Dictum:
?Is the true wisdom fortitude ambition. -- Napoleon
??馬爾可夫決策程序(Markov Decision Processes, MDPs)是一種對序列決策問題的解決工具,在這種問題中,決策者以序列方式與環境互動,
“智能體-環境”互動的程序
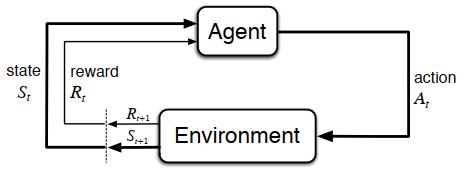
??首先,將MDPs引入強化學習,我們可以將智能體和環境的互動程序看成關于離散情況下時間步長\(t(t=0,1,2,3,\ldots)\)的序列:\(S_0,A_0,R_1,S_1,A_1,R_2,S_2,A_2,R_3,\ldots\),可以定義動作空間\(\mathcal{S}\)為所有動作的集合,定義狀態空間\(\mathcal{A}\)為所有狀態的集合,
馬爾可夫決策程序
馬爾可夫性
??當且僅當狀態滿足下列條件,則該狀態具有馬爾科夫性
\[\mathbb{P}[S_{t+1}|S_t\ ]=\mathbb{P}[S_{t+1} |S_1,…,S_t] \tag{2.1} \]
??也就是說,未來狀態只與當前狀態有關,是獨立于過去狀態的,即當前狀態捕獲了所有歷史狀態的相關資訊,是對未來狀態的充分統計,因此只要當前狀態已知,就歷史狀態就可以被丟棄,
動態特性
??根據這個性質,我們可以寫出狀態轉移概率\(\mathcal{P}_{ss^\prime}=\mathbb{P}[S_{t+1}=s^\prime\ |S_t=s]\)
??由此可以得到狀態轉移矩陣\(\mathcal{P}\):
\[\mathcal{P} = from \begin{matrix} to \\ \left[\begin{array}{rr} \mathcal{P}_{11} & \cdots & \mathcal{P}_{1n} \\ \vdots & \ddots & \vdots \\ \mathcal{P}_{n1} & \cdots & \mathcal{P}_{nn} \\ \end{array}\right] \end{matrix} \tag{2.2} \]
??(該矩陣中所有元素之和為1)
??我們將函式\(p\)定義為MDP的動態特性,通常情況下\(p\)是一個包含四個引數的確定函式(\(p: \mathcal{S}\times\mathcal{A}\times\mathcal{S}\times\mathcal{R}\rightarrow[0,1]\)):
\[p(s^\prime,r|s,a)\doteq\Pr\{S_t=s^\prime,R_t=r|S_{t-1}=s,A_{t-1}=a\} \tag{2.3} \]
??或者,我們可以定義一個三個引數的狀態轉移概率\(p\)(\(p: \mathcal{S}\times\mathcal{S}\times\mathcal{A}\rightarrow[0,1]\)):
\[p(s^\prime|s,a)\doteq\Pr\{S_t=s^\prime|S_{t-1}=s,A_{t-1}=a\}= \sum_{r \in \mathcal{R}}p(s^\prime,r|s,a) \tag{2.4} \]
??由此,可以定義“狀態-動作”二元組的期望獎勵\(r(r:\mathcal{S}\times\mathcal{A}\rightarrow\mathbb{R})\):
\[r(s,a)\doteq\mathbb{E}[R_t|S_{t-1}=s,A_{t-1}=a]=\sum_{r\in\mathcal{R}}r\sum_{s^\prime\in\mathcal{S}}p(s^\prime,r|s,a) \tag{2.5} \]
??也可以定義“狀態-動作-后繼狀態”三元組的期望獎勵\(r(r:\mathcal{S}\times\mathcal{A}\times\mathcal{S}\rightarrow\mathbb{R})\):
\[r(s,a,s^\prime)\doteq\mathbb{E}[R_t|S_{t-1}=s,A_{t-1}=a,S_t=s^\prime]=\sum_{r\in\mathcal{R}}r\frac{p(s^\prime,r|s,a)}{p(s^\prime|s,a)} \tag{2.6} \]
價值函式
回報
??回報(Return)的定義式為
\[G_t\doteq\displaystyle \sum^{T}_{k=t+1}\gamma^{k-t-1}R_k,\ 0\le\gamma \le 1 \tag{2.7} \]
??\(\gamma\)被稱為折扣率(discount rate),當\(T= \infin\)且\(0 \le \gamma<1\)時,強化學習任務被稱為連續任務(continuing tasks),當\(\gamma=1\)且\(T\ne\infin\)時,強化學習任務被稱為幕式任務(episodic tasks),
