dlib+opencv+python庫人臉識別
- 一、基于dlib庫人臉特征提取
- (一)采集人臉
- 1.代碼實作
- 2.采集結果
- (二)采集20張圖片對應的68個特征點陣列和平均特征值
- 1.代碼實作
- 2.采集結果
- 二、人臉識別
- (一)實作代碼
- (二)識別結果
- 三、總結
- 四、參考資料
一、基于dlib庫人臉特征提取
基于dlib庫對人臉特征進行提取,在視頻流中抓取人臉特征、并保存為64x64大小的圖片檔案,
注意的是:因為我們后面會對人臉資料集進行訓練識別,因此,這一步非常重要,
- 光線——曝光和黑暗圖片因手動剔除
- 攝像頭的清晰度也比較重要——在哪臺筆記本識別,就要在那臺筆記本做資料集采集,我用了同學在其他筆記本采取的資料,因為電腦配置,在后面的訓練中出現不能識別或錯誤識別的情況,因此,盡量同一設備——采取資料集和做人臉識別,
(一)采集人臉
1.代碼實作
建立自己的人臉資料集:采集多角度的20張人臉
import cv2
import dlib
import os
import sys
import random
# 存盤位置
output_dir = 'F:/picture/person/1xiaozhan'
size = 64
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 改變圖片的亮度與對比度
def relight(img, light=1, bias=0):
w = img.shape[1]
h = img.shape[0]
#image = []
for i in range(0,w):
for j in range(0,h):
for c in range(3):
tmp = int(img[j,i,c]*light + bias)
if tmp > 255:
tmp = 255
elif tmp < 0:
tmp = 0
img[j,i,c] = tmp
return img
#使用dlib自帶的frontal_face_detector作為我們的特征提取器
detector = dlib.get_frontal_face_detector()
# 打開攝像頭 引數為輸入流,可以為攝像頭或視頻檔案
#用攝像頭采集人臉
#camera = cv2.VideoCapture(0)
#用視頻采集人臉
camera = cv2.VideoCapture('F:/picture/xz/xz1/.mp4')
index = 1
while True:
if (index <= 20):#存盤20張人臉特征影像
print('Being processed picture %s' % index)
# 從攝像頭讀取照片
success, img = camera.read()
# 轉為灰度圖片
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用detector進行人臉檢測
dets = detector(gray_img, 1)
for i, d in enumerate(dets):
x1 = d.top() if d.top() > 0 else 0
y1 = d.bottom() if d.bottom() > 0 else 0
x2 = d.left() if d.left() > 0 else 0
y2 = d.right() if d.right() > 0 else 0
face = img[x1:y1,x2:y2]
# 調整圖片的對比度與亮度, 對比度與亮度值都取亂數,這樣能增加樣本的多樣性
face = relight(face, random.uniform(0.5, 1.5), random.randint(-50, 50))
face = cv2.resize(face, (size,size))
cv2.imshow('image', face)
cv2.imwrite(output_dir+'/'+str(index)+'.jpg', face)
index += 1
key = cv2.waitKey(30) & 0xff
if key == 27:
break
else:
print('Finished!')
