影像分割技術原理決議
- 影像分割
- 模型
- 全卷積網路(FCN)
- UNet
- 顯著性目標檢測/影像分割 U2net
- SegNet
- 現在的影像分割技術常用
- 常用損失函式
- 損失函式
- 精度描述
- 像素準確率(Pixel Accuracy)
- 平均像素準確率(Mean Pixel Accuracy)
- 平均交并比(Mean IoU)
- 頻權交并比(FWIoU)
- Dice系數(Dice Coeffcient)
影像分割
模型
- 早期基于深度學習的影像分割以FCN為核心,旨在重點解決如何更好從卷積下采樣中恢復丟掉的資訊損失,
后來逐漸形成了以U-Net為核心的這樣一種編解碼對稱的U形結構, - 語意分割界迄今為止最重要的兩個設計,一個是以U-Net為代表的U形結構,目前基于U-Net結構的創新就層出不窮,比如說應用于3D影像的V-Net,嵌套U-Net結構的U-Net++等,除此在外還有SegNet、RefineNet、HRNet和FastFCN,另一個則是以DeepLab系列為代表的Dilation設計,主要包括DeepLab系列和PSPNet,隨著模型的Baseline效果不斷提升,語意分割任務的主要矛盾也逐從downsample損失恢復像素逐漸演變為如何更有效地利用context背景關系資訊,
全卷積網路(FCN)
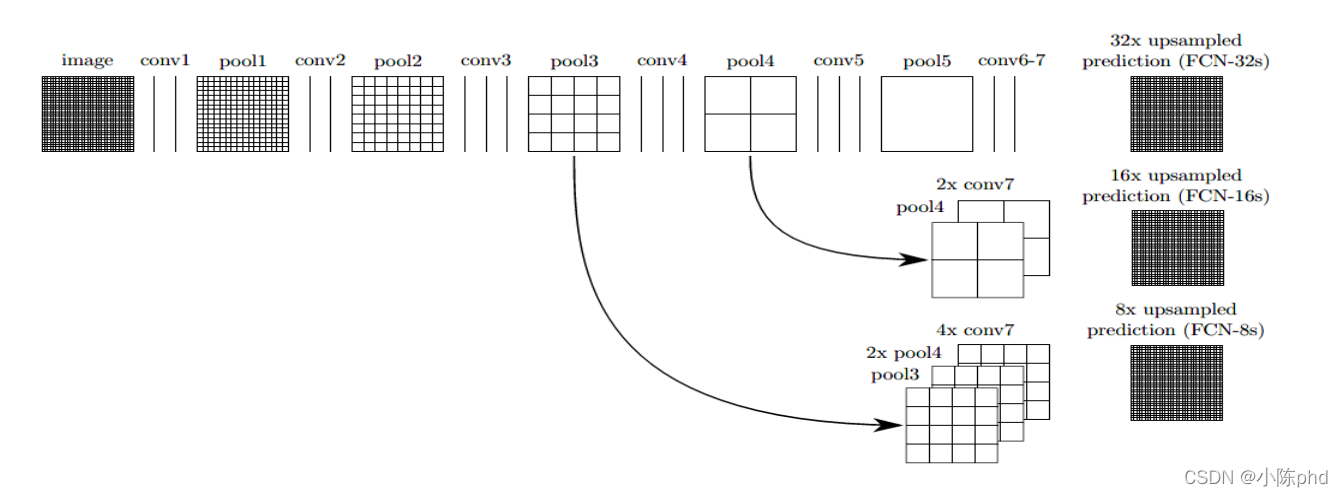
FCN(Fully Convilutional Networks)是語意分割領域的開山之作,FCN的提出是在2016年,相較于此前提出的AlexNet和VGG等卷積全連接的網路結構,FCN提出用卷積層代替全連接層來處理語意分割問題,這也是FCN的由來,即全卷積網路,FCN的關鍵點主要有三,一是全卷積進行特征提取和下采樣,二是雙線性插值進行上采樣,三是跳躍連接進行特征融合,
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as F
from torch.utils import model_zoo
from torchvision import models
class FCN8(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.feats = nn.Sequential(*feats[0:9])
self.feat3 = nn.Sequential(*feats[10:16])
self.feat4 = nn.Sequential(*feats[17:23])
self.feat5 = nn.Sequential(*feats[24:30])
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.requires_grad = False
self.fconn = nn.Sequential(
nn.Conv2d(512, 4096, 7),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Conv2d(4096, 4096, 1),
nn.ReLU(inplace=True),
nn.Dropout()
)
self.score_feat3 = nn.Conv2d(256, num_classes, 1)
self.score_feat4 = nn.Conv2d(512, num_classes, 1)
self.score_fconn = nn.Conv2d(4096, num_classes, 1)
def forward(self, x):
feats = self.feats(x)
feat3 = self.feat3(feats)
feat4 = self.feat4(feat3)
feat5 = self.feat5(feat4)
fconn = self.fconn(feat5)
score_feat3 = self.score_feat3(feat3)
score_feat4 = self.score_feat4(feat4)
score_fconn = self.score_fconn(fconn)
score = F.upsample_bilinear(score_fconn, score_feat4.size()[2:])
