目錄
使用流程
1.環境的安裝 pip install selenium
2.下載瀏覽器的驅動
3.實體化瀏覽器物件
4.基于瀏覽器自動化的代碼
之前requests:
用selenium后
作用:
便捷獲取網站中動態加載的資料
便捷實作模擬登錄
簡介:基于瀏覽器自動化的模塊
使用流程
1.環境的安裝 pip install selenium
2.下載瀏覽器的驅動
3.實體化瀏覽器物件
4.基于瀏覽器自動化的代碼
1.環境的安裝 pip install selenium
2.下載瀏覽器的驅動
例如我的google瀏覽器的驅動
詳細教程:1.特別說一下沒有你的該版本,選個大致一樣的就可以了
2.將解壓的chromedriver放你的程式同一路徑下
chromedriver下載與安裝方法,親測可用_zhoukeguai的博客-CSDN博客_chromedriver下載安裝chromedriver下載地址:http://chromedriver.storage.googleapis.com/index.htmlhttp://npm.taobao.org/mirrors/chromedriver/兩個地址都可以下載,根據自己的chrome瀏覽器的版本選擇下載即可查看瀏覽器版本 ↓,我的版本為88.0.4324.104,目前最新版沒有找到88.0.4324.104對應的驅動,下載了88.0.4324.96的下載解壓后把exe檔案復制到瀏覽器的安裝目錄下:Chttps://blog.csdn.net/zhoukeguai/article/details/113247342?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163854737516780271966573%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=163854737516780271966573&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-113247342.pc_search_es_clickV2&utm_term=chromedriver&spm=1018.2226.3001.4187
3.實體化瀏覽器物件
固定格式:
from selenium import webdriver
bro = webdriver.Chrome(executable_path="./chromedriver")
#發起請求
bro.get('http://scxk.nmpa.gov.cn:81/xk/')
4.基于瀏覽器自動化的代碼
我們來看一下爬取藥監局(該頁面某些資料是通過ajax動態加載)
如果我們用requests要對主網頁分析一次,子網頁也分析一次,就會特別麻煩
之前requests:
import requests
import json
url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
all_data_list = []
id_list = []
#獲取所有頁面操作
for page in range(1,6):
page=str(page)
data = {
'on':' true',
'page': page,
'pageSize': '15',
'productName': '',
'conditionType':' 1',
'applyname': '',
'applysn': ''
}
id_json = requests.post(url=url,headers=header,data=data).json()
#print(id_json)
#獲取每個企業id
for id in id_json["list"]:
id_list.append(id["ID"])
#獲取企業具體資料
post_url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById"
for ids in id_list:
data = {
"id":ids
}
data_json = requests.post(url=post_url,headers=header,data=data).json()
all_data_list.append(data_json)
fp = open('./all_data.json',"w",encoding="utf-8")
json.dump(all_data_list, fp, ensure_ascii=False)
print("over")用selenium后
"""
CSDN : heart_6662
PYTHON amateur
"""
from selenium import webdriver
from lxml import etree
from time import sleep
bro = webdriver.Chrome(executable_path="./chromedriver")
#發起請求
bro.get('http://scxk.nmpa.gov.cn:81/xk/')
#page_source 獲取當前頁面回傳的頁面原始碼
page_text = bro.page_source
#決議
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@id="gzlist"]/li')
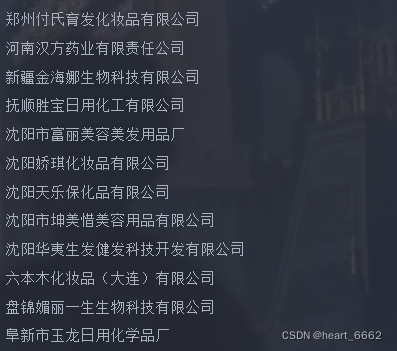
for li in li_list:
name = li.xpath('./dl/@title')[0]
print(name)
sleep(5)
bro.quit()
自動打開瀏覽器
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/374725.html
標籤:其他
上一篇:Python入門總結-默單詞程式