??episodic tasks的智能體和環境的互動程序能夠被拆分為一系列的子序列,在這類任務中,當時間步長\(t\)達到某個值\(T\)時,會產生終止狀態(terminal state),這種狀態下,對于任意\(k>1,S_{T+k}=S_T=s\)恒成立,此時,\(T\)被稱為終止時刻,它隨著幕(episode)的變化而變化,從起始狀態到達終止狀態的每個子序列被稱為幕,
策略
??策略(Policy)\(\pi\)是狀態到動作空間分布的映射
\[\pi(a|s)= \mathbb{P}[A_t=a|S_t=s] \tag{2.8} \]
??它表示根據當前狀態\(s\),執行動作\(a\)的概率,
狀態價值函式
??狀態價值函式(State-value Function)\(v_\pi(s)\)定義為從狀態\(s\)開始,執行策略\(\pi\)所獲得的回報的期望值,
\[v_\pi(s) \doteq \mathbb{E}_\pi[G_t|S_t=s]=\mathbb{E}[\sum^\infin_{k=0} \gamma^kR_{t+k+1}|S_t=s], s \in \mathcal{S} \tag{2.9} \]
動作價值函式
??類似于公式\((2.9)\)的定義,將動作價值函式(Action-value Function)\(q_\pi(s,a)\)定義為在狀態\(s\)時采取動作\(a\)后,所有可能的決策序列的期望回報,
\[q_\pi(s,a) \doteq \mathbb{E}_\pi[G_t|S_t=s,A_t=a]=\mathbb{E}[\sum^\infin_{k=0} \gamma^kR_{t+k+1}|S_t=s,A_t=a], s \in \mathcal{S} \tag{2.10} \]
貝爾曼方程
??貝爾曼方程(Bellman Euqation)是以等式的方式表示某一時刻價值與期后繼時刻價值之間的遞推關系,
??下面給出狀態價值函式\(v_\pi(s)\)的貝爾曼方程:
\[\begin{aligned} v_\pi(s) & \doteq \mathbb{E}_\pi[G_t|S_t=s] \\ & =\mathbb{E}_\pi[R_{t+1}+ \gamma G_{t+1}|S_t=s] \\ & =\displaystyle \sum_a\pi(a|s) \sum_{s^\prime} \sum_rp(s^\prime,r|s,a)[r+\gamma \mathbb{E}_\pi[G_{t+1}|S_{t+1}=s^\prime]] \\ & =\displaystyle \sum_a\pi(a|s) \sum_{s^\prime.r} p(s^\prime,r|s,a) [r+\gamma v_\pi(s^\prime)] \end{aligned} \tag{2.11} \]
??可以通過下面關于\(v_\pi(s)\)的回溯圖(backup diagram)更好地理解上述方程,backup就是將價值資訊從后繼狀態(或“狀態-動作”二元組)轉移到當前狀態(或“狀態-動作”二元組),
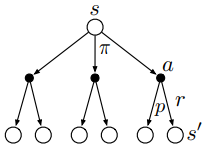
??在上圖中,由上往下看,空心圓表示狀態,實心圓表示“狀態-動作”二元組,圖中,從根節點狀態\(s\)開始,智能體根據策略\(\pi\)采取動作集合中的任意動作,對于每個動作,環境會根據它的動態特性函式\(p\),給出獎勵值\(r\)和后繼狀態\(s^\prime\),
??同樣也可以通過\(q_\pi\)的回溯圖得到它的貝爾曼方程(同時也給出推導程序):
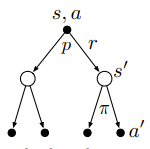
\[\begin{aligned} q_\pi(s,a) & \doteq \mathbb{E}_\pi[G_t|S_t=s,A_t=a] \\ & =\mathbb{E}_\pi[R_{t+1}|S_t=s,A_t=a]+ \gamma \mathbb{E}_\pi[G_{t+1}|S_t=s,A_t=a] \\ & =\displaystyle \sum_{s^\prime,r}p(s^\prime,r|s,a)r+ \gamma \sum_{s^\prime,r}p(s^\prime,r|s,a) \sum_{a^\prime}\pi(a^\prime|s^\prime) \mathbb{E}_\pi[G_{t+1}|S_{t+1}=s^\prime,A_{t+1}=a^\prime] \\ & =\displaystyle \sum_{s^\prime,r}p(s^\prime,r|s,a)[r+ \gamma \sum_{a^\prime}\pi(a^\prime|s^\prime)q_\pi(s^\prime,a^\prime)] \end{aligned} \tag{2.12} \]
