前言
上一章為大家介紹過深度學習的基礎和多層感知機 MLP 的應用,本章開始將深入講解卷積神經網路的實用場景,
卷積神經網路 CNN(Convolutional Neural Networks,ConvNet)是一種特殊的深度學習神經網路,近年來在物體識別、影像重繪、視頻分析等多個層面得到了廣泛的應用,
本文將以VGG16預訓練模型為例子,從人臉識別、預訓練模型、圖片風格遷移、濾波分析、熱力圖等多過領域介紹 CNN 的應用,
目錄
一、卷積神經網路的原理
二、構建第一個 CNN 對 MNIST 數字進行分類
三、利用 CNN 進行人臉識別
四、使用 VGG16 框架的預訓練模型
五、CNN 中間激活層輸出圖
六、CNN 濾波器的可視化輸出
七、CNN 熱力圖
一、卷積神經網路的原理
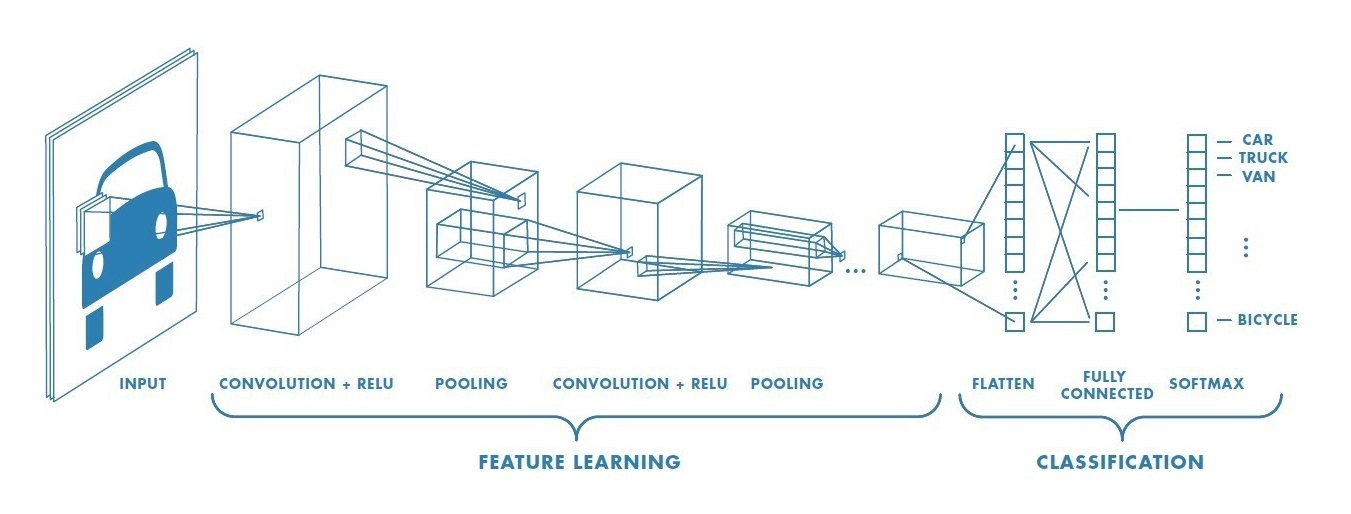
卷積神經網路 CNN 是由多個塊組成,每個塊都具有兩種層:卷積層 Conv 和池化層 Pooling,卷積層 Conv 通過卷積核(也稱濾波器)進行卷積運算后,由激活函式輸出到池化層,再通過池化運算,如此迭代多次后,由最后的一個塊通過輸出層全連接進行資料輸出,完成卷積神經網路的整個程序(如下圖),
可能聽起來可能有點復雜,其實可以把 “卷積層 ——> 激活層 ——> 池化層” 作為一個重復塊看待,經過多層重復后再由全連接輸出,下面將從卷積層和池化層兩個方面分別介紹 CNN 流程,
1.1 卷積層
1.1.1 濾波器(卷積核)
假設在卷積層中,有一個 1*6*6 的圖形作為輸入資料,這里把它稱為輸入特征圖,它經過一個 3*3 的濾波器(也被稱為卷積核)進行卷積運算,即從 input 左上角 3*3 的受野區開始計算其張量積,每完成一次計算向右移動,步幅為1,完成此計算后,就會得出一個 1*4*4 的輸出特征圖(如下圖),
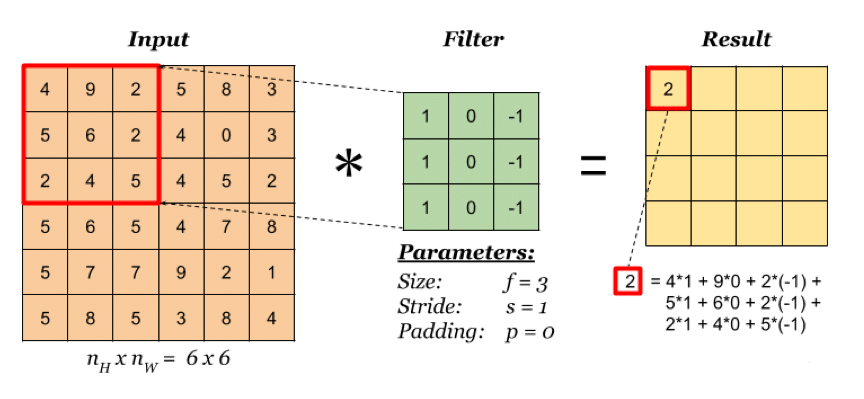
卷積核的形狀必須大于等于 2 * 2 ,一般為 3*3 或者 5*5,其步幅可以自定義,一般為 1,如果卷積核步幅為 3,那么一個輸入特征圖為1*6*6經過步幅為3的3*3卷積核后,輸出特征圖就會變為 1*2*2, 如此類推,
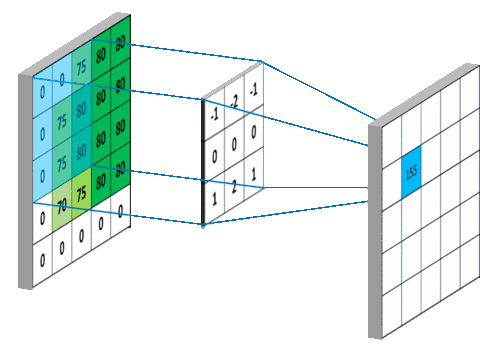
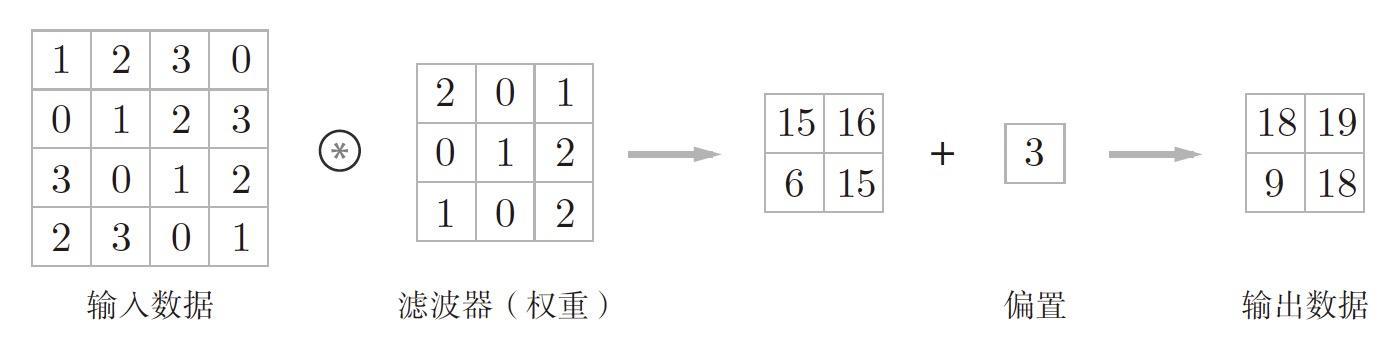
1.1.2 偏置值
正如正常等式 f(x)=w*x+h 一樣,卷積運算也有偏置值,偏置值的運算就是為每個值都加上此張量,如果下圖
1.1.3 填充
經過卷積核運算后,輸出特征圖會比輸入特征圖維度少2,也就是一個1*3*3 的輸入特征圖與一個步幅為1的3*3卷積核運算后,會得出一個 1*1*1 的輸出特征圖,然而,這時候如果需要得出一個1*3*3 的輸出特征圖,只需要把 padding 引數設定為 same,系統就會自動把輸入稱征圖變形狀為 1*5*5,用 0 來填充再進行運行,
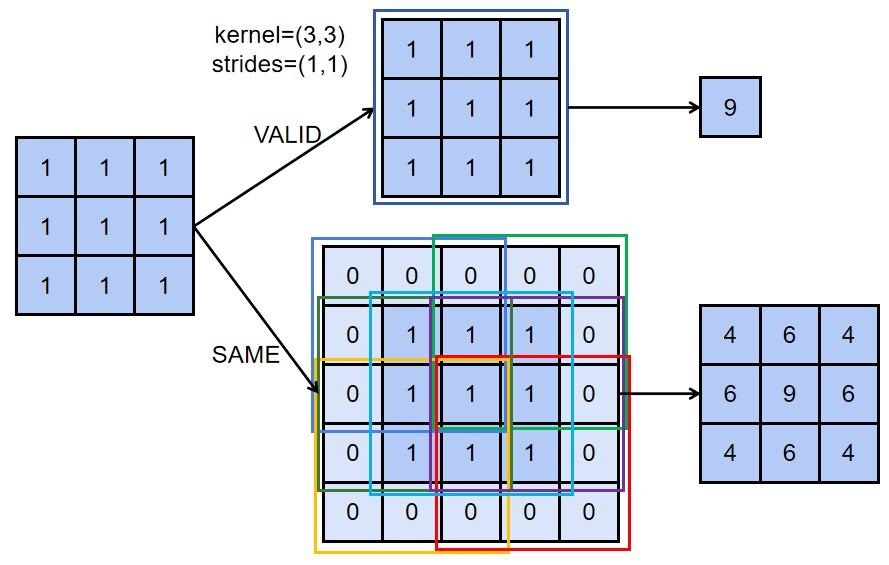
1.1.4 三維資料卷積運算
上圖所介紹的都是二維資料的卷積運算,如果遇到影像處理時,例如 RGB 圖片,往往還需要處理一個資料就是通道 channel,一般 RGB 圖片的 channel 數為 3(紅、綠、藍),而 monochrome 圖片的 channel 數為 1,根據格式不同略有差別,因此卷積核有三維資料的運算,當輸入特征圖為三維資料時,其卷積核也會變為三維,并將每個維度的結果相加得出輸出特征輸出圖,
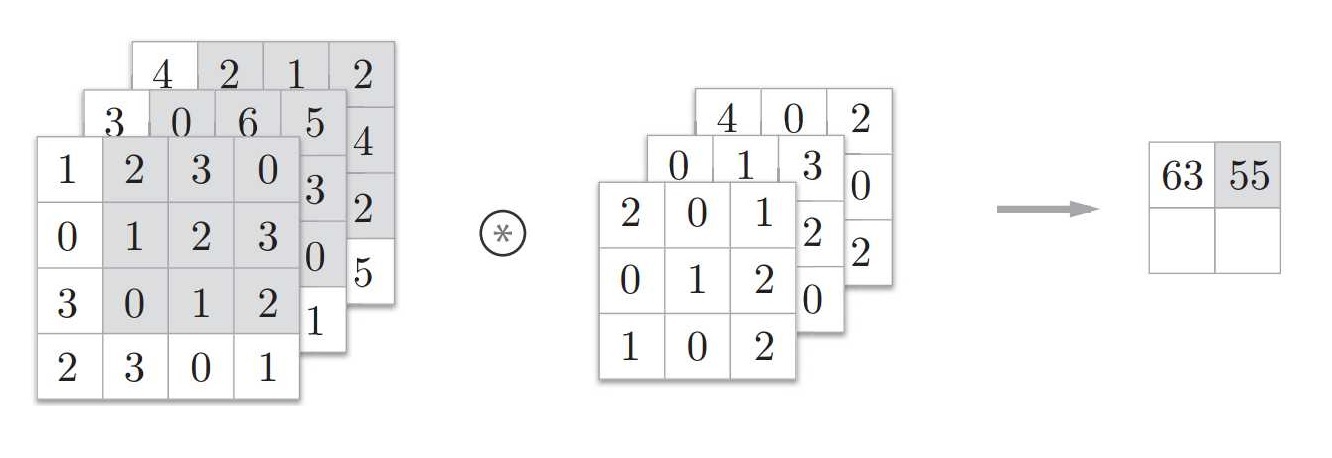
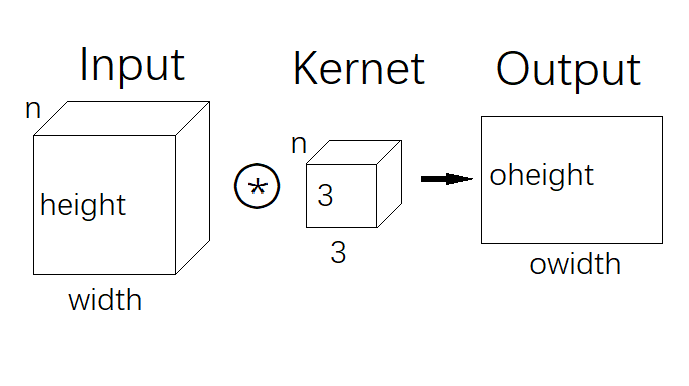
我們可以把這個三維的輸入特征圖看成是一幅 n 個 channel 的圖片輸入操作,如果圖片為 n 個 channel 大小為 width*height 的輸入特征圖,卷積核的形狀是 n*3*3,最后輸出特征圖將是 1*owitdh * oheight ,
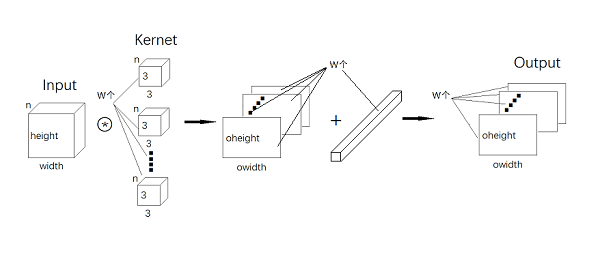
此時,若用到 w 個卷積核,然后再加入 w 個偏置值,那 n 個 channel 大小為 height * width 的輸入特征圖將會輸出 w 層大小為 oheight * owidth 的輸出特征圖
1.1.5 TensorFlow 中的 卷積類 ConvNet
在 TensorFlow 1.x 中需要添加一個卷積層,可使用 tf.nn.conv2d 函式
1 def conv2d_v2(input, filters, strides, padding, 2 data_format="NHWC", dilations=None, 3 name=None):
