引言
今天來好好地捋一捋交叉熵損失(Cross Entropy Loss),
從資訊熵入手,再到極大似然估計,然后引入KL散度,最后來看KL散度與交叉熵的關系,
雖然文章有點長,但相信看完本文,你一定會對交叉熵損失有更高一層的領悟,
資訊熵
資訊的價值在于消除事件的不確定性,那事件的不確定性要怎么度量呢?答案就是資訊熵(information entropy),
比如你告訴別人你中了500萬彩票,別人會大吃一驚,因為他被消除了大量的不確定性,但如果你告訴別人你沒中彩票,別人基本熵沒有反應,因為他估計你這小子十有八九不會中彩票,相當于你幾乎沒有消除他對你沒有中彩票這件事的不確定性,或者說你傳達的資訊量太少,我們知道概率只能在0到1之間,也就是說,最好在概率為1的時候,資訊量為0,且概率越小,資訊量越大,后來人們發現,對數函式很符合這樣的規律,某個事件的資訊量與概率的關系是 i = log ? ( 1 p ) i = \log(\frac{1}{p}) i=log(p1?),這里的對數是以2為底的, p p p是事件發生的概率,
上面最后這個式子是怎么來的呢?以拋硬幣游戲為例,如果有一枚理想的硬幣,其出現正面和反面的概率相等,假設我們相隔很遠,只能通過電位信號(0或1)進行交流,如何把這個硬幣的結果告訴我呢,顯然,此時只需要發送一個信號就可以,用1表示正面,用0表示反面,資訊的價值在于消除事件的不確定性,傳遞一枚硬幣結果的資訊,幫我們消除了它是哪一個面的不確定性,
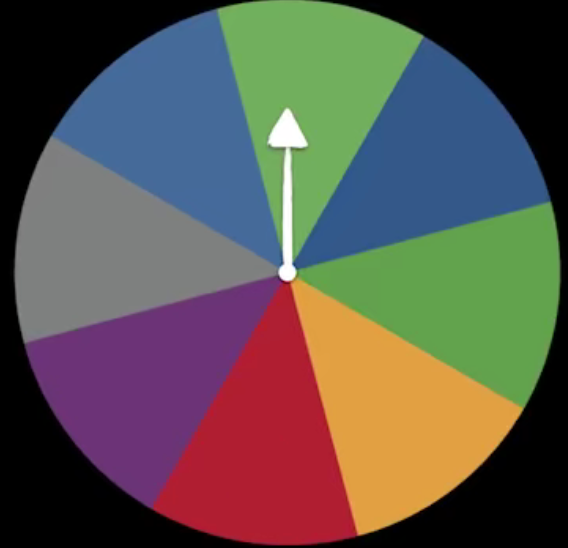
我們再來看一個轉盤游戲,這個轉盤被均等地分為8個區域,如果我們要把轉盤的結果發送出去,那么需要多少個信號呢?答案是3個信號,
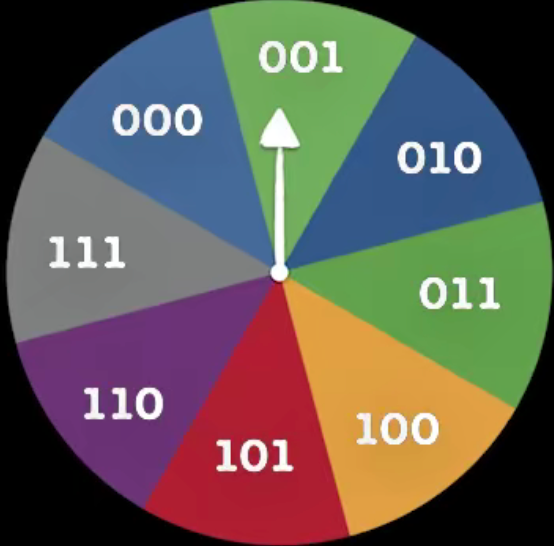
在這兩個例子中,我們發現一件事情,把一個游戲系統中所有可能出現的等概率事件數量取以2為底的對數,就是我們要傳遞事件結果所需要的信號數量,比如在拋硬幣游戲中是 log ? 2 ( 2 ) = 1 \log_2(2)=1 log2?(2)=1,在轉盤游戲中是 log ? 2 ( 8 ) = 3 \log_2(8)=3 log2?(8)=3??,這個數量就是資訊量,
即 資訊量 = log ? ( N ) \text{資訊量}=\log(N) 資訊量=log(N),這里的 N N N是等可能事件數量,
可以把這種度量不確定性的資訊量稱為資訊熵,但嚴格來說這并不是香農所說的資訊熵,這只是資訊熵的一個特例,即所有的事件是等可能的,我們遇到的更多情況是事件發生的可能性不一樣的系統, 比如現實生活中就無法制作出來正反面概率都是50%的硬幣,
實際上,我們總是可以把一個事件的概率值轉換為一個等可能事件系統中發生某個事件的概率,舉例來說,我們總是可以把一個概率值轉換為“在N個球中隨機摸一個球”這個等可能事件系統中摸出某個球的概率,
假設中彩票大獎的概率很低,只有兩千萬分之一,我們可以把這個概率值轉換為在兩千萬個球中摸出中獎球的概率,在這個摸球系統中,就有兩千萬個等可能事件,所以只需要用1除以概率值就可以想象出等可能事件系統中事件等數量,即 N = 1 p N=\frac{1}{p} N=p1??,
假設我們有一個動了手腳的不均勻硬幣,它正面朝上的概率是0.8,反面朝上的概率是0.2,

如上圖,反面朝上0.2的概率可以想象有5個球的摸球系統中摸出某個球的概率,

而正面朝上0.8的概率可以想象成在有1.25個球的系統中摸出某個球的概率,我們通過想象把一個非等概率事件的系統拆成了兩個等概率事件的系統,
而面對等概率事件系統,我們就可以很容易地計算它們的資訊量,再把這兩個想象出來的摸球系統的資訊量加起來,就是這個不均勻硬幣的資訊量: log ? 5 + log ? 1.25 \log 5 + \log 1.25 log5+log1.25,由于這兩個我們想象出來的等概率系統本身出現的概率也不一樣,因此我們需要分別乘上它們出現的概率,得 0.2 ? log ? 5 + 0.8 ? log ? 1.25 0.2 \cdot \log 5 + 0.8 \cdot \log 1.25 0.2?log5+0.8?log1.25,
如果我們用符號去抽象這些具體的值,就是
p
1
?
log
?
