我在我的圖書館管理系統中做了一個結賬功能。它旨在讓用戶從給定的樹視圖中選擇書籍: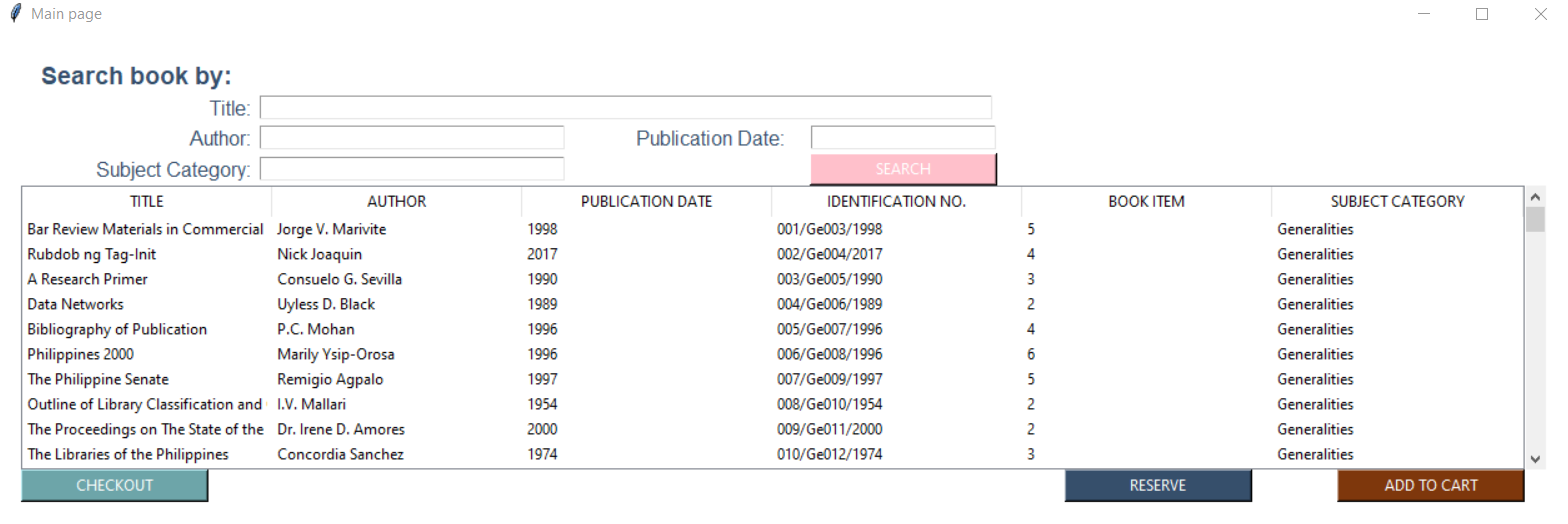 我的目標是獲取用戶單擊并按下“添加到購物車”到另一個帶有樹視圖的視窗的資料行:
我的目標是獲取用戶單擊并按下“添加到購物車”到另一個帶有樹視圖的視窗的資料行: 。只添加他們從主頁中選擇的特定行書籍資料。這是我的樹視圖代碼:
。只添加他們從主頁中選擇的特定行書籍資料。這是我的樹視圖代碼:
reserve_button = Button(text="RESERVE" ,fg=WHITE, bg=NAVY_BLUE, width=20, command=reserve)
reserve_button.grid(column=5,row=5)
checkout_button = Button(text="CHECKOUT", fg=WHITE,bg="#6DA5A9",width=20,command=checkout_page)
checkout_button.grid(column=0,row=5,sticky="w")
search_button = Button(text="SEARCH", fg=WHITE,bg="pink", width=20, command=search)
search_button.grid(column=3,row=3)
add_to_cart = Button(text="ADD TO CART", fg=WHITE,bg="#7E370C", width=20,command=add_to_cart_f)
add_to_cart.grid(column=7, row=5,sticky="e")
tree = ttk.Treeview()
books_data = pandas.read_csv("List of Books - Sheet1 (3).csv")
df_column = books_data.columns.values
print(len(df_column))
print(df_column)
tree["column"] = list(books_data.columns)
tree["show"] = "headings"
vsb = ttk.Scrollbar(orient="vertical", command=tree.yview())
vsb.grid(column=8, row=4, sticky="ns")
tree.configure(yscrollcommand=vsb.set)
for column in tree['column']:
tree.heading(column,text=column)
df_rows = books_data.to_numpy().tolist()
for row in df_rows:
tree.insert("","end",values=row)
tree.grid(column=0,row=4,columnspan=8)
uj5u.com熱心網友回復:
簡短的回答
我創建了一個使用這個的示例專案:
import tkinter as tk
import tkinter.ttk as ttk
import sys
from numpy import select
import pandas
# https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv
df = pandas.read_csv('./booklist.csv')
df.columns = df.columns.str.replace('.', '', regex=False)
df.columns = df.columns.str.replace(' ', '_', regex=False)
df.head()
class main_window:
def __init__(self, root):
self.root = root
root.title("Treeview Search Example")
# Create DataFrame for this window
self.build_df = df.copy()
self.checkout_ids = []
# INITIALIZE TREEVIEW SCROLLVIEW
self.tree = ttk.Treeview(root, columns=list(df.columns.values), show='headings')
self.tree.grid(row=1, column=0, sticky='nsew')
# https://stackoverflow.com/a/41880534/5210078
vsb = ttk.Scrollbar(root, orient="vertical", command=self.tree.yview)
vsb.grid(row=1, column=1, sticky='ns')
self.tree.configure(yscrollcommand=vsb.set)
for column in self.tree['column']:
self.tree.heading(column,text=column)
df_rows = df.to_numpy().tolist()
for row in df_rows:
if row[4] != 0:
self.tree.insert("","end",values=row)
# ADD SEARCH BOXES
search_frame = tk.Frame(root)
search_frame.grid(row=0, column=0, columnspan=2, sticky='nsew')
tk.Label(search_frame, text="TITLE:").grid(row=0, column=0)
tk.Label(search_frame, text="AUTHOR:").grid(row=0, column=2)
tk.Label(search_frame, text="IDENTIFICATION NO:").grid(row=0, column=4)
tk.Label(search_frame, text="SUBJECT CATEGORY:").grid(row=0, column=6)
# Add Search boxes
self.title_ent = tk.Entry(search_frame)
self.title_ent.grid(row=0, column=1)
self.author_ent = tk.Entry(search_frame)
self.author_ent.grid(row=0, column=3)
self.identifaction_ent = tk.Entry(search_frame)
self.identifaction_ent.grid(row=0, column=5)