- input: 型別為 `float32`, `float64`,`int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`其中一種的張量,形狀為 [batch, in_height, in_width, depth],代表輸入的批量資料
- filters: 型別為 float32、float64、halt 的張量,輸入型別與 input 相同,代表卷積核格式,例如 [1,3,3,1]
- strides:int 型別串列,長度為4,用于控制卷積核的移動步幅,與上述引數相同,也是四維的,[1,1,1,1],其中第一個1和最后一個1是固定值,中間的兩個數代表在x軸和y軸的移動步長,
- padding:str 型別 [ SAME','VALID'] 之一,用于選擇填充的演算法,SAME 是填充邊界,VALID 是當不足以移動時直接舍棄,
- data_formate:str型別 [‘NHWC’、'NCHW' ] 之一,默認值為 NHWC,指定輸入和輸出資料的格式,NHWC 時資料格式為 [batch, in_height, in_width, in_channels],NCHW時資料格式為 [batch,in_channels,in_heihgt,in_width]
- dilations:int型別串列,格式必須為 [1, rate_height, rate_width, 1],指定填充邊界時的步幅,當邊界無需填充時,其默認值為 None,當需要填充邊界時,其默認值為 [1,1,1,1]
- name: str 型別,名稱
在 TensorFlow 2.x 中可以直接使用 Conv2D 類,其常用引數與 TensorFlow 1.x 類似,注意資料輸入格式略有不同,
1 class Conv2D(Conv): 2 def __init__(self,filters,kernel_size,strides=(1, 1),padding='valid', 3 data_format=None,dilation_rate=(1, 1),groups=1,activation=None, 4 use_bias=True,kernel_initializer='glorot_uniform',bias_initializer='zeros', 5 kernel_regularizer=None,bias_regularizer=None,activity_regularizer=None, 6 kernel_constraint=None, bias_constraint=None, 7 **kwargs):
- filters:int 型別,代表卷積核的數量
- kernel_size:int 型別串列,形狀 [int,int],代表卷積核的形狀
- strides:int 型別串列,默認值為 (1 , 1 ) 與 tf.nn.conv2d 不同,其形狀為 [int , int ] 二維陣列,用于控制卷積核的移動步幅,
- padding:"valid" 或 "same" (大小寫敏感),用于選擇填充的演算法,same 是填充邊界,valid 是當不足以移動時直接舍棄,
- data_formate:str型別 [ channels_last , channels_first ] 之一,默認值為 channels_last,指定輸入和輸出資料的格式,channels_first 時資料格式為 [batch, channels, height, width],channels_last 時資料格式為 [batch,heihgt,width, in_channels]
- dilations:int型別串列,格式必須為 [ rate_height, rate_width ],默認值為 [1 , 1 ],指定填充邊界時的步幅,
- group: int 型別,默認為1,指定輸入資料中,沿 channel 軸分割的組的數量
- activation: str 型別,默認為 None,要使用的激活函式, 如果你不指定,則不使用激活函式 (即線性激活: a(x) = x),
- use_bias: bool 型別,默認為 True,指該層是否使用偏置向量,
- kernel_initializer: str 型別,默認為 glorot_uniflorm, kernel 權值矩陣的初始化器 (詳見 keras.initializers),
- bias_initializer: str 型別,默認為 zeros ,偏置向量的初始化器 (詳見 keras.initializers) ,
- kernel_regularizer: str 型別,默認為 None,運用到 kernel 權值矩陣的正則化函式 (詳見 keras.regularizers),
