我正在從事一個專案,該專案要求我通過網路抓取 IMDB 并構建一個 pd 資料框。
這是我目前正在處理的網址: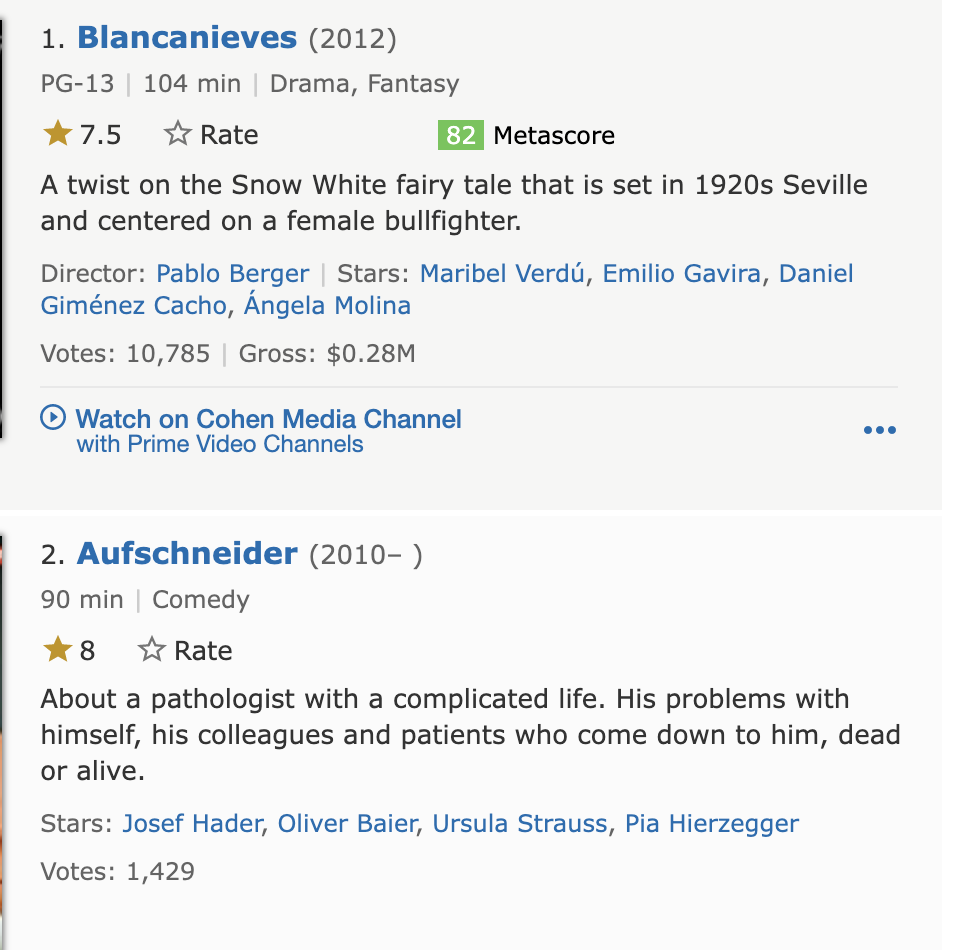
html 代碼如下所示:
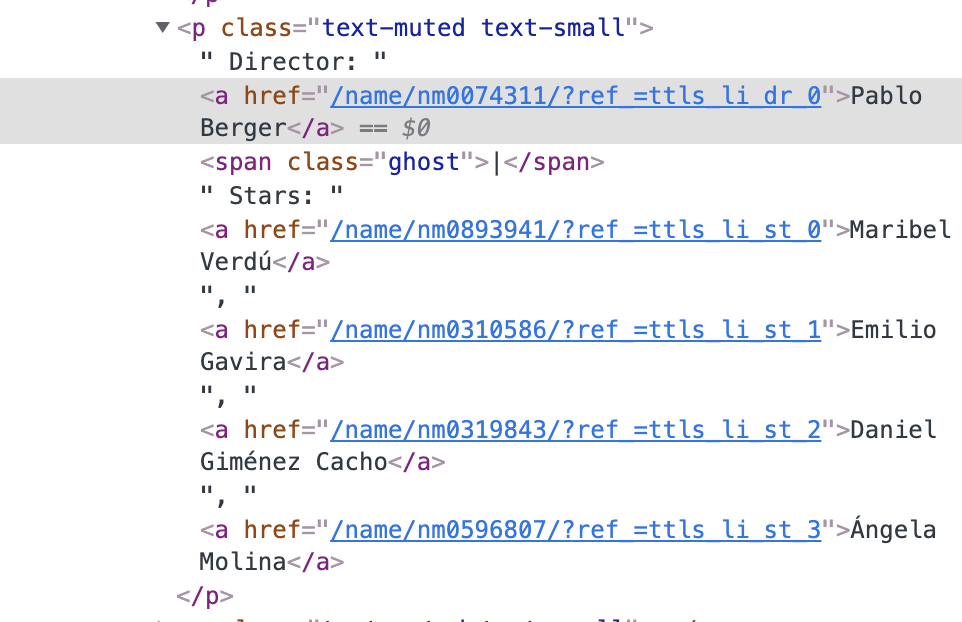
我寫了一個函式,它使用 Beautiful Soup 從 html 中獲取每個導演(text_muted 只是我螢屏截圖上的代碼部分):
def getDirector(text_muted):
try:
return text_muted.find("a").getText()
except:
return 'NA'
text_muted_stuff = movie.find_all("p", {"class": "text-muted text-small"})[1]
director = getDirector(text_muted_stuff) # Need to seperate director and actor
movie_director.append(director)
我設法將所有導演和明星都放在一個串列中,但我想更具體一些,只用導演填充串列(如果任何電影沒有導演,請附加 NA)。我不確定是否可以使用 Beautiful Soup 或任何硬代碼來實作這一點。
謝謝
uj5u.com熱心網友回復:
編輯: diggusbickus 評論更嚴格,所以你不必檢查兩次 -很好。將完整示例更改為它的方法,結果相同。
[x.text for x in d] if (d := item.select('a[href*="_dr_"]')) else None
屬性選擇器
[href*="_dr_"]- 表示具有命名屬性的元素,href其值包含子字串_dr_。
第一種方法
您可以選擇帶有css selector和 條件的導演,該條件也檢查href.
[x.text for x in d if '_dr_' in x['href']] if (d := item.select('p:-soup-contains("Director:") a')) else None
<a>在<p>包含Director 的a中選擇所有:item.select('p:-soup-contains("Director:") a')檢查元素是否不是
Noneelse 將導演的值設定為None檢查是否有
_dr_在href,以確保其董事if '_dr_' in x['href']
示例(https://www.imdb.com/search/title/?genres=action)
import requests
from bs4 import BeautifulSoup
url = 'https://www.imdb.com/search/title/?genres=action'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
page = requests.get(url,headers=headers)
soup = BeautifulSoup(page.text, 'html.parser')
data = []
for item in soup.select('.lister-item'):
data.append({
'title':item.h3.a.text,
'url':'https://www.imdb.com' item.a['href'],