1
p
1
+
p
2
?
log
?
1
p
2
(1)
p_1 \cdot \log \frac{1}{p_1} + p_2 \cdot \log \frac{1}{p_2} \tag{1}
p1??logp1?1?+p2??logp2?1?(1)
對于有更多事件的一般情況,我們可以這么表示:
∑
i
p
i
log
?
1
p
i
(2)
\sum_i p_i \log \frac{1}{p_i} \tag{2}
i∑?pi?logpi?1?(2)
我們整理下這個式子
∑
i
p
i
log
?
1
p
i
=
∑
i
(
p
i
?
(
log
?
1
?
log
?
p
i
)
)
=
∑
i
?
p
i
log
?
p
i
=
?
∑
i
p
i
log
?
p
i
(3)
\begin{aligned} \sum_i p_i \log \frac{1}{p_i} &= \sum_i (p_i \cdot (\log1 - \log p_i)) \\ &= \sum_i - p_i \log p_i \\ &= - \sum_i p_i \log p_i \end{aligned} \tag{3}
i∑?pi?logpi?1??=i∑?(pi??(log1?logpi?))=i∑??pi?logpi?=?i∑?pi?logpi??(3)
就得到了香農所提出的資訊熵公式 ? ∑ i p i log ? p i -\sum_i p_i \log p_i ?∑i?pi?logpi?
我們可以看出,資訊熵實際熵就是我們給每個概率值想象出來的某球系統的資訊量的平均值,或者說是資訊量的期望,
如果我們要比較兩個概率模型的距離,最簡單的辦法就是把它們的資訊熵都算出來,直接比較兩個結果就好了,但是問題是,在機器學習中,我們往往不知道訓練樣本的概率模型,此時呢,我們就需要用到相對熵,也稱為KL散度(KL Divergence),
但是在這之前,為了知識的完整性,我們需要了解極大似然估計的概念,
極大似然估計
極大似然估計里面有三個概念,極大、似然和估計,通俗來說,就是用已知的樣本結果資訊,去反推最有可能導致這些樣本結果出現的模型引數值,
反推說的是一種推理、估計,我們無法保證完全能從已知樣本去推出產生這些樣本的概率分布,只能說是一種估計,似然值說的是,真實樣本已經看到,假設有很多(概率)模型,每個模型產生這些真實樣本的可能性就叫似然值,極大似然估計就是選擇似然值最高的模型來估計真實(概率)模型,
還是以拋硬幣為例,我們記硬幣的正面為H(Head),反面為T(Tail),
假設我們不知道這個硬幣產生正反面的概率,但是我們可以做10次實驗,假設產生這樣一組結果:HHHHHHHTTT,即前7次是正面,后3次是反面,
假設有三個產生這組結果的模型(概率分布),
- 模型A產生正面的概率 p = 0.1 p=0.1 p=0.1,產生反面的概率就是 1 ? p = 0.9 1-p=0.9 1?p=0.9?
- 模型B產生正面的概率 p = 0.7 p=0.7 p=0.7,產生反面的概率是 1 ? p = 0.3 1-p=0.3 1?p=0.3
- 模型 C C C產生正面的概率 p = 0.8 p=0.8 p=0.8,產生反面的概率是 1 ? p = 0.2 1-p=0.2 1?p=0.2
計算某個概率模型產生這組結果的可能性是可以計算出來的,公式為:
P
(
C
1
,
C
2
,
?
?
,
C
10
∣
θ
)
=
∏
i
=
1
10
P
(
C
i
∣
θ
)
(4)
P(C_1,C_2,\cdots,C_{10}|\theta) = \prod_{i=1}^{10} P(C_i|\theta) \tag{4}
P(C1?,C2?,?,C10?∣θ)=i=1∏10?P(Ci?∣θ)(4)
其中
C
i
∈
{
0
,
1
}
C_i \in \{0,1\}
Ci?∈{0,1}是第
i
i
i次拋硬幣的結果,整個式子說的是由引數
θ
\theta
θ確定的模型同時發生
C
1
,
C
2
,
?
?
,
C
10
C_1,C_2,\cdots,C_{10}
C1?,C2?,?,C10?的概率,
同時發生就是連乘,
這樣的可能性就叫似然值,
因此我們只需要計算每個模型的似然值,然后選擇似然值最大的模型來估計真實模型,
模型 A A A的似然值: 0. 1 7 0. 9 3 ≈ 7.29 e ? 08 0.1^70.9^3 \approx 7.29e-08 0.170.93≈7.29e?08
模型 B B B的似然值: 0. 7 7 0. 3 3 ≈ 0.00222 0.7^70.3^3\approx 0.00222 0.770.33≈0.00222
模型 C C C的似然值: 0. 1 7 0. 9 3 ≈ 0.00168 0.1^70.9^3\approx 0.00168 0.170.93≈0.00168
挑出似然值最大的模型就叫最大似然估計法,
極大似然法
我們從極大似然估計的角度來看一下損失函式的選擇,
以上圖為例,把一些圖片,輸入到神經網路,神經網路會輸出這張圖片是貓的可能性,假設這些圖片是訓練資料,我們已經這些圖片是否是貓,
在拋硬幣中,我們通過 θ \theta θ來表示引數,在神經網路這里可以具體地用 W , b W,b W,b來表示,
即可以寫成:
P
(
x
1
,
x
2
,
x
3
,
?
