譯自:https://ruslanspivak.com/lsbasi-part5/
(已獲得作者授權)
你如何處理和了解像創建解釋器或編譯器這樣復雜的事情?在開始時,一切看上去都像是一團亂七八糟的紗線,你需要解開纏結才能得到完美的球,
到達那里的方法是將它解開一個線,一次解開一個結,不過有時候,你可能會覺得自己聽不懂某些內容,但必須繼續前進,我向你保證,如果你足夠堅持,它最終將“咔嗒”一聲被解開,
在理解如何創建解釋器和編譯器的程序中,最好的建議之一是閱讀文章中的解釋,閱讀代碼,然后自己撰寫代碼,甚至在一段時間里撰寫相同的代碼,使你能完全了解材料和代碼,然后繼續學習新主題,不要著急,只要放慢腳步,花點時間深刻理解基本概念,這種方法雖然看似很慢,但會在未來獲得回報,相信我,
最后,最終將獲得完美的毛線球,即使不是那么完美,它也比什么也不做或者快速瀏覽后的幾天內忘掉好多了,
請記住:一步步理解這些知識點,并通過撰寫代碼練習所學的知識:
今天,你將使用前幾篇文章中獲得的知識,學習如何決議和解釋具有任意數量的加,減,乘和除運算的算術運算式,你將撰寫一個解釋器,該解釋器將能夠對"14 + 2 * 3 - 6 / 2"之類的運算式求值,
在深入學習并撰寫一些代碼之前,我們先討論一下運算子的結合性(associativity)和優先級(associativity),
按照慣例7 + 3 + 1與(7 + 3)+ 1相同,而7 - 3 - 1相當于(7 - 3)- 1, 我們都了解這些,如果我們將7 - 3 - 1視為7 -(3 - 1),則結果將會意外的變成5,而不是我們預期的3,
在普通算術和大多數編程語言中,加,減,乘和除是左結合(left-associative)的:
7 + 3 + 1 is equivalent to (7 + 3) + 1
7 - 3 - 1 is equivalent to (7 - 3) - 1
8 * 4 * 2 is equivalent to (8 * 4) * 2
8 / 4 / 2 is equivalent to (8 / 4) / 2
什么是運算子號的左結合性呢?
當運算式7 + 3 + 1中的3之類的運算元在兩側都帶有加號時,我們需要約定來確定哪個運算子適用于3,是左邊的加號還是右邊的加號?我們說運算子加號左結合,是因為在存在兩側都帶有加號的運算元時,此時左邊的加號適用于此運算元,因此我們說運算子加號是左結合的(The operator + associates to the left because an operand that has plus signs on both sides belongs to the operator to its left and so we say that the operator + is left-associative.),所以按照結合性慣例,7 + 3 + 1等于(7 + 3)+ 1,
我們再來看7 + 5 * 2這個運算式,在運算元5的兩邊都有不同型別的運算子,該運算式等于7 +(5 * 2)還是(7 + 5)* 2呢?我們如何解決這種歧義?