score += score_feat4
score = F.upsample_bilinear(score, score_feat3.size()[2:])
score += score_feat3
return F.upsample_bilinear(score, x.size()[2:])
- vgg16作為FCN-8的編碼部分,這使得FCN-8具備較強的特征提取能力,
UNet
- 早期基于深度學習的影像分割以FCN為核心,旨在重點解決如何更好從卷積下采樣中恢復丟掉的資訊損失,后來逐漸形成了以UNet為核心的這樣一種編解碼對稱的U形結構,UNet結構能夠在分割界具有一統之勢,最根本的還是其效果好,尤其是在醫學影像領域,所以,做醫學影像相關的深度學習應用時,一定都用過UNet,而且最原始的UNet一般都會有一個不錯的baseline表現,2015年發表UNet的MICCAI,是目前醫學影像分析領域最頂級的國際會議,UNet為什么在醫學上效果這么好非常值得探討一番,U-Net結構如下圖所示:
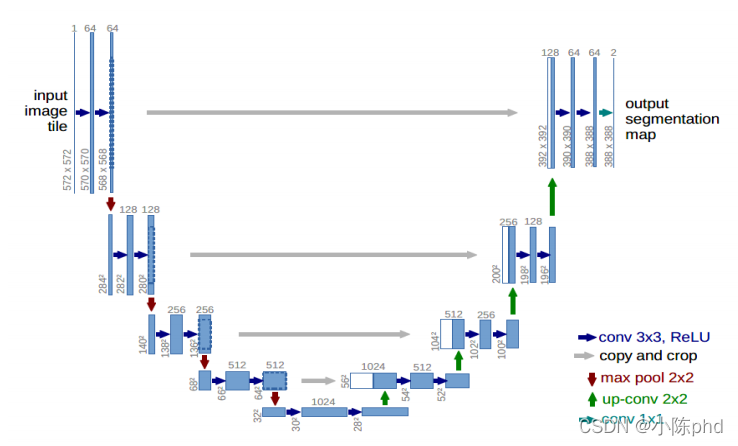
乍一看很復雜,U形結構下貌似有很多細節問題,我們來把UNet簡化一下,如下圖所示:
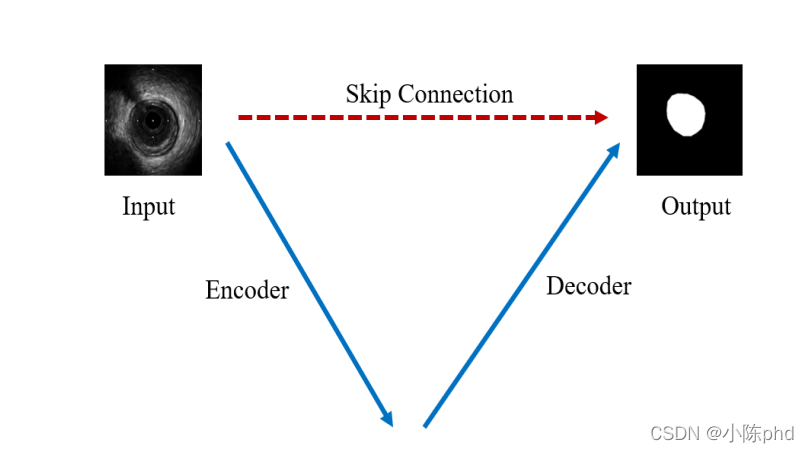
從圖中可以看到,簡化之后的UNet的關鍵點只有三條線: - 下采樣編碼
- 上采樣解碼
- 跳躍連接
下采樣進行資訊濃縮和上采樣進行像素恢復
UNet進行了4次的最大池化下采樣,每一次采樣后都使用了卷積進行資訊提取得到特征圖,然后再經過4次上采樣恢復輸入像素尺寸,
但UNet最關鍵的、也是最特色的部分在于圖中紅色虛線的Skip Connection,
特點:每一次下采樣都會有一個跳躍連接與對應的上采樣進行級聯,這種不同尺度的特征融合對上采樣恢復像素大有幫助,具體來說就是高層(淺層)下采樣倍數小,特征圖具備更加細致的圖特征,底層(深層)下采樣倍數大,資訊經過大量濃縮,空間損失大,但有助于目標區域(分類)判斷,當high level和low level的特征進行融合時,分割效果往往會非常好,
import torch
from torch.nn import functional as F
class CNNLayer(torch.nn.Module):
def __init__(self, C_in, C_out):
'''
卷積層
:param C_in:
:param C_out:
'''
super(CNNLayer, self).__init__()
self.layer = torch.nn.Sequential(
torch.nn.Conv2d(C_in, C_out, kernel_size=(3,3), stride=(1,1), padding=(1,1)),
torch.nn.BatchNorm2d(C_out),
torch.nn.Dropout(0.3),
torch.nn.LeakyReLU(),
torch.nn.Conv2d(C_out, C_out, kernel_size=(3,3), stride=(1,1), padding=(1,1)),
torch.nn.BatchNorm2d(C_out),
torch.nn.Dropout(0.4),
torch.nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class DownSampling(torch.nn.Module):
def __init__(self, C):
'''
下采樣
:param C:
'''
super(DownSampling, self).__init__()
self.layer = torch.nn.Sequential(
torch.nn.Conv2d(C, C,kernel_size=(3,3), stride=(2,2), padding=(1,1)),
torch.nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class UpSampling(torch.nn.Module):
def __init__(self, C):
'''
上采樣
:param C:
'''
super(UpSampling, self).__init__()
