在訓練卷積神經網路模型時,經常遇到max pooling 和 average pooling,近些年的影像分類模型多數采用了max pooling,為什么都是使用max pooling,它的優勢在哪呢?
一般情況下,max pooling的效果更好,雖然 max pooling 和 average pooling 都對資料做了sampling,但是感覺max pooling更像是做了特征選擇,選出了分類辨識度更高的特征,提供了非線性,根據相關理論,特征提取的誤差主要來自兩個方面:(1)鄰域大小受限造成的估計值方差增大;(2)卷積層引數誤差造成估計均值的偏移,一般來說,average pooling 能減小第一種誤差,更多地保留影像的背景資訊,max pooling 能減小第二種誤差,更多地保留紋理資訊,average pooling 更側重對整體特征資訊進行sampling,在減少引數維度方面的貢獻更大一些,更多地體現在資訊的完整傳遞這個層面上,在一個很大很有代表性的模型中,比如DenseNet中的模塊之間的連接大多采用 average pooling,在減少維度的同時,更有利資訊傳遞到下一個模塊進行特征提取,
average pooling 在全域平均池化操作中應用得也比較廣,在ResNet和Inception結構中最后一層都使用了平均池化,有的時候,在接近模型分類器的末端使用全域平均池化還可以代替flatten操作,使輸入資料變成一維向量,
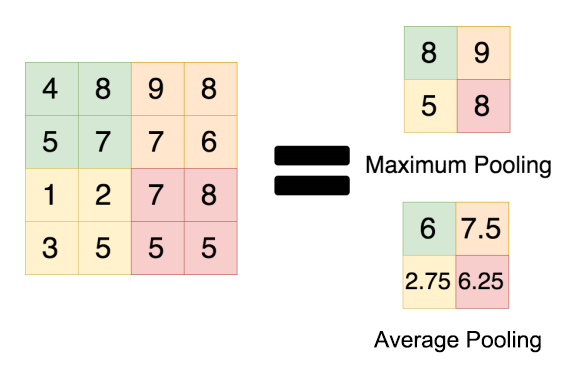
max pooling 和 average pooling 的使用性能對于設計卷積網路模型還是很有幫助的,雖然池化操作對于整體的精度提升效果不大,但是在減參降維,控制過擬合以及提高模型性能,節約算力方面的作用還是很明顯的,所以池化操作是卷積神經網路設計上不可缺少的一個環節,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/36674.html
標籤:其他