代碼倉庫: https://github.com/brandonlyg/cute-dl
目標
- 為Session類增加自動分批訓練模型的功能, 使框架更好用,
- 新增緩解過擬合的演算法: L2正則化, 隨機丟棄,
實作自動分批訓練
設計方案
- 增加Dataset類負責管理資料集, 自動對資料分批,
- 在Session類中增加fit方法, 從Dataset得到資料, 使用事件機制告訴外界訓練情況, 最后回傳一個訓練歷史記錄,
- 增加FitListener類, 用于監聽fit方法訓練程序中觸發的事件,
fit方法
定義:
fit(self, data, epochs, **kargs)
data: 訓練資料集Dataset物件,
epochs: 訓練輪數, 把data中的每一批資料遍歷訓練一次稱為一輪,
kargs:
val_data: 驗證資料集,
val_epochs: 執行驗證的訓練輪數. 每val_epochs輪訓練驗證一次,
val_steps: 執行驗證的訓練步數. 每val_steps步訓練驗證一次. 只有val_steps>0才有效, 優先級高于val_epochs,
listeners: 事件監聽器FitListener物件串列.
fit方法觸發的事件
- epoch_start: 每輪訓練開始時觸發,
- epoch_end: 每輪訓練結束時觸發,
- val_start: 每次執行驗證時觸發,
- val_end: 每次執行驗證結束時觸發,
訓練程序中, fit方法會把觸發的事件派發到所有的FitListener物件, FitListener物件自己決定處理或忽略,
訓練歷史記錄(history)
history的格式:
{
'loss': [],
'val_loss': [],
'steps': [],
'val_pred': darray,
'cost_time': float
}
- loss: 記錄訓練誤差,
- val_loss: 記錄驗證誤差,loss會和val_loss同步記錄,
- steps: 每個誤差記錄對應的訓練步數,
- val_pred: 最后一次執行驗證時模型使用驗證資料集預測的結果,
- cost_time: 整個訓練程序花費的時間(s),
代碼
fit方法實作
代碼檔案: cutedl/session.py,
fit方法比較復雜, 先看主干代碼:
#初始化訓練歷史資料結構
history = {
'loss': [],
'val_loss': [],
'steps': [],
'val_pred': None,
'cost_time': 0
}
#打開訓練開關, 當呼叫stop_fit方法后會關閉這個開關, 停止訓練,
self.__fit_switch = True
#得到引數
val_data = https://www.cnblogs.com/brandonli/p/kargs.get('val_data')
val_epochs = kargs.get('val_epochs', 1)
val_steps = kargs.get('val_steps', 0)
listeners = kargs.get('listeners', [])
if val_data is None:
history['val_loss'] = None
#計算將會訓練的最大步數