self.C = torch.nn.Conv2d(C, C // 2, kernel_size=(1,1), stride=(1,1))
def forward(self, x, r):
up = F.interpolate(x, scale_factor=2, mode='nearest')
x = self.C(up)
return torch.cat((x, r), 1)
class Unet(torch.nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.C1 = CNNLayer(3, 64)
self.D1 = DownSampling(64)
self.C2 = CNNLayer(64, 128)
self.D2 = DownSampling(128)
self.C3 = CNNLayer(128, 256)
self.D3 = DownSampling(256)
self.C4 = CNNLayer(256, 512)
self.D4 = DownSampling(512)
self.C5 = CNNLayer(512, 1024)
self.U1 = UpSampling(1024)
self.C6 = CNNLayer(1024, 512)
self.U2 = UpSampling(512)
self.C7 = CNNLayer(512, 256)
self.U3 = UpSampling(256)
self.C8 = CNNLayer(256, 128)
self.U4 = UpSampling(128)
self.C9 = CNNLayer(128, 64)
self.pre = torch.nn.Conv2d(64, 3, kernel_size=(3,3), stride=(1,1), padding=(1,1))
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
'''
U型結構
:param x:
:return:
'''
R1 = self.C1(x)
R2 = self.C2(self.D1(R1))
R3 = self.C3(self.D2(R2))
R4 = self.C4(self.D3(R3))
Y1 = self.C5(self.D4(R4))
O1 = self.C6(self.U1(Y1, R4))
O2 = self.C7(self.U2(O1, R3))
O3 = self.C8(self.U3(O2, R2))
O4 = self.C9(self.U4(O3, R1))
return self.sigmoid(self.pre(O4))
if __name__ == '__main__':
a = torch.randn(2, 3, 256, 256) #.cuda()
net = Unet() #.cuda()
print(net(a).shape)
顯著性目標檢測/影像分割 U2net
- 更強的連接
- 套娃無止境
- 每一層其實都可以作為一個單層模型進行訓練計算
- 訓練速度快,精度高,建議使用
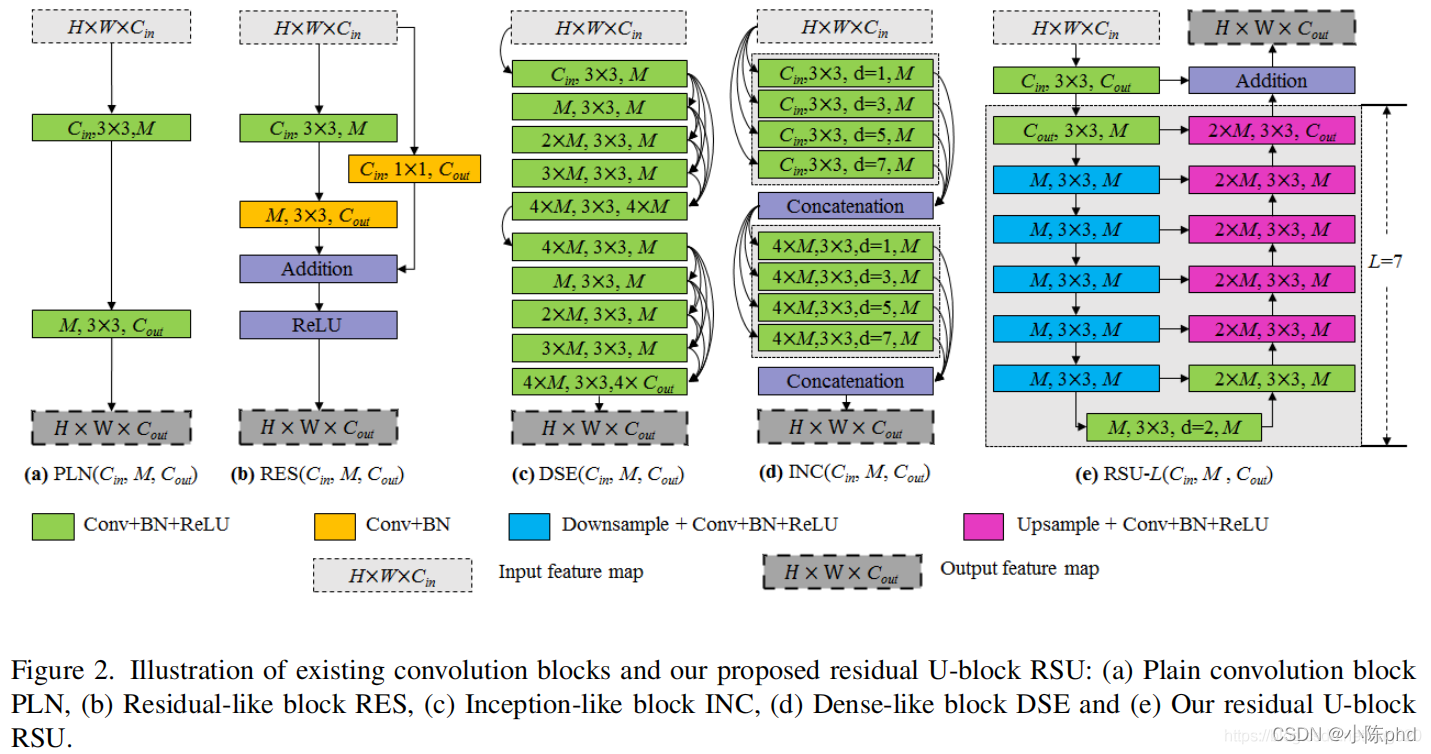
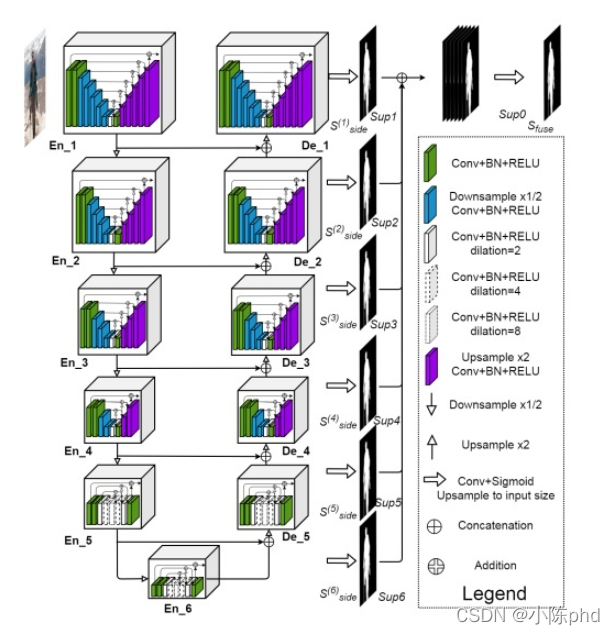
- pytorch實作代碼如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class REBNCONV(nn.Module):
def __init__(self, in_ch=3, out_ch=3, dirate=1):
super(REBNCONV, self).__init__()
self.conv_s1 = nn.Conv2d(in_ch, out_ch, kernel_size=(3, 3), padding=(1 * dirate, 1 * dirate),
dilation=(1 * dirate, 1 * dirate))
self.bn_s1 = nn.BatchNorm2d(out_ch)
self.relu_s1 = nn.ReLU(inplace=True)
def forward(self, x):
hx = x
xout = self.relu_s1(self.bn_s1(self.conv_s1(hx)))
