ClickHouse vs StarRocks 選型對比
面向列存的 DBMS 新的選擇
Hadoop 從誕生已經十三年了,Hadoop 的供應商爭先恐后的為 Hadoop 貢獻各種開源插件,發明各種的解決方案技術堆疊,一方面確實幫助很多用戶解決了問題,但另一方面因為繁雜的技術堆疊與高昂的維護成本,Hadoop 也漸漸地失去了原本屬于他的市場,對于用戶來說,一套高性能,簡單化,可擴展的資料庫產品能夠幫助他們解決業務痛點問題,越來越多的人將目光鎖定在列存的分布式資料庫上,
ClickHouse 簡介
ClickHouse 是由俄羅斯的第一大搜索引擎 Yandex 公司開源的列存資料庫,令人驚喜的是,ClickHouse 相較于很多商業 MPP 資料庫,比如 Vertica,InfiniDB 有著極大的性能提升,除了 Yandex 以外,越來越多的公司開始嘗試使用 ClickHouse 等列存資料庫,對于一般的分析業務,結構性較強且資料變更不頻繁,可以考慮將需要進行關聯的表打平成寬表,放入 ClickHouse 中,
相比傳統的大資料解決方案,ClickHouse 有以下的優點:
- 配置豐富,只依賴與 Zookeeper
- 線性可擴展性,可以通過添加服務器擴展集群
- 容錯性高,不同分片間采用異步多主復制
- 單表性能極佳,采用向量計算,支持采樣和近似計算等優化手段
- 功能強大支持多種表引擎
StarRocks 簡介
StarRocks 是一款極速全場景 MPP 企業級資料庫產品,具備水平在線擴縮容,金融級高可用,兼容 MySQL 協議和 MySQL 生態,提供全面向量化引擎與多種資料源聯邦查詢等重要特性,StarRocks 致力于在全場景 OLAP 業務上為用戶提供統一的解決方案,適用于對性能,實時性,并發能力和靈活性有較高要求的各類應用場景,
相比于傳統的大資料解決方案,StarRocks 有以下優點:
- 不依賴于大資料生態,同時外表的聯邦查詢可以兼容大資料生態
- 提供多種不同的模型,支持不同維度的資料建模
- 支持在線彈性擴縮容,可以自動負載均衡
- 支持高并發分析查詢
- 實時性好,支持資料秒級寫入
- 兼容 MySQL 5.7 協議和 MySQL 生態
StarRocks 與 ClickHouse 的功能對比
StarRocks 與 ClickHouse 有很多相似之處,比如說兩者都可以提供極致的性能,也都不依賴于 Hadoop 生態,底層存盤分片都提供了主主的復制高可用機制,但功能、性能與使用場景上也有差異,ClickHouse 在更適用與大寬表的場景,TP 的資料通過 CDC 工具的,可以考慮在 Flink 中將需要關聯的表打平,以大寬表的形式寫入 ClickHouse,StarRocks 對于 join 的能力更強,可以建立星型或者雪花模型應對維度資料的變更,
大寬表 vs 星型模型
ClickHouse:通過拼寬表避免聚合操作
不同于以點查為主的 TP 業務,在 AP 業務中,事實表和維度表的關聯操作不可避免,ClickHouse 與 StarRocks 最大的區別就在于對于 join 的處理上,ClickHouse 雖然提供了 join 的語意,但使用上對大表關聯的能力支撐較弱,復雜的關聯查詢經常會引起 OOM,一般我們可以考慮在 ETL 的程序中就將事實表與維度表打平成寬表,避免在 ClickHouse 中進行復雜的查詢,
目前有很多業務使用寬表來解決多遠分析的問題,說明了寬表確有其獨到之處:
- 在 ETL 的程序中處理好寬表的欄位,分析師無需關心底層的邏輯就可以實作資料的分析
- 寬表能夠包含更多的業務資料,看起來更直觀一些
- 寬表相當于單表查詢,避免了多表之間的資料關聯,性能更好
但同時,寬表在靈活性上也帶來了一些困擾: - 寬表中的資料可能會因為 join 的程序中存在一對多的情況造成錯誤資料冗余