# 釋放攝像頭 release camera
camera.release()
# 洗掉建立的視窗 delete all the windows
cv2.destroyAllWindows()
break
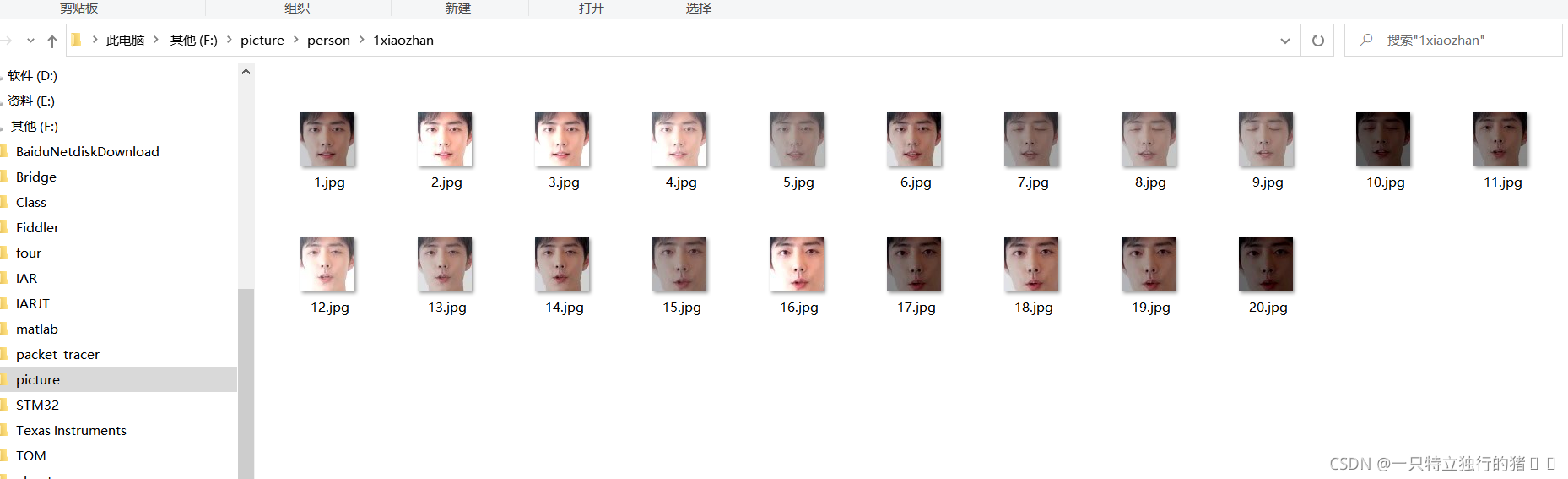
2.采集結果
我采集了五組資料如下




(二)采集20張圖片對應的68個特征點陣列和平均特征值
1.代碼實作
由于光線、和角度等原因五官沒有在采集到的圖片內或模糊不清時可能一部分人臉影像無法識別
from cv2 import cv2 as cv2
import os
import dlib
from skimage import io
import csv
import numpy as np
# 要讀取人臉影像檔案的路徑
path_images_from_camera = "F:/picture/person/"
# Dlib 正向人臉檢測器
detector = dlib.get_frontal_face_detector()
# Dlib 人臉預測器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# Dlib 人臉識別模型
# Face recognition model, the object maps human faces into 128D vectors
face_rec = dlib.face_recognition_model_v1("dlib_face_recognition_resnet_model_v1.dat")
# 回傳單張影像的 128D 特征
def return_128d_features(path_img):
img_rd = io.imread(path_img)
#采取人臉特征陣列,并寫入檔案夾F:/picture/features/631907060525/下
s=path_img
a=s[16:17]
i1=str(a)
a1=s[17:]
str1="/"
b=a1[a1.index(str1):-4]
b1=b[1:]
i2=str(b1)
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_BGR2RGB)
faces = detector(img_gray, 1)
for i in range(len(faces)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(img_rd,faces[i]).parts()])
for idx, point in enumerate(landmarks):
# 68點的坐標
pos = (point[0, 0], point[0, 1])
add="F:/picture/features/631907060525/face"+i1+"_feature"+i2+".csv"
with open(add, "a", newline="") as csvfile:
writer1 = csv.writer(csvfile)
writer1.writerow((idx,pos))
print(add)
print("%-40s %-20s" % ("檢測到人臉的影像 / image with faces detected:", path_img), '\n')
# 因為有可能截下來的人臉再去檢測,檢測不出來人臉了
# 所以要確保是 檢測到人臉的人臉影像 拿去算特征
if len(faces) != 0:
shape = predictor(img_gray, faces[0])
face_descriptor = face_rec.compute_face_descriptor(img_gray, shape)
else:
face_descriptor = 0
print("no face")
return face_descriptor
# 將檔案夾中照片特征提取出來, 寫入 CSV
def return_features_mean_personX(path_faces_personX):
