- 1.文章地址
- paper:https://arxiv.org/pdf/2104.11178
- 2.Motivation
- 作者提出了一個使用無卷積transformer架構從無標簽資料中學習多模態表示的框架,具體來說,Video-AudioText Transformer (VATT)將原始信號作為輸入,并提取足夠豐富的多模態表征,從而有利于各種下游任務(例如檢測、分類、跟蹤),作者使用多模態對比損失從頭到尾訓練VATT,并通過視頻動作識別、音頻事件分類、影像分類和文本到視頻檢索等下游任務評估其性能,此外,作者研究了一種模式不可知的、單骨干的transformer,在三種模態之間共享權值,證明了無卷積VATT在下游任務中的性能優于先進的基于基于ConvNet的結構,
- 最近的研究表明,無需卷積的、專門設計的全注意模型可以匹配cnn在影像識別任務中的表現,
- 作者提出了一個緊迫的問題:如何得到大規模未標注的資料?
- 作者認為多模態視頻的極大規模有可能教會transformer必要的先驗知識,而不是預先定義的歸納偏差,以建模視覺表征,
- 為此,作者研究了三種transformer的self-supervised、多模態預訓練,它們分別將互聯網視頻的原始RGB幀、音頻波形和語音音頻的文本作為輸入,
- 3.Method
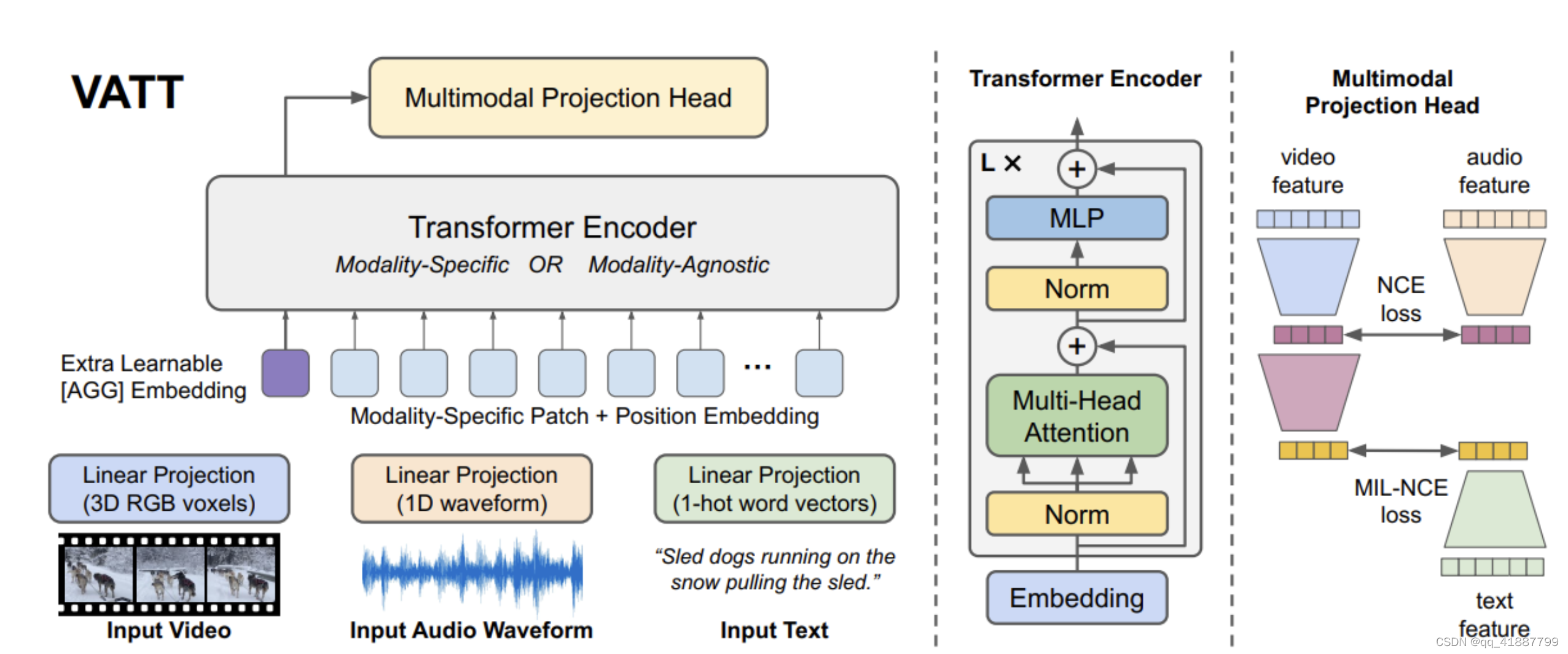
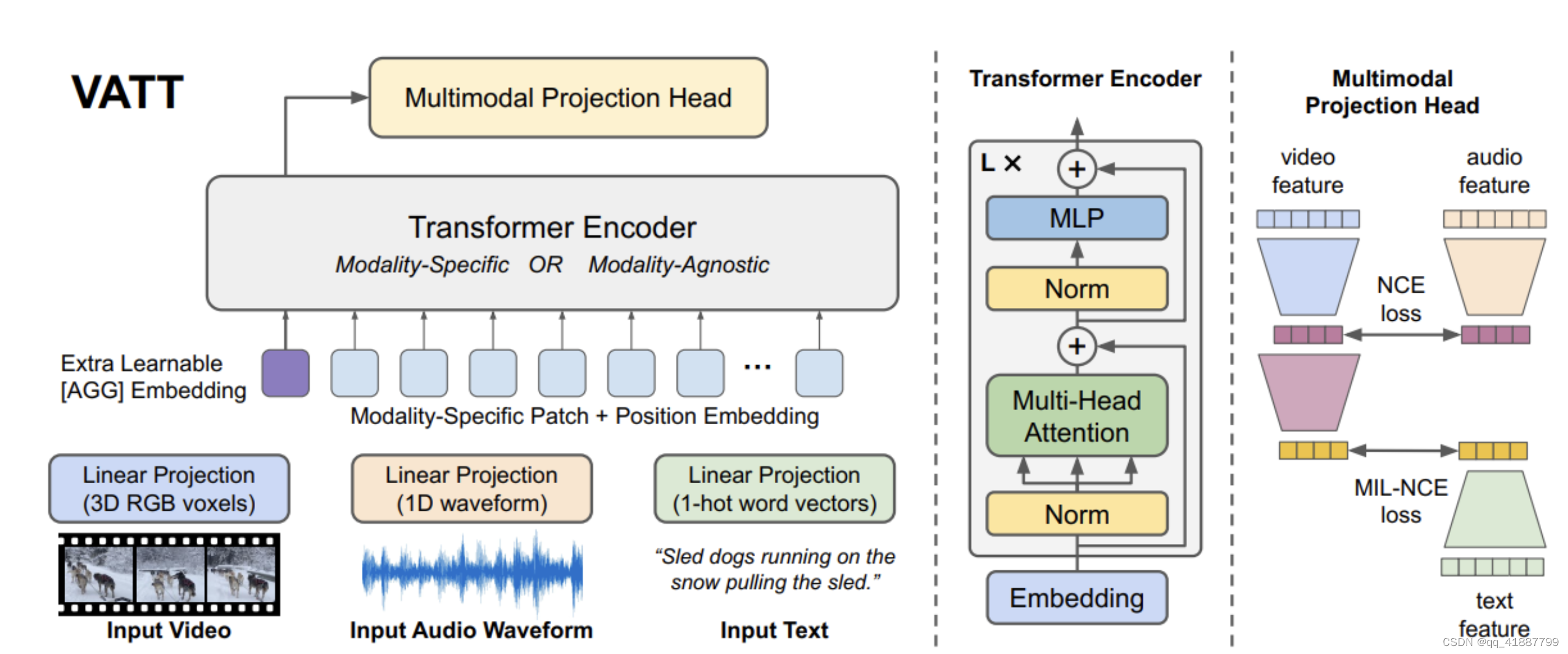
- This is the overview of the VTT structure, and the self-supervised, multimodal learining strategy.
- Each modality into a feature vector and feeds it into a Transformer encoder.