- 寬表的結構維護麻煩,遇到維度資料變更的情況需要重跑寬表
- 寬表需要根據業務預先定義,寬表可能無法滿足臨時新增的查詢業務
StarRocks:通過星型模型適應維度變更
可以說,拼寬表的形式是以犧牲靈活性為代價,將 join 的操作前置,來加速業務的查詢,但在一些靈活度要求較高的場景,比如訂單的狀態需要頻繁改變,或者說業務人員的自助 BI 分析,寬表往往無法滿足我們的需求,此時我們還需要使用更為靈活的星型或者雪花模型進行建模,對于星型/雪花模型的兼容度上,StarRocks 的支撐要比 ClickHouse 好很多,
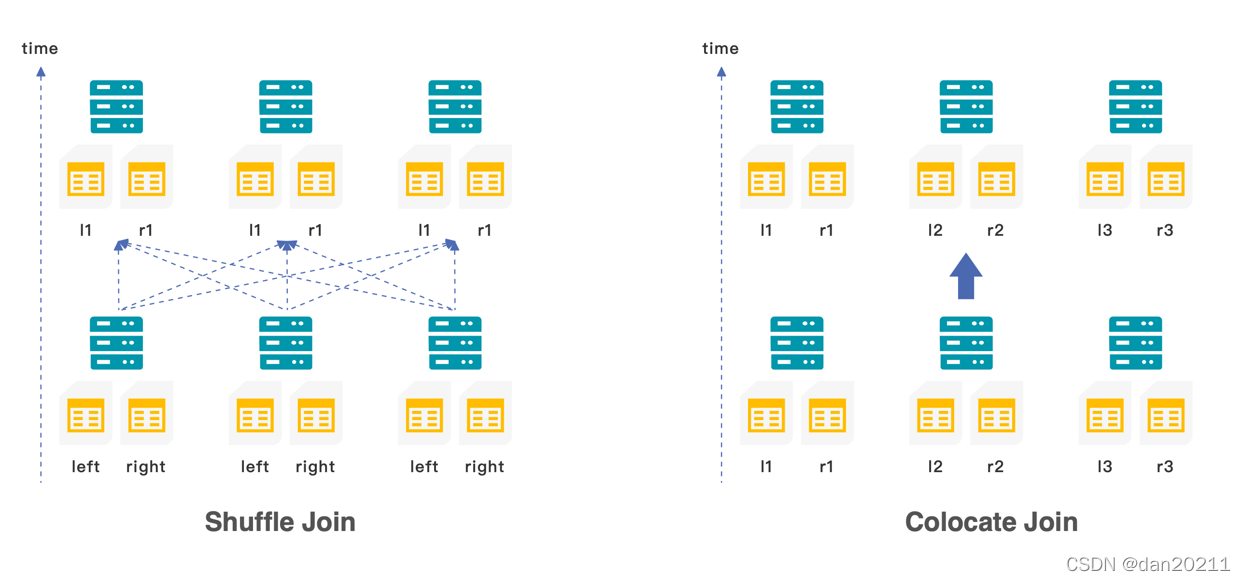
在 StarRocks 中提供了三種不同型別的 join:
- 當小表與大表關聯時,可以使用 boardcast join,小表會以廣播的形式加載到不同節點的記憶體中
- 當大表與大表關聯式,可以使用 shuffle join,兩張表值相同的資料會 shuffle 到相同的機器上
- 為了避免 shuffle 帶來的網路與 I/O 的開銷,也可以在創建表示就將需要關聯的資料存盤在同一個 colocation group 中,使用 colocation join
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);
目前大部分的 MPP 架構計算引擎,都采用基于規則的優化器(RBO),為了更好的選擇 join 的型別,StarRocks 提供了基于代價的優化器(CBO),用戶在開發業務 SQL 的時候,不需要考慮驅動表與被驅動表的順序,也不需要考慮應該使用哪一種 join 的型別,CBO 會基于采集到的表的 metric,自動的進行查詢重寫,優化 join 的順序與型別,
高并發支撐
ClickHouse 對高并發的支撐
為了更深維度的挖掘資料的價值,就需要引入更多的分析師從不同的維度進行資料勘察,更多的使用者同時也帶來了更高的 QPS 要求,對于互聯網,金融等行業,幾萬員工,幾十萬員工很常見,高峰時期并發量在幾千也并不少見,隨著互聯網化和場景化的趨勢,業務逐漸向以用戶為中心轉型,分析的重點也從原有的宏觀分析變成了用戶維度的細粒度分析,傳統的 MPP 資料庫由于所有的節點都要參與運算,所以一個集群的并發能力與一個節點的并發能力相差無幾,如果一定要提高并發量,可以考慮增加副本數的方式,但同時也增加了 RPC 的互動,對性能和物理成本的影響巨大,
在 ClickHouse 中,我們一般不建議做高并發的業務查詢,對于三副本的集群,通常會將 QPS 控制在 100 以下,ClickHouse 對高并發的業務并不友好,即使一個查詢,也會用服務器一半的 CPU 去查詢,一般來說,沒有什么有效的手段可以直接提高 ClickHouse 的并發量,只能考慮通過將結果集寫入 MySQL 中增加查詢的并發度,
StarRocks 對高并發的支撐
相較于 ClickHouse,StarRocks 可以支撐數千用戶同時進行分析查詢,在部分場景下,高并發能力能夠達到萬級,StarRocks 在資料存盤層,采用先磁區再分桶的策略,增加了資料的指向性,利用前綴索引可以快讀對資料進行過濾和查找,減少磁盤的 I/O 操作,提升查詢性能,
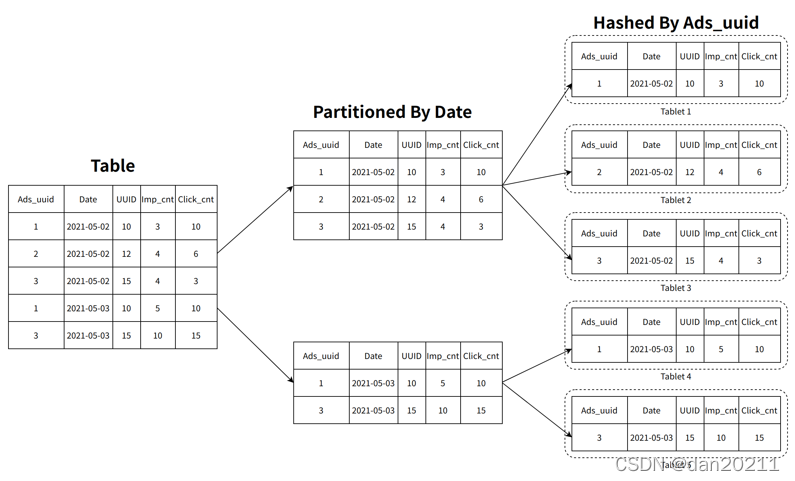
在建表的時候,磁區分桶應該盡可能的覆寫到所帶的查詢陳述句,這樣可以有效的利用磁區分桶剪裁的功能,盡可能的減少資料的掃描量,此外,StarRocks 也提供了 MOLAP 庫的預聚合能力,對于一些復雜的分析類查詢,可以通過創建物化視圖進行預先聚合,原有幾十億的基表,可以通過預聚合 RollUp 操作變成幾百或者幾千行的表,查詢時延遲會有顯著下降,并發也會有顯著提升,