- bias_regularizer: 運用到偏置向量的正則化函式 (詳見 keras.regularizers),
- activity_regularizer: 運用到層輸出(它的激活值)的正則化函式 (詳見 keras.regularizers),
- kernel_constraint: 運用到 kernel 權值矩陣的約束函式 (詳見 keras.constraints),
- bias_constraint: 運用到偏置向量的約束函式 (詳見 keras.constraints),
1.2 最大池化層
池化層分為最大池化層 MaxPool 與均值池化層 AvgPool,其實就是縮小width和height的運算,比如按步幅 2 進行 2*2 MaxPool,相當于在 2*2 的區域中獲取最大值運算,取出最大的值,其池化大小往往也步幅相同,即 2 * 2 的池化步幅為2 ,3 * 3 的池化步幅為3,如此類推,
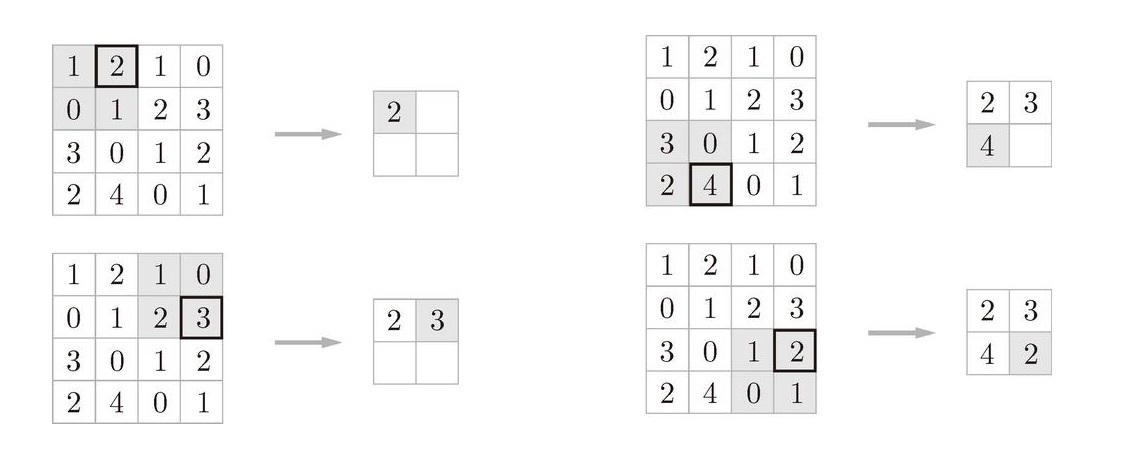
在 TensorFlow 1.x 中需要添加最大池化層,可使用 tf.nn.max_pool 函式
1 def max_pool(value, ksize, strides, padding, 2 data_format="NHWC", name=None, input=None):
- input: 型別為 `float32` 的 4維張量,形狀為 [batch, in_height, in_width, depth],代表輸入的批量資料
- ksize: 型別為 int 的整數串列,代表池化區域的格式,例如 [1 , 2 , 2 , 1]
- strides:int 型別串列,長度為4,用于控制池化的移動步數,與上述引數相同,也是四維的,例如[1,1,1,1],其中第一個1和最后一個1是固定值,中間的兩個數代表在x軸和y軸的移動步長,
- padding:str 型別 [ SAME','VALID'] 之一,用于選擇填充的演算法,SAME 是填充邊界,VALID 是當不足以移動時直接舍棄,
- data_formate:str型別 [‘NHWC’、'NCHW' ] 之一,默認值為 NHWC,指定輸入和輸出資料的格式,NHWC 時資料格式為 [batch, in_height, in_width, in_channels],NCHW時資料格式為 [batch,in_channels,in_heihgt,in_width]
- name: str 型別,名稱
在 TensorFlow 2.x 中可通過 MaxPooling2D 類生成最大池化層
1 class MaxPooling2D(Pooling2D): 2 def __init__(self, pool_size=(2, 2), strides=None, 3 padding='valid', data_format=None, **kwargs):
- pool_size:int 型別的整數串列,長為2,默認為(2,2),代表池化層在兩個方向(豎直,水平)采樣范圍,
- strides:int 型別串列,步長為2的整數串列,默認為 None,用于控制池化的移動步數,當使用 None 時,默認 與pool_size 相同,
- padding:"valid" 或 "same" (大小寫敏感),用于選擇填充的演算法,same 是填充邊界,valid 是當不足以移動時直接舍棄,
- data_format:字串,“channels_first”或“channels_last”之一,代表影像的通道維的位置,默認值為 channels_last,指定輸入和輸出資料的格式,channels_first 時資料格式為 [batch, channels, height, width],channels_last 時資料格式為 [batch,heihgt,width, channels]
1.3 卷積神經網路 CNN 的優勢
對比起多層感知機,卷積神經網路有其天生的優勢,由于多層感知機使用的是全轉接層,因此當輸入圖形資料例如 RGB 圖形為三維形狀時,需要先對影像進行變形,例如常用的 MNIST 28*28*1 的數字,輸入前會先將其轉化為 784 的資料形式,如此一來相當于把所有的神經元看作同一維度處理,這樣會把原有的三維資料間所隱藏的關聯標志,相距像素等重要資訊丟棄,
而從上面的例子可以看到,使用卷積神經網路會以三維資料的形式接收輸入資料,同時以三維的形式輸出到下一層,因此使用 CNN 可以最大程度保存圖形原來的特征,這也是近年來 CNN 被廣泛應用于影像、視頻、人臉識別等領域的原因,
回到目錄
二、構建第一個 CNN 對MNIST 數字進行分類
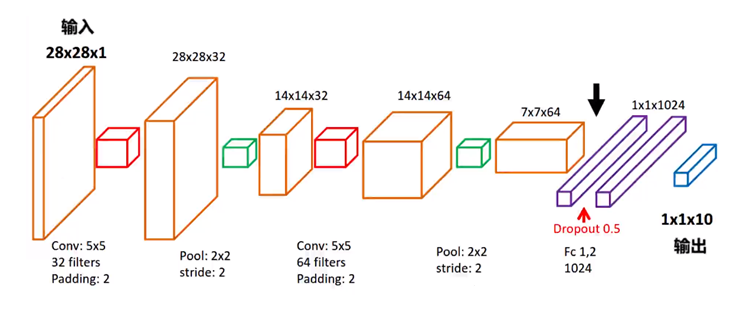
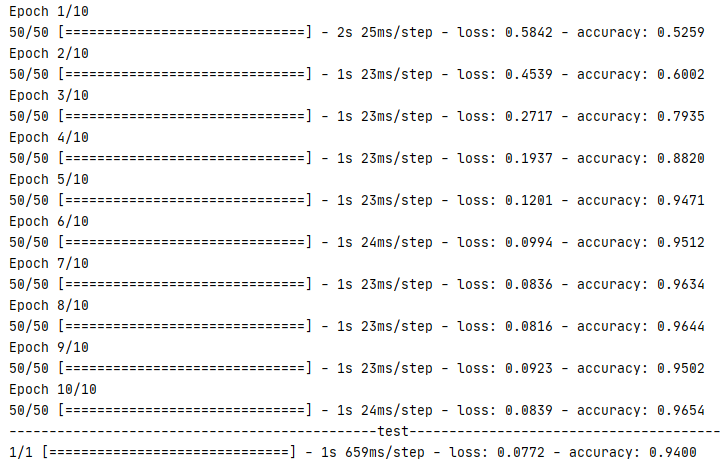
