前言
一、索引型別
-
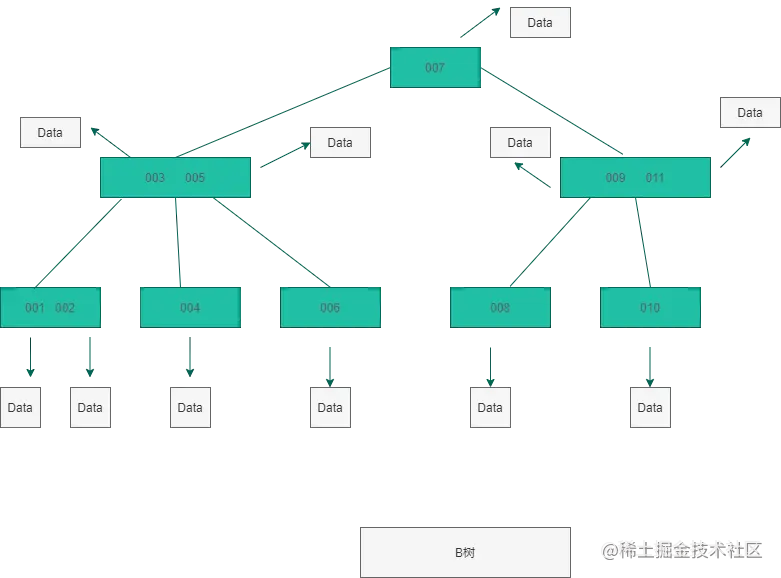
B+樹
-
為什么是B+樹而不是B樹?
首先看看B樹和B+樹在結構上的區別
-
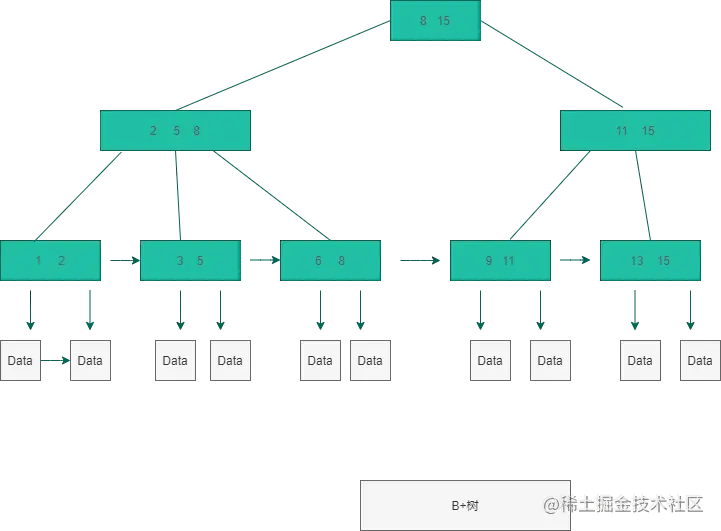
- 可以看到:
- B樹在每個節點上都有衛星資料(資料表中的一行資料),而B+樹只在葉子節點上有衛星資料,這意味著相同大小的磁盤扇區,B+樹可以存盤的葉子節點更多,磁盤IO次數更少;同樣也意味著B+樹的查找效率更穩定,而B樹資料查詢的最快時間復雜度是O(1),
- B樹的每個節點只出現一次,B+樹的所有節點都會出現在葉子節點中,B+樹的所有葉子節點形成一個升序鏈表,適合區間范圍查找,而B樹則不適合,
-
MyISAM和InnoDB的B+樹索引實作方式的區別(聚簇索引和非聚簇索引)?
首先需要了解聚簇索引和非聚簇索引,
- 聚簇索引
在聚簇索引中,葉子頁包含了行的全部資料,節點頁值包含索引列,InnoDB通過主鍵聚集資料,如果沒有定義主鍵則選擇一個唯一的非空索引列代替;如果沒有這樣的索引,InnoDB會隱式定義一個主鍵來作為聚簇索引,
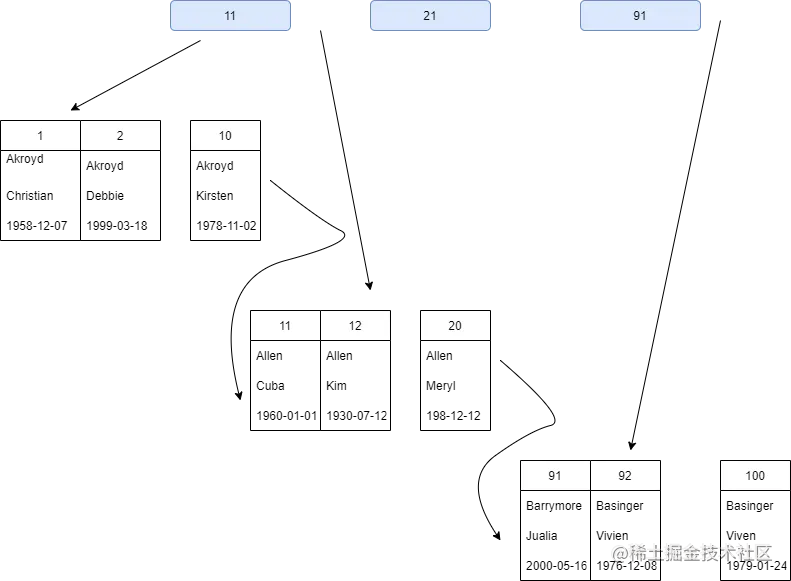
在聚簇索引中,除了主鍵索引,還有二級索引,二級索引中的葉子節點存盤的不是“行指標”,而是主鍵值,并以此作為指向行的“指標”,這意味著通過二級索引查找行,存盤引擎需要找到二級索引的葉子節點獲得對應的主鍵值,然后根據這個值去聚簇索引中查找對應的行,也稱為“回表”,當然,可以通過覆寫索引避免回表或者InnoDB的自適應索引能夠減少這樣的重復作業,
PS:聚簇索引中每一個葉子節點不止包含完整的資料行,還包括事務ID、用于事務和MVCC的回滾指標,
- 非聚簇索引
非聚簇索引的主鍵索引和二級索引在結構上沒有什么不同,都在葉子節點上存盤指向資料的物理地址的“行指標”,