if val_epochs <= 0 or val_epochs >= epochs:
val_epochs = 1
if val_steps <= 0:
val_steps = val_epochs * data.batch_count
#開始訓練
step = 0
history['cost_time'] = time.time()
for epoch in range(epochs):
if not self.__fit_switch:
break
#觸發并派發事件
event_dispatch("epoch_start")
for batch_x, batch_y in data.as_iterator():
if not self.__fit_switch:
break
#pdb.set_trace()
loss = self.batch_train(batch_x, batch_y)
step += 1
if step % val_steps == 0:
#使用驗證資料集驗證模型
event_dispatch("val_start")
val_loss, val_pred = validation()
record(loss, val_loss, val_pred, step)
event_dispatch("val_end")
#顯示訓練進度
display_progress(epoch+1, epochs, step, val_steps, loss, val_loss)
else:
display_progress(epoch+1, epochs, step, val_steps, loss)
event_dispatch("epoch_end")
#記錄訓練耗時
history['cost_time'] = time.time() - history['cost_time']
return history
主干代碼中使用了一些區域函式, 這些區域函式每個都是實作了一個小功能,
派發事件:
def event_dispatch(event):
#pdb.set_trace()
for listener in listeners:
listener(event, history)
執行驗證:
def validation():
if val_data is None:
return None, None
val_pred = None #保存所有的預測結果
losses = [] #保存所有的損失值
#分批驗證
for batch_x, batch_y in val_data.as_iterator():
#pdb.set_trace()
y_pred = self.__model.predict(batch_x)
loss = self.__loss(batch_y, y_pred)
losses.append(loss)
if val_pred is None:
val_pred = y_pred
else:
val_pred = np.vstach((val_pred, y_pred))
#計算平均損失
loss = np.mean(np.array(losses))
return loss, val_pred
記錄訓練歷史:
def record(loss, val_loss, val_pred, step):
