我正在使用 R 編程語言。我有以下代碼可以創建 100 個資料集(包含一個固定組件和一個隨機組件):
a = rnorm(300,10,5)
b = rnorm(300,3,1)
c = rnorm(300,12,1)
e = "original"
d = data.frame(a,b,c,e)
results <- list()
for (i in 1:100){
a = rnorm(100,10,10)
b = rnorm(100,10,10)
c = rnorm(100,10,10)
e = "simulated"
d_i = data.frame(a,b,c,e)
data_i = rbind(d, d_i)
data_i$iteration = i
results[[i]] <- data_i
}
results_df <- do.call(rbind.data.frame, results)
目前,這 100 個資料集已全部放在同一個檔案(“results_df”)中。現在,我想將“results_df”檔案分解為這 100 個資料集中的每一個(使用“迭代”列作為索引):
results_df$iteration = as.factor(results_df$iteration)
X<-split(results_df, results_df$iteration)
這個“X”檔案似乎是一個“串列”,其中列出了 100 個資料集中的每一個,如下所示:
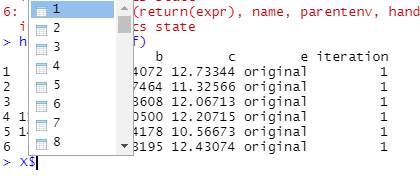
我可以通過使用呼叫“索引”來訪問這些檔案中的每一個i,例如
> head(X$`1`)
a b c e iteration
1 2.141495 3.984072 12.73344 original 1
2 8.769269 4.267464 11.32566 original 1
3 5.413573 2.823608 12.06713 original 1
4 11.710470 3.710500 12.20715 original 1
5 14.423155 2.944178 10.56673 original 1
6 6.886629 2.843195 12.43074 original 1
> head(X$`2`)
a b c e iteration
401 2.141495 3.984072 12.73344 original 2
402 8.769269 4.267464 11.32566 original 2
403 5.413573 2.823608 12.06713 original 2
404 11.710470 3.710500 12.20715 original 2
405 14.423155 2.944178 10.56673 original 2
406 6.886629 2.843195 12.43074 original 2
> head(X$`98`)
a b c e iteration
38801 2.141495 3.984072 12.73344 original 98
38802 8.769269 4.267464 11.32566 original 98
38803 5.413573 2.823608 12.06713 original 98
38804 11.710470 3.710500 12.20715 original 98
38805 14.423155 2.944178 10.56673 original 98
38806 6.886629 2.843195 12.43074 original 98
我的問題:我現在想撰寫另一個函式,對這 100 個資料集的每一個執行線性回歸,保存回歸系數,并將它們放入單個檔案中。我試圖為此撰寫代碼:
results_1 <- list()
for (i in 1:100){
model_i <- lm(a ~ b c, data = X$`i`)
coeff_i = model_i$coefficients
results_1[[i]] <- coeff_i
}
results_df_1 <- do.call(rbind.data.frame, results_1)
乍一看,這似乎奏效了 - 但這將所有回歸系數顯示為相同。這是不可能的,因為回歸模型在不同的資料集上運行了 100 次:
#for some reason, the column names have been corrupted
hist(results_df_1$c.14.5741211250235..14.5741211250235..14.5741211250235..14.5741211250235.., main = "first coeff")
hist(results_df_1$c..0.105285805666629...0.105285805666629...0.105285805666629.., main = "second coeff")
hist(results_df_1$c..0.236548691738492...0.236548691738492...0.236548691738492.., main = "third coeff")
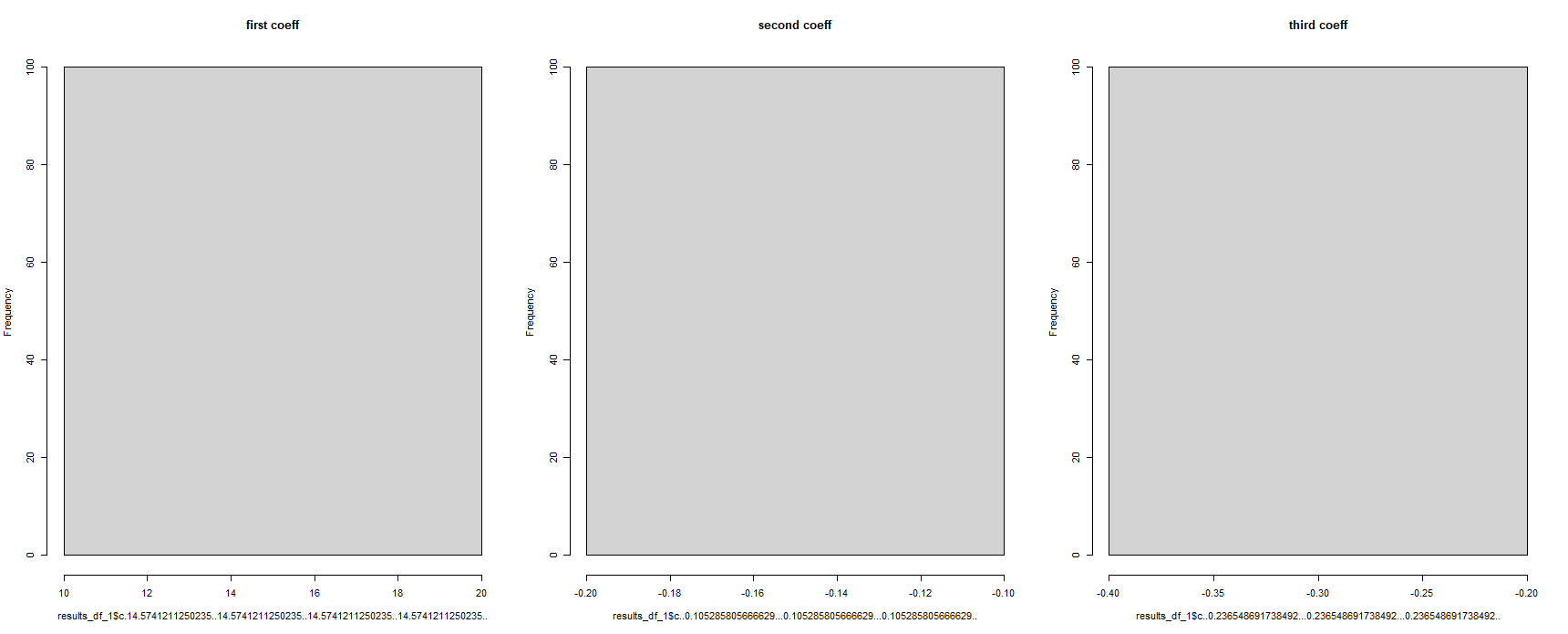
有人可以幫我解決這個問題嗎?當您在 R 中使用“split()”函式時,這是在以后的命令中“呼叫”“拆分組件”的正確方法嗎?
