背景/場景:
我有兩個表:一個 1-200 萬個條目表,其中包含以下形式的交易
TRX-ID , PROCESS-ID , ACTOR-ID
此外,表單的參與者查找(系統的多個用戶類別之一)表
USER-ID , PARTICIPANT-ID
該交易表是歷史原因有點亂。PROCESS-ID 可以是參與者 ID,而 ACTOR-ID 可以是不同型別用戶的用戶 ID。在某些情況下,PROCESS-ID 是別的東西,而 ACTOR-ID 是參與者的用戶 ID。
我需要加入事務和參與者查找表才能獲得所有事務的參與者 ID。我以兩種方式嘗試了這一點。
(我在片段中省略了一些代碼步驟,專注于連接部分。假設 df 變數是資料框,并且我選擇了正確的列來支持例如聯合。)
第一種方法:
transactions_df.join(pt_lookup_df, (transactions_df['actor-id'] == pt_lookup_df['user-id']) | (transactions_df['process-id'] == pt_lookup_df['participant-id']))
帶有此連接的代碼非常慢。它最終在我的作業中在 10 個實體的 AWS 膠水集群上運行了 45 分鐘,所有執行器的負載接近 99%。
第二種方法:
我意識到有些交易已經有了參與者 ID,我不需要為它們加入。所以我改為:
transactions_df_1.join(pt_lookup_df, (transactions_df_1['actor-id'] == pt_lookup_df['user-id']))
transactions_df_2 = transactions_df_2.withColumnRenamed('process-id', 'participant-id')
transactions_df_1.union(transactions_df_2)
這在5分鐘內完成!
這兩種方法都給出了正確的結果。
題
我不明白為什么一個這么慢而另一個沒有。第二種方法中排除的資料量最少。所以transactions_df_2 只占總資料的一個很小的子集。
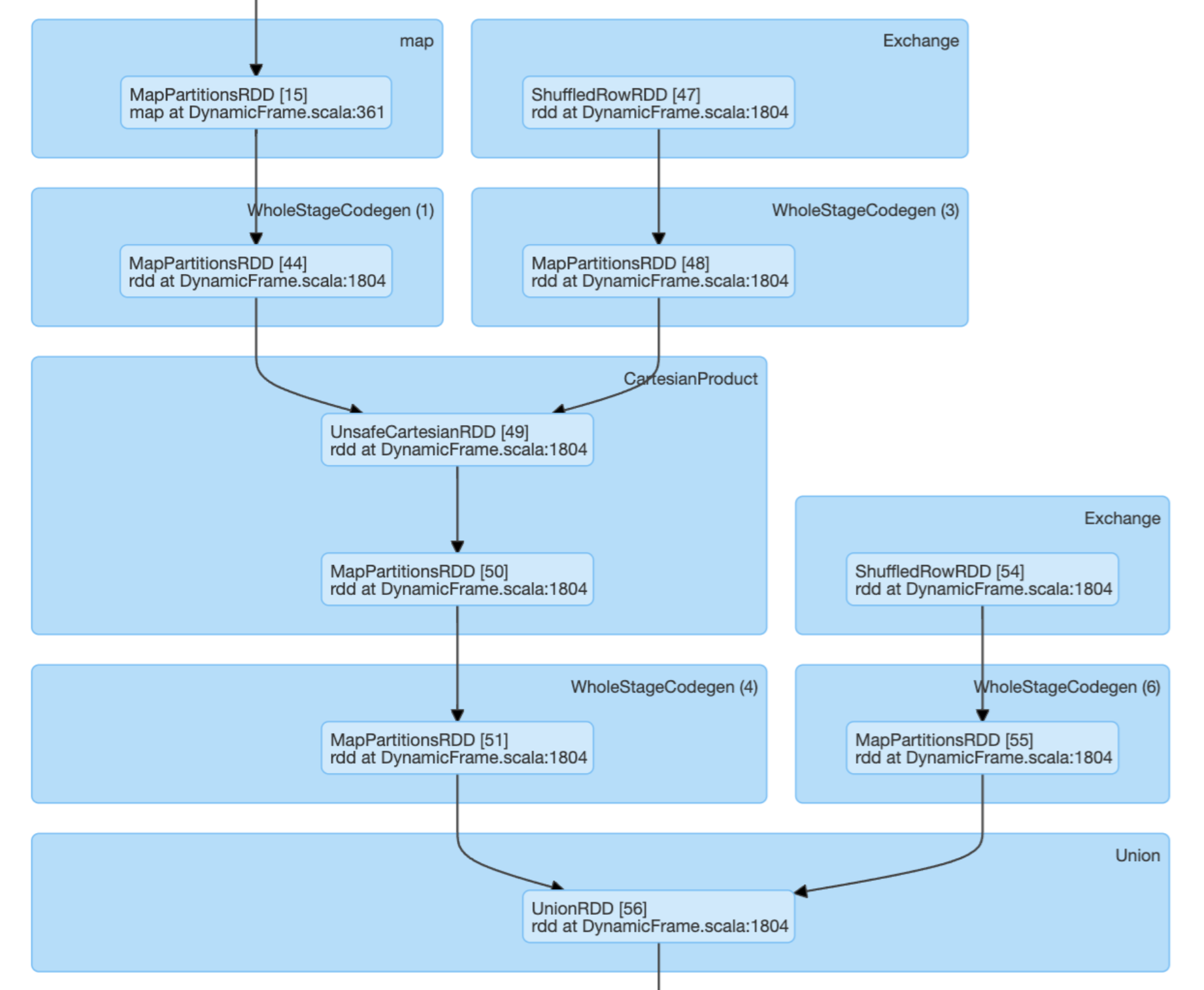
從計劃來看,影響主要是在方法 1 中完成的笛卡爾積,而不是方法 2。所以我假設,這是性能瓶頸。我仍然不明白這會導致 40 分鐘的計算時間差異。
有人可以給出解釋嗎?
DAG 中的笛卡爾積通常是 Spark 中的警告標志嗎?
概括
條件中的多列連接似乎會觸發極慢的笛卡爾積運算。我應該對較小的資料集進行廣播操作以避免這種情況嗎?
DAG 方法 1

DAG 方法 2


uj5u.com熱心網友回復:
這是因為 aCartesian Product join和常規join不涉及相同的資料改組程序。即使認為資料量相似,洗牌量也不同。
這篇文章解釋了額外的洗牌來自哪里。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/364801.html
上一篇:在PYSPARK中將行轉換為列