return xout
## upsample tensor 'src' to have the same spatial size with tensor 'tar'
def _upsample_like(src, tar):
'''
:param src:
:param tar:
:return:
'''
src = F.interpolate(src, size=tar.shape[2:], mode='bilinear', align_corners=True)
return src
### RSU-7 ###
class RSU7(nn.Module): # UNet07DRES(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU7, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv7 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv6d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv5d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx = self.pool4(hx4)
hx5 = self.rebnconv5(hx)
hx = self.pool5(hx5)
hx6 = self.rebnconv6(hx)
hx7 = self.rebnconv7(hx6)
hx6d = self.rebnconv6d(torch.cat((hx7, hx6), 1))
hx6dup = _upsample_like(hx6d, hx5)
hx5d = self.rebnconv5d(torch.cat((hx6dup, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
### RSU-6 ###
class RSU6(nn.Module): # UNet06DRES(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU6, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv5d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx = self.pool4(hx4)
hx5 = self.rebnconv5(hx)
hx6 = self.rebnconv6(hx5)
hx5d = self.rebnconv5d(torch.cat((hx6, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
### RSU-5 ###
class RSU5(nn.Module): # UNet05DRES(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU5, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx5 = self.rebnconv5(hx4)
hx4d = self.rebnconv4d(torch.cat((hx5, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
### RSU-4 ###
class RSU4(nn.Module): # UNet04DRES(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU4, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx4 = self.rebnconv4(hx3)
hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
