我在 JIRA 上有 2000 多個問題,并計劃通過 Azure 資料工廠將所有這些問題復制到 JSON 檔案中。但是,由于 Jira API 每個 API 鏈接只允許 100 個問題,我需要在資料集上創建多個 API 鏈接(例如: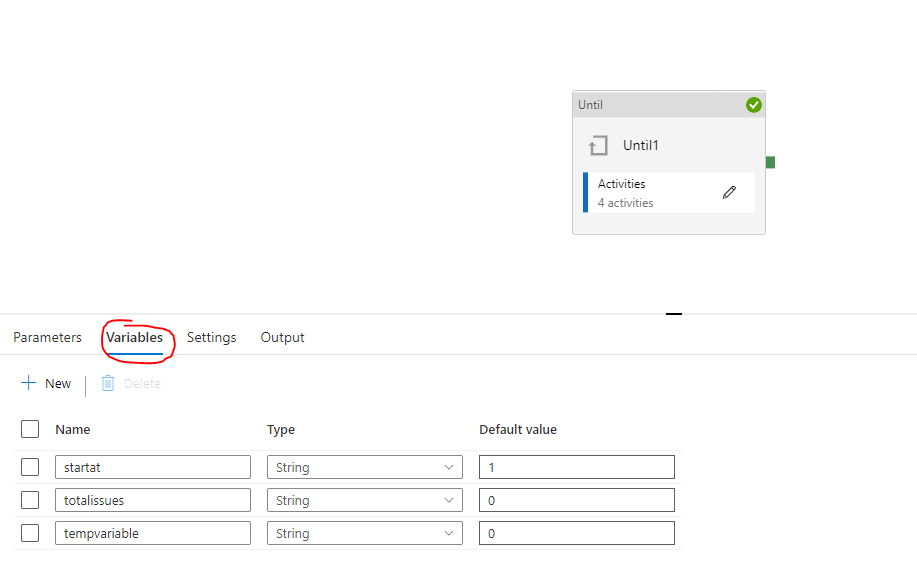
您的 webactivity url 將是帶有 startat 變數的 api url 的連接,如圖所示。maxresults 可以硬編碼,因為它們總是 100。
@concat('https://anunetfunc.azurewebsites.net/api/PaginatedAPI?startat=',variables('startat'),'&maxresults=100')
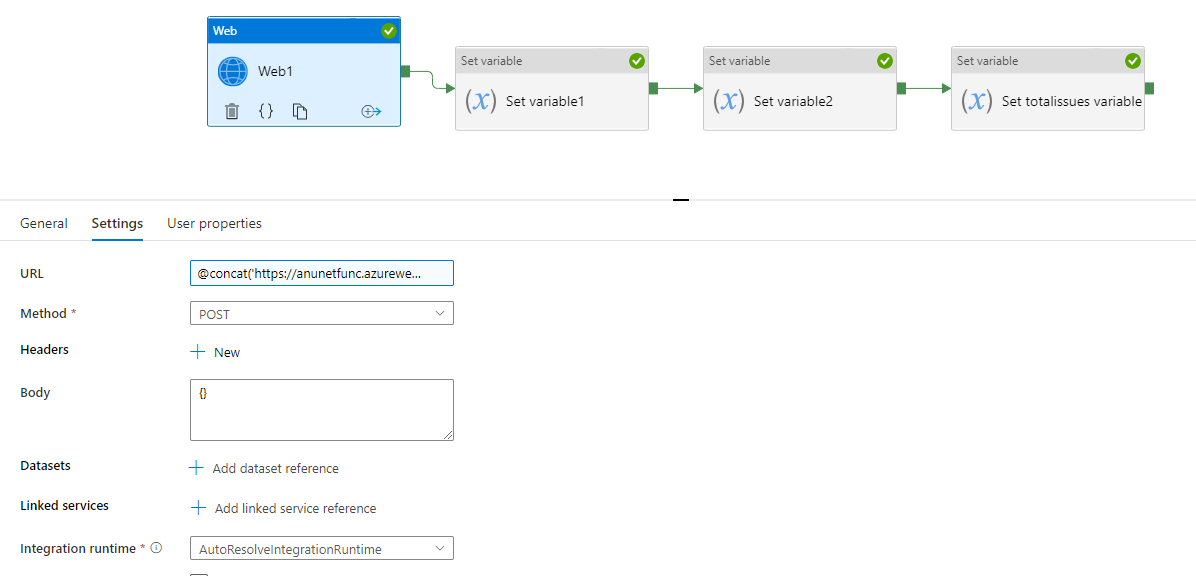
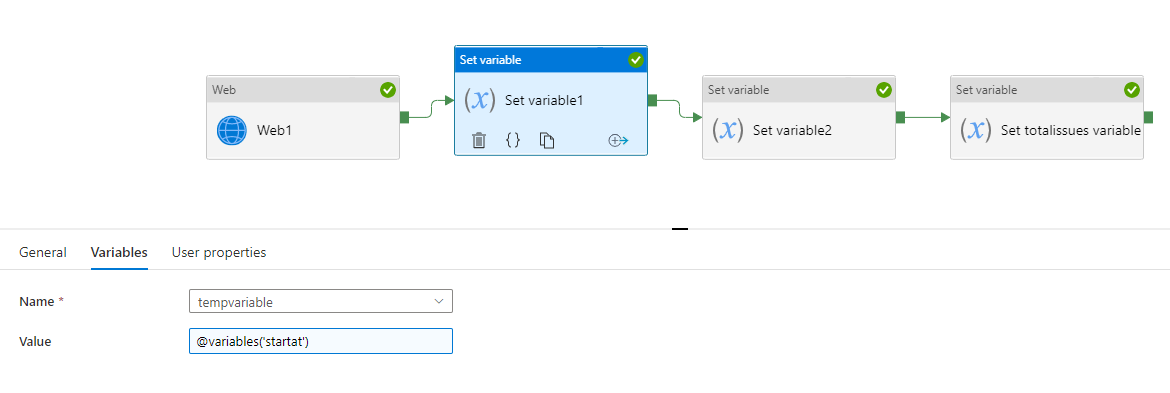
現在您需要將臨時變數設定為@variables('startat')。這是因為 ADF 動態內容允許您包含正在設定的變數。
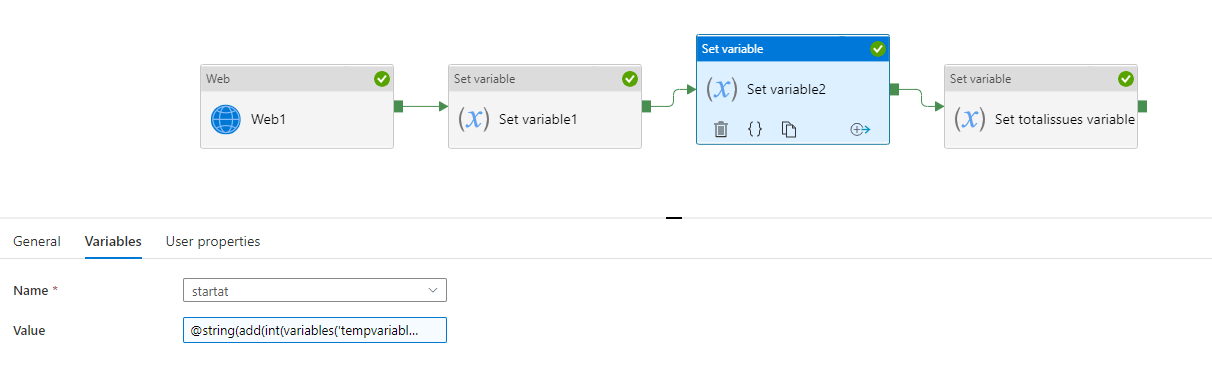
接下來將 startat 設定為 temp 100。這是下一頁閱讀。
