLECTION )
val ratingCollection = mongoClient( mongoConfig.db )( MONGODB_RATING_COLLECTION )
// 如果表已經存在,則刪掉
productCollection.dropCollection()
ratingCollection.dropCollection()
// 將當前資料存入對應的表中
productDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_PRODUCT_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
ratingDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
// 對表創建索引
productCollection.createIndex( MongoDBObject( "productId" -> 1 ) )
ratingCollection.createIndex( MongoDBObject( "productId" -> 1 ) )
ratingCollection.createIndex( MongoDBObject( "userId" -> 1 ) )
mongoClient.close()
}
}
// An highlighted block
最后在linux上我們就可以spark-submit了:
spark-submit --master spark://192.168.125.129:7077 --class com.ynu.recommender.DataLoader /opt/test/DataLoader-1.0-SNAPSHOT-jar-with-dependencies.jar
只不過這里的–master設不設定都一樣,因為代碼里面已經寫好了,
scala的demo和spark遠程除錯,
這里給大家放一篇參考配置的blog:
https://blog.csdn.net/zgjdzwhy/article/details/81632978
這里敘述三點:
1.如果按照上述blog老哥的來無法使用spark-submit,那么恢復spark-class之前的內容,轉而在spark-env.sh添加jvm的引數,
2.集群除錯時出現一直accetped,則將hadoop的capacity-scheduler.xml里面的yarn.scheduler.capacity.maximum-am-resource-percent修改如下: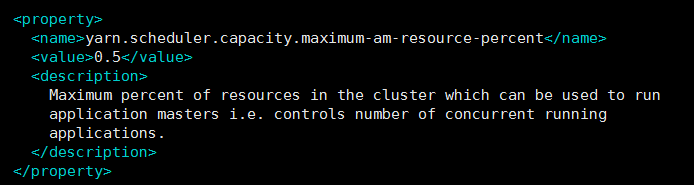
3.需要讀取的檔案要么以args引數傳入,要么是hdfs路徑(所有節點都要有該檔案),setjars方法里面的路徑是windows本地jar包的路徑,且master上的jar包要和本地的相同,若果出現ClassNotFound則在打包的時候把所有依賴排除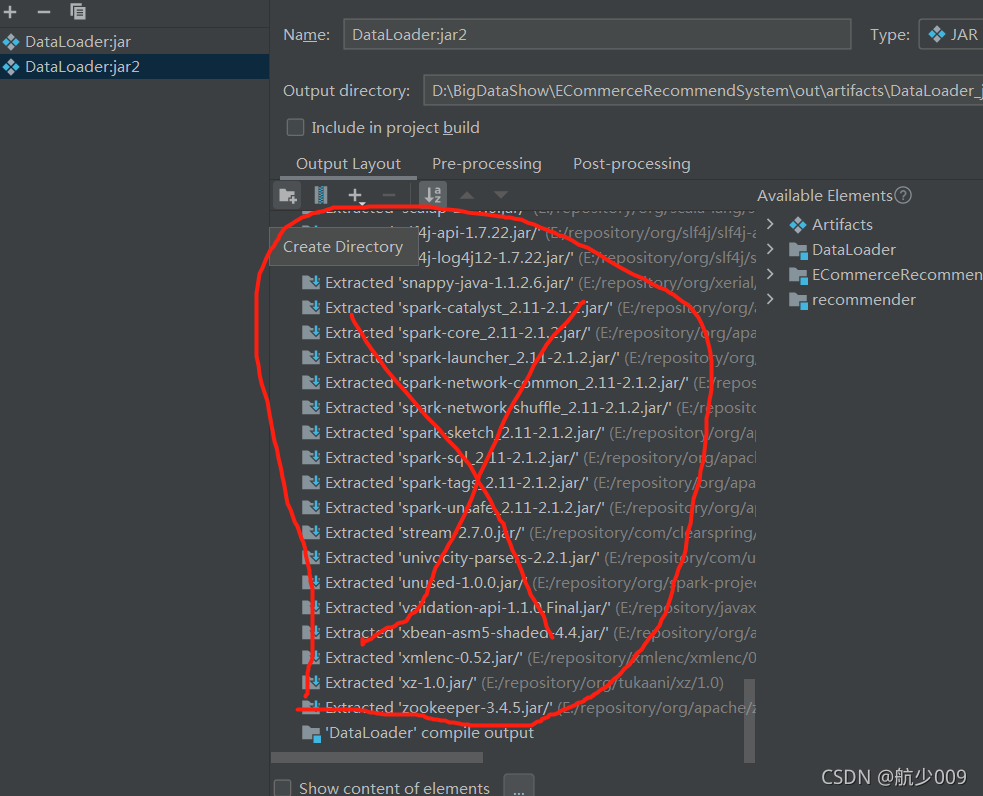
運行結果
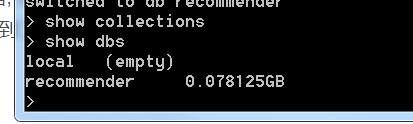
可以看到資料已經匯入到mongodb中了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357251.html
標籤:其他