價值函式的相互轉換
??從定義的角度,我們更容易理解\(v_\pi(s)\)和\(q_\pi(s,a)\)的關系,我們可以將\(q_\pi(s,a)\)理解為執行策略后選取動作空間中一個動作所得到的價值函式,而將\(v_\pi(s)\)理解為執行策略后選擇動作空間中所有動作所得到的價值函式,\(v_\pi\)其實就是\(q_\pi\)基于策略\(\pi\)的期望值,所以它們的關系轉換如下:
\[v_\pi(s)= \sum_a \pi(a|s)q_\pi(s,a) \tag{2.13} \]
??它的回溯圖如下圖所示:
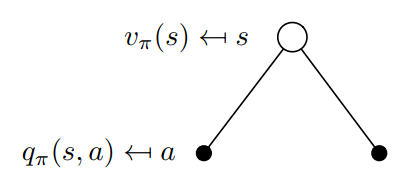
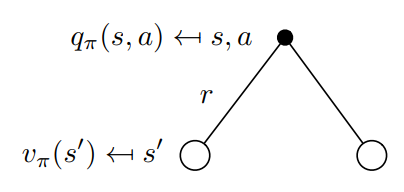
\[q_\pi(s,a) =\displaystyle \sum_{s^\prime,r}[r+ \gamma v_\pi(s^\prime)] \tag{2.14} \]
最優策略和最優價值函式
最優策略
??智能體的目標就是找出一種策略,能夠最大化它的長期獎勵,這個策略就是最優策略(optimal policy),記作\(\pi_*\),公式表示如下:
\[\forall s \in \mathcal{S}, \exist \pi_* \ge \pi, v_{\pi_*}(s) \ge v_\pi(s) \tag{2.15} \]
??也可以將上式的狀態價值函式替換為動作價值函式,它們在尋找最優策略上是等價的,
最優價值函式
??最優狀態價值函式可以定義為
\[v_*(s) \doteq \max_\pi v_\pi(s) \tag{2.16} \]
??\(v_*(s)\)的貝爾曼最優方程為
\[v_*(s)=\displaystyle \max_a \sum_{s^\prime.r} p(s^\prime,r|s,a) [r+\gamma v_*(s^\prime)] \tag{2.17} \]
??最優動作價值函式可以定義為
\[q_*(s,a) \doteq \max_\pi q_\pi(s,a) \tag{2.18} \]
??\(q_*(s,a)\)的貝爾曼最優方程為
\[q_*(s,a)=\displaystyle \sum_{s^\prime,r}p(s^\prime,r|s,a)[r+ \gamma \max_{a^\prime} q_*(s^\prime,a^\prime)] \tag{2.19} \]
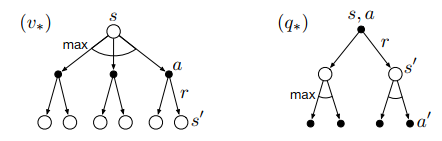
??下圖展示了\(v_*(s)\)和\(q_*(s,a)\)的貝爾曼最優方程的回溯圖(弧線表示在給定策略下取最大值而不是期望值)
后續概念
強化學習的方法
??強化學習方法可以分為基于模型的(model-based)和不基于模型的(model-free),二者之間的區別在于是否有完備的環境知識,若存在MDP中的狀態轉移概率矩陣\(\mathcal{P}\),且能得到相應的獎勵\(\mathcal{R}\),則是基于模型的;否則,是不基于模型的,
強化學習的問題
??一般來說,強化學習問題可以分為兩步:一、預測問題——給定強化學習的相關要素,評估價值函式;二、控制問題——求解最優價值函式和最優策略,
FAQ
- Q:如果當前狀態是\(S_t\),并根據隨機策略\(\pi\)選擇動作,那么如何用\(\pi\)和四引數\(p\)表示\(R_{t+1}\)的期望?
A:\(\mathbb{E}_\pi[R_{t+1}|S_t=s]=\displaystyle \sum_a\pi(a|s) \sum_{s^\prime,r}rp(s^\prime,r|s,a)\)
References
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction (Second Edition). Cambridge, Massachusetts London, England : The MIT Press, 2018.
Csaba Szepesvári, ‘Algorithms for Reinforcement Learning’, Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 4, no. 1, pp. 1–103, Jan. 2010, doi: 10.2200/S00268ED1V01Y201005AIM009.
UCL Reinforcement Learning Course by David Silver:https://www.bilibili.com/video/BV1b7411y7ax
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/36668.html
標籤:其他
上一篇:三菱A系列plc 程式背景黃色