history['loss'].append(loss)
history['steps'].append(step)
if history['val_loss'] is not None and val_loss is not None :
history['val_loss'].append(val_loss)
history['val_pred'] = val_pred
顯示訓練進度:
def display_progress(epoch, epochs, step, steps, loss, val_loss=-1):
prog = (step % steps)/steps
w = 20
str_epochs = ("%0"+str(len(str(epochs)))+"d/%d")%(epoch, epochs)
txt = (">"*(int(prog * w))) + (" "*w)
txt = txt[:w]
if val_loss < 0:
txt = txt + (" loss=%f "%loss)
print("%s %s"%(str_epochs, txt), end='\r')
else:
txt = "loss=%f, val_loss=%f"%(loss, val_loss)
print("")
print("%s %s\n"%(str_epochs, txt))
實作L2正則化引數優化器
設計方案
- 增強Optimizer類的功能, 能夠自己匹配要更新的引數,
- 給出L2正則化演算法的Optimizer實作,
- 在Session類中增加對廣義優化器的支持(L2優化器就是廣義優化器),
數學原理
設模型每一層的損失函式為:
\[J=f(XW+b) \]
X是資料, W是權重引數,b是偏移量引數. L2演算法是在原損失函式上加上W范數平方的衰減量, 得到一個新的損失函式:
\[J_{L2} = J + \frac{λ}{2}||W||^2 \]
λ是衰減率, 是一個相當于學習率的超引數,對于一個模型來說, 只有輸出層的損失函式是明確知道的, 其他層是不明確的,不過沒關系, 更新引數是在反向傳播階段,這個時候需要的是梯度, 并不關心原函式的形式, 新損失函式的梯度為:
\[\frac{\partial}{\partial W_i}J_{L2} = \frac{\partial}{\partial W_i} J + λW_i \]
其中
\[\frac{\partial}{\partial W_i} J \]
可以在反向傳播時候得到. 在梯度下降法訓練模型時, 更新引數的運算式變成:
\[W_i = W_i - (α\frac{\partial}{\partial W_i} J + λW_i) = (1-λ)W_i - α\frac{\partial}{\partial W_i} J, \quad \text{α是學習率} \]
這個運算式的含義是: 在使用學習率更新引數之前,先把引數(W的范數)縮小到原來的(1-λ)倍,
代碼
增強Optimizer功能
代碼檔案: cutedl/optimizer.py
修改__call__代碼:
def __call__(self, model):
params = self.match(model)
for p in params:
self.update_param(model, p)
match方法用來把名字匹配的引數過濾出來,
update_param方法實作實際的更新引數操作, 由子類實作,
match實作:
'''
得到名字匹配pattern的引數
'''
def match(self, model):
params = []
rep = re.compile(self.pattern)
for ly in model.layer_iterator():
for p in ly.params:
if rep.match(p.name) is None:
continue
params.append(p)
return params
這個方法使用正則運算式通過引數名匹配引數, 并回傳匹配的引數串列,pattern是正則運算式屬性, 子類可以通過覆寫這個屬性, 改變匹配行為,
實作L2正則化優化器
'''
L2 正則化
'''
class L2(Optimizer):
'''
damping 引數衰減率
'''
def __init__(self, damping):
self.__damping = damping
def update_param(self, model, param):
#pdb.set_trace()
param.value = https://www.cnblogs.com/brandonli/p/(1 - self.__damping) * param.value
在Session中支持廣義引數優化器
代碼檔案: cutedl/session.py,
首先為__init__ 方法添加引數:
'''
genoptms: list[Optimizer]物件, 廣義引數優化器串列,
串列中的優化器將會在optimizer之前按順序執行
'''
def __init__(self, model, loss, optimizer, genoptms=None):
self.__genoptms = genoptms
然后在batch_train方法中呼叫優化器:
#執行廣義優化器更新引數
if self.__genoptms is not None:
for optm in self.__genoptms:
optm(self.__model)
實作隨機丟棄層: Dropout
數學原理
向前傳播的函式:
\[Y_i = \frac{A_i}{p} X_i, \quad A_i服從引數為p的伯努利分布, p∈(0, 1) \]
p是我們要給出的常數,演算法使用p構造隨機變數A, 使得A=1的概率為p, A=0的概率為1-p. 對這個函式的直觀解釋是: A將有1-p的概率被丟棄掉(置為0), p的概率被保留, 如果被保留, 它將會被拉伸1/p倍, 這個函式有一個很有用的性質, 它的輸入和輸出的均值不變:
\[E(Y_i) = \frac{E(A_i)}{p} E(X_i) = \frac{p}{p} E(X_i) = E(X_i) \]
反向傳播的梯度為:
\[\frac{\partial}{\partial X_i} = \frac{A_i}{p} \]
代碼
代碼檔案: nn_layers.py,
Dropout類實作了隨機丟棄演算法,向前傳播實作:
def forward(self, in_batch, training=False):