?
,
x
n
∣
W
,
b
)
(5)
P(x_1,x_2,x_3,\cdots,x_n|W,b) \tag{5}
P(x1?,x2?,x3?,?,xn?∣W,b)(5)
n
n
n這些圖片的個數;
x
i
∈
{
0
,
1
}
x_i \in \{0,1\}
xi?∈{0,1}代表輸入的這張圖片是否為貓,
1
1
1代表是貓,
這樣我們也可以把上式改成連乘的形式:
P
(
x
1
,
x
2
,
x
3
,
?
?
,
x
n
∣
W
,
b
)
=
∏
i
=
1
n
P
(
x
i
∣
W
,
b
)
(6)
P(x_1,x_2,x_3,\cdots,x_n|W,b) =\prod_{i=1}^n P(x_i|W,b) \tag{6}
P(x1?,x2?,x3?,?,xn?∣W,b)=i=1∏n?P(xi?∣W,b)(6)
我們就可以得到基于這些圖片的模型的似然值,我們要找到使得這個似然值最大的
W
,
b
W,b
W,b,
但是
W
,
b
W,b
W,b?是一個確定的值,而我們知道神經網路可以看成是由
W
,
b
W,b
W,b這組引數確定的一個函式,該函式的輸出結果
y
i
y_i
yi?表示輸入圖片
x
i
x_i
xi?是貓的可能性有多大,即
y
i
=
N
N
W
,
b
(
x
i
)
y_i = NN_{W,b}(x_i)
yi?=NNW,b?(xi?)??,這里我們就可以用可能性
y
i
y_i
yi?來替代上面的引數
W
,
b
W,b
W,b:
P
(
x
1
,
x
2
,
x
3
,
?
?
,
x
n
∣
W
,
b
)
=
∏
i
=
1
n
P
(
x
i
∣
y
i
)
(7)
P(x_1,x_2,x_3,\cdots,x_n|W,b) =\prod_{i=1}^n P(x_i|y_i) \tag{7}
P(x1?,x2?,x3?,?,xn?∣W,b)=i=1∏n?P(xi?∣yi?)(7)
這樣輸入不同貓的圖片
x
i
x_i
xi?,我們可以得到不同的概率值
y
i
y_i
yi?,
這個式子我們要如何展開呢,我們這個連乘時的寫法與 x i x_i xi?的取值有關,當 x i = 1 x_i=1 xi?=1時,輸出的應該是判斷為貓的概率,取 y i y_i yi?;當 x i = 0 x_i=0 xi?=0時,輸出的應該是判斷不是貓的概率,取 1 ? y i 1-y_i 1?yi?,
好在還是有解法的,這個式子可以通過伯努利分布展開的,因為 x i ∈ { 0 , 1 } x_i \in \{0,1\} xi?∈{0,1}兩種情況,同時 y i y_i yi?又是一個概率,

和拋硬幣的例子類似,當 x = 1 x=1 x=1時,我們用硬幣是正面的概率 p p p去乘;當 x = 0 x=0 x=0是,我們用硬幣是反面的概率 1 ? p 1-p 1?p去乘,
我們就可以通過伯努利分布的這個式子來展開式
(
7
)
(7)
(7),得:
P
(
x
1
,
x
2
,
x
3
,
?
?
,
x
n
∣
W
,
b
)
=
∏
i
=
1
n
y
i
x
i
(
1
?
y
i
)
1
?
x
i
(8)
P(x_1,x_2,x_3,\cdots,x_n|W,b) = \prod_{i=1}^n y_i^{x_i}(1-y_i)^{1-x_i} \tag{8}
P(x1?,x2?,x3?,?,xn?∣W,b)=i=1∏n?yixi??(1?yi?)1?xi?(8)
我們通過在等式右邊取對數,把連乘變成連加,因為取對數不改變單調性的,
log
?
(
∏
i
=
1
n
y
i
x
i
(
1
?
y
i
)
1
?
x
i
)
=
∑
i
=
1
n
log
?
(
y
i
x
i
(
1
?
y
i
)
1
?
x
i
)
=
∑
i
=
1
n
(
x
i
?
log
?
y
i
+
(
1
?
x
i
)
?
log
?
(
1
?
y
i
)
)
(9)
\begin{aligned} \log \left( \prod_{i=1}^n y_i^{x_i}(1-y_i)^{1-x_i} \right )&= \sum_{i=1}^n \log \left(y_i^{x_i}(1-y_i)^{1-x_i} \right) \\ &= \sum_{i=1}^n \left(x_i \cdot \log y_i + (1-x_i)\cdot \log (1-y_i) \right) \\ \end{aligned} \tag{9}
log(i=1∏n?yixi??(1?yi?)1?xi?)?=i=1∑n?log(yixi??(1?yi?)1?xi?)=i=1∑n?(xi??logyi?+(1?xi?)?log(1?yi?))?(9)
我們要求極大似然值,是取的最大值,而損失函式是取最小值,我們把等式兩邊乘以一個負號,變成了求最小值,
min
?
?
∑
i
=
1
n
(
x
i
?
log
?
y
i
+
(
1
?
x
i
)
?
log
?
