作者
王孝威,FinOps 認證從業者,騰訊云容器服務產品經理,熱衷于為客戶提供高效的 Kubernetes 使用方式,為客戶極致降本增效服務,
余宇飛,FinOps 認證從業者,騰訊云專家工程師,從事云原生可觀測性、資源管理、降本增效產品的開發,
資源利用率為何都如此之低?
雖然 Kubernetes 可以有效的提升業務編排能力和資源利用率,但如果沒有額外的能力支撐,提升的能力十分有限,根據 TKE 團隊之前統計的資料: Kubernetes 降本增效標準指南| 容器化計算資源利用率現象剖析,如下圖所示:TKE 節點的資源平均利用率在 14% 左右,
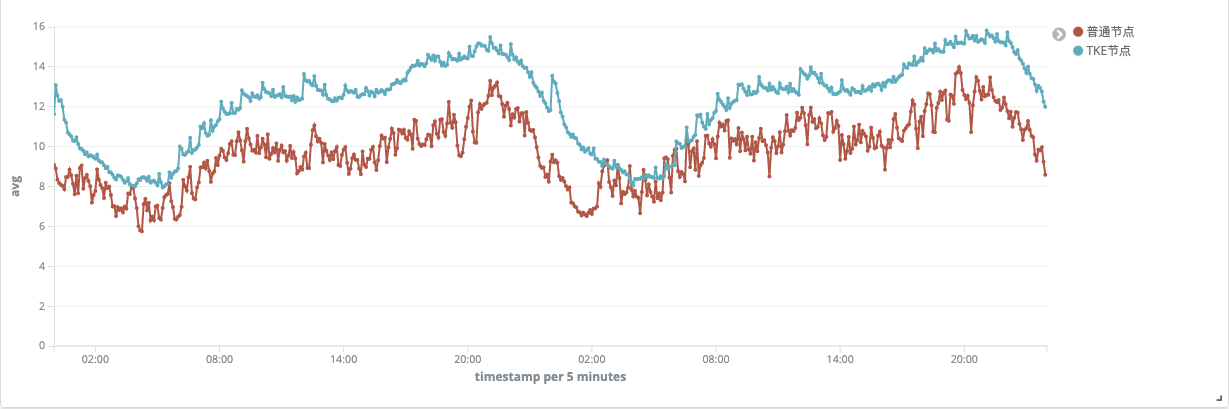
為什么 Kubernetes 集群的資源利用率依舊不高?