kp = self.__keep_prob
#pdb.set_trace()
if not training or kp <= 0 or kp>=1:
return in_batch
#生成[0, 1)之間的均價分布
tmp = np.random.uniform(size=in_batch.shape)
#保留/丟棄索引
mark = (tmp <= kp).astype(int)
#丟棄資料, 并拉伸保留資料
out = (mark * in_batch)/kp
self.__mark = mark
return out
隨機丟棄層傳入的引數是keep_prob保留概率, 這意味這丟棄的概率為1 - keep_prob. 只有處于訓練狀態且0<keep_prob<1才執行丟棄操作,代碼中的變數mark就是用保留概率構造隨機變數, 它服從引數為keep_prob的伯努利分布,
反向傳播實作:
def backward(self, gradient):
#pdb.set_trace()
if self.__mark is None:
return gradient
out = (self.__mark * gradient)/self.__keep_prob
return out
驗證
目前階段所需要的代碼已經完成,現在我們來進行驗證,驗證代碼位于: examples/mlp/linear-regression-1.py,
對比基準
首先我們來構造一個欠擬合模型作為對比基準,
'''
過擬合對比基準
'''
def fit0():
print("fit0")
model = Model([
nn.Dense(128, inshape=1, activation='relu'),
nn.Dense(256, activation='relu'),
nn.Dense(1)
])
model.assemble()
sess = Session(model,
loss=losses.Mse(),
optimizer = optimizers.Fixed(),
)
history = sess.fit(ds, 200000, val_data=https://www.cnblogs.com/brandonli/p/val_ds, val_epochs=1000,
listeners=[
FitListener('val_end', callback=lambda h:on_val_end(sess, h))
]
)
fit_report(history, report_path+'00.png', 10)
可以看到這里不再需要自己寫訓練函式, 直接呼叫fit方法即可實作自動訓練,on_val_end函式監聽val_end事件, 它的功能是在滿是條件時呼叫Session的stop_fit方法停止訓練, 這里停止訓練的條件是: 最初的10次驗證過后, 檢查每次驗證的val_loss值, 如果連續10次沒有變得更小就停止訓練,
擬合報告:
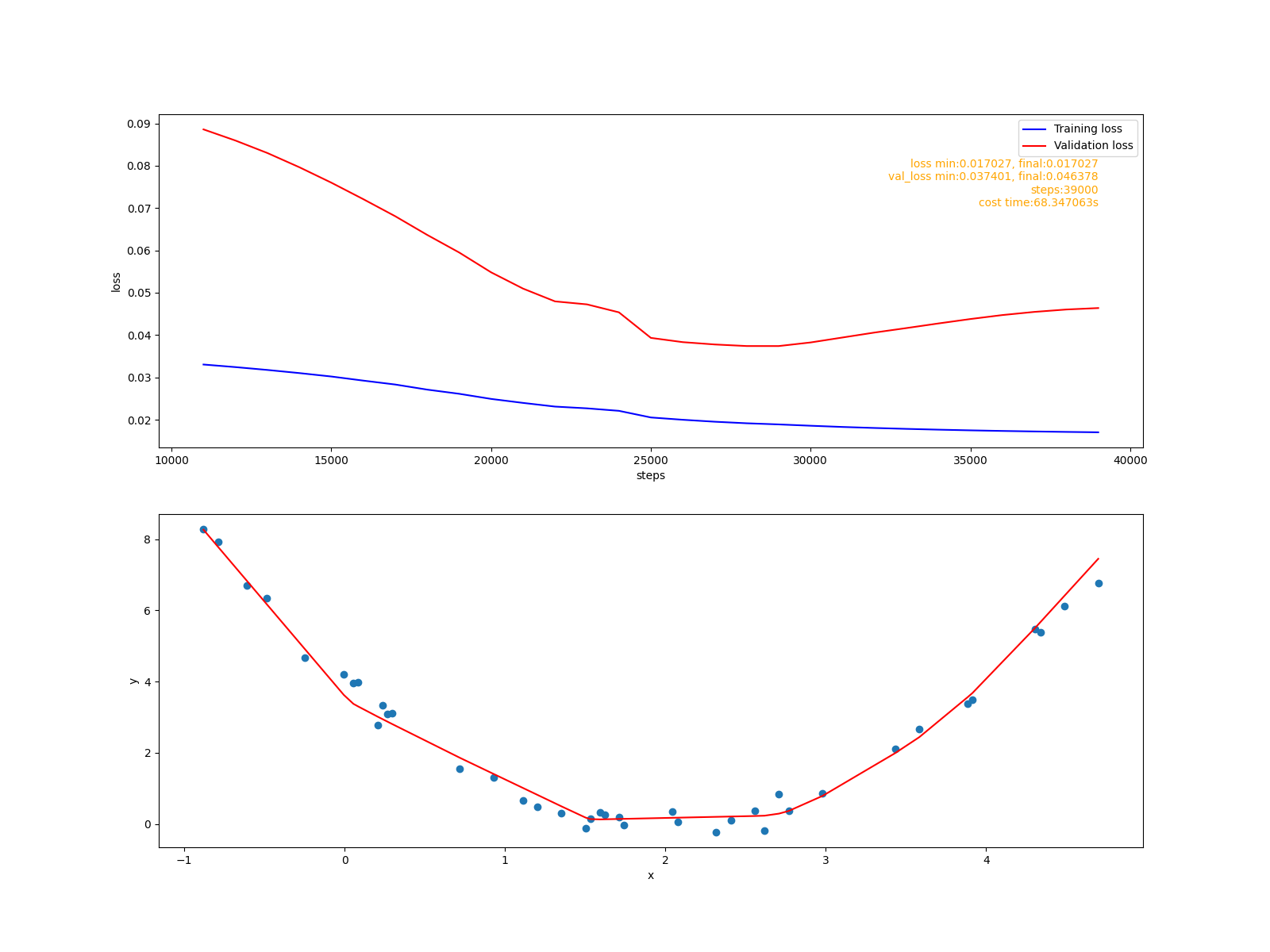
使用L2優化器緩解過擬合
'''
使用L2正則化緩解過擬合
'''
def fit1():
print("fit1")
model = Model([
nn.Dense(128, inshape=1, activation='relu'),