以最簡單的 MNIST 數字集為例字,介紹最基礎的 CNN 應用,輸入 28*28*1 MNIST 資料集,經過 32 個 5*5 的卷積核,池化層形狀為 2*2,使用ReLU輸出后,資料形狀變為 14*14*32,經過64個 5*5 卷積核,池化層形狀為 2*2,使用ReLU輸出后資料形式變為 7*7*64,然后通過 Flatten 把資料拉直,經過三層的全轉接,使用 Adam 模型把輸出數從1024、256、50下降到10,最后輸出層使用 softmax 激活函式輸出,
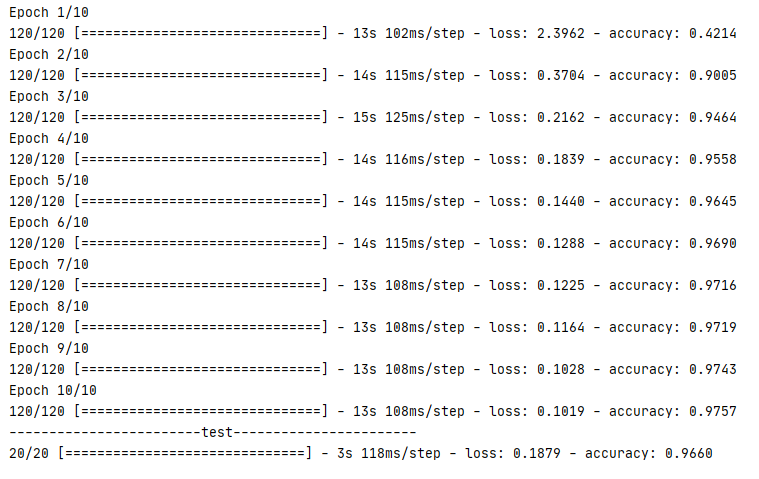
完成訓練后,測驗資料準確率基本保持在 96% 以上
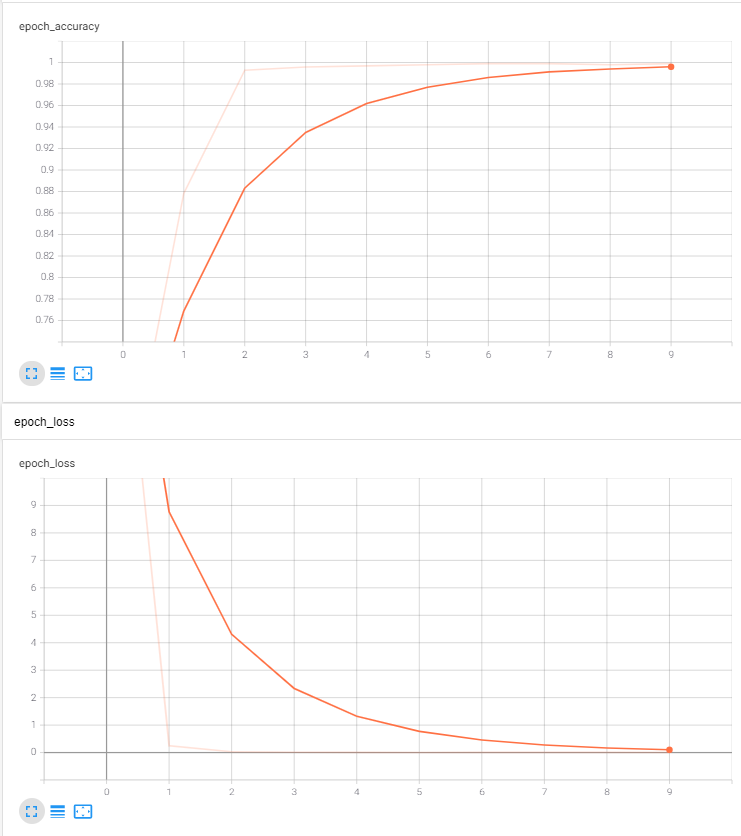
1 def getmodel(): 2 # 生成模型 3 model=models.Sequential() 4 # 32個卷積核形狀為 5*5,激活函式為 relu 5 model.add(layers.Conv2D(filters=32,padding='same',kernel_size=(5,5),activation='relu')) 6 # 池化層,大小2*2 7 model.add(layers.MaxPool2D(2,2)) 8 # 64個卷積核形狀為 5*5,激活函式為 relu 9 model.add(layers.Conv2D(filters=64,padding='same',kernel_size=(5,5),activation='relu')) 10 # 池化層,大小2*2 11 model.add(layers.MaxPool2D(2,2)) 12 # 拉直資料 13 model.add(layers.Flatten()) 14 # 多層 MLP dropout 為 0.5 15 model.add(layers.Dense(1024,activation='relu')) 16 model.add(layers.Dropout(rate=0.5)) 17 model.add(layers.Dense(256,activation='relu')) 18 model.add(layers.Dropout(rate=0.5)) 19 model.add(layers.Dense(50,activation='relu')) 20 model.add(layers.Dropout(rate=0.5)) 21 # 輸出層激活函式為 softmax 22 model.add(layers.Dense(10,activation='softmax')) 23 return model 24 25 def run(X,y,model,epoch=10): 26 # 輸入資料轉換 27 X,_train=convert(X,y) 28 # 生成訓練模型,學習率為0.003 29 model.compile(optimizer=optimizers.Adam(0.003), 30 loss=losses.sparse_categorical_crossentropy, 31 metrics=['accuracy']) 32 # 日志輸出 33 callbacks= keras.callbacks.TensorBoard(log_dir='logs') 34 model.fit(X,y,batch_size=500,epochs=epoch,callbacks=callbacks) 35 return model 36 37 def convert(X,y): 38 # 資料格式轉換 39 X=X.reshape(-1,28,28,1) 40 X=tf.convert_to_tensor(X,tf.float32) 41 y=tf.convert_to_tensor(y,tf.float32) 42 return X,y 43 44 if __name__=='__main__': 45 # 獲取資料集 46 (X_train,y_train),(X_test,y_test)=keras.datasets.mnist.load_data() 47 # 生成模型 48 model=getmodel() 49 # 資料測驗 50 run(X_train,y_train,model) 51 print('------------------------test-----------------------') 52 run(X_test,y_test,model,1)
運行結果
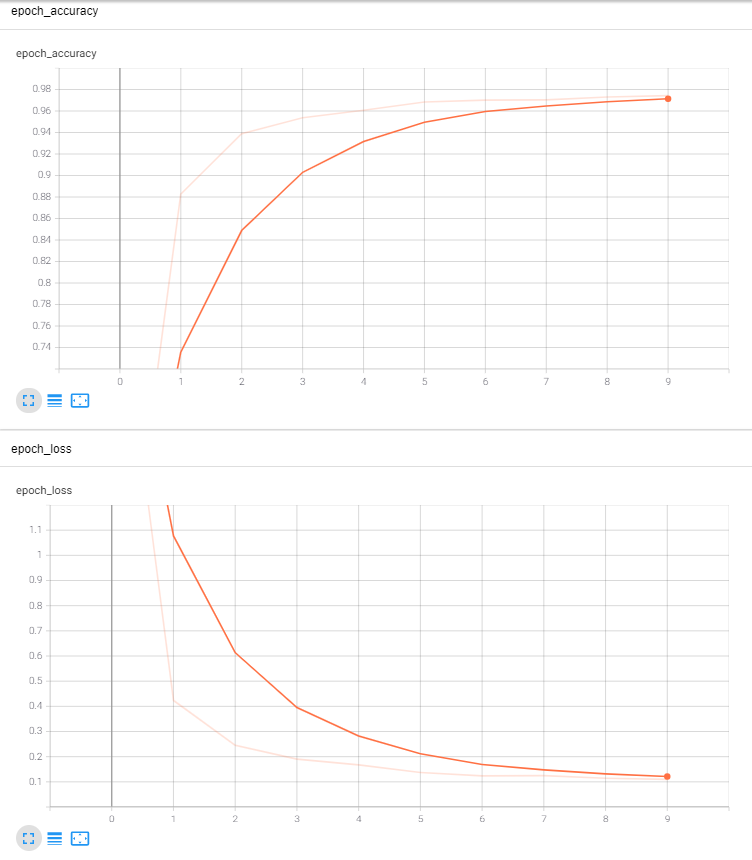
tensorboard 損失函式與正確率變化
回到目錄
三、利用 CNN 進行人臉識別