### RSU-4F ###
class RSU4F(nn.Module): # UNet04FRES(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU4F, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=4)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=8)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=4)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=2)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx2 = self.rebnconv2(hx1)
hx3 = self.rebnconv3(hx2)
hx4 = self.rebnconv4(hx3)
hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1))
hx2d = self.rebnconv2d(torch.cat((hx3d, hx2), 1))
hx1d = self.rebnconv1d(torch.cat((hx2d, hx1), 1))
return hx1d + hxin
##### U^2-Net ####
class U2NET(nn.Module):
def __init__(self, in_ch=3, out_ch=1):
super(U2NET, self).__init__()
self.stage1 = RSU7(in_ch, 32, 64)
self.pool12 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage2 = RSU6(64, 32, 128)
self.pool23 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage3 = RSU5(128, 64, 256)
self.pool34 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage4 = RSU4(256, 128, 512)
self.pool45 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage5 = RSU4F(512, 256, 512)
self.pool56 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage6 = RSU4F(512, 256, 512)
# decoder
self.stage5d = RSU4F(1024, 256, 512)
self.stage4d = RSU4(1024, 128, 256)
self.stage3d = RSU5(512, 64, 128)
self.stage2d = RSU6(256, 32, 64)
self.stage1d = RSU7(128, 16, 64)
self.side1 = nn.Conv2d(64, out_ch, kernel_size=(3, 3), padding=(1, 1))
self.side2 = nn.Conv2d(64, out_ch, kernel_size=(3, 3), padding=(1, 1))
self.side3 = nn.Conv2d(128, out_ch, kernel_size=(3, 3), padding=(1, 1))
self.side4 = nn.Conv2d(256, out_ch, kernel_size=(3, 3), padding=(1, 1))
self.side5 = nn.Conv2d(512, out_ch, kernel_size=(3, 3), padding=(1, 1))
self.side6 = nn.Conv2d(512, out_ch, kernel_size=(3, 3), padding=(1, 1))
self.outconv = nn.Conv2d(6, out_ch, kernel_size=(1, 1))
def forward(self, x):
hx = x
# stage 1
hx1 = self.stage1(hx)
hx = self.pool12(hx1)
# stage 2
hx2 = self.stage2(hx)