nn.Dense(256, activation='relu'),
nn.Dense(1)
])
model.assemble()
sess = Session(model,
loss=losses.Mse(),
optimizer = optimizers.Fixed(),
#L2正則化
genoptms = [optimizers.L2(0.00005)]
)
history = sess.fit(ds, 200000, val_data=https://www.cnblogs.com/brandonli/p/val_ds, val_epochs=1000,
listeners=[
FitListener('val_end', callback=lambda h:on_val_end(sess, h))
]
)
fit_report(history, report_path+'01.png', 10)
擬合報告:
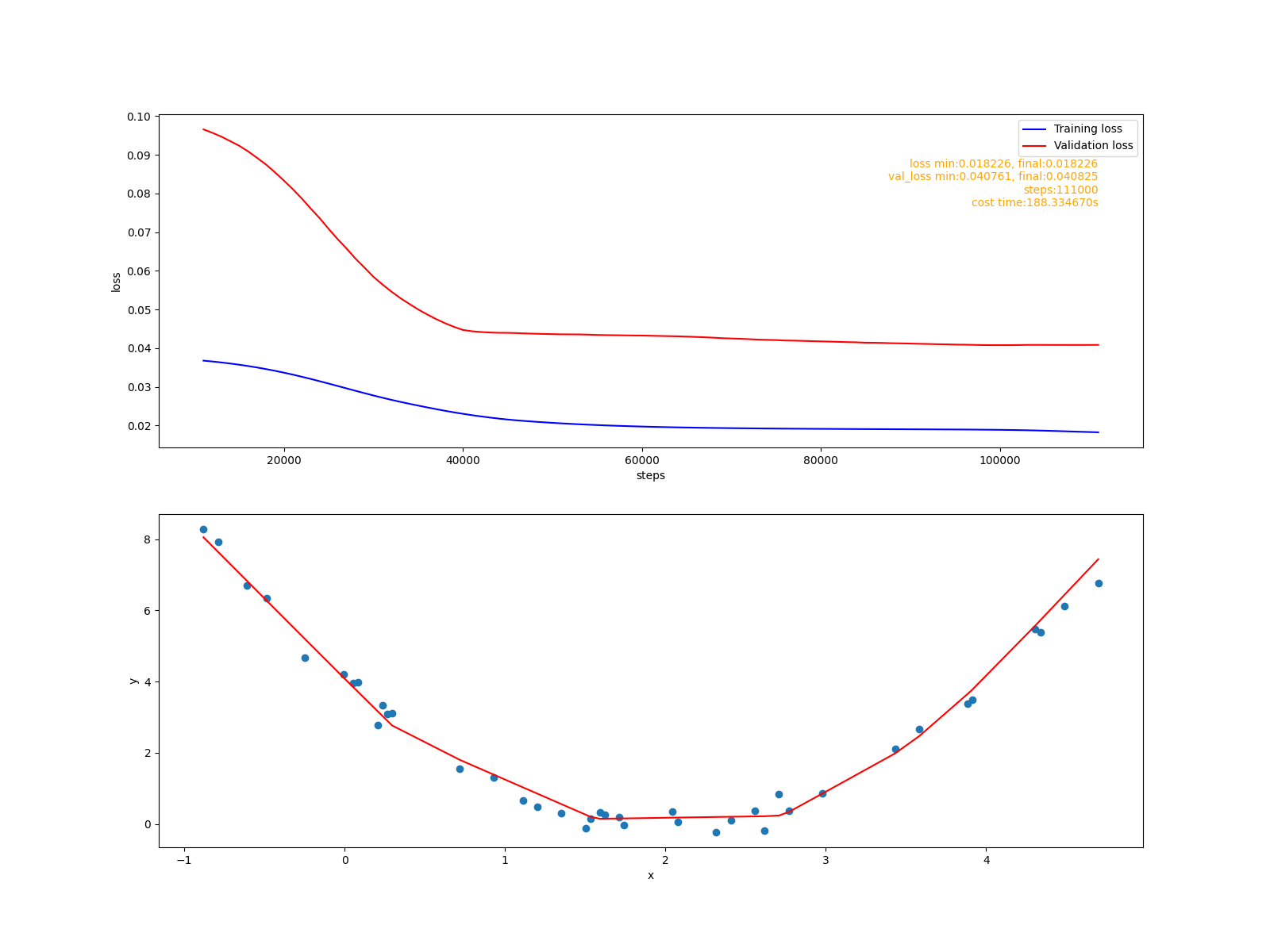
從訓練損失值影像上看有明顯的緩解跡象,
使用Dropout層緩解過擬合
'''
使用dropout緩解過擬合
'''
def fit2():
print("fit2")
model = Model([
nn.Dense(128, inshape=1, activation='relu'),
nn.Dense(256, activation='relu'),
nn.Dropout(0.80), #0.8的保留概率
nn.Dense(1)
])
model.assemble()
sess = Session(model,
loss=losses.Mse(),
optimizer = optimizers.Fixed(),
)
history = sess.fit(ds, 200000, val_data=https://www.cnblogs.com/brandonli/p/val_ds, val_epochs=1000,
listeners=[
FitListener('val_end', callback=lambda h:on_val_end(sess, h))
]
)
fit_report(history, report_path+'02.png', 15)
擬合報告:
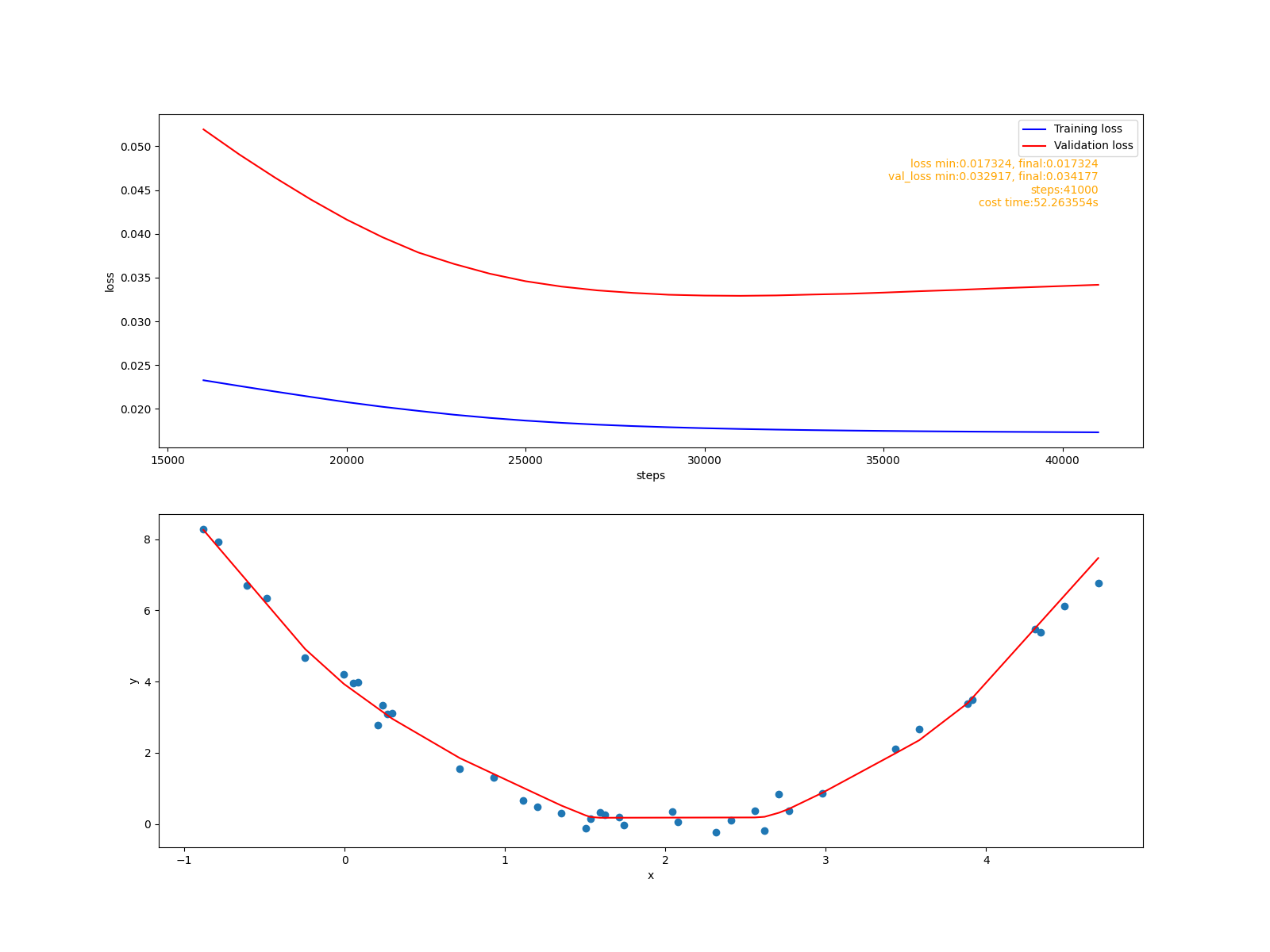
從訓練損失值影像上隨機丟棄的效果更好一些,
總結
驗證結果表明, cute-dl目前可以用很少代碼實作模型的自動分批訓練, 和linear-regression.py相比, linear-regression-1.py中已經不需要關注具體的訓練程序了, 并且能夠得到基本訓練歷史記錄,另外, L2正則化優化器和Dropout層也能有效地緩解過擬合, 本階段目標基本達成,
到目前為止, 用來驗證框架的是一個線性回歸任務, 資料集是從一個二次函式采樣得到, 這個任務本質上是訓練模型預測連續值,但是在深度學習領域,還要求模型能夠預測離散值,即能夠執行分類任務,下個階段, 將會給框架添加新的損失函式, 使之能夠支持分類任務, 并討論這些損失函式的數學性質,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/36690.html
標籤:其他