self.category_ent = tk.Entry(search_frame)
self.category_ent.grid(row=0, column=7)
tk.Button(search_frame, text="Search", command=self.search).grid(row=0, column=10)
tk.Button(search_frame, text="Reseve", command=self.reserve).grid(row=0, column=11)
def search(self):
# https://stackoverflow.com/a/27068344/5210078
self.tree.delete(*self.tree.get_children())
self.build_df = df.copy()
# https://stackoverflow.com/a/56157729/5210078
entries = [
self.title_ent,
self.author_ent,
self.identifaction_ent,
self.category_ent
]
if entries[0].get():
self.build_df = self.build_df[self.build_df.TITLE.str.contains(entries[0].get())]
if entries[1].get():
self.build_df = self.build_df[self.build_df.AUTHOR.str.contains(entries[1].get())]
if entries[2].get():
self.build_df = self.build_df[self.build_df.SUBJECT_CATEGORY.str.contains(entries[2].get())]
if entries[3].get():
self.build_df = self.build_df[self.build_df.PUBLICATION_DATE == (entries[3].get())]
df_rows = self.build_df.to_numpy().tolist()
for row in df_rows:
print(row)
if row[4] != 0:
self.tree.insert("","end",values=row)
def reserve(self):
selected = self.tree.item(self.tree.focus())
if selected['values']:
# get the id
book_id = selected['values'][3]
book_id_val = df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'].to_numpy().tolist()[0]
if book_id_val < 1:
return 0
else:
self.checkout_ids.append(book_id)
df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'] = book_id_val - 1
self.search()
if __name__ == '__main__':
main = tk.Tk()
main_window(main)
main.mainloop()
sys.exit()
凡booklist.csv如下所示:
TITLE,AUTHOR,PUBLICATION DATE,IDENTIFICATION NO.,BOOK ITEM,SUBJECT CATEGORY
Book 1,Author 1,1923,001/geo003/1993,4,Awesome
Book 2,Author 2,1924,001/geo003/1994,5,Awesome
Book 3,Author 3,1925,001/geo003/1995,6,Awesome
Book 4,Author 4,1926,001/geo003/1996,7,Awesome
Book 5,Author 5,1927,001/geo003/1997,8,Awesome
Book 6,Author 6,1928,001/geo003/1998,9,Awesome
Book 7,Author 7,1929,001/geo003/1999,10,Awesome
Book 8,Author 8,1930,001/geo003/2000,11,Awesome
Book 9,Author 9,1931,001/geo003/2001,12,Awesome
Book 10,Author 10,1932,001/geo003/2002,13,Awesome
說明
df = pandas.read_csv('./booklist.csv')
df.columns = df.columns.str.replace('.', '', regex=False)
df.columns = df.columns.str.replace(' ', '_', regex=False)
清理csv檔案,所以沒有空格或.列名(pandas真的不喜歡它們,它們不是必需的)
class main_window:
def __init__(self, root):
self.root = root
root.title("Treeview Search Example")
# Create DataFrame for this window
self.build_df = df.copy()
self.checkout_ids = []
初始化一個main_window包含您需要的代碼的類。并創建兩個變數build_dfand checkout_ids,這checkout_ids將是一個包含您當前“籃子”的串列。該build_df握著你的臨時副本DataFrame (df),它可以過濾只要你喜歡搬來搬去,而不會影響原來的DataFrame。
# INITIALIZE TREEVIEW SCROLLVIEW
self.tree = ttk.Treeview(root, columns=list(df.columns.values), show='headings')
self.tree.grid(row=1, column=0, sticky='nsew')
# https://stackoverflow.com/a/41880534/5210078
vsb = ttk.Scrollbar(root, orient="vertical", command=self.tree.yview)
vsb.grid(row=1, column=1, sticky='ns')
self.tree.configure(yscrollcommand=vsb.set)