# if you do not like lists in your data frame, simply join ','.join([x.text for x in d])
'director': [x.text for x in d] if (d := item.select('a[href*="_dr_"]')) else None,
'stars':[x.text for x in s] if (d := item.select('a[href*="_st_"]')) else None
})
pd.DataFrame(data)
輸出
| 標題 | 網址 | 導向器 | 星星 |
|---|---|---|---|
| 時代周報 | https://www.imdb.com/title/tt7462410/?ref_=adv_li_i | [‘羅莎蒙德·派克’、‘丹尼爾·海尼’、‘瑪德琳·馬登’、‘佐伊·羅賓斯’] | |
| 奧術 | https://www.imdb.com/title/tt11126994/?ref_=adv_li_i | [“凱文·亞歷杭德羅”、“杰森·斯皮薩克”、“海莉·斯坦菲爾德”、“哈利·勞埃德”] | |
| 鷹眼 | https://www.imdb.com/title/tt10160804/?ref_=adv_li_i | [“杰瑞米·雷納”、“海莉·斯坦菲爾德”、“弗洛倫斯·普格”、“托尼·道爾頓”] | |
| 牛仔布 | https://www.imdb.com/title/tt1267295/?ref_=adv_li_i | ['John Cho'、'Mustafa Shakir'、'Daniella Pineda'、'Elena Satine'] | |
| 紅色通告 | https://www.imdb.com/title/tt7991608/?ref_=adv_li_i | ['羅森·馬歇爾·瑟伯'] | [“道恩·強森”、“瑞安·雷諾茲”、“蓋爾·加朵”、“瑞圖·艾莉亞”] |
| 蜘蛛俠:無路可走 | https://www.imdb.com/title/tt10872600/?ref_=adv_li_i | ['Jon Watts'] | ['Zendaya', 'Benedict Cumberbatch', 'Tom Holland', 'Marisa Tomei'] |
| Dune | https://www.imdb.com/title/tt1160419/?ref_=adv_li_i | ['Denis Villeneuve'] | ['Timothée Chalamet', 'Rebecca Ferguson', 'Zendaya', 'Oscar Isaac'] |
| Shang-Chi and the Legend of the Ten Rings | https://www.imdb.com/title/tt9376612/?ref_=adv_li_i | ['Destin Daniel Cretton'] | ['Simu Liu', 'Awkwafina', 'Tony Chiu-Wai Leung', 'Ben Kingsley'] |
| James Bond 007: Keine Zeit zu sterben | https://www.imdb.com/title/tt2382320/?ref_=adv_li_i | ['Cary Joji Fukunaga'] | ['Daniel Craig', 'Ana de Armas', 'Rami Malek', 'Léa Seydoux'] |