hx = self.pool23(hx2)
# stage 3
hx3 = self.stage3(hx)
hx = self.pool34(hx3)
# stage 4
hx4 = self.stage4(hx)
hx = self.pool45(hx4)
# stage 5
hx5 = self.stage5(hx)
hx = self.pool56(hx5)
# stage 6
hx6 = self.stage6(hx)
hx6up = _upsample_like(hx6, hx5)
# -------------------- decoder --------------------
hx5d = self.stage5d(torch.cat((hx6up, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.stage4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.stage3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.stage2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.stage1d(torch.cat((hx2dup, hx1), 1))
# side output
d1 = self.side1(hx1d)
d2 = self.side2(hx2d)
d2 = _upsample_like(d2, d1)
d3 = self.side3(hx3d)
d3 = _upsample_like(d3, d1)
d4 = self.side4(hx4d)
d4 = _upsample_like(d4, d1)
d5 = self.side5(hx5d)
d5 = _upsample_like(d5, d1)
d6 = self.side6(hx6)
d6 = _upsample_like(d6, d1)
d0 = self.outconv(torch.cat((d1, d2, d3, d4, d5, d6), 1))
return torch.sigmoid(d0), torch.sigmoid(d1), torch.sigmoid(d2), torch.sigmoid(d3), torch.sigmoid(
d4), torch.sigmoid(d5), torch.sigmoid(d6)
### U^2-Net small ###
class U2NETP(nn.Module):
def __init__(self, in_ch=3, out_ch=1):
super(U2NETP, self).__init__()
# 左一
self.stage1 = RSU7(in_ch, 16, 64)
self.pool12 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# 左2
self.stage2 = RSU6(64, 16, 64)
self.pool23 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# 左3
self.stage3 = RSU5(64, 16, 64)
self.pool34 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# 左4
self.stage4 = RSU4(64, 16, 64)
self.pool45 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# 左5
self.stage5 = RSU4F(64, 16, 64)
self.pool56 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
# 左6
self.stage6 = RSU4F(64, 16, 64)
# decoder
self.stage5d = RSU4F(128, 16, 64)
self.stage4d = RSU4(128, 16, 64)
self.stage3d = RSU5(128, 16, 64)