(
1
?
y
i
)
)
(10)
\min - \sum_{i=1}^n \left(x_i \cdot \log y_i + (1-x_i)\cdot \log (1-y_i) \right) \tag{10}
min?i=1∑n?(xi??logyi?+(1?xi?)?log(1?yi?))(10)
雖然這個式子看起來很像交叉熵,但實際上還是有很大不同的,主要的區別是它們的量綱不同,
這里面的對數是我們故意加上去的,并且負號也是為了湊成求最小值,
下面我們就來了解相對熵,
KL散度
KL散度,也被稱為相對熵,是用來衡量兩個分布的距離,設
P
P
P和
Q
Q
Q是兩個概率分布,則
P
P
P對
Q
Q
Q的相對熵為:
D
K
L
(
P
∣
∣
Q
)
=
∑
i
P
(
i
)
log
?
P
(
i
)
Q
(
i
)
(11)
D_{KL}(P||Q) = \sum_i P(i) \log \frac{P(i)}{Q(i)} \tag{11}
DKL?(P∣∣Q)=i∑?P(i)logQ(i)P(i)?(11)
這里
i
i
i代表分布中的所有類別,
性質
- 不具備對稱性,即 D ( P ∣ ∣ Q ) ≠ D ( Q ∣ ∣ P ) D(P||Q) \neq D(Q||P) D(P∣∣Q)?=D(Q∣∣P)
- 非負性,即 D ( P ∣ ∣ Q ) ≥ 0 D(P||Q) \geq 0 D(P∣∣Q)≥0
舉個例子,還是以拋硬幣為例,假設我們有一個公平的硬幣,即正反概率都是50%;我們還有一個有偏差的硬幣,其正面概率為 p p p,反面概率為 q q q,
我們要如何判斷這兩個分布的相似性呢?
可能不好回答,但是我們知道,如果 p = 0.55 p=0.55 p=0.55,它肯定比 p = 0.95 p=0.95 p=0.95要更相似,
我們可以從拋硬幣的結果來看,
? 假設公平硬幣的拋擲結果為:HHTHHTTHTHTH
假設 p = 0.55 p=0.55 p=0.55硬幣的拋擲結果為:HHTHHTTHHHTH
假設 p = 0.95 p=0.95 p=0.95硬幣的拋擲結果為:HHHHHHTHHHHH
我們可以簡單的計算不相等的結果個數,但是更嚴謹的做法是計算產生某個結果的似然值,
如果似然值很接近,那么說明這兩個概率分布很接近,
基于(公平硬幣拋出的)觀察結果,我們就可以計算公平硬幣的似然值和其他硬幣的似然值的比值:
P
(
觀察結果
∣
公平硬幣
)
P
(
觀察結果
∣
偏差硬幣
)
\frac{P(\text{觀察結果}|\text{公平硬幣})}{P(\text{觀察結果}|\text{偏差硬幣})}
P(觀察結果∣偏差硬幣)P(觀察結果∣公平硬幣)?
我們再舉一個例子,假設有一枚硬幣,其正面概率為
p
1
p_1
p1?,反面概率為
p
2
p_2
p2?;
假設我們拋擲這枚硬幣12次,產生的結果為:HHTHHTHHHTHT
我們可以很容易計算出這枚硬幣產生這個結果的概率: p 1 ? p 1 ? p 2 ? p 1 ? p 1 ? p 2 ? p 1 ? p 1 ? p 1 ? p 2 ? p 1 ? p 2 p_1\cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot p_1 \cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot \color{red}p_2 p1??p1??p2??p1??p1??p2??p1??p1??p1??p2??p1??p2?
我們再拿一枚硬幣,它產生正面的概率為 q 1 q_1 q1?,反面概率為 q 2 \color{red}q_2 q2?
那么這枚新的硬幣產生這個結果的概率為: q 1 ? q 1 ? q 2 ? q 1 ? q 1 ? q 2 ? q 1 ? q 1 ? q 1 ? q 2 ? q 1 ? q 2 q_1\cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot q_1 \cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot \color{red}q_2 q1??q1??q2??q1??q1??q2??q1??q1??q1??q2??q1??q2?
即基于觀察結果,有
P ( 觀察結果 ∣ 硬幣1 ) = p 1 N H p 2 N T P(\text{觀察結果}|\text{硬幣1}) = p_1^{N_H}\color{red}p_2^{N_T} P(觀察結果∣硬幣1)=p1NH??p2NT??
P ( 觀察結果 ∣ 硬幣2 ) = q 1 N H q 2 N T P(\text{觀察結果}|\text{硬幣2}) = q_1^{N_H}\color{red}q_2^{N_T} P(觀察結果∣硬幣2)=q1NH??q2NT??
其中
N
H
N_H
NH??表示觀察結果中為正面的次數,
N
T
N_T
NT??為反面的次數,我們計算它們的比值:
P
(
觀察結果
∣
真實硬幣
)
P
(
觀察結果
∣
硬幣2
)
=
p
1
N
H
p
2
N
T
q
1
N
H
q
2
N
T
(12)
\frac{P(\text{觀察結果}|\text{真實硬幣})}{P(\text{觀察結果}|\text{硬幣2})} = \frac{p_1^{N_H}\color{red}p_2^{N_T}}{q_1^{N_H}\color{red}q_2^{N_T}} \tag{12}
P(觀察結果∣硬幣2)P(觀察結果∣真實硬幣)?=q1NH??q2NT??p1NH??p2NT???(12)
這樣就能計算出來這兩個硬幣的相似性,
其實KL散度衡量的是類似的東西,怎么說?
我們把上式右邊取對數,并除以實驗總數
N
=
N
H
+
N
T
N=N_H+\color{red}N_T
N=NH?+NT?:
1
N
log
?
(
p
1
N
H
p
2
N
T
q
1
N
H
q
2
N
T
)
=
1
N
log
?
p
1
N
H
+
1
N
log
?
p
2
N
T
?
1
N
log
?
q
1
N
H
?
