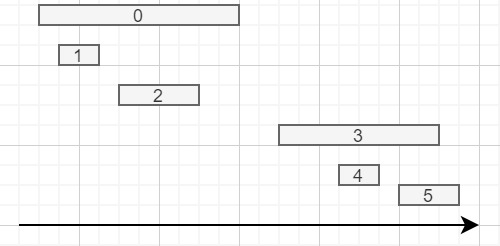
我有一個這樣的 DataFrame(但要大得多):
id start end
0 10 20
1 11 13
2 14 18
3 22 30
4 25 27
5 28 31
我試圖有效地合并 PySpark 中的重疊區間,同時保存在一個新列“ids”中,這些區間被合并,因此它看起來像這樣:
start end ids
10 20 [0,1,2]
22 31 [3,4,5]
可視化:
來自:
到:
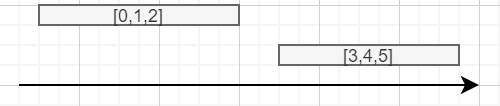
我可以在不使用 udf 的情況下做到這一點嗎?
編輯:id 和 start 的順序不一定相同。
uj5u.com熱心網友回復:
您可以使用視窗函式將前一行與當前行進行比較,構建一個列來確定當前行是否是新間隔的開始,然后對該列求和以構建間隔 id。然后按此間隔 id 分組以獲得最終資料幀。
如果您呼叫input_df輸入資料框,代碼將如下所示:
from pyspark.sql import Window
from pyspark.sql import functions as F
all_previous_rows_window = Window \
.orderBy('start') \
.rowsBetween(Window.unboundedPreceding, Window.currentRow)
result = input_df \
.withColumn('max_previous_end', F.max('end').over(all_previous_rows_window)) \
.withColumn('interval_change', F.when(
F.col('start') > F.lag('max_previous_end').over(Window.orderBy('start')),
F.lit(1)
).otherwise(F.lit(0))) \
.withColumn('interval_id', F.sum('interval_change').over(all_previous_rows_window)) \
.drop('interval_change', 'max_previous_end') \
.groupBy('interval_id') \
.agg(
F.collect_list('id').alias('ids'),
F.min('start').alias('start'),
F.max('end').alias('end')
).drop('interval_id')
所以你可以在沒有任何用戶定義函式的情況下合并你的間隔。然而,每次我們使用一個視窗時,代碼只在一個執行器上執行,因為我們的視窗沒有磁區。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/365960.html