self.stage2d = RSU6(128, 16, 64)
self.stage1d = RSU7(128, 16, 64)
self.side1 = nn.Conv2d(64, out_ch, (3, 3), padding=(1, 1))
self.side2 = nn.Conv2d(64, out_ch, (3, 3), padding=(1, 1))
self.side3 = nn.Conv2d(64, out_ch, (3, 3), padding=(1, 1))
self.side4 = nn.Conv2d(64, out_ch, (3, 3), padding=(1, 1))
self.side5 = nn.Conv2d(64, out_ch, (3, 3), padding=(1, 1))
self.side6 = nn.Conv2d(64, out_ch, (3, 3), padding=(1, 1))
self.outconv = nn.Conv2d(6, out_ch, kernel_size=(1, 1))
def forward(self, x):
hx = x
# stage 1
hx1 = self.stage1(hx)
hx = self.pool12(hx1)
# stage 2
hx2 = self.stage2(hx)
hx = self.pool23(hx2)
# stage 3
hx3 = self.stage3(hx)
hx = self.pool34(hx3)
# stage 4
hx4 = self.stage4(hx)
hx = self.pool45(hx4)
# stage 5
hx5 = self.stage5(hx)
hx = self.pool56(hx5)
# stage 6
hx6 = self.stage6(hx)
hx6up = _upsample_like(hx6, hx5)
# decoder
hx5d = self.stage5d(torch.cat((hx6up, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.stage4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.stage3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.stage2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.stage1d(torch.cat((hx2dup, hx1), 1))
# side output
d1 = self.side1(hx1d)
d2 = self.side2(hx2d)
d2 = _upsample_like(d2, d1)
d3 = self.side3(hx3d)
d3 = _upsample_like(d3, d1)
d4 = self.side4(hx4d)
d4 = _upsample_like(d4, d1)
d5 = self.side5(hx5d)
d5 = _upsample_like(d5, d1)
d6 = self.side6(hx6)
d6 = _upsample_like(d6, d1)
d0 = self.outconv(torch.cat((d1, d2, d3, d4, d5, d6), 1))
return torch.sigmoid(d0), torch.sigmoid(d1), torch.sigmoid(d2), torch.sigmoid(d3), torch.sigmoid(
d4), torch.sigmoid(d5), torch.sigmoid(d6)
if __name__ == '__main__':
model = U2NET(in_ch=3, out_ch=1)
print(model)
x = torch.randn(1, 3, 224, 224)
print(model(x)[0].shape)
SegNet
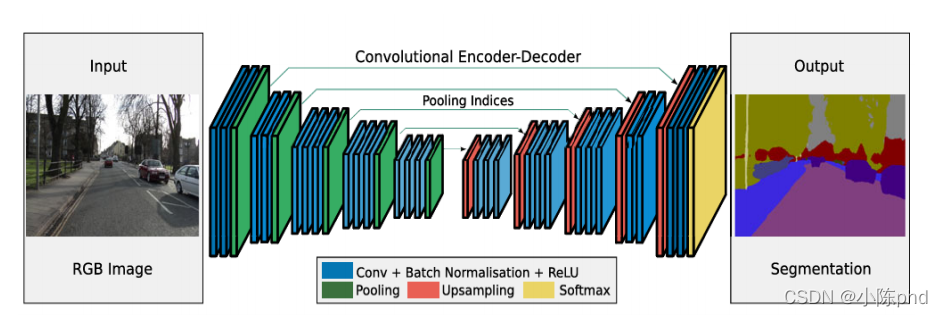
SegNet網路是典型的編碼-解碼結構,SegNet編碼器網路由VGG16的前13個卷積層構成,所以通常是使用VGG16的預訓練權重來進行初始化,每個編碼器層都有一個對應的解碼器層,因此解碼器層也有13層,編碼器最后的輸出輸入到softmax分類器中,輸出每個像素的類別概率,SegNet如下圖所示,