如今人臉識別是近來最為普及的應用,下面就以此為例介紹 CNN 在人面識別領域的實作方式,這個例子只是基于對 CNN 使用的介紹,實際市場上已經有多個成熟的人臉識別框架可供用戶選擇,
相信大家也感受到在很多手機 APP 中都有著人臉識別登錄的功能,在視頻錄制時都會要求用戶進行張口/閉眼/轉頭等一系列動作,其目的就是進可能地把用戶各個臉面特征收納到云端,然后利用 cv2 把視頻按照幀進行分解,最后對分解的圖片進行學習,
下面假設錄制好的視頻被放到 input 檔案夾中,通過 cv2 函式即可把視頻分解為 jpg 檔案,圖片按 50*70的大小統一放到 pic 檔案夾內,
1 def read(videopath,output): 2 # 讀入視頻檔案 3 vc=cv2.VideoCapture(videopath) 4 # 打開檔案 5 isOpen=vc.isOpened() 6 n=0 7 while(isOpen): 8 # 讀取資料幀 9 rval,frame=vc.read() 10 if rval: 11 img=Image.fromarray(frame) 12 # 圖片剪切 13 img=img.crop((0,100,500,800)) 14 # 圖片保存為 50*70 大小 15 out=img.resize((50,70),Image.ANTIALIAS) 16 path=output+str(n)+'.jpg' 17 out.save(path) 18 n=n+1 19 20 else: 21 break 22 print('success') 23 24 if __name__=='__main__': 25 path='E://Python_Projects/ANN/venv' 26 read(path+'/input/1.mp4',path+'/pic/train/Leslie')
視頻轉化為圖片后,把圖片訓練資料和測驗資料分別放到 train 和 test 檔案夾中,不同人物頭像放到不同子檔案夾,一般用戶注冊時視頻錄制一般不會超過 5 秒,所以轉化后的圖片數量有限,此時可通過 ImageDataGenerator 類得到增強資料集進行訓練,通過 ImageDataGenerator 類可以從變換角度,平移等隨機轉換的方式來增加訓練樣本,從而得到更好的泛化能力,
切記使用 ImageDataGenerator 時,增強資料只適用于訓練資料集,不用于測驗資料集,否則將影響準確率,
1 @keras_export('keras.preprocessing.image.ImageDataGenerator') 2 class ImageDataGenerator(image.ImageDataGenerator): 3 def __init__(self, featurewise_center=False, samplewise_center=False, 4 featurewise_std_normalization=False,samplewise_std_normalization=False, 5 zca_whitening=False, zca_epsilon=1e-6,rotation_range=0, 6 width_shift_range=0., height_shift_range=0., 7 brightness_range=None, shear_range=0., 8 zoom_range=0.,channel_shift_range=0., 9 fill_mode='nearest',cval=0., horizontal_flip=False, 10 vertical_flip=False, rescale=None,preprocessing_function=None, 11 data_format=None, validation_split=0.0,dtype=None): 12 13 def flow_from_directory(self, directory,target_size=(256, 256), 14 color_mode='rgb',classes=None,class_mode='categorical', 15 batch_size=32,shuffle=True, seed=None, 16 save_to_dir=None,save_prefix='', save_format='png', 17 follow_links=False, subset=None,interpolation='nearest'):
__init__建構式引數說明
- featurewise_center:bool 型別,默認為 False ,是否使輸入資料集去中心化(均值為0), 按feature執行