資料的高頻變更
ClickHouse 中的資料更新
在 OLAP 資料庫中,可變資料(Mutable data)通常是不受歡迎的,ClickHouse 也是如此,早期的版本中并不支持 UPDATE 和 DELETE 操作,在 1.15 版本后,Clickhouse 提供了 MUTATION 操作(通過 ALTER TABLE 陳述句)來實作資料的更新、洗掉,但這是一種“較重”的操作,它與標準 SQL 語法中的 UPDATE、DELETE 不同,是異步執行的,對于批量資料不頻繁的更新或洗掉比較有用,除了 MUTATION 操作,Clickhouse 還可以通過 CollapsingMergeTree、VersionedCollapsingMergeTree、ReplacingMergeTree 結合具體業務資料結構來實作資料的更新、洗掉,這三種方式都通過 INSERT 陳述句插入最新的資料,新資料會“抵消”或“替換”掉老資料,但是“抵消”或“替換”都是發生在資料檔案后臺 Merge 時,也就是說,在 Merge 之前,新資料和老資料會同時存在,
針對與不同的業務場景,ClickHouse 提供了不同的業務引擎來進行資料變更,
對于離線業務,可以考慮增量和全量兩種方案:
增量同步方案中,使用 ReplacingMergeTree 引擎,先用 Spark 將上游資料同步到 Hive,再由 Spark 消費 Hive 中的增量資料寫入到 ClickHouse 中,由于只同步增量資料,對下游的壓力較小,需要確保維度資料基本不變,
全量同步方案中,使用 MergeTree 引擎,通過 Spark 將上游資料定時同步到 Hive 中,truncate ClickHouse 中的表,隨后使用 Spark 消費 Hive 近幾天的資料一起寫入到 ClickHouse 中,由于是全量資料匯入,對下游壓力較大,但無需考慮維度變化的問題,
對于實時業務,可以采用 VersionedCollapsingMergeTree 和 ReplacingMergeTree 兩種引擎:
使用 VersionedCollapsingMergeTree 引擎,先通過 Spark 將上游資料一次性同步到 ClickHouse 中,在通過 Kafka 消費增量資料,實時同步到 ClickHouse 中,但因為引入了 MQ,需要保證 exectly once 語意,實時和離線資料連接點存在無法折疊現象,
使用 ReplacingMergeTree 引擎替換 VersionedCollapsingMergeTree 引擎,先通過 Spark 將上游存量資料一次性同步到 ClickHouse 中,在通過 MQ 將實時資料同步到 ReplacingMergeTree 引擎中,相比 VersionedCollapsingMergeTree 要更簡單,且離線和實時資料連接點不存在例外,但此種方案無法保重沒有重復資料,
StarRocks 中的資料更新
相較于 ClickHouse,StarRocks 對于資料更新的操作更加簡單,
StarRocks 中提供了多種模型適配了更新操作,明細召回操作,聚合操作等業務需求,更新模型可以按照主鍵進行 UPDATE/DELETE 操作,通過存盤和索引的優化可以在并發更新的同時高效的查詢,在某些電商場景中,訂單的狀態需要頻繁的更新,每天更新的訂單量可能上億,通過更新模型,可以很好的適配實時更新的需求,
| 特點 | 適用場景 | |
|---|---|---|
| 明細模型 | 用于保存和分析原始明細資料,以追加寫為主要寫入方式,資料寫入后幾乎無更新, | 日志,操作記錄,設備狀態采樣,時序類資料等 |
