說明:這是一個機器學習實戰專案(附帶資料+代碼+檔案+代碼講解),如需資料+代碼+檔案+代碼講解可以直接到文章最后獲取,

1.專案背景
孤立森林是基于Ensemble的快速例外檢測方法,具有線性時間復雜度和高精準度,是符合大資料處理要求的state-of-the-art演算法,孤立森林演算法適用于連續資料的例外檢測,將例外定義為“容易被孤立的離群點”,可以理解為分布稀疏且離密度高的群體較遠的點,用統計學來解釋,在資料空間里面,分布稀疏的區域表示資料發生在此區域的概率很低,因而可以認為落在這些區域里的資料是例外的,
孤立森林最早來源于2008年發表的一篇論文《Isolation Forest》,該論文由莫納什大學的 Fei Tony Liu、Kai Ming Ting 和南京大學的周志華合作完成的,孤立森林演算法的思想是通過不斷地分割資料集,從而把例外點給孤立出來,分割資料集的依據是反復隨機選取樣本特征,不斷地分割資料集直到每個樣本點都是孤立的,在此情況下,例外點因為具有不同或者特殊的特征值,因此例外點的路徑通常很短,也會比較早被分離出來,
2.資料獲取
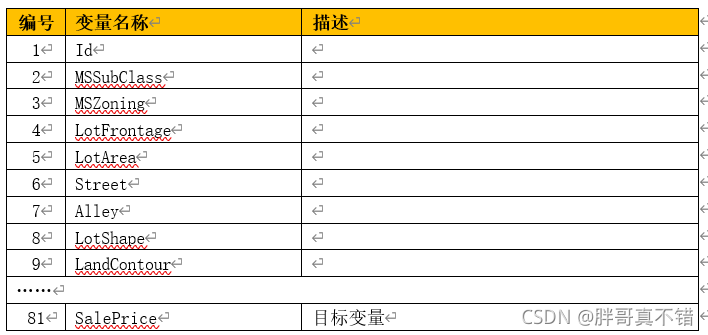
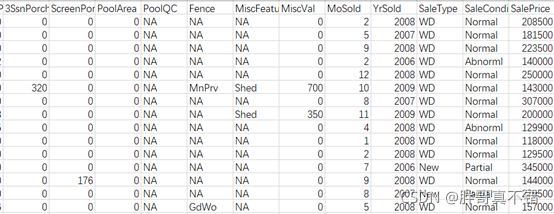
本次建模資料來源于網路(本專案撰寫人整理而成),資料項統計如下:
資料組成:訓練資料1460條、81個特征(38個數值特征和43個分類特征)
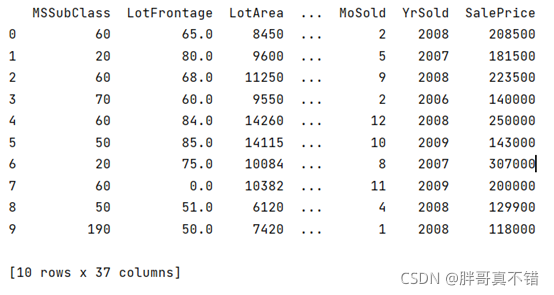
資料詳情如下(部分展示):
3.資料預處理
3.1 用Pandas工具查看資料形狀
使用Pandas工具的shape ()方法查看資料的形狀:
關鍵代碼:


3.2缺失值資料填充
使用Pandas工具的fillna ()方法用0填充缺失的資料,關鍵代碼:
3.3生產資料集的特征串列
使用Pandas工具的columns屬性來生成資料集的特征串列:

關鍵代碼:

4.例外資料檢測
使用sklearn工具中的IsolationForest(演算法)來進行資料集中例外資料的檢測,
4.1建模
模型引數如下:
4.2擬合與預測
應用fit()方法進行擬合,應用predict()進行預測,預測值分為1和-1,1為正常值,-1為例外值,那么在后續的深度神經網路模型應用中將會丟棄掉例外值的資料,檢測結果如下:
關鍵代碼如下:

4.3正常值結果展示
使用Pandas工具的head()方法來展示正常值資料的前10行:
關鍵代碼如下:

5.特征工程
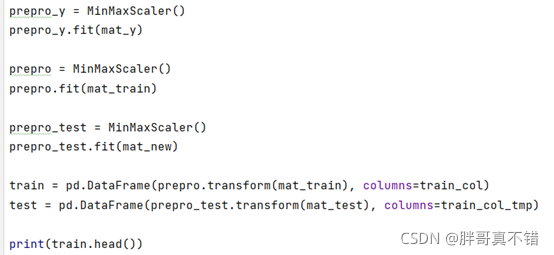
5.1資料歸一化
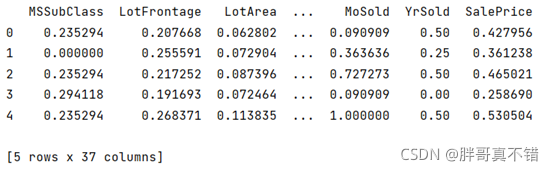
使用sklearn工具MinMaxScaler()方法來進行資料的無量綱化,即資料的歸一化,歸一化后的資料如下圖:
關鍵代碼:
5.2 建立特征資料和標簽資料
SalePrice為標簽資料,除SalePrice之外的為特征資料,關鍵代碼如下:
5.3資料集拆分
訓練集拆分,分為訓練集和驗證集,70%訓練集和30%驗證集,關鍵代碼如下:
6.構建深度神經網路模型
主要使用Keras工具的Sequential()方法構建序慣模型,然后添加Dense層,用于目標回歸,
6.1建模
關鍵代碼如下:
7.模型評估
7.1評估指標及結果
評估指標主要包括均方誤差等等,
從上表可以看出,損失值較小,深度神經網路模型效果較好,
關鍵代碼如下:
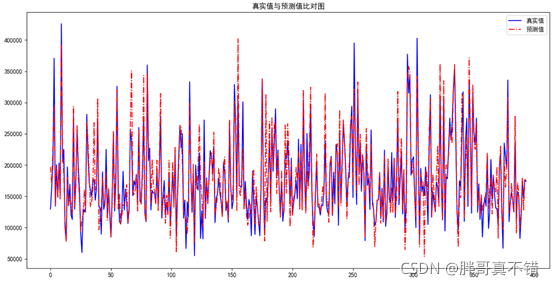
7.3 真實值與預測值比對圖
從上圖可以看到,真實值和預測值波動基本一致,說明除去例外值之后的深度神經網路模型效果較好,
8.結論與展望
綜上所述,使用了孤立森林演算法對房價資料進行例外檢測,實驗結果表明,該演算法可以有效檢測出房價資料中存在的例外資料,然后把例外資料去除,來構建深度神經網路模型,模型效果較好,可用于日常生活中進行建模預測,以提高生產價值和效能,
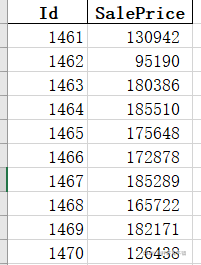
測驗集資料預測結果如下:








本次機器學習專案實戰所需的資料,專案資源如下:
專案說明:
鏈接:https://pan.baidu.com/s/13r3-mTcCRBfwWRtbpnFUpw
提取碼:s2wn網盤如果失效,可以添加博主微信:zy10178083
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357259.html
標籤:其他
上一篇:DAY7_Softmax
下一篇:Ubuntu中圖片與文字的疊加