這里一個很重要的原因是因為 Kubernetes 的資源調度邏輯,在創建 Kubernetes 作業負載的時候,通常需要為作業負載配置合適的資源 Request 和 Limit,表示對資源的占用和限制,其中對利用率影響最大的是 Request,
為防止自己的作業負載所用的資源被別的作業負載所占用,或者是為了應對高峰流量時的資源消耗訴求,用戶一般都習慣將 Request 設定得較大,這樣 Request 和實際使用之間的差值,就造成了浪費,而且這個差值的資源,是不能被其它作業負載所使用的,
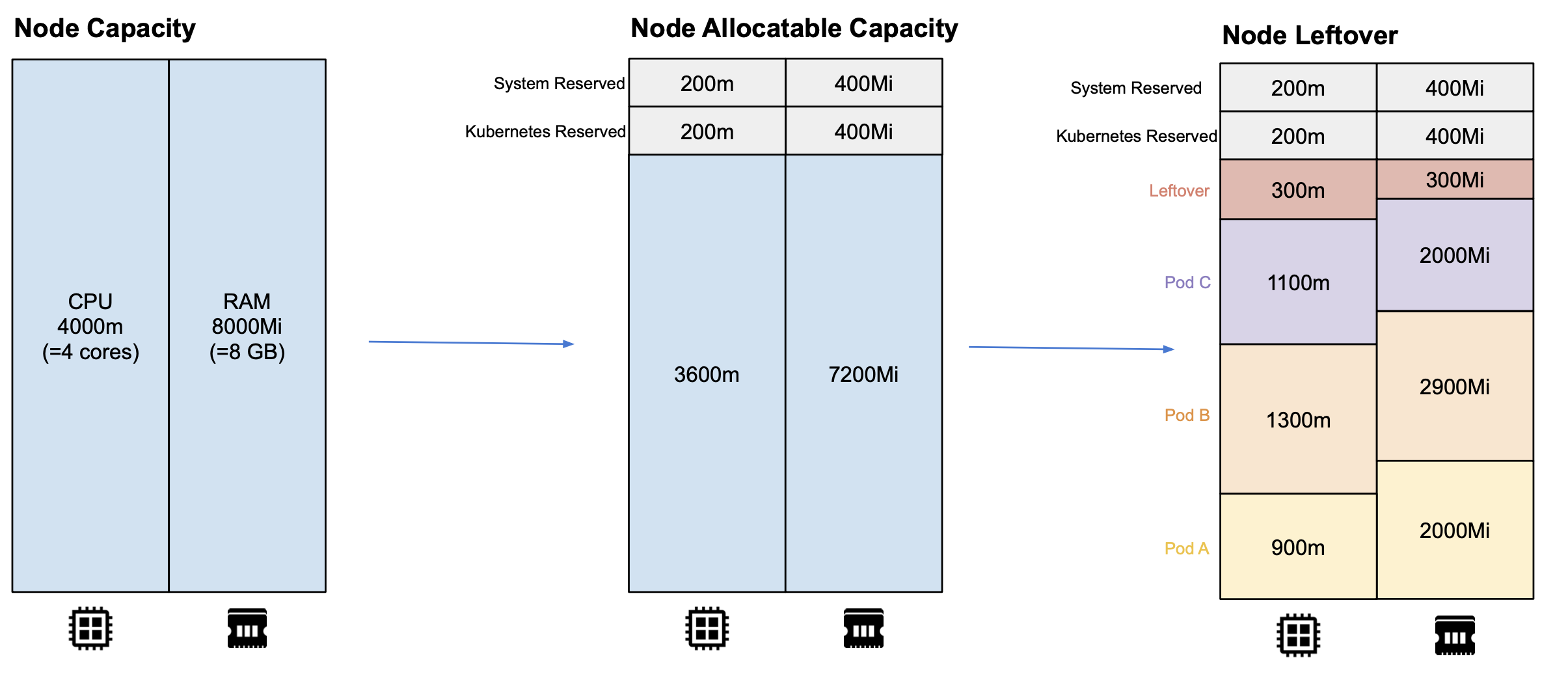
Request 數值不合理的過大,是造成 Kubernetes 集群資源利用率低一個很普遍的現象,另外,每個節點的資源很難被充分分配,如下圖所示,節點普遍會存在一些資源的碎片(Leftover),這些都是導致集群整理資源利用率不高的原因,
資源實際利用率到底有多低?