| 聚合模型 | 用于保存和分析匯總類(如:max、min、sum等)資料,不需要查詢明細資料,資料匯入后實時完成聚合,資料寫入后幾乎無更新, | 按時間、地域、機構匯總資料等 |
| Primary Key | 模型 支持基于主鍵的更新,delete-and-insert,大批量匯入時保證高性能查詢,用于保存和分析需要更新的資料, | 狀態會發生變動的訂單,設備狀態等 |
| Unique 模型 | 支持基于主鍵的更新,Merge On Read,更新頻率比主鍵模型更高,用于保存和分析需要更新的資料, | 狀態會發生變動的訂單,設備狀態等 |
StarRocks 1.19 版本之前,可以使用 Unique 模型進行按主鍵的更新操作,Unique 模型使用的是 Merge-on-Read 策略,即在資料入庫的時候會給每一個批次匯入資料分配一個版本號,同一主鍵的資料可能有多個版本號,在查詢的時候 StarRocks 會先做 merge 操作,回傳一個版本號最新的資料,
自 StarRocks 1.19 版本之后發布了主鍵模型,能夠通過主鍵進行更新和洗掉的操作,更友好的支持實時/頻繁更新的需求,相較于 Unique 模型中 Merge-on-Read 的模式,主鍵模型中使用的是 Delete-and-Insert 的更新策略,性能會有三倍左右的提升,對于前端的 TP 庫通過 CDC 實時同步到 StarRocks 的場景,建議使用主鍵模型,
集群的維護
相比于單實體的資料庫,任何一款分布式資料庫維護的成本都要成倍的增長,一方面是節點增多,發生故障的幾率變高,對于這種情況,我們需要一套良好的自動 failover 機制,另一方便隨著資料量的增長,要能做到在線彈性擴縮容,保證集群的穩定性與可用性,
###ClickHouse 中的節點擴容與重分布
與一般的分布式資料庫或者 Hadoop 生態不同,HDFS 可以根據集群節點的增減自動的通過 balance 來調節資料均衡,但是 ClickHouse 集群不能自動感知集群拓撲的變化,所以就不能自動 balance 資料,當集群資料較大時,新增集群節點可能會給資料負載均衡帶來極大的運維成本,
一般來說,新增集群節點我們通常有三種方案:
- 如果業務允許,可以給集群中的表設定 TTL,長時間保留的資料會逐漸被清理到,新增的資料會自動選擇新節點,最后會達到負載均衡,
- 在集群中建立臨時表,將原表中的資料復制到臨時表,再洗掉原表,當資料量較大時,或者表的數量過多時,維護成本較高,同時無法應對實時資料變更,
- 通過配置權重的方式,將新寫入的資料引導到新的節點,權重維護成本較高,
無論上述的哪一種方案,從時間成本,硬體資源,實時性等方面考慮,ClickHouse 都不是非常適合在線位元組點擴縮容及資料充分布,同時,由于 ClickHouse 中無法做到自動探測節點拓撲變化,我們可能需要再 CMDB 中寫入一套資料重分布的邏輯,所以我們需要盡可能的提前預估好資料量及節點的數量,
StarRocks 中的在線彈性擴縮容
與 HDFS 一樣,當 StarRocks 集群感知到集群拓撲發生變化的時候,可以做到在線的彈性擴縮容,避免了增加節點對業務的侵入,
StarRocks 中的資料采用先磁區再分桶的機制進行存盤,資料分桶后,會根據分桶鍵做 hash 運算,結果一致的資料被劃分到同一資料分片中,我們稱之為 tablet,Tablet 是 StarRocks 中資料冗余的最小單位,通常我們會默認資料以三副本的形式存盤,節點中通過 Quorum 協議進行復制,當某個節點發生宕機時,在其他可用的節點上會自動補齊丟失的 tablet,做到無感知的 failover,