features_list_personX = []
photos_list = os.listdir(path_faces_personX)
if photos_list:
for i in range(len(photos_list)):
# 呼叫return_128d_features()得到128d特征
print("%-40s %-20s" % ("正在讀的人臉影像 / image to read:", path_faces_personX + "/" + photos_list[i]))
features_128d = return_128d_features(path_faces_personX + "/" + photos_list[i])
# print(features_128d)
# 遇到沒有檢測出人臉的圖片跳過
if features_128d == 0:
i += 1
else:
features_list_personX.append(features_128d)
i1=str(i+1)
add="F:/picture/features/tz/face_feature"+i1+".csv"
print(add)
with open(add, "w", newline="") as csvfile:
writer1 = csv.writer(csvfile)
writer1.writerow(features_128d)
else:
print("檔案夾內影像檔案為空 / Warning: No images in " + path_faces_personX + '/', '\n')
# 計算 128D 特征的均值
# N x 128D -> 1 x 128D
if features_list_personX:
features_mean_personX = np.array(features_list_personX).mean(axis=0)
else:
features_mean_personX = '0'
return features_mean_personX
# 讀取某人所有的人臉影像的資料
people = os.listdir(path_images_from_camera)
people.sort()
with open("F:/picture/features/features2_all.csv", "w", newline="") as csvfile: #程式會新建一個表格檔案來保存特征值,方便以后比對
writer = csv.writer(csvfile)
for person in people:
print("##### " + person + " #####")
# Get the mean/average features of face/personX, it will be a list with a length of 128D
features_mean_personX = return_features_mean_personX(path_images_from_camera + person)
writer.writerow(features_mean_personX)
print("特征均值 / The mean of features:", list(features_mean_personX))
print('\n')
print("所有錄入人臉資料存入 / Save all the features of faces registered into:F:/picture/features/features2_all.csv")
2.采集結果
(1)特征陣列
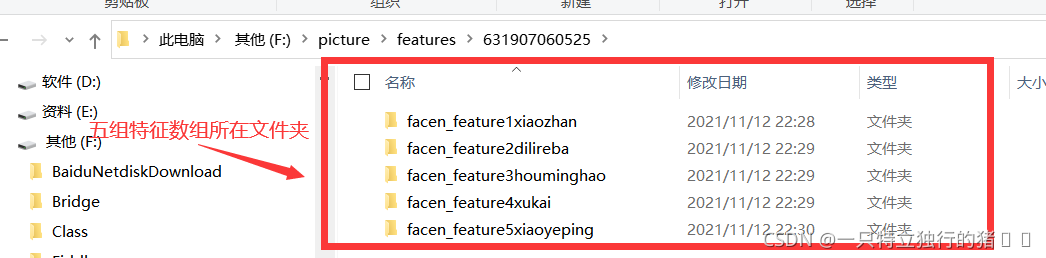
可以觀察到有20組
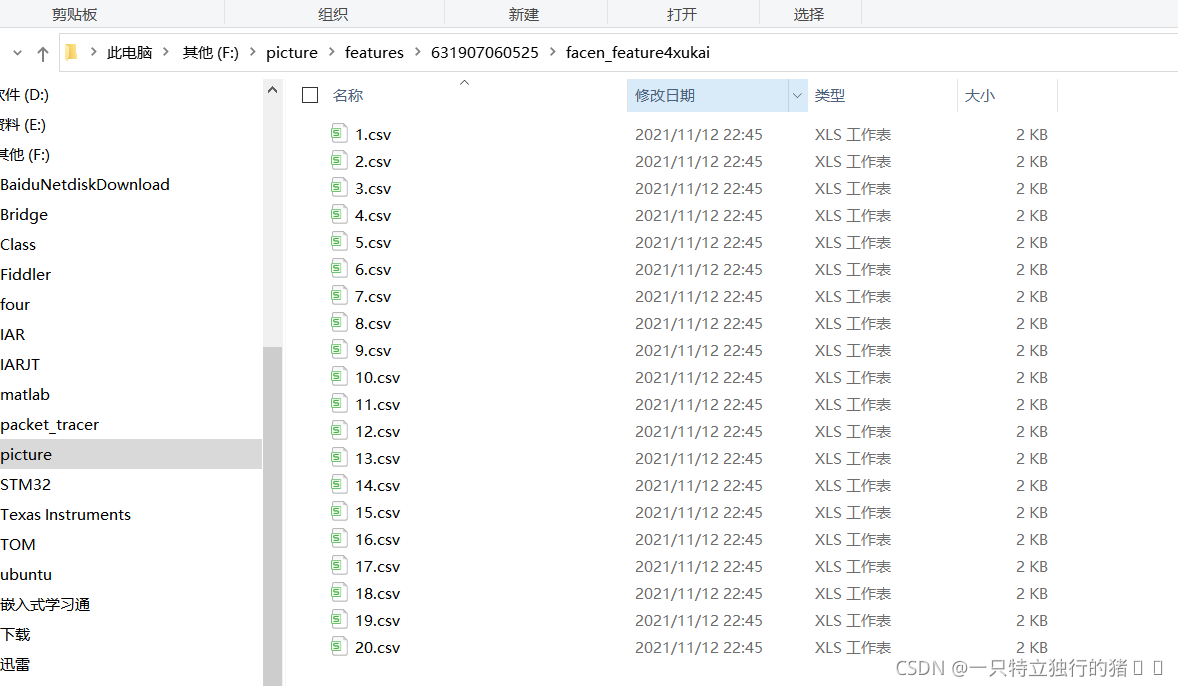
特征陣列的值
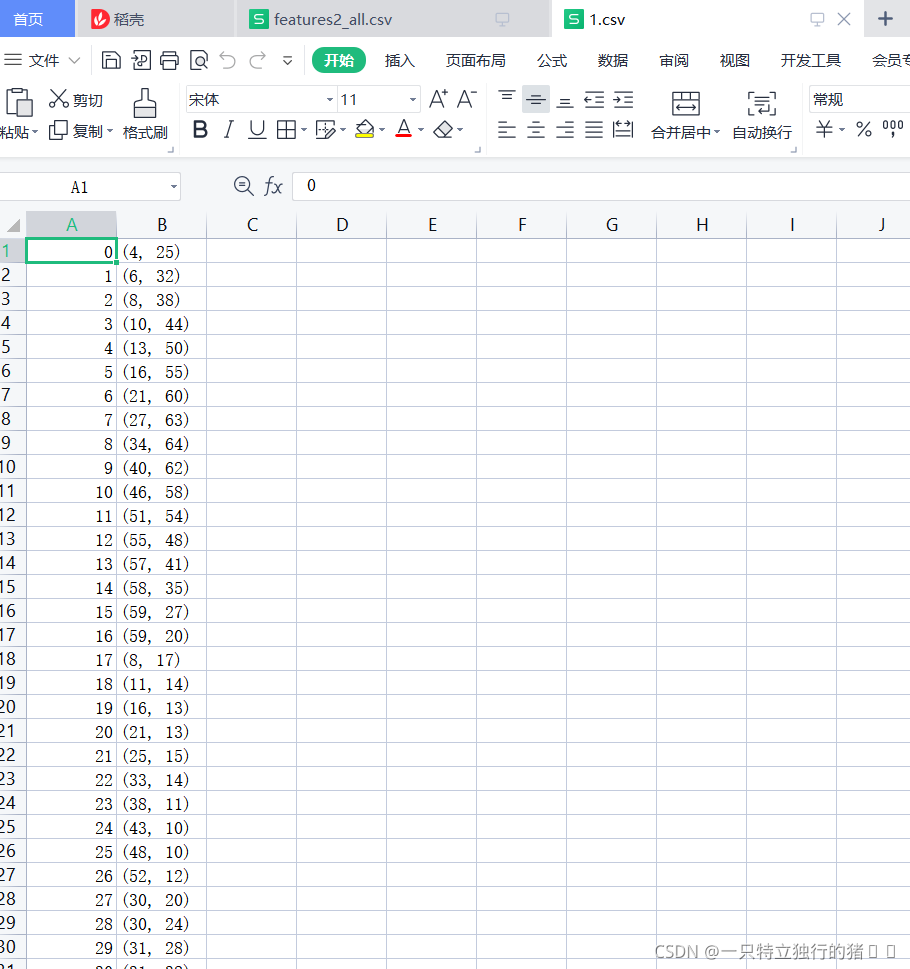
(2)特征值
這是我個人的特征值,一共20組