如何設定更合理的資源 Request,首先需要分析業務對資源的消耗情況,在騰訊云原生 Kubernetes 降本增效標準指南| 資源利用率提升工具大全資源常見浪費場景部分,有對單一的作業負載進行分析,作業負載設定的 Request 中至少有一半的資源沒有被使用,而且這部分資源不能被其他的作業負載使用,浪費現象嚴重, 這時把視角上升到集群維度,下圖是某一 TKE 集群的 CPU 分配率和使用率,
分配率是用所有容器對 CPU 的 Request 之和除以集群所有節點的 CPU 數量,使用率是所有容器對 CPU 的 Usage 之和除以集群所有節點的 CPU 數量:
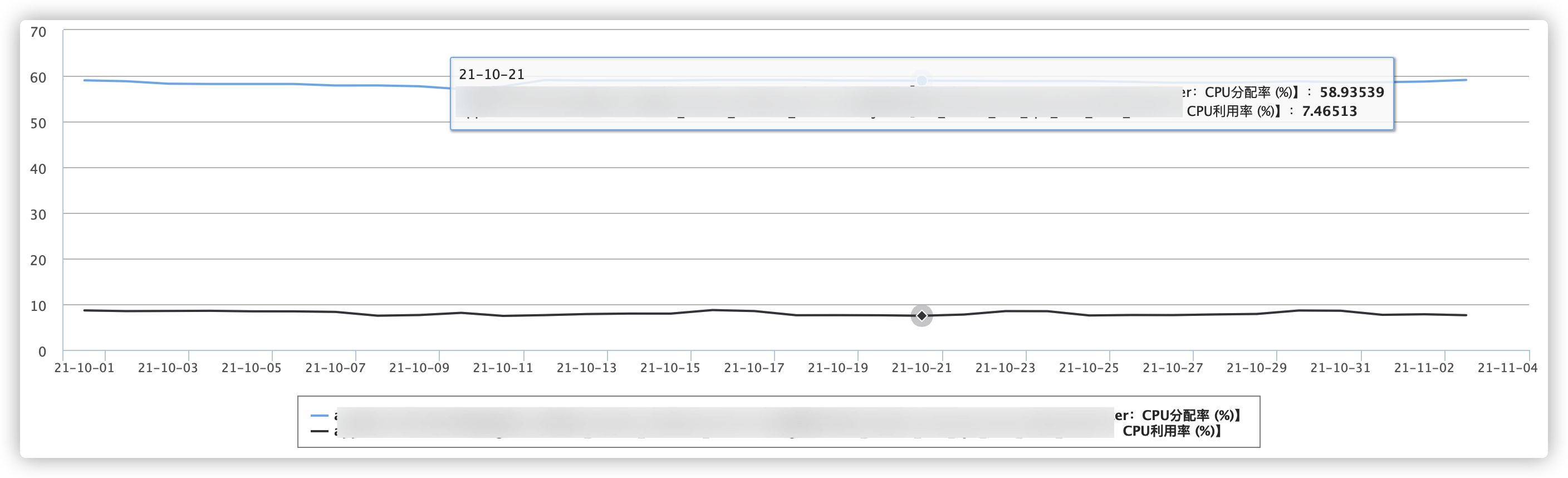
可見集群整體的 CPU 分配率在60%左右,但 CPU 實際的利用率最高不超過 10%,可以理解成用戶在云上花了一百元,實際上 90多元都被浪費掉了,
如何設定 Request?
提升資源利用率有很多種方法,詳見 Kubernetes 降本增效標準指南| 資源利用率提升工具大全,本文主要探討 Request 的設定,
既然設定了 Request 導致資源利用率如此之低,那是不是干脆不要設定 Request了,然后直接把集群的規模縮減到原來的十分之一,就可以解決上圖中的問題?這確實看似是一種簡單高效的方法,但存在幾個較為嚴重的問題:
- Kubernetes 會自動配置 Pod 的服務質量 QoS,對于沒有設定 Request 數值的 Pod,當資源比較緊張時,比較容易被驅逐,業務穩定性受到影響,
- 集群的整理資源實際上并不是一個完整的整體,集群是由很多節點構成的,實際的 CPU 和記憶體的資源都是節點的屬性,每個節點的容量大小有上限,例如64核 CPU,對于比較大的業務來說,可能需要一個數千核乃至數萬核的集群,這樣集群里的節點數量就會變多,節點數量越多,每個節點的碎片資源越多,碎片資源都無法有效被利用,
- 業務本身可能會有較大波動,例如地鐵系統白天繁忙、夜晚空閑,設定固定的 Request 數值必須按照峰值考慮,此時浪費現象依舊突出,
可以看出,Request 的設定對于運維開發來說一直是個很大難題,Request 設定過小容易導致業務運行時性能受到影響,設定過大勢必造成浪費,
Request 智能推薦
是否存在一個有效的工具,能基于業務本身的特性自動推薦甚至設定 Request 數值?
