https://zhuanlan.zhihu.com/p/69888124
基于人
基于物
. 什么是協同過濾
(1)怎么去理解呢?
協同過濾是利用集體智慧的一個典型方法,
(PS,協同過濾是推薦的核心演算法,即集體智慧和推薦是關系的,個中原理參見上面所說的,)
要理解什么是協同過濾 (Collaborative Filtering, 簡稱 CF),首先想一個簡單的問題:
如果你現在想看個電影,但你不知道具體看哪部,你會怎么做?
大部分的人會問問周圍的朋友,看看最近有什么好看的電影推薦,而一般更傾向于從口味比較類似的朋友那里得到推薦,這就是協同過濾的核心思想,
核心原理:協同過濾一般是在海量的用戶中發掘出一小部分和你品位比較類似的,在協同過濾中,這些用戶成為鄰居,然后根據他們喜歡的其他東西組織成一個排序的目錄作為推薦給你,
協同過濾和基于內容推薦有什么區別?
協同: 使用多個用戶的資料來訓練模型,借助群體智慧的同時也避免了單個用戶資料的資訊不足,過濾: 把十億量級的商品降低到數百量級甚至更少,解決資訊過載問題,結合兩種思想就是協同過濾,使用多個用戶的資料來訓練一個模型,模型輸入可以有用戶資訊,物品資訊,還可以有背景關系資訊等等,模型輸出是各物品的預測評分,最后僅取分數top K的物品推薦給用戶,
差別在于:協同過濾必須要有用戶行為,基于內容的推薦可以不用考慮用戶行為,冷啟動階段只能用基于內容的推薦,因為沒有用戶行為資料;積累一段時間用戶行為資料后就可以用協同過濾了,基于內容的推薦的要求:item資料比較容易結構化,且結構化的資料能相對完整的描述item,否則效果不會太好;協同過濾的要求:用戶行為越豐富越好;不管用哪種,都要避免出現馬太效應:推薦的item困在一個封閉的小范圍內,產品上要多做設計,推薦看一些推薦系統方面的書籍
協同過濾
協同過濾本質就是算用戶與用戶相似度、用戶與商品的相似度、商品與商品的相似度,相似度有很多種計算方式,最常用的就是歐式距離,和余弦相似度,拿最常用的 word2vec 做協同過濾例子,就是算商品跟商品的相似度,可以用來給每個商品推薦相似的商品,資料就是先把每個用戶在一定時間范圍內點擊過的商品 id ,點擊的商品要大于2,做成以空格分開的一行,再喂給 word2vec 程式,最后產出是每個商品 Id 的向量,就是俗稱的詞向量或 embdding ,有了向量后,再通過余弦公式算出每個商品與另一個商品的相似度,就可以作為這個商品相似的商品了,是不是比較簡單,具體不同,就是資料量大的時候,可以通過 spark 進行預處理,通過 spark 訓練詞向量,最后算兩兩相似度復雜度比較高,可以通過 spark 呼叫矩陣庫來進行加速,線上效果一般還是挺不錯的,
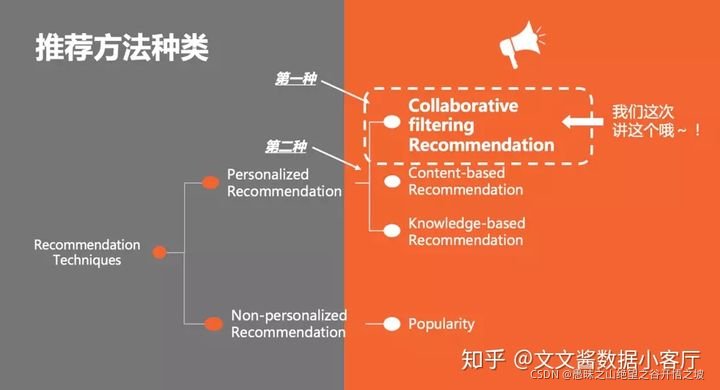
協同過濾演算法我們可以分為兩大類:
基于用戶的協同過濾演算法(UserCF)
基于物品的協同過濾演算法(ItemCF)
其實可以把基于物品的協同過濾看做是基于用戶的協同過濾的一種改良,
針對電商類網站,用戶數遠大于物品數,而且物品的變更頻率不高,物品的相似度相對于用戶的興趣來講比較穩定,這個時候使用基于物品的協同過濾是比較好的選擇,
針對新聞類的應用,時效性較高,物品變化很快,而用戶有相對穩定的場景,此時往往會選擇基于用戶的協同過濾演算法,
最后要如何挑選,取決于網站里哪個相似度更穩定,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357256.html
標籤:其他
上一篇:最大最小歸一化和反歸一化
下一篇:生成式模型與判別式模型