簡介
Prometheus是一個開源的監控、告警整體解決方案,最初由SoundCloud構建,從2012年開始,大量的公司開始適配Prometheus,擁有大量的開發者和非常活躍的用戶社區,目前已作為獨立的專案在運營,并與2016年加入CNCF,是繼Kubernetes之后第二個被CNCF托管的專案,
特性
- 通過指標名稱和標簽(key/value對)區分的多維度、時間序列資料模型
- 靈活的查詢語法 PromQL
- 不需要依賴額外的存盤,一個服務節點就可以作業
- 利用http協議,通過pull模式來收集時間序列資料
- 需要push模式的應用可以通過中間件gateway來實作
- 監控目標支持服務發現和靜態配置
- 支持各種各樣的圖表和監控面板組件
核心組件
整個Prometheus生態包含多個組件,除了Prometheus server組件其余都是可選的
- Prometheus server:主要的核心組件,用來收集和存盤時間序列資料
- client libraries:提供個客戶端,主要是用來幫助應用程式更容易生成滿足Prometheus格式的監控資料,支持各種各樣的開發語言
- push gateway:對于那些生存時間很短的job作業,采用Prometheus的pull模式可能來不及收集,可以部署這個組件,讓job主動把監控指標push到getway,Prometheus再從getway中拉取
- 各種各樣的exports
- alertmanager 一個告警組件
架構圖
下面這張圖,清晰的描繪出了Prometheus各個組件如何相互協作完成系統監控
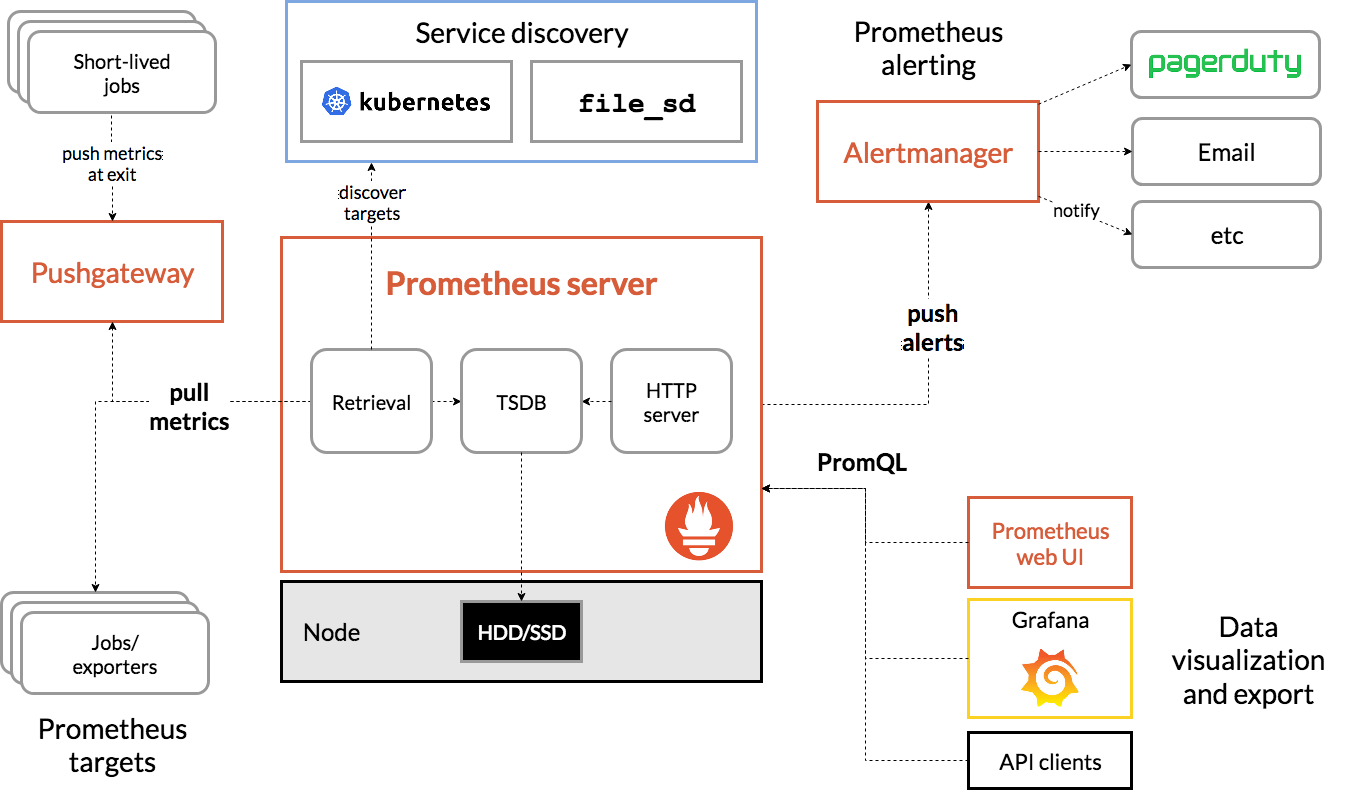
- Prometheus server利用各種各樣的服務發現機制獲取需要監控的target
- Prometheus server通過pull從各種各樣的target處拉取指標資料
- 資料可視化組件(Grfana)通過PromQl從Prometheus server查詢資料,進行展示
- Prometheus server根據自己定義的rule,可以提前對指標資料再次進行計算,觸發報警的發送到alertmanager組件
- alertmanager組件根據配置的告警方式發送相應的通知
適用范圍
Prometheus非常適合用來獲取和存盤純粹數值型時間序列資料,如cpu使用率、系統訪問量、資料更新頻率等,所以多被用來對宿主機和微服務架構中的指標監控,
Prometheus非常的可靠,每個Prometheus server可以作為一個獨立體進行部署,不用依賴其他服務或者是網路,所以在底層基礎設施出現問題時,你還可以從Prometheus server中取出歷史指標來分析問題出現的原因,并且Prometheus server運行時也不會占用很多的資源
不適用場景
因為Prometheus server是周期性pull指標資訊的,所以收集的資料可能是不完整的(比如拉取間隔期間,目標服務出現故障,則這個間隔期間中的資料就獲取不到),所以對于要求資料100%準確的場景如交易額統計等,Prometheus就不太適合了,對于Prometheus最好的用法就是來做監控,通過Prometheus收集的指標資料對系統的健康狀態進行評判和報警處理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/36617.html
標籤:其他
上一篇:通過 Serverless 加速 Blazor WebAssembly
下一篇:Promethues(二)安裝