這是其中一組值

(3)特征平均值
以下是所有人的特征平均值

二、人臉識別
(一)實作代碼
# 攝像頭實時人臉識別
import os
import winsound # 系統音效
from playsound import playsound # 音頻播放
import dlib # 人臉處理的庫 Dlib
import csv # 存入表格
import time
import sys
import numpy as np # 資料處理的庫 numpy
from cv2 import cv2 as cv2 # 影像處理的庫 OpenCv
import pandas as pd # 資料處理的庫 Pandas
# 人臉識別模型,提取128D的特征矢量
# face recognition model, the object maps human faces into 128D vectors
# Refer this tutorial: http://dlib.net/python/index.html#dlib.face_recognition_model_v1
facerec = dlib.face_recognition_model_v1("dlib_face_recognition_resnet_model_v1.dat")
# 計算兩個128D向量間的歐式距離
# compute the e-distance between two 128D features
def return_euclidean_distance(feature_1, feature_2):
feature_1 = np.array(feature_1)
feature_2 = np.array(feature_2)
dist = np.sqrt(np.sum(np.square(feature_1 - feature_2)))
return dist
# 處理存放所有人臉特征的 csv
path_features_known_csv = "F:/picture/features/features2_all.csv"
csv_rd = pd.read_csv(path_features_known_csv, header=None)
# 用來存放所有錄入人臉特征的陣列
# the array to save the features of faces in the database
features_known_arr = []
# 讀取已知人臉資料
# print known faces
for i in range(csv_rd.shape[0]):
features_someone_arr = []
for j in range(0, len(csv_rd.iloc[i, :])):
features_someone_arr.append(csv_rd.iloc[i, :][j])
features_known_arr.append(features_someone_arr)
print("Faces in Database:", len(features_known_arr))
# Dlib 檢測器和預測器
# The detector and predictor will be used
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
# 創建 cv2 攝像頭物件
# cv2.VideoCapture(0) to use the default camera of PC,
# and you can use local video name by use cv2.VideoCapture(filename)
cap = cv2.VideoCapture(0)
# cap.set(propId, value)
# 設定視頻引數,propId 設定的視頻引數,value 設定的引數值
cap.set(3, 480)
# cap.isOpened() 回傳 true/false 檢查初始化是否成功
# when the camera is open
while cap.isOpened():