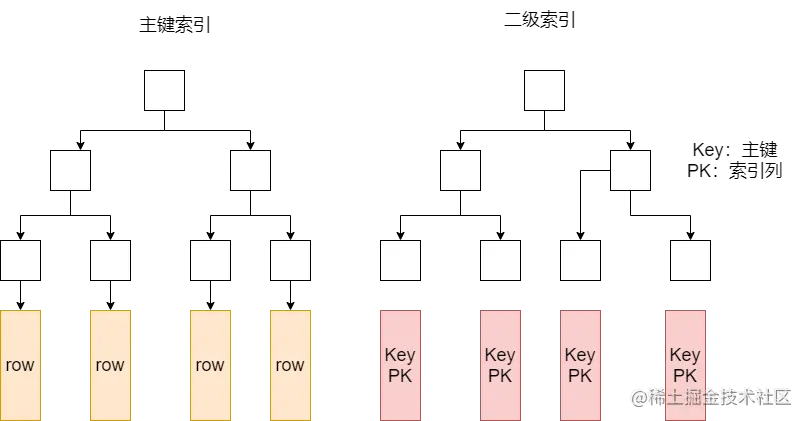
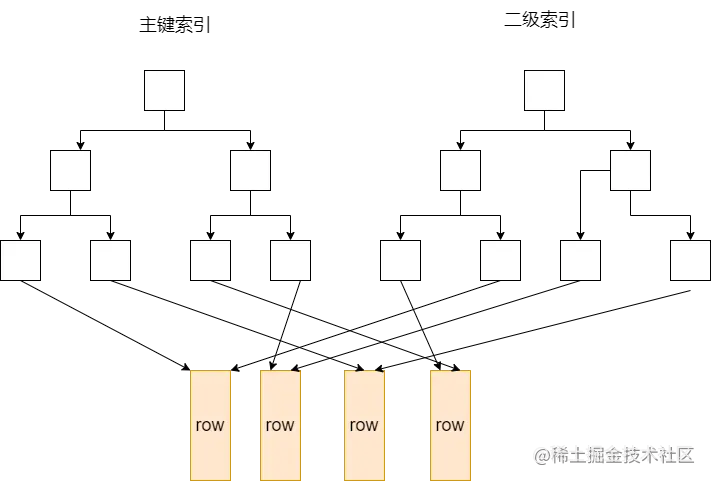
聚簇索引的優缺點
-
優點
- 把相關資料保存在一起(比如用用戶ID把用戶的全部郵件聚集在一起),否則每次資料讀取就可能導致一次磁盤IO
- 資料訪問更快,把索引和資料保存在同一個B+樹中,通常在聚簇索引中獲取資料比在非聚簇索引中查找更快
- 使用覆寫查詢可以直接利用頁節點中的主鍵值
-
缺點
- 如果所有資料都可以放在記憶體中,順序訪問不再那么必要,聚簇索引沒有優勢
- 插入速度依賴于插入順序,隨機插入會導致頁分裂,造成空洞,使用OPTIMIZE TABLE重建表
- 每次插入、更新、洗掉都需要維護索引的變化,代價很高
- 二級索引可能比想象中大,因為在節點中包含了參考行的主鍵列
-
哈希索引
哈希索引基于哈希表實作,只有精確匹配索引所有列的查詢才有效,這意味著,哈希索引適用于等值查詢,
具體實作:對于每一行資料,存盤引擎都會對所有的索引列計算一個哈希碼,哈希索引將所有的哈希碼存盤在索引中,同時在哈希表中保存指向每個資料行的指標,
在MySQL中,只有Memory引擎顯式支持哈希索引,當然Memory引擎也支持B樹索引,
PS:Memory引擎支持非唯一哈希索引,解決沖突的方式是以鏈表的形式存放多個哈希值相同的記錄指標,
- 自適應哈希索引
InnoDB注意到某些索引值被使用得非常頻繁時,會在記憶體中基于B+樹索引之上再創建一個哈希索引,這樣就讓B+樹索引也具有哈希索引的一些優點,比如快速的哈希查找
鏈接:https://juejin.cn/post/7037403074008203278
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/374629.html
標籤:其他
下一篇:LeetCode 383 贖金信