目錄
實驗環境
實驗目錄
準備作業
安裝步驟
jdk安裝
安裝hadoop
偽分布式配置
實驗環境
- Windows10+Centos7+Linux+Mobaxterm
實驗目錄
- 準備作業
- 實驗步驟
準備作業
- jdk-8u171-linux-x64.tar.gz和hadoop-2.7.3.tar.gz
安裝步驟
jdk安裝
- 在根目錄下創建tools目錄和training目錄,執行:
mkdir tools mkdir training - 將jdk-8u171-linux-x64.tar.gz上傳至/tools/目錄下
- 進入/tools/目錄下將其解壓至/training/目錄下,執行:
tar -zvxf jdk-8u171-linux-x64.tar.gz -C /training/ - 配置環境變數,執行:
vi ~/.bash_profile -
添加如下內容:
#JAVA export JAVA_HOME=/training/jdk1.8.0_171 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin; - 使環境生效,執行:
source ~/.bash_profile -
驗證jdk是否安裝成功,執行:
java -version -
設定虛擬機主機名,執行:
hostnamectl --static set-hostname hadoop001 -
虛擬機中配置主機名與虛擬機之間的映射關系,執行:
vi /etc/hosts -
在檔案末尾添加類似于:192.168.88.100 hadoop001(也就是ip地址加虛擬機名稱)
-
Windows系統下配置映射關系,進入到C:\Windows\System32\drivers\etc檔案夾下,找到hosts檔案,用記事本打開(以管理員身份運行),在末尾添加類似于:192.168.88.100 hadoop001(也就是ip地址加虛擬機名稱)
-
關閉防火墻
systemctl status firewalld.service systemctl stop firewalld.service systemctl disable firewalld.service -
配置免密登錄,執行:
ssh-keygen -t rsa (執行命令后,只需敲三次回車鍵) cd ~/.ssh/ ssh-copy-id -i id_rsa.pub root@hadoop001
安裝hadoop
- 將hadoop-2.7.3.tar.gz上傳至/tools/目錄下
- 進入/tools/目錄下將其解壓至/training/目錄下,執行:
tar -zvxf hadoop-2.7.3.tar.gz -C /training/ - 配置環境變數,執行:
vi ~/.bash_profile -
添加如下內容
#HADOOP export HADOOP_HOME=/training/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin - 使環境生效,執行:
source ~/.bash_profile -
驗證hadoop是否安裝成功,執行:hdfs或hadoop
偽分布式配置
- 在/training/hadoop-2.7.3目錄下新建tmp,執行:
mkdir tmp - 進入/training/hadoop-2.7.3/etc/hadoop目錄下,配置以下hadoop組態檔:
hadoop-env.sh hdfs-site.xml core-site.xml mapred-site.xml yarn-site.xml - 配置hadoop-env.sh檔案,修改JAVA_HOME內容:
export JAVA_HOME=/training/jdk1.8.0_171 -
配置hdfs-site.xml檔案,在<configuration></configuration>之間添加:
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> -
配置core-site.xml檔案,在<configuration></configuration>之間添加:
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop001:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/training/hadoop-2.7.3/tmp</value> </property> -
配置mapred-site.xml檔案,在<configuration></configuration>之間添加:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 歷史服務器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop001:10020</value> </property> <!-- 歷史服務器 web 端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop001:19888</value> </property> - 配置yarn-site.xml檔案,在<configuration></configuration>之間添加:
<!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop001</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留時間設定7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!--配置Log Server --> <property> <name>yarn.log.server.url</name> <value>http://hadoop001:19888/jobhistory/logs</value> </property> -
格式化hdfs,執行:
hdfs namenode -format -
進入/training/hadoop-2.7.3/sbin目錄下啟動hadoop環境,執行:
start-all.sh -
進入/training/hadoop-2.7.3目錄下啟動mr歷史服務,執行:
mr-jobhistory-daemon.sh start historyserver - web界面進行驗證,使用瀏覽器訪問以下兩個地址:
# 訪問HDFS: http://hadoop001:50070 # 訪問Yarn: http://hadoop001:8088
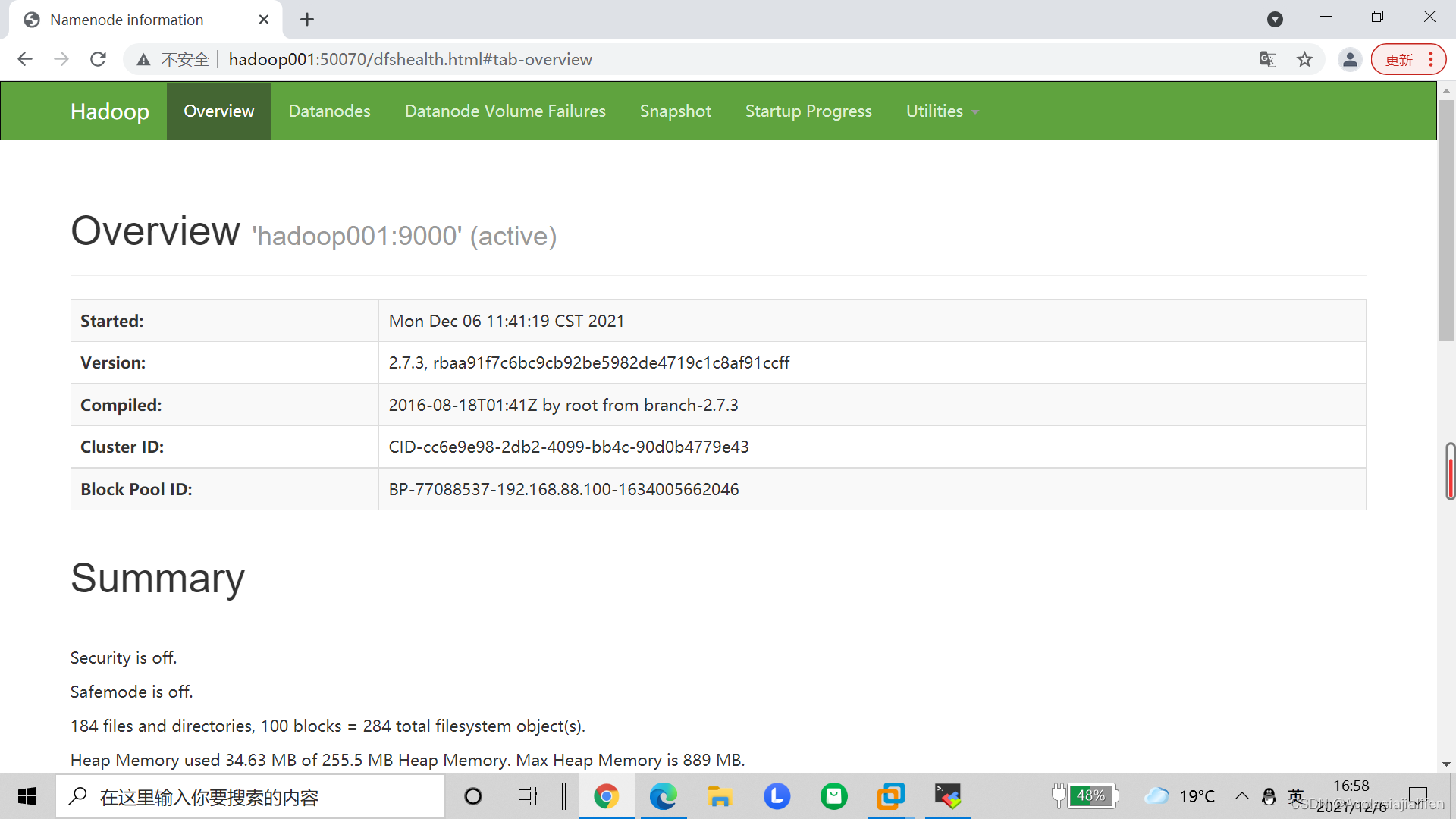
正常會出現:
hdfs:
Yarn:
此后使用jps命令,查看是否有以下行程:
NameNode
DataNode
SecondaryNameNode
ReourceManager
NodeManagerok,小主人,恭喜你,到這里你應該配置完成啦!
注意:本文參考其他博客,如有錯誤,請指正,非常感謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375089.html
標籤:其他
下一篇:hadoop環境搭建(一)