for column in self.tree['column']:
self.tree.heading(column,text=column)
df_rows = df.to_numpy().tolist()
for row in df_rows:
if row[4] != 0:
self.tree.insert("","end",values=row)
# ADD SEARCH BOXES
search_frame = tk.Frame(root)
search_frame.grid(row=0, column=0, columnspan=2, sticky='nsew')
tk.Label(search_frame, text="TITLE:").grid(row=0, column=0)
tk.Label(search_frame, text="AUTHOR:").grid(row=0, column=2)
tk.Label(search_frame, text="IDENTIFICATION NO:").grid(row=0, column=4)
tk.Label(search_frame, text="SUBJECT CATEGORY:").grid(row=0, column=6)
# Add Search boxes
self.title_ent = tk.Entry(search_frame)
self.title_ent.grid(row=0, column=1)
self.author_ent = tk.Entry(search_frame)
self.author_ent.grid(row=0, column=3)
self.identifaction_ent = tk.Entry(search_frame)
self.identifaction_ent.grid(row=0, column=5)
self.category_ent = tk.Entry(search_frame)
self.category_ent.grid(row=0, column=7)
tk.Button(search_frame, text="Search", command=self.search).grid(row=0, column=10)
tk.Button(search_frame, text="Reseve", command=self.reserve).grid(row=0, column=11)
初始化主 UI,它包含諸如輸入框之類的東西。重要的是,使用if陳述句:if row[4] != 0:是因為如果沒有可用的書籍,則沒有理由顯示它們!
def search(self):
# https://stackoverflow.com/a/27068344/5210078
self.tree.delete(*self.tree.get_children())
self.build_df = df.copy()
# https://stackoverflow.com/a/56157729/5210078
entries = [
self.title_ent,
self.author_ent,
self.identifaction_ent,
self.category_ent
]
if entries[0].get():
self.build_df = self.build_df[self.build_df.TITLE.str.contains(entries[0].get())]
if entries[1].get():
self.build_df = self.build_df[self.build_df.AUTHOR.str.contains(entries[1].get())]
if entries[2].get():
self.build_df = self.build_df[self.build_df.SUBJECT_CATEGORY.str.contains(entries[2].get())]
if entries[3].get():
self.build_df = self.build_df[self.build_df.PUBLICATION_DATE == (entries[3].get())]
df_rows = self.build_df.to_numpy().tolist()
for row in df_rows:
print(row)
if row[4] != 0:
self.tree.insert("","end",values=row)
該search系統仍然是一樣的以前的答案!除了if前面看到的添加的陳述句功能之外!
儲備功能
def reserve(self):
selected = self.tree.item(self.tree.focus())
if selected['values']:
# get the id
book_id = selected['values'][3]
book_id_val = df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'].to_numpy().tolist()[0]
if book_id_val < 1:
return 0
else:
self.checkout_ids.append(book_id)
df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'] = book_id_val - 1
self.search()
selected = self.tree.item(self.tree.focus())
從當前選擇的專案中獲取 self.tree
if selected['values']:
如果有一個選定的專案(當什么都沒有選擇時停止錯誤)
book_id = selected['values'][3]
book_id從所選專案中獲取(第 4 列)并存盤它的副本。
book_id_val = df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'].to_numpy().tolist()[0]
在原版中 找到這本書,DataFrame并獲取其中有多少本書!
if book_id_val < 1:
return 0
如果沒有可用的書籍,請不要做任何事情(這是一個后備錯誤捕捉器,因為它不是完全必要的)。
self.checkout_ids.append(book_id)
df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'] = book_id_val - 1
self.search()
- 將 的副本存盤
id到checkout_ids串列中 - 將可用書籍的數量減少一本
- 重新加載樹視圖!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/369272.html
上一篇:計算器不總結總數