- samplewise_center:bool 型別,默認為 False ,是否使輸入資料的每個樣本均值為0
- featurewise_std_normalization:bool 型別,默認為 False ,是否輸入除以資料集的標準差以完成標準化, 按feature執行
- samplewise_std_normalization:bool 型別,默認為 False ,將輸入的每個樣本除以其自身的標準差
- zca_whitening:bool 型別,默認為 False ,對輸入資料施加 ZCA 白化
- zca_epsilon: float 型別,默認1e-6,ZCA 使用的 eposilon
- rotation_range:int 型別,默認為 0,圖片旋轉角度
- width_shift_rang:float 型別,默認為 0.,圖片平移的比例
- height_shift_rang: float 型別,默認為 0., 圖片垂直移動的比例
- brightness_range:
- shear_range:float 型別,默認為 0.,剪切強度(逆時針方向的剪切變換角度)
- zoom_range:float 型別 或 形如 [lower,upper] 的串列,默認為 0.,隨機縮放的幅度,若為浮點數,則相當于[lower,upper] = [1 - zoom_range, 1+zoom_range]
- channel_shift_range:浮點數,隨機通道偏移的幅度
- horizontal_flip:bool 型別,默認為 False ,是否水平翻轉
- fill_mode:str 型別,[‘constant’,‘nearest’,‘reflect’, ‘wrap’ ] 之一,默認為 ’nearest' ,當進行變換時超出邊界的點將根據本引數給定的方法進行處理
- cval:浮點數或整數,當fill_mode=constant時,指定要向超出邊界的點填充的值
- rescale:默認為None,對圖片縮放處理的比例
- vertical_flip:布林值,進行隨機豎直翻轉
- rescale: 重放縮因子,默認為None. 如果為None或0則不進行放縮,否則會將該數值乘到資料上(在應用其他變換之前)
- preprocessing_function: 將被應用于每個輸入的函式,該函式將在圖片縮放和資料提升之后運行,該函式接受一個引數,為一張圖片(秩為3的numpy array),并且輸出一個具有相同shape的numpy array
- data_format:字串,“channel_first”或“channel_last”之一,代表影像的通道維的位置,該引數是Keras 1.x中的image_dim_ordering,“channel_last”對應原本的“tf”,“channel_first”對應原本的“th”,以128x128的RGB影像為例,“channel_first”應將資料組織為(3,128,128),而“channel_last”應將資料組織為(128,128,3),該引數的默認值是~/.keras/keras.json中設定的值,若從未設定過,則為“channel_last”
flow_from_directory 方法引數說明
- directory: str 型別,目標檔案夾路徑,對于每一個類,該檔案夾都要包含一個子檔案夾.子檔案夾中任何JPG、PNG、BNP、PPM的圖片都會被生成器使用.詳情請查看此腳本
- target_size: int 陣列 [ weight,width ],圖片轉換的像素比例,默認為 [ 256, 256 ]
- color_mode: str 型別,顏色模式,為 [ "grayscale","rgb" ] 之一,默認為"rgb".代表這些圖片是否會被轉換為單通道或三通道的圖片.
- classes: str 型別 可選引數,為子檔案夾的串列,如['dogs','cats']默認為None. 若未提供,則該類別串列將從directory下的子檔案夾名稱/結構自動推斷,每一個子檔案夾都會被認為是一個新的類,(類別的順序將按照字母表順序映射到標簽值),通過屬性class_indices可獲得檔案夾名與類的序號的對應字典,
- class_mode: str 型別 [ "categorical", "binary", "sparse",None] 之一. 默認為"categorical. 該引數決定了回傳的標簽陣列的形式, "categorical"會回傳2D的one-hot編碼標簽,"binary"回傳1D的二值標簽."sparse"回傳1D的整數標簽,如果為None則不回傳任何標簽, 生成器將僅僅生成batch資料, 這種情況在使用model.predict_generator()和model.evaluate_generator()等函式時會用到.