在這種情況下,結合性約定對我們沒有幫助,因為它僅適用于加減法(+,-)或乘除法(*,/)這種同一型別的運算子,當我們在同一運算式中具有不同種類的運算子時,我們需要另一種約定來解決歧義,我們需要一個定義運算子相對優先級的約定,
我們說如果運算子乘號在加號之前執行其運算元,則乘號具有更高的優先級(higher precedence),在我們所使用的運算中,乘法和除法的優先級高于加法和減法,所以運算式7 + 5 * 2等效于7 +(5 * 2),運算式7 - 8 / 4等效于7-(8 / 4),
在含有優先級相同的運算子的運算式中,我們僅使用結合性約定并從左到右執行運算子:
7 + 3 - 1 is equivalent to (7 + 3) - 1
8 / 4 * 2 is equivalent to (8 / 4) * 2
希望你不要因為這些運算子的結合性和優先級而感到無聊,我們可以利用這些約定來構造算術運算式的語法,以顯示算術運算子的結合性和優先級,然后,我們可以按照我在第4部分中概述的準則將語法轉換為代碼,我們的解釋器將能夠處理運算子的優先級和結合性約定,
這是我們的優先級表(precedence table):
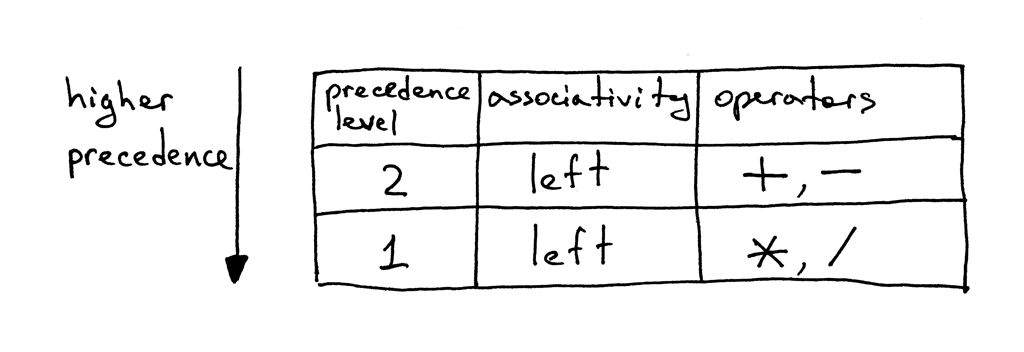
從表中可以看出,運算子加號和減號具有相同的優先級,并且它們都是左結合的,還可以看到,運算子乘號和除號也是左結合的,它們之間也具有相同的優先級,但是比加減運算子具有更高的優先級,
以下是有關如何根據優先級表構造語法的規則:
1、為每一類優先級定義一個非終結符,非終極符的產生式主體應包含該類優先級的算術運算子和下一類更高優先級的非終結符,( The body of a production for the non-terminal should contain arithmetic operators from that level and non-terminals for the next higher level of precedence.)
2、為基本的表達單位(在本文下為整數)創建一個附加的非終結符factor,一般規則是,如果具有N類優先級,則總共將需要N + 1個非終結符:每類級別一個非終結符(N個)再加上一個運算基本單位的非終結符factor(1個),(Create an additional non-terminal factor for basic units of expression, in our case, integers. The general rule is that if you have N levels of precedence, you will need N + 1 non-terminals in total: one non-terminal for each level plus one non-terminal for basic units of expression.)
繼續!
讓我們遵循規則并構建語法,
根據規則1,我們將定義兩個非終結符:一個用于級別2的稱為expr的非終結符和一個用于級別1的稱為term的非終結符,通過規則2,我們將為算術的基本單位定義一個非終結符factor來表達整數,
新語法的起始符號將為expr,expr的產生式將包含一個表示使用級別2的運算子主體,在本例中為加號和減號,并將包含更高級別優先級的非終結符term,
級別2:

term產生式將包含一個使用級別1運算子的主題,即運算子乘號和除號,并且它也包含基本運算式單位(整數)的非終結符factor:
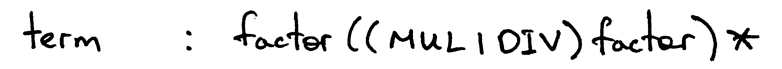
非終結符factor的產生式為:
