原論文名稱:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
論文下載地址:https://arxiv.org/abs/1412.7062
參考原始碼:https://github.com/TheLegendAli/DeepLab-Context
講解視頻: https://www.bilibili.com/video/BV1SU4y1N7Ao
文章目錄
- 語意分割任務中存在的問題
- DeepLabV1的優勢
- 網路搭建細節
- LargeFOV
- MSc(Multi-Scale)
這篇文章最早發表于2014年,是Google和UCLA等共同的杰作,也是一篇很經典的論文,DeepLab系列的第一篇論文,因為已經過了很久了,所以本博文只做部分簡單的記錄,
語意分割任務中存在的問題
在論文的引言部分(INTRODUCTION)首先拋出了兩個問題(針對語意分割任務): 信號下采樣導致解析度降低和空間“不敏感” 問題,
There are two technical hurdles in the application of DCNNs to image labeling tasks: signal downsampling, and spatial ‘insensitivity’ (invariance).
對于第一個問題信號下采樣,作者說主要是采用Maxpooling導致的,為了解決這個問題作者引入了'atrous'(with holes) algorithm(空洞卷積 / 膨脹卷積 / 擴張卷積),如果不了解的可以參考我在bilibili上錄的講解視頻,
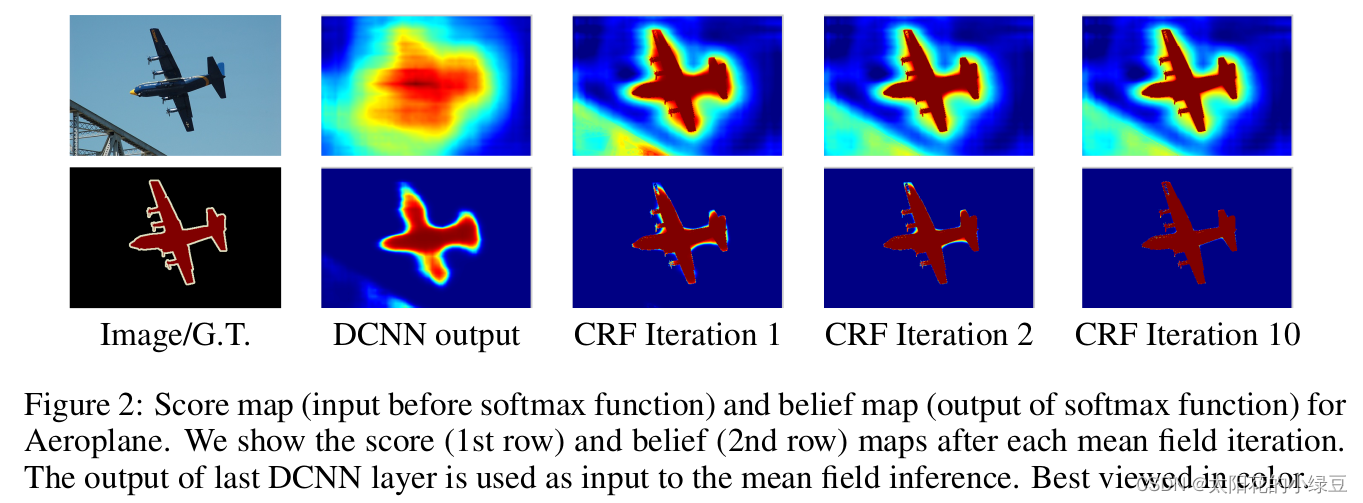
對于第二個問題空間“不敏感”,作者說分類器自身的問題(分類器本來就具備一定空間不變性),我個人認為其實還是Maxpooling導致的,為了解決這個問題作者采用了fully-connected CRF(Conditional Random Field)方法,這個方法只在DeepLabV1-V2中使用到了,從V3之后就不去使用了,而且這個方法挺耗時的,
DeepLabV1的優勢
相比之前的一些網路,本文提出的網路具有以下優勢:
- 速度更快,論文中說是因為采用了膨脹卷積的原因,但fully-connected CRF很耗時
- 準確率更高,相比之前最好的網路提升了7.2個點
- 模型很簡單,主要由DCNN和CRF聯級構成
網路搭建細節
LargeFOV
首先網路的backbone是當時比較火的VGG-16,并且和FCN網路一樣將全連接層的權重轉成了卷積層的權重,構成全卷積網路,然后關于膨脹卷積的使用,論文中是這么說的:
We skip subsampling after the last two max-pooling layers in the network of Simonyan & Zisserman (2014) and modify the convolutional filters in the layers that follow them by introducing zeros to increase their length (2×in the last three convolutional layers and 4× in the first fully connected layer).