在新增節點時,也會有 FE 自動的進行調度,將已有節點中的 tablet 自動的調度到擴容的節點上,做到自動的資料片均衡,為了避免 tablet 遷移時對業務的性能影響,可以盡量選擇在業務低峰期進行節點的擴縮容,或者可以動態調整調度引數,通過引數控制 tablet 調度的速度,盡可能的減少對業務的影響,
ClickHouse 與 StarRocks 的性能對比
單表 SSB 性能測驗
由于 ClickHouse join 能力有限,無法完成 TPCH 的測驗,這里使用 SSB 100G 的單表進行測驗,
測驗環境
| 機器 | 配置 (阿里云主機 3 臺) |
|---|---|
| CPU | 64 核 Intel? Xeon? Platinum 8269CY CPU @ 2.5GHz Cache Size: 36608 KB |
| 記憶體 | 128G |
| 網路帶寬 | 100G |
| 磁盤 | SSD 高效云盤 |
| ClickHouse 版本 | 21.9.5.16-2.x86_64 (18-Oct-2021) |
| StarRocks 版本 | v1.19.2 |
測驗資料
| 表名 | 行數 | 說明 |
|---|---|---|
| lineorder | 6 億 | SSB 商品訂單表 |
| customer | 300 萬 | SSB 客戶表 |
| part | 140 萬 | SSB 零部件表 |
| supplier | 20 萬 | SSB 供應商表 |
| dates | 2556 | 日期表 |
| lineorder_flat | 6 億 | SSB 打平后的寬表 |
測驗結果
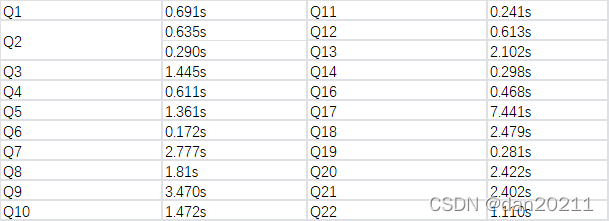
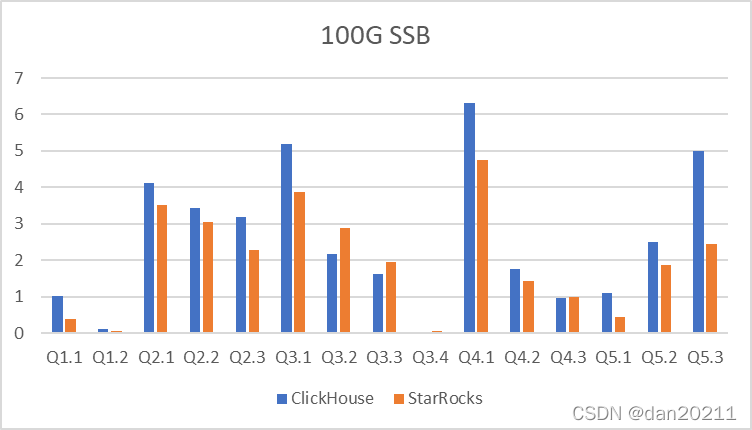
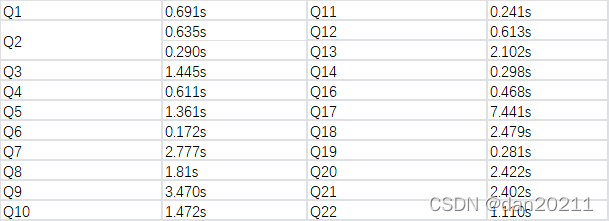
從測驗結果中可以看出來,14 個測驗中,有 9 個 SQL,StarRocks 在性能上要超過 ClickHouse,
多表 TPCH 性能測驗
ClickHouse 不擅長多表關聯的場景,對于 TPCH 測驗機,很多查詢無法跑出,或者 OOM,目前只進行了 StarRocks 的 TPCH 測驗,
測驗環境
| 機器 | 配置 (阿里云主機 3 臺) |
|---|---|
| CPU | 64 核 Intel? Xeon? Platinum 8269CY CPU @ 2.5GHz Cache Size: 36608 KB |
| 記憶體 | 128G |
| 網路帶寬 | 100G |
| 磁盤 | SSD 高效云盤 |
| ClickHouse 版本 | 21.9.5.16-2.x86_64 (18-Oct-2021) |
| StarRocks 版本 | v1.19.2 |
測驗資料
選用 TPCH 100G 測驗集,
| 表名 | 行數 |
|---|---|
| customer | 15000000 |
| lineitem | 600037902 |
| nation | 25 |
| orders | 150000000 |
| part | 20000000 |
| partsupp | 80000000 |
| region | 5 |
| supplier | 1000000 |
測驗結果
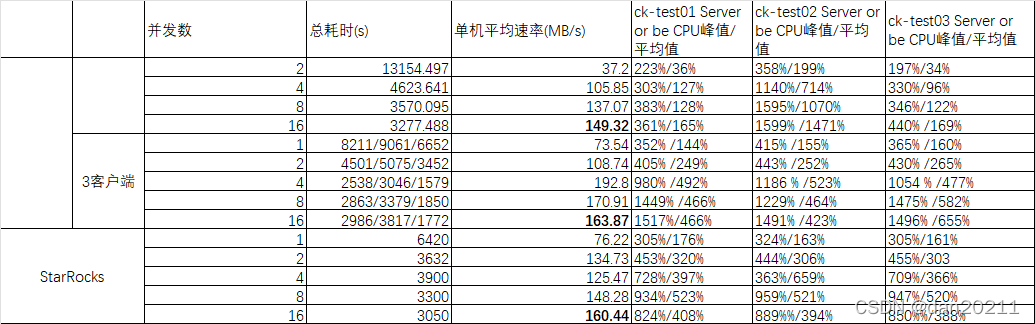
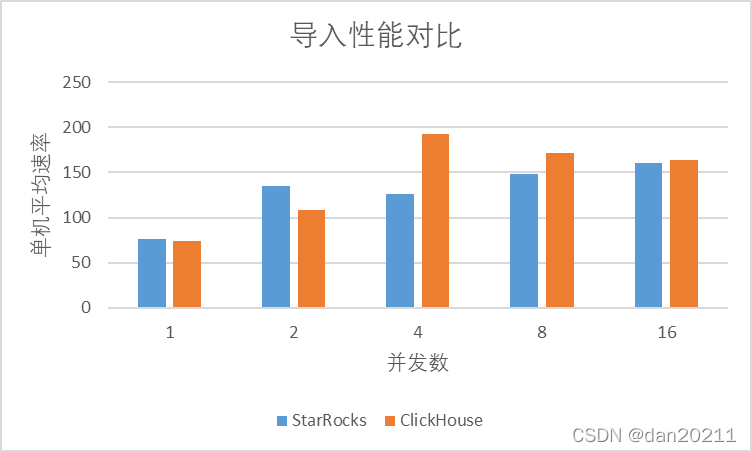
匯入性能測驗
無論是 ClickHouse 還是 StarRocks,我們都可以使用 DataX 進行全量資料的匯入,增量部分通過 CDC 工具寫入到 MQ 中在經過下游資料庫消費即可,
資料集