1
N
log
?
q
2
N
T
=
p
1
log
?
p
1
+
p
2
log
?
p
2
?
p
1
log
?
q
1
?
p
2
log
?
q
2
=
p
1
log
?
p
1
q
1
+
p
2
log
?
p
2
q
2
\begin{aligned} \frac{1}{N}\log \left( \frac{p_1^{N_H}\color{red}p_2^{N_T}}{q_1^{N_H}\color{red}q_2^{N_T}} \right) &= \frac{1}{N}\log p_1^{N_H} + \frac{1}{N}\log \color{red}p_2^{N_T} \color{black} - \frac{1}{N}\log q_1^{N_H} -\frac{1}{N}\log \color{red} q_2^{N_T} \\ &= p_1\log p_1 + p_2 \log \color{red}p_2 \color{black} - p_1 \log q_1 - \color{red}p_2 \color{black}\log \color{red}q_2 \\ &= p_1 \log \frac{p_1}{q_1} + \color{red}p_2 \color{black}\log \frac{\color{red}p_2}{\color{red}q_2} \end{aligned}
N1?log(q1NH??q2NT??p1NH??p2NT???)?=N1?logp1NH??+N1?logp2NT???N1?logq1NH???N1?logq2NT??=p1?logp1?+p2?logp2??p1?logq1??p2?logq2?=p1?logq1?p1??+p2?logq2?p2???
其中 N H N = p 1 ???? N T N = p 2 \frac{N_H}{N}=p_1 \,\,\,\, \frac{\color{red}N_T}{N}=\color{red}p_2 NNH??=p1?NNT??=p2?,這里 p p p是一個概率分布, q q q是另一個概率分布,該式子和KL散度的式子一模一樣,
即我們通過計算真實分布的似然值除以第二個分布的似然值,再取歸一化的對數,就得到了KL散度的運算式,
我們可以看到,KL散度是一種衡量兩個概率分布距離的方式,通過觀察第二個概率分布產生第一個概率分布樣本的可能性,
KL散度非常適用于深度學習的場景,因為深度學習模型基本上是關于為已知樣本的真實分布建模,
實際上,交叉熵損失(cross entroy loss)就等于KL損失,最小化交叉熵就是最小化兩個分布的距離,
我們先來看下交叉熵的定義,
交叉熵
交叉熵(Cross Entropy)主要衡量兩個概率分布之間的差異性,交叉熵可在神經網路中作為損失函式,有:
H
(
P
?
∣
P
)
=
?
∑
i
P
?
(
i
)
log
?
P
(
i
)
(13)
H(P^*|P)=- \sum_i P^*(i) \log P(i) \tag{13}
H(P?∣P)=?i∑?P?(i)logP(i)(13)
其中
P
?
P^*
P?表示真實分布;
P
P
P表示預測分布;
i
i
i表示分布中的所有類別,
KL散度和交叉熵
我們已經了解了KL散度和交叉熵,我們本小節來看它們之間的關系,
我們知道,交叉熵可以用來衡量預測分布和真實分布的差異(距離),我們觀察到的樣本都是由真實分布產生的,所以我們可以這樣描述KL散度:
D
K
L
(
P
?
∣
∣
P
)
=
D
K
L
(
P
?
(
y
∣
x
i
)
∣
∣
P
(
y
∣
x
i
;
θ
)
(14)
D_{KL}(P^*||P) =D_{KL}\left ( P^* (y|x_i) || P(y|x_i;\theta\right) \tag{14}
DKL?(P?∣∣P)=DKL?(P?(y∣xi?)∣∣P(y∣xi?;θ)(14)
其中
P
?
P^*
P?是真實分布,
P
P
P是我們的預測分布;
x
i
x_i
xi?是第
i
i
i個樣本,
y
y
y是其對應的標簽;
θ
\theta
θ是模型的引數,
D
K
L
(
P
?
∣
∣
P
)
=
∑
y
P
?
(
y
∣
x
i
)
log
?
P
?
(
y
∣
x
i
)
P
(
y
∣
x
i
;
θ
)
=
∑
y
P
?
(
y
∣
x
i
)
[
log
?
P
?
(
y
∣
x
i
)
?
log
?
P
(
y
∣
x
i
;
θ
)
]
=
∑
y
P
?
(
y
∣
x
i
)
log
?
P
?
(
y
∣
x
i
)
?
∑
y
P
?
(
y
∣
x
i
)
log
?
P
(
y
∣
x
i
;
θ
)
(15)
\begin{aligned} D_{KL}(P^*||P) &= \sum_y P^* (y|x_i) \log \frac{P^*(y|x_i)}{P(y|x_i;\theta)} \\ &=\sum_y P^* (y|x_i) \left [\log P^*(y|x_i) - \log P(y|x_i;\theta) \right] \\ &= \sum_y P^* (y|x_i)\log P^*(y|x_i) - \sum_y P^* (y|x_i) \log P(y|x_i;\theta) \\ \end{aligned} \tag{15}
DKL?(P?∣∣P)?=y∑?P?(y∣xi?)logP(y∣xi?;θ)P?(y∣xi?)?=y∑?P?(y∣xi?)[logP?(y∣xi?)?logP(y∣xi?;θ)]=y∑?P?(y∣xi?)logP?(y∣xi?)?y∑?P?(y∣xi?)logP(y∣xi?;θ)?(15)
觀察上面最終的式子,其中
P
?
(
y
∣
x
i
)
log
?
P
?
(
y
∣
x
i
)
P^* (y|x_i)\log P^*(y|x_i)
P?(y∣xi?)logP?(y∣xi?)與引數
θ
\theta
θ無關,實際上是真實分布的資訊熵,是一個常數;而
?
P
?
(
y
∣
x
i
)
log
?