- batch_size: int 型別,batch資料的大小,默認32
- shuffle: bool 型別,是否打亂資料,默認為True
- seed: 可選引數,打亂資料和進行變換時的亂數種子
- save_to_dir: None或 str,該引數能讓你將提升后的圖片保存起來,用以可視化
- save_prefix:str,保存提升后圖片時使用的前綴, 僅當設定了save_to_dir時生效
- save_format:"png"或"jpeg"之一,指定保存圖片的資料格式,默認"jpeg"
- flollow_links: bool 型別,是否訪問子檔案夾中的軟鏈
建立 model 卷積核形狀為 5 *5,數量由 32 個轉化為 64 個轉化為 128 個,使用 Adam 優化器,由于是圖片資料損失函式使用 binary_crossentropy,通過 Flatten 拉直資料后,通過五層 MLP 使用 sigmoid激活函式輸出,dropout 為 50%,
通過訓練后,測驗資料的準確率平均可達90%以上,準確率高主要是因為人臉識別的登錄 / 支付等應用通常都是通過直視鏡頭的方式進行判斷的,所以角度比較固定,對其特征的要求不太高,
然而如果需要進一步對動態圖片進行復雜的辨認,那簡單 CNN 模型的準確率很可能會急速下滑,
1 def getModel(): 2 model=keras.models.Sequential() 3 # 32個卷積核形狀為 5*5,激活函式為 relu 4 model.add(layers.Conv2D(filters=32,kernel_size=(5,5),activation='relu')) 5 # 池化層,大小2*2 6 model.add(layers.MaxPool2D()) 7 # 64個卷積核形狀為 5*5,激活函式為 relu 8 model.add(layers.Conv2D(filters=64,kernel_size=(5,5),activation='relu')) 9 # 池化層,大小2*2 10 model.add(layers.MaxPool2D()) 11 # 128個卷積核形狀為 5*5,激活函式為 relu 12 model.add(layers.Conv2D(filters=128,kernel_size=(5,5),activation='relu')) 13 # 池化層,大小2*2 14 model.add(layers.MaxPool2D()) 15 # 多層 MLP dropout 為 0.5 16 model.add(layers.Flatten()) 17 model.add(layers.Dense(8192,activation='relu')) 18 model.add(layers.Dropout(rate=0.5)) 19 model.add(layers.Dense(1024,activation='relu')) 20 model.add(layers.Dropout(rate=0.5)) 21 model.add(layers.Dense(128,activation='relu')) 22 model.add(layers.Dropout(rate=0.5)) 23 model.add(layers.Dense(60,activation='relu')) 24 model.add(layers.Dense(10,activation='sigmoid')) 25 return model 26 27 def run(generator, model, steps_per_epoch=10,epochs=10): 28 # 生成訓練模型,學習率為0.003 29 model.compile(optimizer=optimizers.Adam(0.001), 30 loss=losses.binary_crossentropy, 31 metrics=['accuracy']) 32 # 分批訓練 33 model.fit(generator,steps_per_epoch=steps_per_epoch,epochs=epochs) 34 35 if __name__=='__main__': 36 # 視頻轉換后的檔案路徑 37 path='E://Python_Projects/ANN/venv/pic/' 38 # 增強的訓練資料 39 trainDataGenerator=ImageDataGenerator(rescale=1./255,rotation_range=50, 40 width_shift_range=0.3,height_shift_range=0.3, 41 shear_range=0.3,zoom_range=0.3,horizontal_flip=True) 42 train_data=https://www.cnblogs.com/leslies2/archive/2021/12/07/trainDataGenerator.flow_from_directory(path+'train', 43 target_size=(70,50),batch_size=20) 44 # 測驗資料 45 testDataGenerator=ImageDataGenerator(rescale=1./255) 46 test_data=https://www.cnblogs.com/leslies2/archive/2021/12/07/testDataGenerator.flow_from_directory(path+'test', 47 target_size=(70,50),batch_size=50) 48 # 資料訓練與測驗 49 model = getModel() 50 run(train_data,model,steps_per_epoch=50) 51 print('-------------------------test------------------------') 52 run(test_data,model,epochs=1)
運行結果
損失函式
以上所介紹的例子,都屬于小型的 CNN 模型,每次創建 model 時都需要手動建立多個 layer ,隨著計算的復雜程度越來越高,需要建立的 layer 也會越來越多,這其實是一件令人煩心的事,
事實上,當遇上大型的資料集時更多情況下會使用預訓練模型來解決,下面將為大家介紹,
回到目錄
四、使用 VGG16 框架預訓練模型
4.1 預訓練模型
小型的 CNN 模型可以通過訓練資料去精準化模型的權重,然而對于一些大型的資料集這可能需要耗費大量的資源,為了可以使模型發揮更高效的作用,于是業內產生預訓練模型這個概念,實際上這是把大量的資料集在網路上完成訓練,并把模型保存,通過云端模式,進行模型共享,只要原始資料集足夠大,那么經過訓練后的模型就可以有效地作為通用模型,
Keras 中早已經包含 VGG16、VGG19、Inception V3、ResNet 50 、AlexNet 等多個模型架構,
完成預訓練的模型可以通過 save_model 函式進行保存