匯入測驗選取了 ClickHouse Native Format 資料集,1 個 xz 格式壓縮檔案大概 85GB 左右,解壓后原始檔案 1.4T,31 億條資料,檔案格式為 CSV
匯入方式
ClickHouse 中采用的 HDFS 外表的形式,ClickHouse 中分布式表只能選擇一個 integer 列作為 Sharding Key,觀察資料發現技術都很低,因此使用 rand() 分布形式,
CREATE TABLE github_events_all AS github_events_local \
ENGINE = Distributed( \
perftest_3shards_1replicas, \
github, \
github_events_local, \
rand());
HDFS 外表定義如下:
CREATE TABLE github_events_hdfs
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4,
'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8,
'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11,
'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15,
'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19,
'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9,
'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
body String,
path String,
position Int32,
line Int32,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
locked UInt8,
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
comments UInt32,
author_association Enum('NONE' = 0, 'CONTRIBUTOR' = 1, 'OWNER' = 2, 'COLLABORATOR' = 3, 'MEMBER' = 4, 'MANNEQUIN' = 5),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
requested_teams Array(LowCardinality(String)),
head_ref LowCardinality(String),
head_sha String,
base_ref LowCardinality(String),
base_sha String,
merged UInt8,
mergeable UInt8,
rebaseable UInt8,
mergeable_state Enum('unknown' = 0, 'dirty' = 1, 'clean' = 2, 'unstable' = 3, 'draft' = 4),
merged_by LowCardinality(String),
review_comments UInt32,
maintainer_can_modify UInt8,
commits UInt32,
additions UInt32,
deletions UInt32,
changed_files UInt32,
diff_hunk String,
original_position UInt32,