P
(
y
∣
x
i
;
θ
)
-P^* (y|x_i)\log P(y|x_i;\theta)
?P?(y∣xi?)logP(y∣xi?;θ)就是我們熟悉的交叉熵的式子,
如果看不明白的話,或者我們換一種寫法: D K L ( P ? ∣ ∣ P ) = ? S ( P ? ) + H ( P ? , P ) D_{KL}(P^*||P)= -S(P^*) + H(P^*,P) DKL?(P?∣∣P)=?S(P?)+H(P?,P), S ( P ? ) S(P^*) S(P?)是 P ? P^* P?的資訊熵; H ( P ? , P ) H(P^*,P) H(P?,P)是交叉熵,KL散度 = 交叉熵 - 熵
因此,我們最小化關于引數
θ
\theta
θ的KL散度,就相當于最小化式
(
15
)
(15)
(15)中的第二項,即:
arg
?
?
min
?
θ
D
K
L
(
P
?
∣
∣
P
)
≡
arg
?
?
min
?
θ
?
∑
i
P
?
(
y
∣
x
i
)
log
?
P
(
y
∣
x
i
;
θ
)
(16)
\arg\,\min_{\theta}D_{KL}(P^*||P) \equiv \arg\,\min_{\theta} - \sum_i P^* (y|x_i) \log P(y|x_i;\theta) \tag{16}
argθmin?DKL?(P?∣∣P)≡argθmin??i∑?P?(y∣xi?)logP(y∣xi?;θ)(16)
即
arg
?
?
min
?
θ
D
K
L
(
P
?
∣
∣
P
)
≡
arg
?
?
min
?
θ
H
(
P
?
,
P
)
(17)
\arg\,\min_{\theta}D_{KL}(P^*||P) \equiv \arg\,\min_{\theta} H(P^*,P) \tag{17}
argθmin?DKL?(P?∣∣P)≡argθmin?H(P?,P)(17)
因此,在機器學習中,我們要評估預測模型和真實模型之間的差距,可以使用KL散度,而KL散度中的資訊熵那一部分不變,所以只需要關注交叉熵就可以了,
基于KL散度恒不小于零的特性,博主找到了一個很好的圖示:
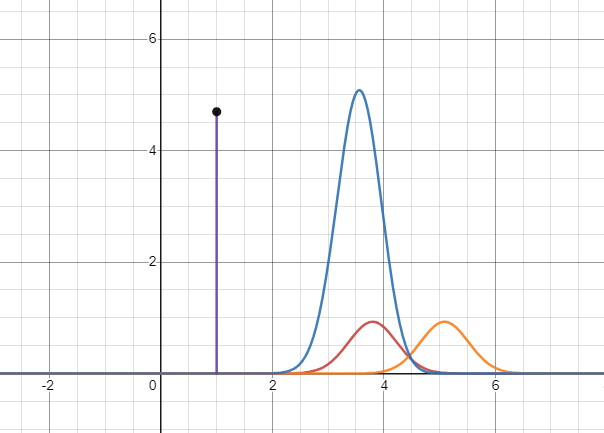
紅色曲線代表真實概率分布;橙色曲線代表預測概率分布;紫線代表藍色曲線下的面積,代表這兩個分布的交叉熵,
交叉熵的大小與預測分布和真實分布的偏離程度相關,
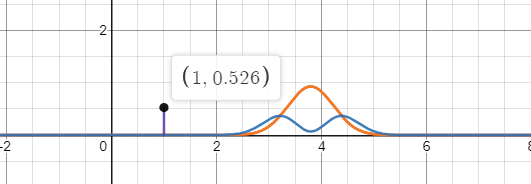
當兩個分布重疊時,此時交叉熵最小,為真實分布的資訊熵,
交叉熵損失
在機器學習中,我們需要評估標簽值 y y y和預測值 y ^ \hat y y^?之間的差距,我們知道只需要關注交叉熵,一般在機器學習中直接用交叉熵做損失函式來評估模型,
l
o
s
s
=
?
∑
j
=
1
n
y
j
log
?
y
^
j
(18)
loss=-\sum_{j=1}^n y_j \log \hat y_j \tag{18}
loss=?j=1∑n?yj?logy^?j?(18)
這里
y
j
y_j
yj?是真實樣本的標簽;
y
^
j
\hat y_j
y^?j?是預測值,通常是一個概率;
n
n
n是分類的個數;因此這是針對單個樣本的情況,如果對于批量樣本,那么交叉熵計算公式為:
L
=
?
∑
i
=
1
m
∑
j
=
1
n
y
i
j
log
?
y
^
i
j
(19)
\mathcal L = -\sum_{i=1}^m \sum_{j=1}^n y_{ij} \log \hat y_{ij} \tag{19}
L=?i=1∑m?j=1∑n?yij?logy^?ij?(19)
其中
m
m
m是樣本數;
n
n
n是分類數,
二分類
有一種特殊問題,即分類數為
2
2
2,就是二分類問題,對于這種問題,由于
n
=
2
n=2
n=2,
y
1
=
1
?
y
2
y_1=1-y_2
y1?=1?y2?,
y
^
1
=
1
?
y
^
2
\hat y_1 = 1- \hat y_2
y^?1?=1?y^?2?,所以交叉熵可以簡化為:
l
o
s
s
=
?
[
y
1
log
?
y
^
1
+
(
1
?
y
1
)
log
?
(
1
?
y
^
1
)
]
(20)
loss = - \left[ y_1 \log \hat y_1 + (1-y_1)\log (1-\hat y_1) \right] \tag{20}
loss=?[y1?logy^?1?+(1?y1?)log(1?y^?1?)](20)
對于批量樣本的交叉熵為:
L
=
?
∑
i
=
1
m
[
y
i
log
?
y
^
i
+
(
1
?
y
i
)
log
?
