首先參考下網上的解釋:
For a grayscale image, every pixel in the mean image is computed from the average of all corresponding pixels (i.e. same coordinates) across all images of your dataset. "Mean image" subtraction means that this mean image is subtracted from any input image you feed to the neural network. The intention is to have inputs that are (on average) centred around zero.
The mean pixel is simply the average of all pixels in the mean image. "Mean pixel" subtraction means that you subtract the *same* mean pixel value from all pixels of the input to the neural network.
Now the same applies to RGB images, except that every channel is processed independently (this means we don't compute averages across channels, instead every channel independently goes through the same transformations as for a grayscale image).
Intuitively, it feels like mean image subtraction should perform better (that is what I noticed on the auto-encoder example in DIGITS) although I don't know of research papers that back this up.
對于灰度影像,平均影像中的每個像素都是由資料集中所有影像間的相應像素(即相同坐標)的平均值計算得出的,“平均影像”減法意味著從輸入神經網路的任何輸入影像中減去該平均影像,目的是使輸入(平均)以零為中心,
平均像素只是平均影像中所有像素的平均值,“平均像素”減法意味著從輸入到神經網路的所有像素中減去“相同的"平均像素值,
這同樣適用于RGB影像,除了每個通道都是獨立處理的(這意味著我們不計算通道之間的平均值,而是每個通道獨立地進行與灰度影像相同的轉換),
從直覺上講,感覺像平均影像減法應該表現的更好(這是我在DIGITS中的自動編碼器示例中注意到的),盡管我不知道有支持這種情況的研究論文,
image mean:
舉例來說,輸入一張RGB影像,比如N*N*3,對其求image mean,結果仍是N*N*3,即對訓練集中所有影像在同一空間位置上(也是相同通道,不跨通道)的像素求均值,
pixel mean:
而pixel mean,是把所有影像的R通道的像素求均值,G,B通道一樣,不考慮空間位置的關系,這樣求得的結果是R_mean, G_mean, B_mean,相當于把image mean再次求平均,
減去均值的原因:
(1)從PCA的角度
減去均值是為了資料特征標準化,特征標準化指的是使資料的每一個維度具有零均值和單位方差,這是歸一化中最常用的方法,在實際計算中,特征標準化的具體操作是:首先計算每一個維度上資料的均值(使用全體資料來計算),然后在每一個維度上都減去該均值,最后在資料的每一個維度上除以該維度上資料的標準差,
對于自然影像來說,更多的是做影像零均值化處理,并不需要估計樣本的方差,這是因為在自然影像上進行訓練時,對每一個像素單獨估計均值和方差的意義不大,因為(理論上)影像上任一部分的統計性質都應該和其他部分相同,影像的這種性質被稱作平穩性(stationarity),
對于影像,這種歸一化可以移除影像的平均亮度值(intensity),很多情況下我們對影像的照度并不感興趣,而更多地關注其內容,比如在物體識別任務中,影像的整體明亮程度并不會影響影像中存在的是什么物體,這時對每個資料點移除像素的均值是有意義的,
(2)從反向傳播計算的角度
在深度學習中,使用gradient descent來訓練模型的話,基本都要在資料預處理時進行資料歸一化,當然這是有原因的,
根據公式
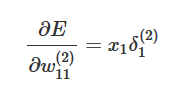
如果輸入層 χ 很大,在反向傳播時傳遞到輸入層的梯度就會變得很大,梯度大,學習率就得非常小,否則會越過最優,在這種情況下,學習率的選擇需要參考輸入層的數值大小,而直接將資料歸一化操作,可以很方便的選擇學習率,而且受 χ 和 w 的影響,各個梯度的數量級不相同,因此,它們需要的學習率數量級也就不相同,對于w1 適合的學習率,可能相對于w2 來說太小,如果仍使用適合w1 的學習率,會導致在w2的方向上下降地很慢,會消耗非常多的時間,而使用適合W2的學習率,對于w1來說又太大,找不到適合w1的解,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/36670.html
標籤:其他
下一篇:如何套用已知R代碼尋找資料斷點