@string(add(int(variables('tempvariable')),100))
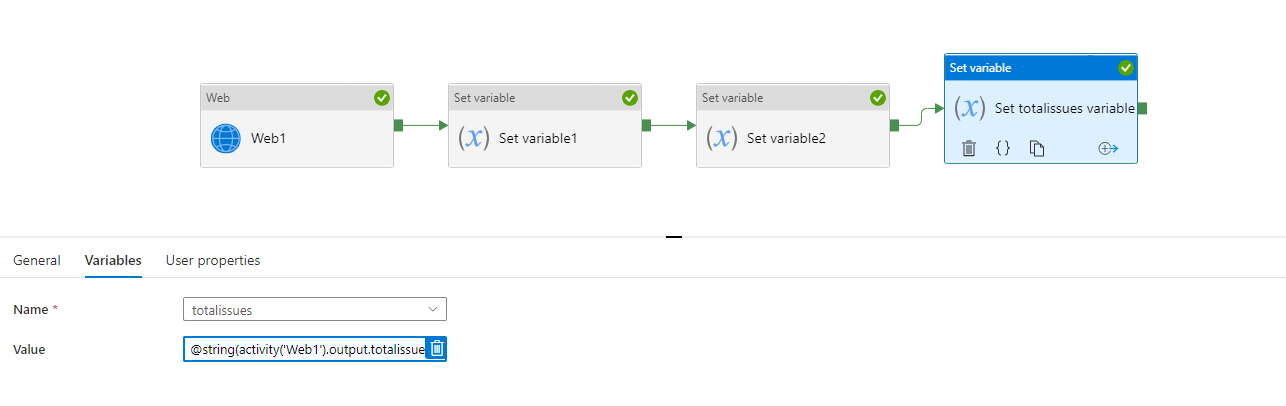
Lastly, set the total issues variable to the totalissues from the output of the 1st webactivity.
@string(activity('Web1').output.totalissues)
With this, the loop will execute only as many times to fetch all the issues. This is just a skeleton to show you how to do this. You still need to add activities to either bunch up all the issues before writing into storage or write separate files for each API call.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/359664.html