(
1
?
y
^
i
)
]
(21)
\mathcal L = - \sum_{i=1}^m \left [ y_i \log \hat y_i + (1-y_i)\log(1-\hat y_i) \right] \tag{21}
L=?i=1∑m?[yi?logy^?i?+(1?yi?)log(1?y^?i?)](21)
通常對于二分類問題,記正例為
1
1
1,負例為
0
0
0,因此上式的兩個相加項只會有一個存在,
多分類
常見的是多分類問題,即分類數
n
≥
3
n \geq 3
n≥3,多分類問題對于批量樣本的交叉熵損失即為式
(
19
)
(19)
(19):
L
=
?
∑
i
=
1
m
∑
j
=
1
n
y
i
j
log
?
y
^
i
j
\mathcal L = -\sum_{i=1}^m \sum_{j=1}^n y_{ij} \log \hat y_{ij}
L=?i=1∑m?j=1∑n?yij?logy^?ij?
這里有必要指出的是,對于多分類問題,標簽值一般采用獨熱編碼,預測值在輸出之前會經過Softmax轉換為概率分布,這樣交叉熵損失只會關注預測正確的類別的概率,
這種特性使得代碼撰寫也比計較直觀,
均方誤差和交叉熵
我們知道,線性回歸的損失函式是均方誤差,而邏輯回歸的損失函式為交叉熵損失,為什么呢?
先看邏輯回歸為什么用交叉熵損失而不是均方誤差,
邏輯回歸其實是分類問題,輸出的是一個概率,交叉熵就是用于衡量概率距離的函式,所以選用交叉熵損失,如果把概率值看成是一個數值的話,也可以用均方誤差啊,那到底為什么呢?
我們可以從均方誤差和交叉熵的函式圖形入手,
以二分類問題為例,先看交叉熵的函式圖形,
import numpy as np
import matplotlib.pyplot as plt
def cross_entropy(y_hat, y):
return -np.log(y_hat) if y == 1 else -np.log(1 - y_hat)
y_hat = np.arange(0.01,1,0.01)
plt.plot(y_hat, cross_entropy(y_hat, 1), label='y=1')
plt.plot(y_hat, cross_entropy(y_hat, 0), label='y=0')
plt.legend()
plt.show()
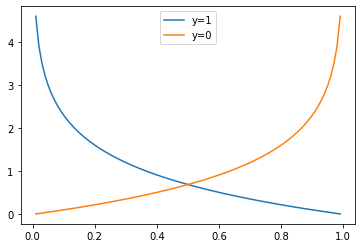
其中藍線代表真實標簽 y = 1 y=1 y=1時的交叉熵損失函式圖形,橙線代表真實標簽 y = 0 y=0 y=0時的圖形,橫坐標代表預測值,縱坐標代表損失值,
可以看到,當 y = 1 y=1 y=1時(藍線),如果預測的越正確(預測值與1越近),則損失(懲罰)越小,在越接近0的位置,損失越大,
反過來,當 y = 0 y=0 y=0時(橙線),如果預測的越正確(預測值與0越近),則損失越小,在越接近1的位置,損失越大,
我們來看下,當 y = 1 y=1 y=1時,預測結果為 y ^ = 0.1 \hat y=0.1 y^?=0.1時的損失:
> cross_entropy(0.1, 1)
2.3025850929940455
大約是 2.3 2.3 2.3,
我們再來看均方誤差的圖形:
def mse(y_hat, y):
return (y - y_hat)**2
plt.plot(y_hat,mse(y_hat, 1) , label='y=1')
plt.plot(y_hat, mse(y_hat, 0), label='y=0')
plt.legend()
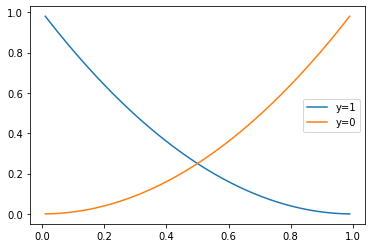
其中藍線代表真實標簽 y = 1 y=1 y=1時的均方誤差損失函式圖形,橙線代表真實標簽 y = 0 y=0 y=0時的圖形,橫坐標代表預測值,縱坐標代表損失值,
上面縱軸最大值也只是 1.0 1.0 1.0,整個函式影像看起來也沒有特別大的梯度,
我們也來看下,當 y = 1 y=1 y=1時,預測結果為 y ^ = 0.1 \hat y=0.1 y^?=0.1?時的損失:
> mse(0.1, 1)
0.81
其損失值也不大,如果選用均方誤差作為邏輯回歸的損失函式,很可能訓練不起來,
這樣我們就明白了為什么邏輯回歸要選擇交叉熵,
我們再來看線性回歸為什么不選擇交叉熵,直接說結論,假設概率分布為高斯分布的情況下,采用交叉熵損失等同于采用均方誤差損失,相關證明可以網上查找,
交叉熵損失的梯度
這里以多分類問題為例,拷貝了博主之前的另一篇文章Softmax與Cross-entropy的求導,
softmax函式為:
y ^ i = e z i ∑ k = 1 K e z k \hat y_i = \frac{e^{z_i}}{\sum_{k=1}^K e^{z_k}} y^?i?=∑k=1K?ezk?ezi??
這里
K
K
K是類別的總數,接下來求
y
^
i
\hat y_i
y^?i?對某個輸出
z
j
z_j
zj?的導數,
?
y
^
i
?
z
j
=
?
e
z
i
∑
k
=
1
K
e
z
k
?
z
j
\frac{\partial \hat y_i}{\partial z_j} = \frac{\partial \frac{e^{z_i}}{\sum_{k=1}^K e^{z_k}}}{\partial z_j}
?zj??y^?i??=?zj??∑k=1K?ezk?ezi???