這樣無疑對開發運維來說極大的減輕了負擔,為解決這樣的問題,TKE 成本大師推出了 Request 智能推薦的工具,用戶可以通過標準 Kubernetes API(例如:/apis/recommendation.tke.io/v1beta1/namespaces/kube-system/daemonsets/kube-proxy)訪問相應的推薦值,
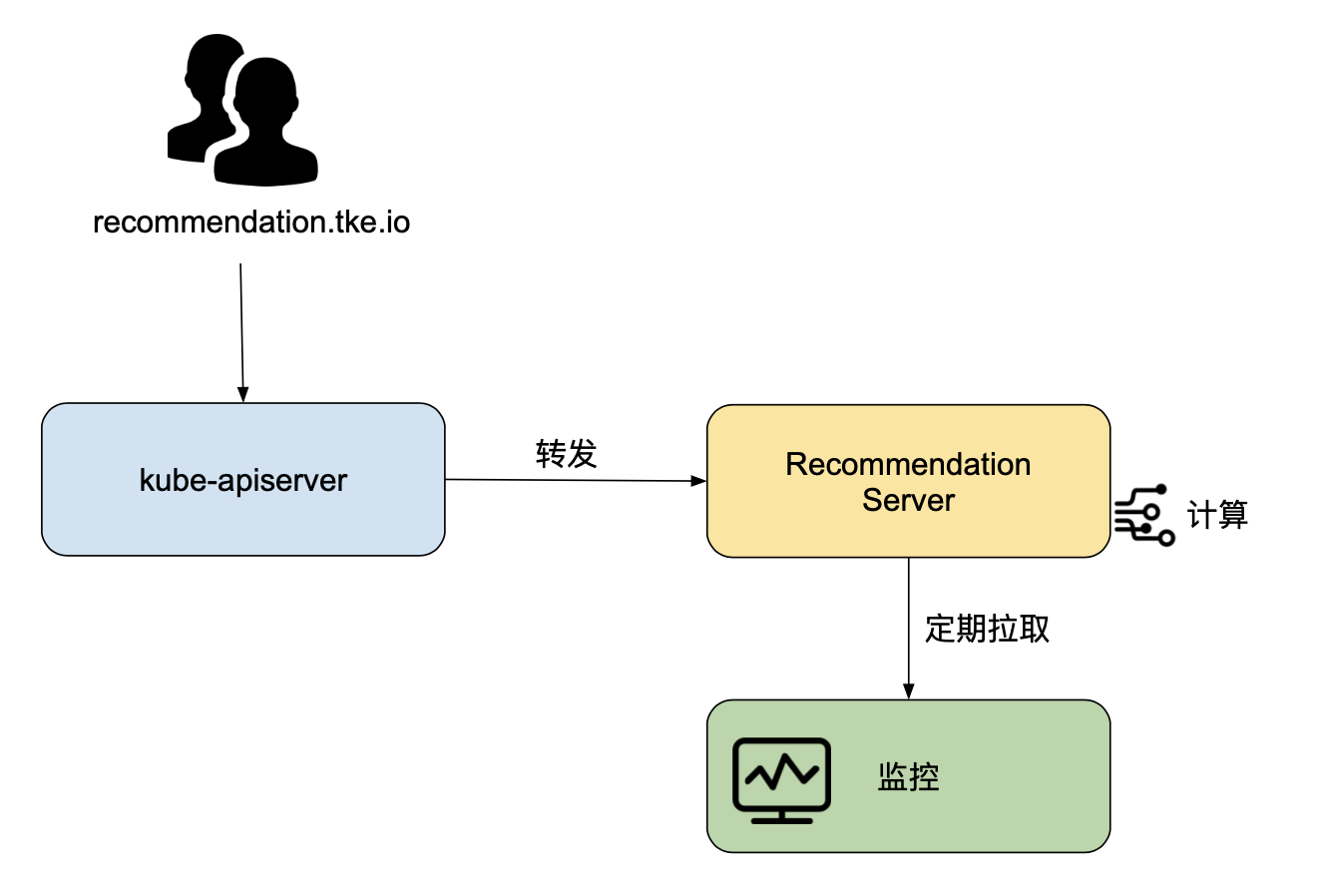
該功能啟動后,Request 智能推薦的相關組件會從騰訊云監控(未來支持 Prometheus,InfluxDB,或第三方云廠商)拉取集群中所有 Deployment、DaemonSet、StatefulSet 在過去一段時間存在過的容器的 CPU 和 記憶體的監控指標,計算相應的 P99 值,再乘以一個安全系數(例如:1.15),當作推薦的 Request,
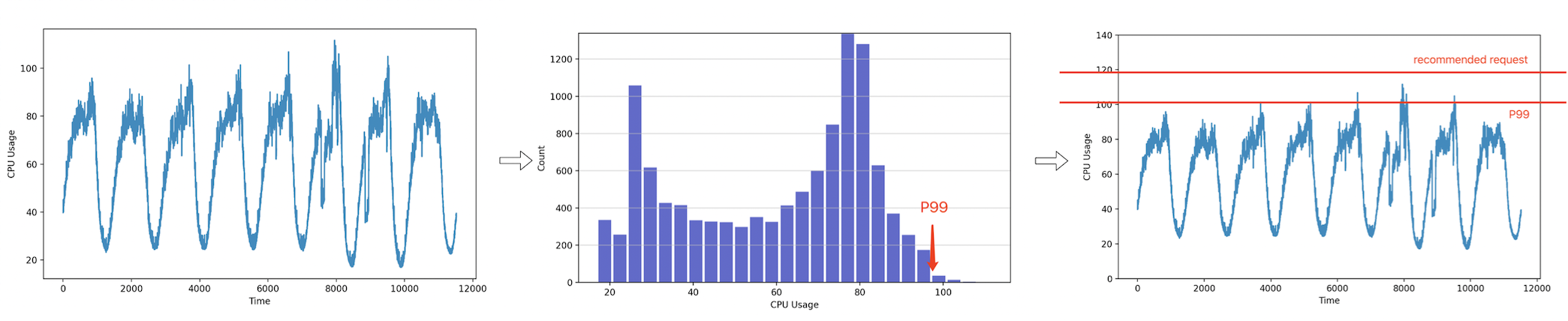
關于 Limit,Request 智能推薦功能推薦的 Limit ,以初始 Request 智能推薦功能設定的 Request 與 Limit 之比計算,例如初始設定的 CPU 的 Request 數值為 1000m,Limit 為 2000m,Request 與 Limit 之比為 1:2,若新推薦的 CPU 的 Request 數值為 500m,則會推薦 Limit 為 1000m,