- We define a semantically hierarchical common space to account for the granularity of different modalities
- process
- 1.對每個模態通過 tokenization layer, 將原始的輸入投影到沒有enbedding的向量, 緊接著傳給transformer
- 2.Transformer backbone 提取具體的某個模態的表征, 然后將其映射到共享空間中,帶上對比損失,
- Transformer 有2種主要的設定:(1)每個模態都有具體各自的權重;(2)各個模態共享同一個權重,
- 詳細步驟:
1.Tokenization and Positional Encoding
Video:
設每個視頻片段(video clip)的大小為: T × H × W
首先,將其劃分為若干個小patch ∈ t × h × w × 3 :
緊接著采用線性投影的方式得到每個patch的d維向量,即用一個可學習的矩陣 Wvp ∈ thw × d
最后,定義了可學習的embedding沿著3D空間編碼位置資訊,即:
故需要用上位置embedding分別加入到 ei , ej , ek中,該位置embedding的長度為:
Audio:
原始的audio信號是1D的資料,其長度為 1 ? T′,緊接著將其劃分為 ? T ′ / t ′ ?個小片段,每個片段的長度是 t ′
緊接著,應用線性投影,即采用可學習的矩陣 Wap ∈ R t ′ × d
最后,作者采用了 ? T ′ / t ′ ? 個可學習的embedding去編碼每個波形片段,
Text
首先,構建一個包含所有訓練資料單詞的詞匯庫,其長度為 v,
緊接著,對于每一個單詞,將其映射為v維度的one-hot向量;
最后,用一個可學習的矩陣 W tp ∈ R v × d 去實作線性投影,
2.DropToken
Figure2. During training, we leverage the high redundancy in multimodal video data and propose to randomly drop input tokens.
This sample and effective technique significantly reduces training time with little loss of quality
Droptoken用來在訓練時減少計算復雜度,
在得到視頻或者語音模態的token后,隨機性的選擇這些token的一部分通過采樣序列,并非采用所有的token資料 傳遞到Transformer,
作者認為與其降低原始輸入的解析度或維度,不如保持高保真輸入,并通過DropToken隨機抽樣token,DropToken特別具有吸引力,
因為它的原始視頻和音頻輸入可能包含高冗余,
3.Transformer-backbone
具體執行方案如下:
xAGG是可學習的embedding ,代表聚合所有輸入資訊的可學習embedding,其輸出為 zout 0, 該輸出會用于后續的分類和common space映射,
MHA代表Multi-Head-Attention,執行了標準的self-attention操作,
MLP代表多層感知機,其激活函式采用了GeLU,
LN代表Layer Normaliztion,
epos代表position embedding,
文本模型中,去掉了編碼位置 ePOS,并在MHA模塊的第一層的每個注意得分中添加了一個可學習的相對偏差,
這個簡單的改變使文本模型的權重可以直接轉移到最先進的文本模型,
4.Common Space Projection
作者使用了公共空間投影和對比學習來訓練網路,更具體地說,對于一個視頻-音頻-文本三元組,作者定義了一個在語意層次的公共空間映射,
能夠通過余弦相似度直接比較視頻-音頻對和視頻-文本對,為此,作者將多層次預測定義如下:
其中 g a → v a ( ) 是用2層帶有ReLU激活函式的投影實作的,此外,作者還增加了BN層在每個線性層后面,
5.Multimodal Contrastive Learning
由于未標記的多模態視頻資料隨處可得,故作者采用了self-supervised目標函式訓練VATT模型,
作者使用了Noise-Contrastive-Estimation (NCE)來對其video-text和video-autio pairs,其中video-text和video-autio pairs是來自視頻的不同時序位置,
作者定義了正樣本和負樣本pairs,
正樣本pairs:在同一個視頻片段里面同時選擇video和audio資訊,在不同的時序上同時選擇video和text資訊,
負樣本Pairs:分別隨機在不同的video,audio和text上選擇,
接著,作者定義了NCE loss,最大化正樣本pairs的相似性同時最小化負樣本pairs的相似性,
由于在預訓練的資料集上存在很多噪聲text資料,并且有些視頻片段不包含語音資訊,
因此,作者使用了 Multiple-Instance-learning-NCE(MIL-NCE)去匹配一個視頻輸入和多個text輸入資訊,視頻和text在視頻輸入的時序上是很靠近的,
這種變體改進了用于視頻-文本匹配的普通NCE,作者對視頻-音頻對使用常規NCE,對視頻-文本對使用MIL-NCE,
具體來說,給定上節中規定的公共空間,損失目標可寫為:
B代表batch_size,作者在每次迭代上構建了B個video-audio pairs,分別代表正的P(z)和N(z)分別為視頻剪輯zv,vt周圍的正文本剪輯和負文本剪輯,
具體來說, P(zv,vt)包含了5個與視頻剪輯在時間上最接近的文本剪輯,τ用來調整區分正對和負對時目標的超參,最后,VATT模型總的損失函式如下:
更多可以了解
BERT: GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
ViT: GitHub - google-research/vision_transformer
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375070.html
標籤:其他