這里要分兩種情況,分別是 i = j i=j i=j與 i ≠ j i \neq j i?=j,當 i = j i=j i=j時, e z i e^{z_i} ezi?對 z j z_j zj?的導數為 e z i e^{z_i} ezi?,否則當 i ≠ j i \neq j i?=j時,導數為 0 0 0,
當
i
=
j
i = j
i=j,
?
y
^
i
?
z
j
=
e
z
i
?
∑
k
=
1
K
e
z
k
?
e
z
i
?
e
z
j
(
∑
k
=
1
m
e
z
k
)
2
=
e
z
i
∑
k
=
1
m
e
z
k
?
e
z
i
∑
k
=
1
m
e
z
k
?
e
z
j
∑
k
=
1
m
e
z
k
=
y
^
i
?
y
^
i
2
=
y
^
i
(
1
?
y
^
i
)
\begin{aligned} \frac{\partial \hat y_i}{\partial z_j} &= \frac{e^{z_i}\cdot \sum_{k=1}^K e^{z_k} - e^{z_i} \cdot e^{z_j} }{(\sum_{k=1}^m e^{z_k})^2} \\ &= \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} - \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} \cdot \frac{e^{z_j}}{\sum_{k=1}^m e^{z_k}} \\ &= \hat y_i - \hat y_i^2 = \hat y_i(1 - \hat y_i) \end{aligned}
?zj??y^?i???=(∑k=1m?ezk?)2ezi??∑k=1K?ezk??ezi??ezj??=∑k=1m?ezk?ezi???∑k=1m?ezk?ezi???∑k=1m?ezk?ezj??=y^?i??y^?i2?=y^?i?(1?y^?i?)?
當
i
≠
j
i \neq j
i?=j,
?
y
^
i
?
z
j
=
0
?
∑
k
=
1
K
e
z
k
?
e
z
i
?
e
z
j
(
∑
k
=
1
m
e
z
k
)
2
=
?
e
z
i
∑
k
=
1
m
e
z
k
?
e
z
j
∑
k
=
1
m
e
z
k
=
?
y
^
i
y
^
j
\begin{aligned} \frac{\partial \hat y_i}{\partial z_j} &= \frac{0 \cdot \sum_{k=1}^K e^{z_k} - e^{z_i} \cdot e^{z_j}}{(\sum_{k=1}^m e^{z_k})^2} \\ &= - \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} \cdot \frac{e^{z_j}}{\sum_{k=1}^m e^{z_k}} \\ &= - \hat y_i \hat y_j \end{aligned}
?zj??y^?i???=(∑k=1m?ezk?)20?∑k=1K?ezk??ezi??ezj??=?∑k=1m?ezk?ezi???∑k=1m?ezk?ezj??=?y^?i?y^?j??
損失函式
L
L
L為:
L
=
?
∑
k
y
k
log
?
y
^
k
L = -\sum_k y_k \log \hat y_k
L=?k∑?yk?logy^?k?
其中 y k y_k yk?是真實類別,相當于一個常數,接下來求 L L L對 z j z_j zj?的導數
? L ? z j = ? ? ( ∑ k y k log ? y ^ k ) z j = ? ? ( ∑ k y k log ? y ^ k ) ? y ^ k ? y ^ k ? z j = ? ∑ k y k 1 y ^ k ? y ^ k z j = ( ? y k ? y ^ k ( 1 ? y ^ k ) 1 y ^ k ) k = j ? ∑ k ≠ j y k 1 y ^ k ( ? y ^ k y ^ j ) = ? y j ( 1 ? y ^ j ) ? ∑ k ≠ j y k ( ? y ^ j ) = ? y j + y j y ^ j + ∑ k ≠ j y k ( y ^ j ) = ? y j + ∑ k y k ( y ^ j ) = ? y j + y ^ j = y ^ j ? y j \begin{aligned} \frac{\partial L}{\partial z_j} &= \frac{\partial -(\sum_k y_k \log \hat y_k)}{z_j}\\ &= \frac{\partial -(\sum_k y_k \log \hat y_k)}{\partial \hat y_k} \frac{\partial \hat y_k}{\partial z_j} \\ &= -\sum_k y_k \frac{1}{\hat y_k} \frac{\partial \hat y_k}{z_j} \\ &= \left(-y_k \cdot \hat y_k(1 - \hat y_k) \frac{1}{\hat y_k} \right)_{k=j} - \sum_{k \neq j} y_k \frac{1}{\hat y_k} (-\hat y_k \hat y_j) \\ &= - y_j (1 -\hat y_j) - \sum_{k \neq j} y_k (-\hat y_j) \\ &= - y_j + y_j \hat y_j + \sum_{k \neq j} y_k (\hat y_j) \\ &= - y_j + \sum_{k} y_k (\hat y_j) \\ &= - y_j +\hat y_j \\ &= \hat y_j -y_j \end{aligned} ?zj??L??=zj???(∑k?yk?logy^?k?)?=?y^?k???(∑k?yk?logy^?k?)??zj??y^?k??=?k∑?yk?y^?k?1?zj??y^?k??=(?yk??y^?k?(1?y^?k?)y^?k?1?)k=j??k?=j∑?yk?y^?k?1?(?y^?k?y^?j?)=?yj?(1?y^?j?)?k?=j∑?yk?(?y^?j?)=?yj?+yj?y^?j?+k?=j∑?yk?(y^?j?)=?yj?+k∑?yk?(y^?j?)=?yj?+y^?j?=y^?j??yj??
這里用到了 ∑ k y k = 1 \sum_{k} y_k = 1 ∑k?yk?=1
Reference
-
如何理解資訊熵
-
損失函式是如何設計出來的
-
Softmax與Cross-entropy的求導
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/374551.html
標籤:AI