flag, img_rd = cap.read()
kk = cv2.waitKey(1)
# 取灰度
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_RGB2GRAY)
# 人臉數 faces
faces = detector(img_gray, 0)
# 待會要寫的字體 font to write later
font = cv2.FONT_HERSHEY_COMPLEX
# 存盤當前攝像頭中捕獲到的所有人臉的坐標/名字
# the list to save the positions and names of current faces captured
pos_namelist = []
name_namelist = []
# 按下 q 鍵退出
# press 'q' to exit
if kk == ord('q'):
break
else:
# 檢測到人臉 when face detected
if len(faces) != 0:
# 獲取當前捕獲到的影像的所有人臉的特征,存盤到 features_cap_arr
# get the features captured and save into features_cap_arr
features_cap_arr = []
for i in range(len(faces)):
shape = predictor(img_rd, faces[i])
features_cap_arr.append(facerec.compute_face_descriptor(img_rd, shape))
# 遍歷捕獲到的影像中所有的人臉
# traversal all the faces in the database
for k in range(len(faces)):
print("##### camera person", k+1, "#####")
# 讓人名跟隨在矩形框的下方
# 確定人名的位置坐標
# 先默認所有人不認識,是 unknown
# set the default names of faces with "unknown"
name_namelist.append("unknown")
# 每個捕獲人臉的名字坐標 the positions of faces captured
pos_namelist.append(tuple([faces[k].left(), int(faces[k].bottom() + (faces[k].bottom() - faces[k].top())/4)]))
# 對于某張人臉,遍歷所有存盤的人臉特征
# for every faces detected, compare the faces in the database
e_distance_list = []
for i in range(len(features_known_arr)):
# 如果 person_X 資料不為空
if str(features_known_arr[i][0]) != '0.0':
print("with person", str(i + 1), "the e distance: ", end='')
e_distance_tmp = return_euclidean_distance(features_cap_arr[k], features_known_arr[i])
print(e_distance_tmp)
e_distance_list.append(e_distance_tmp)
else:
# 空資料 person_X
e_distance_list.append(999999999)
# 找出最接近的一個人臉資料是第幾個
# Find the one with minimum e distance
similar_person_num = e_distance_list.index(min(e_distance_list))