更多關于 Request 智能推薦的使用請參考:Request 智能推薦產品檔案,
Request 推薦參考應用的歷史資源消耗峰值,給出一個相對「合理」并且「安全」的資源請求值,可以很大程度上緩解由于業務 Request 設定不合理導致的資源浪費或者業務不穩定,
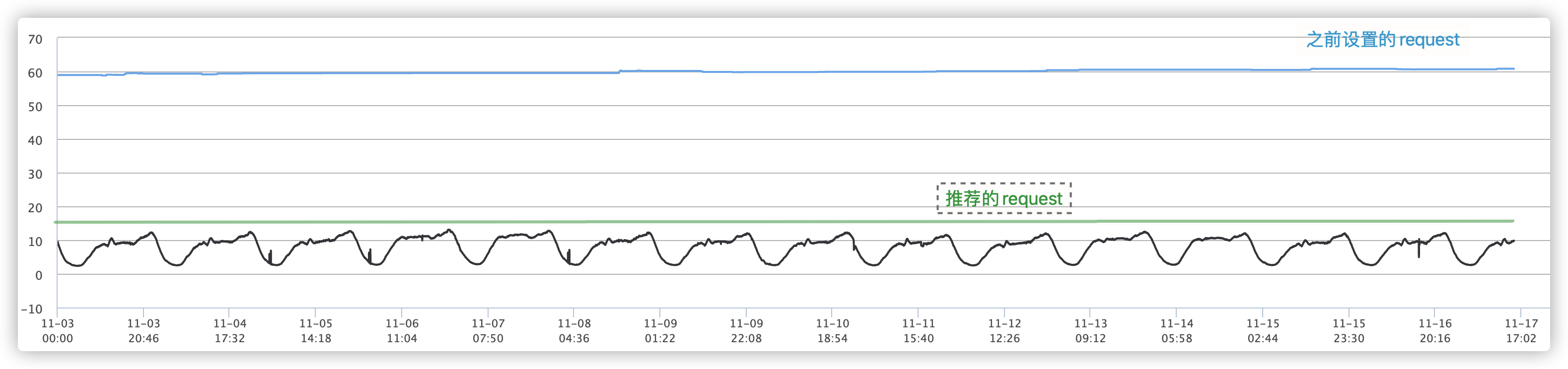
例如在下面的集群中應用 Request 推薦,業務資源使用量在 10 核左右,但手工配置的 Request 是 60 核,實際上 Request 設定在 17 核就足夠了,利用率從之前的 16.7%(=10/60) 左右 提升到 58.8%(=10/17),提升了 252%(=(58.8-16.7)/16.7),CPU 節省了 71.7%(=(60-17)/60),
AHPA
當然 ,Request 智能推薦不是銀彈,因為應用的資源消耗并不是一成不變的,大量的應用都存在潮汐現象,業務高峰和低谷所需要的資源存在著幾倍甚至幾十倍的差距,以高峰期資源需求為準設定的 Request,使得業務在空閑時段占有大量并不使用的資源,導致應用的平均資源利用率依然不高,此時,想要做進一步優化,就需要借助彈性伸縮的手段,
現階段,HPA 是 Kubernetes 領域最常用的彈性工具,雖然 HPA 可以一定程度上解決周期性業務流量資源使用彈性的問題,但是 HPA 是有滯后性的,具體表現在:通常 HPA 需要先定義監控的指標,例如 CPU 利用率 60%,然后相關的監控組件監控到負載壓力變大,觸達了這個使用率的閾值,HPA 才會擴縮容副本數,