commit_id String,
original_commit_id String,
push_size UInt32,
push_distinct_size UInt32,
member_login LowCardinality(String),
release_tag_name String,
release_name String,
review_state Enum('none' = 0, 'approved' = 1, 'changes_requested' = 2, 'commented' = 3, 'dismissed' = 4, 'pending' = 5)
)
ENGINE = HDFS('hdfs://XXXXXXXXXX:9000/user/stephen/data/github-02/*', 'TSV')
在 StarRocks 中,采用 Broker Load 的模式進行匯入,匯入命令如下:
LOAD LABEL github.xxzddszxxzz (
DATA INFILE("hdfs://XXXXXXXXXX:9000/user/stephen/data/github/*")
INTO TABLE `github_events`
(event_type,repo_name,created_at,file_time,actor_login,updated_at,action,comment_id,body,path,position,line,ref,ref_type,creator_user_login,number,title,labels,state,locked,assignee,assignees,comments,author_association,closed_at,merged_at,merge_commit_sha,requested_reviewers,requested_teams,head_ref,head_sha,base_ref,base_sha,merged,mergeable,rebaseable,mergeable_state,merged_by,review_comments,maintainer_can_modify,commits,additions,deletions,changed_files,diff_hunk,original_position,commit_id,original_commit_id,push_size,push_distinct_size,member_login,release_tag_name,release_name,review_state)
)
WITH BROKER oss_broker1 ("username"="user", "password"="password")
PROPERTIES
(
"max_filter_ratio" = "0.1"
);
匯入結果
可以看出,在使用 github 資料集進行匯入的時候,基本上 StarRocks 和 ClickHouse 匯入的性能相差不多,
結論
ClickHouse 與 StarRocks 都是很優秀的關系新 OLAP 資料庫,兩者有著很多的相似之處,對于分析類查詢都提供了極致的性能,都不依賴于 Hadoop 生態圈,從本次的選型對比中,可以看出在一些場景下,StarRocks 相較于 ClickHouse 有更好的表現,一般來說,ClickHouse 適合于維度變化較少的拼寬表的場景,StarRocks 不僅在單表的測驗中有著更出色的表現,在多表關聯的場景具有更大的優勢,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/374646.html
標籤:其他