print("Minimum e distance with person", int(similar_person_num)+1)
# 計算人臉識別特征與資料集特征的歐氏距離
# 距離小于0.4則標出為可識別人物
if min(e_distance_list) < 0.4:
# 這里可以修改攝像頭中標出的人名
# Here you can modify the names shown on the camera
# 1、遍歷檔案夾目錄
folder_name = 'F:/picture/person'
# 最接近的人臉
sum=similar_person_num+1
key_id=1 # 從第一個人臉資料檔案夾進行對比
# 獲取檔案夾中的檔案名:1wang、2zhou、3...
file_names = os.listdir(folder_name)
for name in file_names:
# print(name+'->'+str(key_id))
if sum ==key_id:
#winsound.Beep(300,500)# 響鈴:300頻率,500持續時間
name_namelist[k] = name[1:]#人名刪去第一個數字(用于視頻輸出標識)
key_id += 1
# 播放歡迎光臨音效
#playsound('D:/myworkspace/JupyterNotebook/People/music/welcome.wav')
# print("May be person "+str(int(similar_person_num)+1))
# -----------篩選出人臉并保存到visitor檔案夾------------
for i, d in enumerate(faces):
x1 = d.top() if d.top() > 0 else 0
y1 = d.bottom() if d.bottom() > 0 else 0
x2 = d.left() if d.left() > 0 else 0
y2 = d.right() if d.right() > 0 else 0
face = img_rd[x1:y1,x2:y2]
size = 64
face = cv2.resize(face, (size,size))
# 要存盤visitor人臉影像檔案的路徑
path_visitors_save_dir = "F:/picture/person/visitor/known"
# 存盤格式:2019-06-24-14-33-40wang.jpg
now_time = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
save_name = str(now_time)+str(name_namelist[k])+'.jpg'
# print(save_name)
# 本次圖片保存的完整url
save_path = path_visitors_save_dir+'/'+ save_name
# 遍歷visitor檔案夾所有檔案名
visitor_names = os.listdir(path_visitors_save_dir)
visitor_name=''
for name in visitor_names:
# 名字切片到分鐘數:2019-06-26-11-33-00wangyu.jpg
visitor_name=(name[0:16]+'-00'+name[19:])
# print(visitor_name)
visitor_save=(save_name[0:16]+'-00'+save_name[19:])
# print(visitor_save)
# 一分鐘之內重復的人名不保存
if visitor_save!=visitor_name:
cv2.imwrite(save_path, face)
print('新存盤:'+path_visitors_save_dir+'/'+str(now_time)+str(name_namelist[k])+'.jpg')
else:
print('重復,未保存!')