通過對大量運行在騰訊云上的內部和外部用戶的實際應用的觀察,我們發現許多業務的資源使用在時間序列上是具有周期性的,特別是對于那些直接或間接為“人”服務的業務,這種周期是由人們日常活動的規律性決定的,例如:
- 人們習慣于中午和晚上點外賣
- 早上和晚上是交通高峰期
- 即使對于沒有明顯模式的服務,如搜索,夜間的請求量也遠低于白天
對于與此類相關的應用程式,從過去幾天的歷史資料中推斷第二天的指標,或從上周一的資料推斷下周一的訪問流量是一個自然的想法,通過對未來的指標預測,可以更好地管理應用程式實體,穩定系統,同時降低成本,
CRANE 是 TKE 成本大師的技術底座,專注于通過多種技術,優化資源利用,進而降低用戶的云上成本, CRANE 中的 Predictor 模塊可以自動識別出 Kubernetes 集群中應用的各種監控指標(例如 CPU 負載、記憶體占用、請求 QPS 等)的周期性,并給出未來一段時間的預測序列,在此基礎上,我們開發了 AHPA(advanced-horizontal-pod-autoscaler),它能夠識別適合水平自動縮放的應用程式,制定縮放計劃,并自動進行縮放操作,它利用了原生 HPA 機制,但它基于預測,并主動提前擴容應用程式,而不是被動地對監測指標做出反應,與原生 HPA 相比,AHPA 消除了手動配置和自動縮放滯后的問題,徹底解放運維, 主要有如下特點:
- 可靠性—-保證可伸縮性和可用性