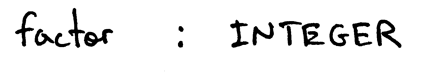
你已經在之前的文章看見過以上產生式的語法和語法圖,在這里,考慮到結合性和優先級,我們將它們組合成一個語法:

這是與上面的語法相對應的語法圖:
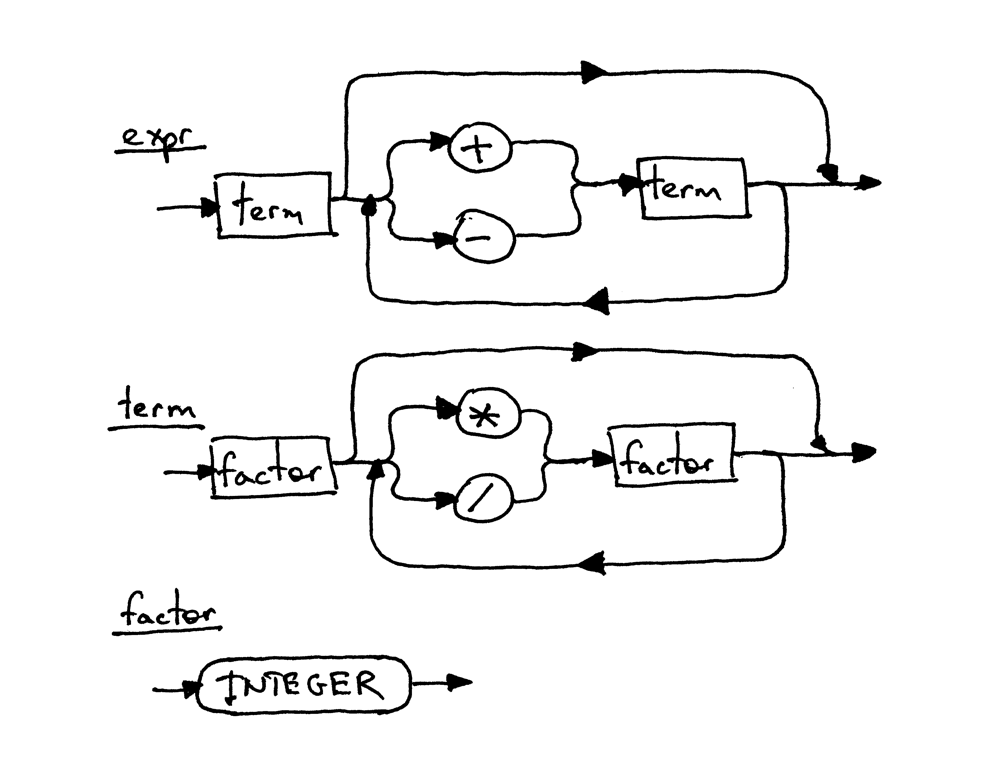
圖中的每個矩形框都是對另一個圖的“函式呼叫(method call)”, 如果你采用運算式7 + 5 * 2并從頂部expr開始,然后一直走到最底部的factor,那么應該能夠看到較高優先級的運算子乘號和除號在較低的圖中,運算子加號和減號在較高的圖中,并且高優先級的運算子先執行,
讓我們看一下根據上面的語法和語法圖來對算術運算式7 + 5 * 2計算的分解步驟,這是顯示高優先級運算子先于低優先級運算子執行的另一種方式:
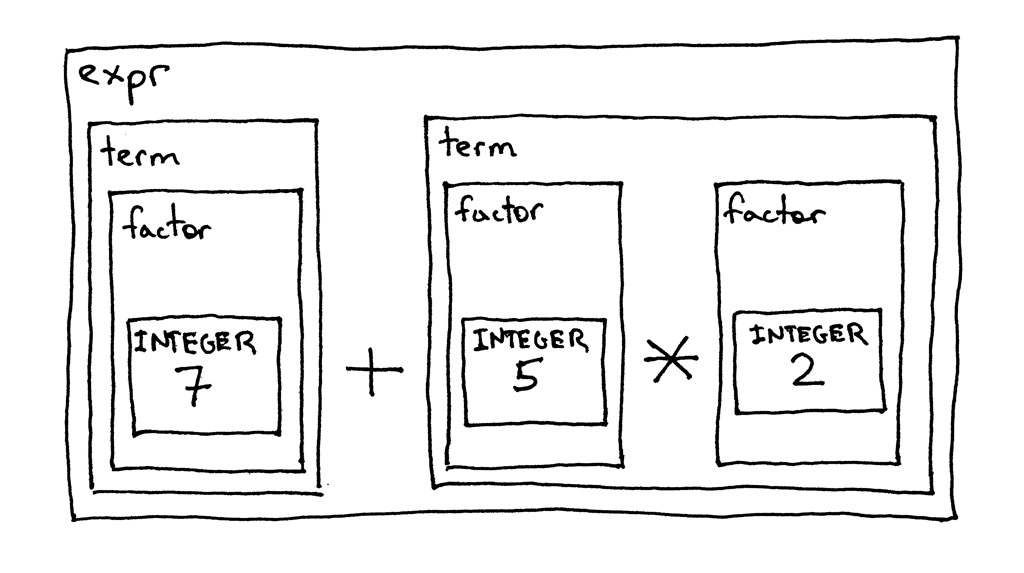
好的,讓我們按照第4部分中的指導方法將語法轉換為代碼,然后看看我們的新解釋器如何作業,
這是語法:

這是計算器的完整代碼,可以處理包含任意數量的加,減,乘和除整數運算的有效算術運算式,
與第4部分中的代碼相比,以下是主要改變的地方:
1、Lexer類現在可以對+,-,*和/進行標記化(這里沒有什么新鮮的,我們只是將以前文章中的代碼組合到一個支持所有這些Token的類中)
2、回想一下,在語法中定義的每個規則(產生式)R都會轉換為具有相同名稱的函式,并且對該規則的參考會成為函式呼叫:R(), 所以Interpreter類現在具有對應于語法中三種非終結符函式:expr,term和factor,
源代碼:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, MUL, DIV, EOF = (
'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', 'EOF'
)
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, MINUS, MUL, DIV, or EOF
self.type = type
# token value: non-negative integer value, '+', '-', '*', '/', or None
self.value = https://www.cnblogs.com/Xlgd/p/value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS,'+')
Token(MUL, '*')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=https://www.cnblogs.com/Xlgd/p/repr(self.value)
)
def __repr__(self):
return self.__str__()
class Lexer(object):
def __init__(self, text):
# client string input, e.g. "3 * 5", "12 / 3 * 4", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Invalid character')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
if self.current_char == '*':
self.advance()
return Token(MUL, '*')
if self.current_char == '/':