else:
# 播放無法識別音效
#playsound('D:/myworkspace/JupyterNotebook/People/music/sorry.wav')
print("Unknown person")
# -----保存圖片-------
# -----------篩選出人臉并保存到visitor檔案夾------------
for i, d in enumerate(faces):
x1 = d.top() if d.top() > 0 else 0
y1 = d.bottom() if d.bottom() > 0 else 0
x2 = d.left() if d.left() > 0 else 0
y2 = d.right() if d.right() > 0 else 0
face = img_rd[x1:y1,x2:y2]
size = 64
face = cv2.resize(face, (size,size))
# 要存盤visitor-》unknown人臉影像檔案的路徑
path_visitors_save_dir = "F:/picture/person/visitor/unknown"
# 存盤格式:2019-06-24-14-33-40unknown.jpg
now_time = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
# print(save_name)
# 本次圖片保存的完整url
save_path = path_visitors_save_dir+'/'+ str(now_time)+'unknown.jpg'
cv2.imwrite(save_path, face)
print('新存盤:'+path_visitors_save_dir+'/'+str(now_time)+'unknown.jpg')
# 矩形框
# draw rectangle
for kk, d in enumerate(faces):
# 繪制矩形框
cv2.rectangle(img_rd, tuple([d.left(), d.top()]), tuple([d.right(), d.bottom()]), (0, 255, 255), 2)
print('\n')
# 在人臉框下面寫人臉名字
# write names under rectangle
for i in range(len(faces)):
cv2.putText(img_rd, name_namelist[i], pos_namelist[i], font, 0.8, (0, 255, 255), 1, cv2.LINE_AA)
print("Faces in camera now:", name_namelist, "\n")
#cv2.putText(img_rd, "Press 'q': Quit", (20, 450), font, 0.8, (84, 255, 159), 1, cv2.LINE_AA)
cv2.putText(img_rd, "Face Recognition", (20, 40), font, 1, (0, 0, 255), 1, cv2.LINE_AA)
cv2.putText(img_rd, "Visitors: " + str(len(faces)), (20, 100), font, 1, (0, 0, 255), 1, cv2.LINE_AA)
# 視窗顯示 show with opencv
cv2.imshow("camera", img_rd)
key = cv2.waitKey(1) & 0xFF
#退出程式
if key == ord("q"):
break
# 開始程式
if key == ord("d"):
dealing = not dealing
# 釋放攝像頭 release camera
cap.release()
# 洗掉建立的視窗 delete all the windows
cv2.destroyAllWindows()
(二)識別結果

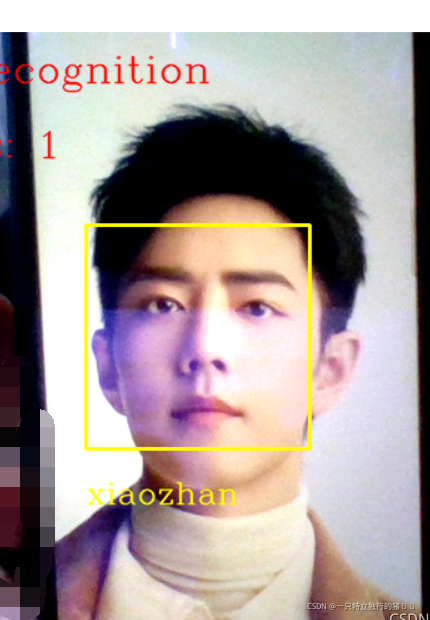
三、總結
人臉識別的程序是采集人臉,通過采集的圖片獲得人臉特征,并計算得到平均特征值,人臉識別時通過實時采集的人臉特征和保存的特征值比對,達到識別人臉的目的,
四、參考資料
基于dlib庫人臉特征提取【構建自己的人臉識別資料集】
簡單的人臉識別
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357277.html
標籤:其他
上一篇:K8s 學習筆記