…實作太簡單,不寫了,以后寫吧
其實還有deeplab系列,也后面補充
現在的影像分割技術常用
- 空洞卷積
- 通過更改空洞數量大小進而來獲取到更大的感受野,感受到全域區域內的影像特征變化
- 編解碼
- encoder - decoder
- 主要是Unet開始之后,現在都使用的是編解碼模式進行影像分割
- encoder - decoder
- skip-connection
- 跳躍連接
- 防止梯度彌散或者梯度爆炸
- 補充尺度資訊中缺少的以前的高頻部分
- 跳躍連接
常用損失函式
損失函式
常用的分類損失均可用作語意分割的損失函式,
最常用的就是交叉熵損失函式,
- 如果只是前景分割,則可以使用二分類的交叉熵損失(Binary CrossEntropy Loss, BCE loss)
- 對于目標物體較小的情況我們可以使用Dice損失
- 對于目標物體類別不均衡的情況可以使用加權的交叉熵損失(Weighted CrossEntropy Loss, WCE Loss),
精度描述
語意分割作為經典的影像分割問題,其本質上還是一種影像像素分類,
語意分割常見的評價指標包括
像素準確率(Pixel Accuracy)
像素準確率跟分類中的準確率含義一樣,即所有分類正確的像素數占全部像素的比例,準確率 ,參考分類演算法
PA的計算公式如下:
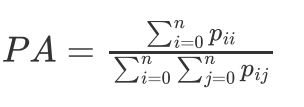
平均像素準確率(Mean Pixel Accuracy)
平均像素準確率(MPA),
平均像素準確率其實更應該叫平均像素精確率,
是指分別計算每個類別分類正確的像素數占所有預測為該類別像素數比例的平均值,
所以,從定義上看,這是精確率(Precision)的定義,MPA的計算公式如下:
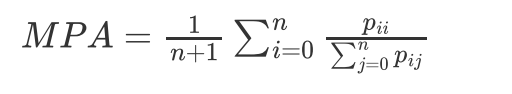
平均交并比(Mean IoU)
平均交并比(MIoU), 交并比(Intersection over Union)的定義很簡單,將標簽影像和預測影像看成是兩個集合,計算兩個集合的交集和并集的比值,而平均交并比則是將所有類的IoU取平均, MIoU的計算公式如下:
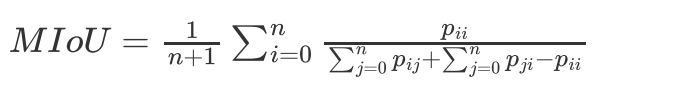
頻權交并比(FWIoU)
- 針對資料集不均衡的情況下,特別關注某類或者某幾類
頻權交并比(FWIoU), 頻權交并比顧名思義,就是以每一類別的頻率為權重和其IoU加權計算出來的結果,FWIoU的設計思想很明確,語意分割很多時候會面臨影像中各目標類別不平衡的情況,對各類別IoU直接求平均不是很合理,所以考慮各類別的權重就非常重要了,FWIoU的計算公式如下:
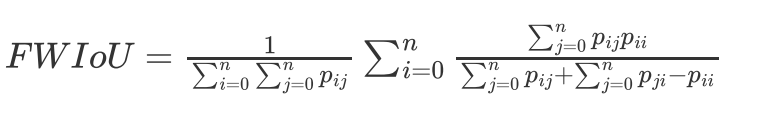
Dice系數(Dice Coeffcient)
Dice系數, Dice系數是一種度量兩個集合相似性的函式,是語意分割中最常用的評價指標之一,Dice系數定義為兩倍的交集除以像素和,跟IoU有點類似,其計算公式如下:
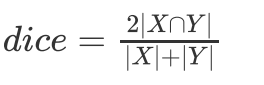
dice本質上跟分類指標中的F1-Score類似,作為最常用的分割指標之一,實作方式 如下:
import torch
def dice_coef(pred, target):
""" Dice = (2*|X & Y|)/ (|X|+ |Y|) = 2*sum(|A*B|)/(sum(A^2)+sum(B^2)) """
smooth = 1.
m1 = pred.reshape(-1).float()
m2 = target.reshape(-1).float()
intersection = (m1 * m2).sum().float()
dice = (2. * intersection + smooth) / (torch.sum(m1*m1) + torch.sum(m2*m2) + smooth)
return dice
參考:深度學習分割理論.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375074.html
標籤:其他
下一篇:OpenCV基礎API函式三