感覺文中的skip subsampling說的有點模糊(可能是自己英語水平太菜)什么叫做跳過下采樣,既然看不懂論文的表述,就去看看代碼,根據代碼我繪制了如下所示的網路結構(DeepLab-LargeFOV),

通過分析發現雖然backbone是VGG-16但所使用Maxpool略有不同,VGG論文中是kernel=2,stride=2,但在DeepLabV1中是kernel=3,stride=2,padding=1,接著就是最后兩個Maxpool層的stride全部設定成1了(這樣下采樣的倍率就從32變成了8),最后三個3x3的卷積層采用了膨脹卷積,膨脹系數r=2,然后關于將全連接層卷積化程序中,對于第一個全連接層(FC1)在FCN網路中是直接轉換成卷積核大小7x7,卷積核個數為4096的卷積層,但在DeepLabV1中作者說是對引數進行了下采樣最終得到的是卷積核大小3x3,卷積核個數為1024的卷積層(這樣不僅可以減少引數還可以減少計算量,詳情可以看下論文中的Table2),對于第二個全連接層(FC2)卷積核個數也由4096采樣成1024,
After converting the network to a fully convolutional one, the first fully connected layer has 4,096 filters of large 7 × 7 spatial size and becomes the computational bottleneck in our dense score map computation. We have addressed this practical problem by spatially subsampling (by simple decimation) the first FC layer to 4×4 (or 3×3) spatial size.
將FC1卷積化后,還設定了膨脹系數,論文3.1中說的是r=4但在Experimental Evaluation中Large of View章節里設定的是r=12對應LargeFOV,對于FC2卷積化后就是卷積核1x1,卷積核個數為1024的卷積層,接著再通過一個卷積核1x1,卷積核個數為num_classes(包含背景)的卷積層,最后通過8倍上采樣還原回原圖大小,
下表是關于是否使用LargeFOV(Large of View)的對比,
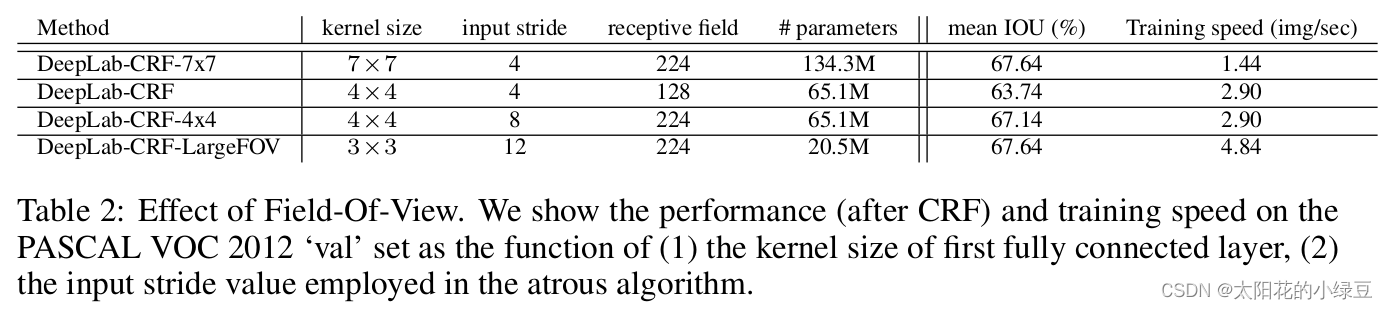
- 第一行
DeepLab-CRF-7x7就是直接將FC1按照FCN論文中的方法轉換成7x7大小的卷積層,并且膨脹因子r=4(receptive field=224), - 第二行