model_i <- lm(a ~ b c, data = X$`i`)
謝謝!
uj5u.com熱心網友回復:
我能夠解決這個問題:
a = rnorm(300,10,5)
b = rnorm(300,3,1)
c = rnorm(300,12,1)
e = "original"
d = data.frame(a,b,c,e)
results <- list()
for (i in 1:100){
a = rnorm(100,10,10)
b = rnorm(100,10,10)
c = rnorm(100,10,10)
e = "simulated"
d_i = data.frame(a,b,c,e)
data_i = rbind(d, d_i)
data_i$iteration = i
results[[i]] <- data_i
}
results_df <- do.call(rbind.data.frame, results)
X<-split(results_df, results_df$iteration)
#####
results_1 <- list()
for (i in 1:100){
#here was the problem
model_i <- lm(a ~ b c, data = X[[i]])
coeff_i = model_i$coefficients
results_1[[i]] <- model_i$coefficients
}
results_df_1 <- do.call(rbind.data.frame, results_1)
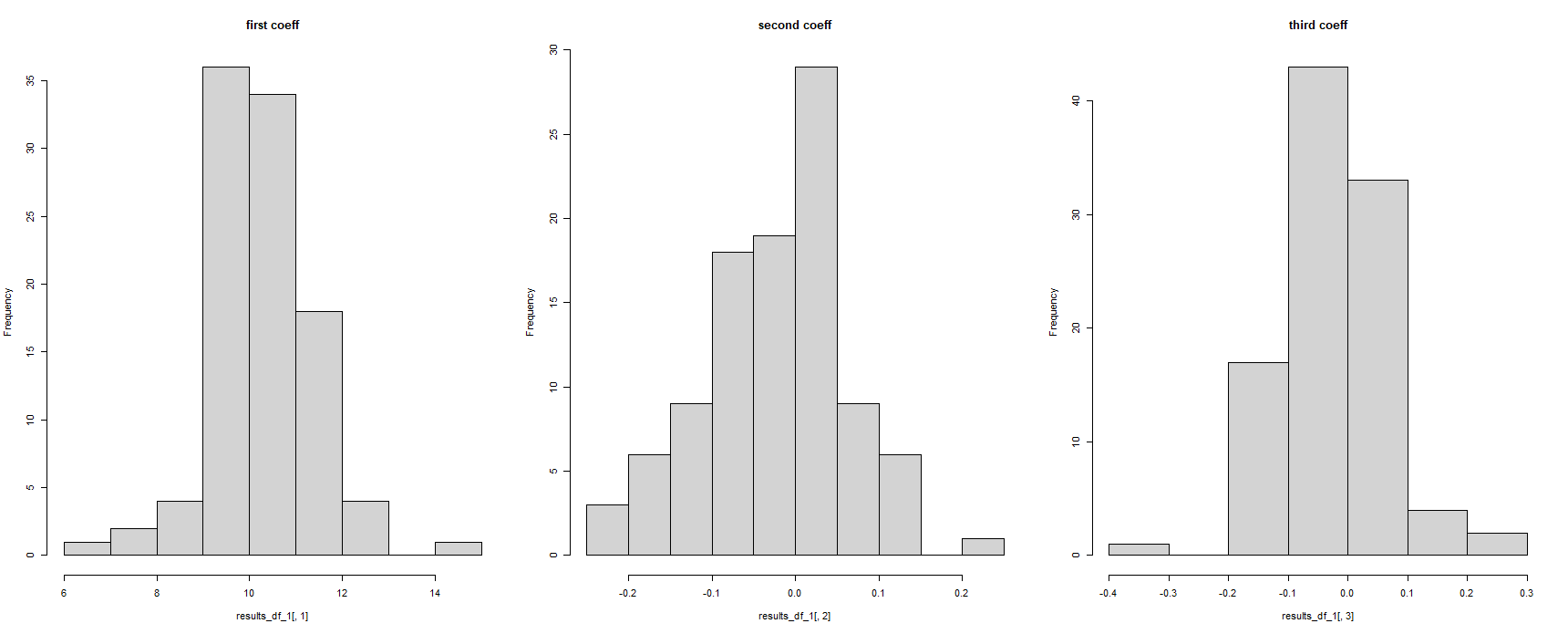
par(mfrow = c(1, 3))
hist(results_df_1[,1], main = "first coeff")
hist(results_df_1[,2], main = "second coeff")
hist(results_df_1[,3], main = "third coeff")
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/365875.html
上一篇:取決于R中匹配的函式的默認引數
下一篇:在構建期間不執行測驗