| Eternals | https://www.imdb.com/title/tt9032400/?ref_=adv_li_i | ['趙克洛'] | ['杰瑪·陳'、'理查德·麥登'、'安吉麗娜·朱莉'、'薩爾瑪·海耶克'] |
| 毒液:讓大屠殺 | https://www.imdb.com/title/tt7097896/?ref_=adv_li_i | ['安迪瑟金斯'] | [“湯姆·哈迪”、“伍迪·哈里森”、“米歇爾·威廉姆斯”、“娜奧米·哈里斯”] |
uj5u.com熱心網友回復:
即使沒有列出導演,我可以看到在保留在 bs4 的同時將導演和明星分開的最簡單方法是使用它們之間的 href 差異。
導演的href標簽包含“dr_0”,這可能對所有標題都一樣(應該檢查這個),多導演的電影可能會遵循與明星相同的模式,并在諸如“dr_1”,“dr_2” ”,...
因此,要僅從 html 源中獲取導演和明星,您可以使用:
import re
# could do with a copy of the html source to test this,
# please provide a test html string of the element if this doesn't work first time
def get_directors(text_muted) -> list:
# find all 'a' tags in that small element, if the href contains "dr_%d" then include the name in the returned list. return empty list if no directors.
names = text_muted.find_all("a")
return [element.string for element in names if re.search("dr_[0-9]", element.get("href", ""))]
def get_stars(text_muted) -> list:
# find all 'a' tags in that small element, if the href contains "st_%d" then include the name in the returned list. return empty list if no stars.
names = text_muted.find_all("a")
return [element.string for element in names if re.search("st_[0-9]", element.get("href", ""))]
這應該足夠安全,但是如果 href 不像它們看起來那樣可預測,那么您可以轉儲元素字串并將其拆分為模式“Director:”和“Stars:”。
順便說一句,我傾向于在 html-scraping 時使用手動字串搜索/正則運算式,因為只需多花一點力氣就可以正確拆分標簽,而 bs4 的速度提高了大約 100-200 倍,因此值得考慮。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/371479.html