self.advance()
return Token(DIV, '/')
self.error()
return Token(EOF, None)
class Interpreter(object):
def __init__(self, lexer):
self.lexer = lexer
# set current token to the first token taken from the input
self.current_token = self.lexer.get_next_token()
def error(self):
raise Exception('Invalid syntax')
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.lexer.get_next_token()
else:
self.error()
def factor(self):
"""factor : INTEGER"""
token = self.current_token
self.eat(INTEGER)
return token.value
def term(self):
"""term : factor ((MUL | DIV) factor)*"""
result = self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
result = result * self.factor()
elif token.type == DIV:
self.eat(DIV)
result = result / self.factor()
return result
def expr(self):
"""Arithmetic expression parser / interpreter.
calc> 14 + 2 * 3 - 6 / 2
17
expr : term ((PLUS | MINUS) term)*
term : factor ((MUL | DIV) factor)*
factor : INTEGER
"""
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
lexer = Lexer(text)
interpreter = Interpreter(lexer)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
將以上代碼保存到calc5.py檔案中,或直接從GitHub下載,嘗試一下,然后自己看看解釋器是否正確地計算了具有不同優先級運算子的算術運算式,
這是我的筆記本電腦上的運行效果:
$ python calc5.py
calc> 3
3
calc> 2 + 7 * 4
30
calc> 7 - 8 / 4
5
calc> 14 + 2 * 3 - 6 / 2
17
接下來是今天的練習:

1、在不瀏覽本文代碼的情況下撰寫本文所述的解釋器,完成后撰寫一些測驗,并確保它們通過,
2、擴展解釋器以處理包含括號的算術運算式,以便你的解釋器可以計算深度嵌套的算術運算式,例如:7 + 3 *(10 /(12 /(3 + 1)-1))
最后再來復習回憶一下:
1、運算子的左結合是什么意思?
2、運算子加號和減號是左結合還是右結合? 乘號和除號呢?
3、運算子加號的優先級是否比運算子乘號高?
嘿,你一直閱讀到最后! 真的很棒 下次我會再寫一篇新文章,敬請期待,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/36491.html
標籤:其他
下一篇:實作一個簡單的解釋器(6)