DeepLab-CRF是將7x7下采樣到4x4大小的卷積層,同樣膨脹因子r=4(receptive field=128),可以看到引數減半,訓練速度翻倍,但mean IOU下降了約4個點, - 第三行
DeepLab-CRF-4x4,是在DeepLab-CRF的基礎上把膨脹因子r改成了8(receptive field=224),mean IOU又提升了回去了, - 第四行
DeepLab-CRF-LargeFOV,是將7x7下采樣到3x3大小的卷積層,膨脹因子r=12(receptive field=224),相比DeepLab-CRF-7x7,引數減少了6倍,訓練速度提升了3倍多,mean IOU不變,
MSc(Multi-Scale)
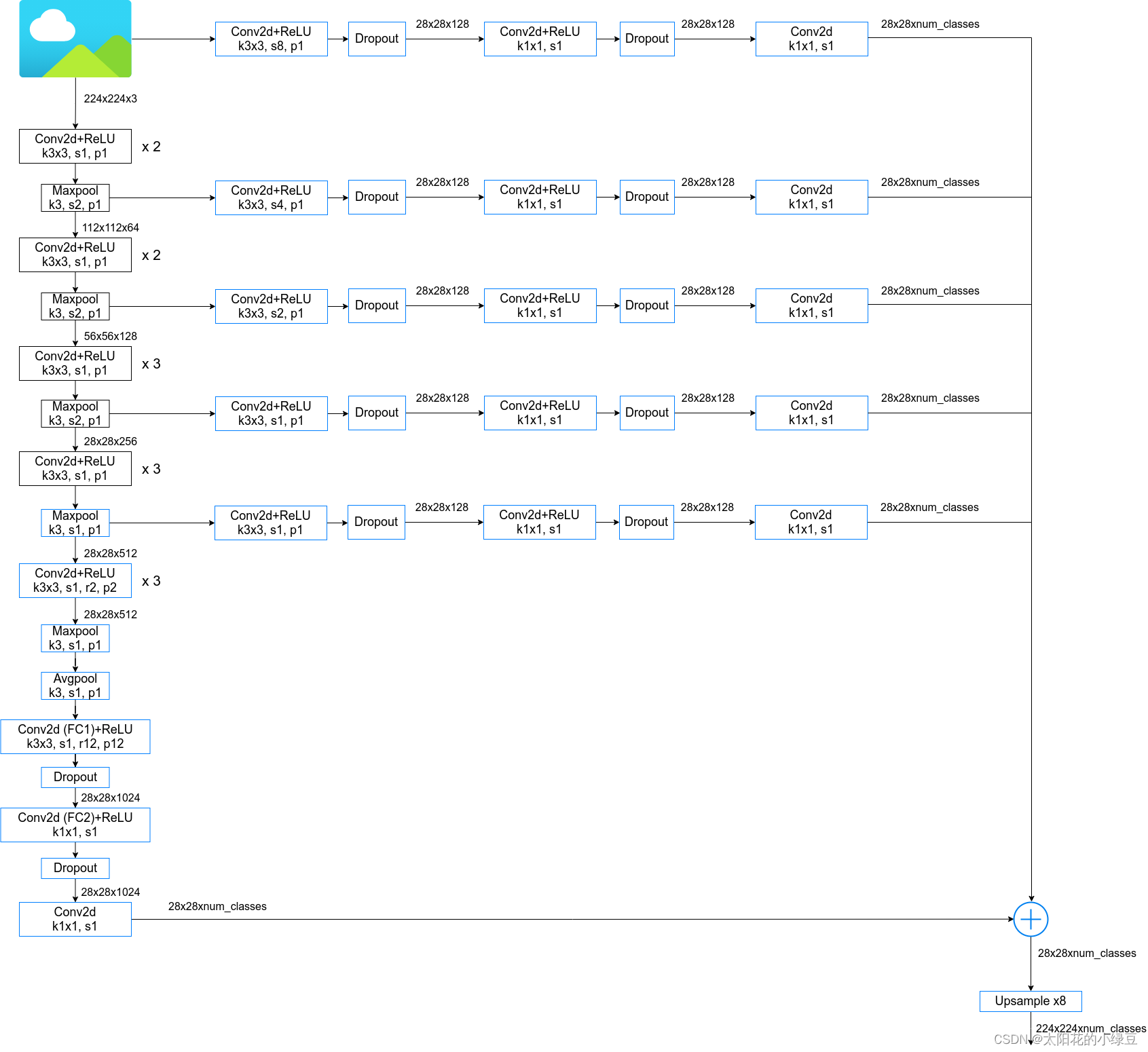
其實在論文的4.3中還提到了Multi-Scale Prediction,即融合多個特征層的輸出,關于MSc(Multi-Scale)的結構論文中是這么說的:
Specifically, we attach to the input image and the output of each of the first four max pooling layers a
two-layer MLP (first layer: 128 3x3 convolutional filters, second layer: 128 1x1 convolutional filters) whose feature map is concatenated to the main network’s last layer feature map. The aggregate feature map fed into the softmax layer is thus enhanced by 5 * 128 = 640 channels.
即,除了使用之前主分支上輸出外,還融合了來自原圖尺度以及前四個Maxpool層的輸出,更詳細的結構參考下圖,論文中說使用MSc大概能提升1.5個點,使用fully-connected CRF大概能提升4個點,但在原始碼中作者建議使用的是不帶MSc的版本,以及看github上的一些開源實作都沒有使用MSc,我個人猜測是因為這里的MSc不僅費時而且很吃顯存,根據參考如下代碼繪制了DeepLab-MSc-LargeFOV結構,
https://www.cs.jhu.edu/~alanlab/ccvl/DeepLab-MSc-LargeFOV/train.prototxt
下表是在PASCAL VOC2012 test資料集上的一個消融實驗:

關于fully-connected CRF,說實話不太懂,這里就不講了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/374545.html
標籤:AI