- 回應能力——擴展快,快速應對高負載
- 資源效能——降低成本
下圖是該專案的實際運行效果:
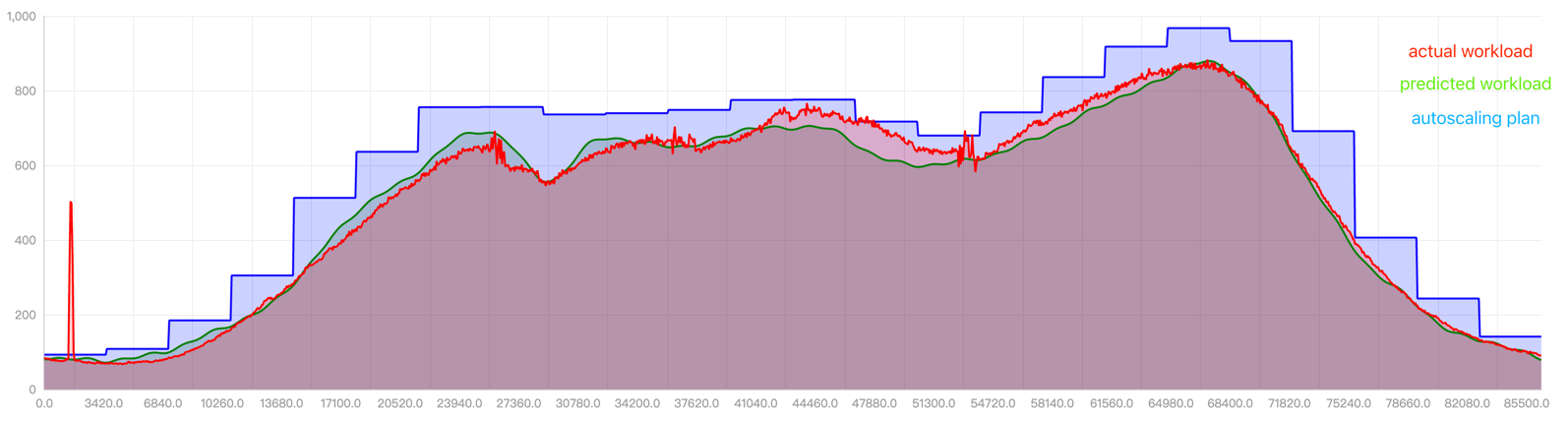
- 紅線是作業負載的實際資源使用量
- 綠線是預測該作業負載的資源使用量
- 藍線是給出的彈性推薦的資源使用量
CRANE 和 AHPA 即將開源,敬請期待,
更多關于云原生的成本優化原理和實際案例可參考《降本之源-云原生成本管理白皮書》,是騰訊基于內外云原生成本管理最佳實踐,并結合行業優秀案例,提出的一套體系化的云原生成本優化方法論和最佳實踐路徑,旨在幫助企業改善用云成本,充分發揮云原生的效能和價值,

更多白皮書細節內容,在【騰訊云原生】公眾號回復“白皮書”下載了解,
關于我們
更多關于云原生的案例和知識,可關注同名【騰訊云原生】公眾號~
福利:
①公眾號后臺回復【手冊】,可獲得《騰訊云原生路線圖手冊》&《騰訊云原生最佳實踐》~
②公眾號后臺回復【系列】,可獲得《15個系列100+篇超實用云原生原創干貨合集》,包含Kubernetes 降本增效、K8s 性能優化實踐、最佳實踐等系列,
③公眾號后臺回復【白皮書】,可獲得《騰訊云容器安全白皮書》&《降本之源-云原生成本管理白皮書v1.0》
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/373805.html
標籤:其他
上一篇:如何利用 JuiceFS 的性能工具做檔案系統分析和調優
下一篇:學習云計算基礎總結