1 @keras_export('keras.models.save_model') 2 def save_model(model, filepath, overwrite=True, 3 include_optimizer=True, save_format=None, 4 signatures=None, options=None, 5 save_traces=True):
- model: 需要保存的模型物件
- filepath: str 型別,需要保存的路徑
- overwrite: bool 型別,是否覆寫原檔案
- include_optimizer:bool 型別,是否包含 optimizer 優化器資料
- save_format:[ ' tf ' , ' h5 ' ] 二者選一,保存方式,tf 用于 tensorflow 2.x,h5 用于 tensorflow 1.x
- singatures:使用 SavedModel 保存的簽名細節,當save_formate 為 ' tf ' 時可用,請參閱' signatures '引數“ tf.saved_model,
- options:tf.saved_model.SaveOptions 物件,僅適用于SavedModel格式,該物件指定保存到 SavedModel 的選項,
- save_traces:bool 型別,默認值為 True,僅適用于SavedModel 格式,SavedModel將存盤每個層的函式軌跡,禁用此功能將減少序列化時間和減少檔案大小,但它要求所有自定義層/模型實作一個 ' get_config() ' 方法,
需要加載時可以通過 load_model 函式進行獲取
1 def load_model(filepath, custom_objects=None, 2 compile=True, options=None):
- filepath: str 型別,model 保存的路徑
- custom_objects:自定義類或函式在反序列化時所映射名稱,
- compile: bool 型別,是否在加載之后編譯模型,
- options:可選的 tf.saved_model,加載 save_model 時從 SavedModel 所保存的 options ,
4.2 VGG 16 模型介紹
VGG 16 是成熟的預訓練模型之一, 它是由 Karen Simonyan 和 Andrew Zisserman 在 2014 年開發的框架,它包含了16 層 ,如下圖,當中包含了多層的卷積、池化層,完成CNN訓練后拉直,最后通過3層全連接輸出, 默認情況下,VGG 16 訓練集中包含了1300,000 張圖片,驗證集中包含了 50,000 張圖片,輸出 1000 類的物品,因此VGG 16 在卷積層保存了大量已通過訓練的向量特征,如果需要添加自定義類別時可以通過自定義的全連接層進行類別的概率分配,
前面曾經介紹過,全連接層會把所有資料看作同一維度處理,這樣會把原有影像的三維資料中所包含的關聯標志,相距像素,位置等重要資訊丟棄,而 VGG 模型的思路正是通過 CNN 的優勢,通過足夠多的訓練集,在卷積層收集大量圖片的位置、像素等向量特征,初始化模型時把訓練過的特征直接加載,用戶可以使用默認的全連接層,也可通過自定義的全連接層,根據物品的出現的概率進行類別分配,
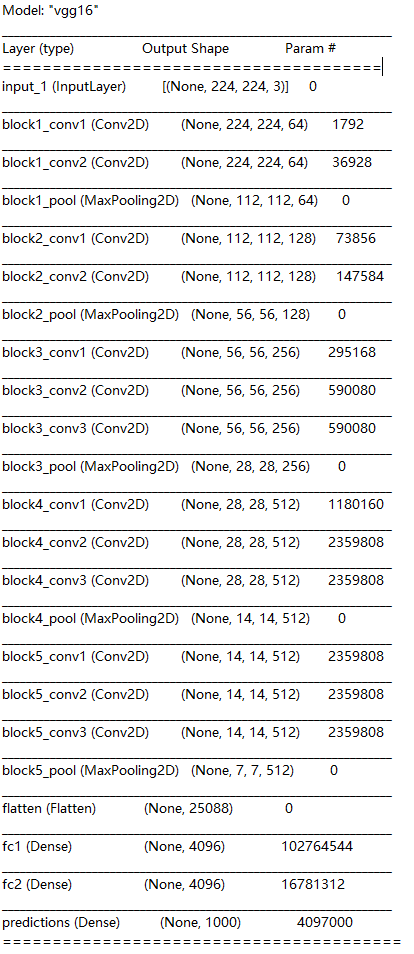
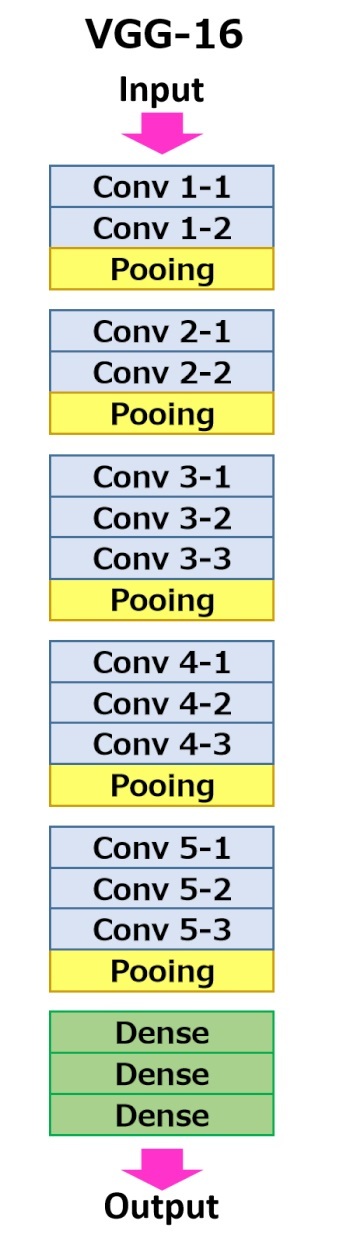
VGG16 函式
1 @keras_export('keras.applications.vgg16.VGG16', 'keras.applications.VGG16') 2 def VGG16( include_top=True, weights='imagenet', 3 input_tensor=None, input_shape=None, 4 pooling=None, classes=1000, 5 classifier_activation='softmax'):
- include_top:bool 型別,默認為 True,指定模型最后是否包含三層全連接分類器,如果使用自定義的全連接層時,可以設定為 False
- weights:str 型別,[ ' None' , 'imagenet ' ] 二選一,默認為 imagenet ,指定初始化時加載模型的權重,None 表示隨機初始化,
- input_tensor:輸入到網路中的 keras 張量格式,
- input_shape:輸入到網路中的影像張量的形狀,這個引數完全是可選的,如果不傳入這個引數,那么網路能夠處理任意形狀的輸入,
- pooling:str 型別,[ ' None ' , ' avg ' , ' max ' ] 三選一,avg 代表使用平均池化,max 代表使用最在池化,' None ' 代表輸出將為四維張量的輸出
- classes:int 型別,表示輸出的分類,默認1000類,只在 include_top 為 True, 而且未指定 weights 為引數時有效
- classifier_activation: str 型別,激活函式,默認使用 softmax
4.3 使用 VGG16 進行特征提取
下面以 kaggle 競賽的 DogVSCat 為例介紹一下 VGG16 的使用方式,先從 kaggle 官網 https://www.kaggle.com/muhammadshahzadkhan/dogvscat 下載圖片資源,當中包括了 train 圖片 2000 張,validation 圖片 1000 張,test 圖片 1000 張,
建立 VGG 16 模型,把 include_top 設定為False 以使用自定義全連接,把 input_shape 輸入張量設定 (256,256,3),
為了在訓練時不影響卷積層,必須先把 VGG16 的 trainable 設定為 False,
利用 ImageDataGenerator 增加訓練資料集,對卷積層輸出資料使用 Flatten 拉直,經過二層全連接,使用 Adam 優化器 sigmoid 激活函式輸出,
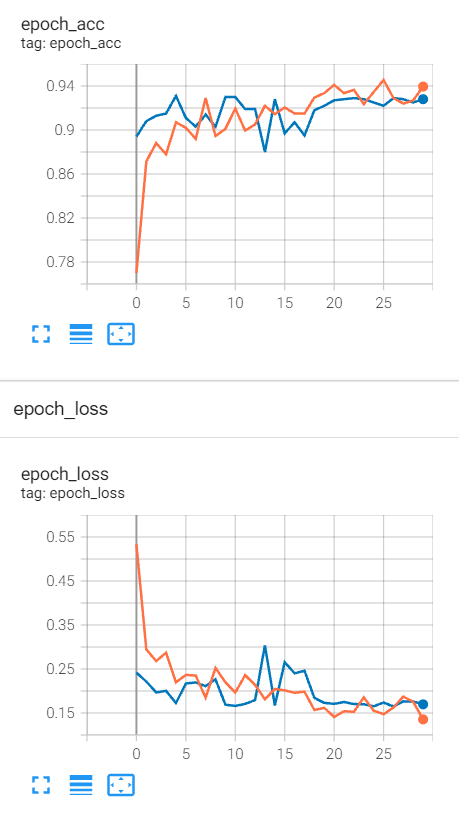
測驗資料集準確率可達到 93% 以上
1 def getModel(): 2 # 獲取 VGG16 模型,把 include_top 設定為 False,使用自定義全連接 3 conv_base=applications.VGG16(weights='imagenet',include_top=False, 4 input_shape=(256,256,3)) 5 # 把 trainable 屬性設計為 False,凍結卷積層權重 6 conv_base.trainable=False 7 # 新建模型,使用 VGG16 的卷積層,拉直后,自定義二層全連接層 8 model=models.Sequential() 9 model.add(conv_base) 10 model.add(layers.Flatten()) 11 model.add(layers.Dense(256,activation='relu')) 12 model.add(layers.Dense(1,activation='sigmoid')) 13 # 顯示模型層特征 14 model.summary() 15 return model 16 17 def test(): 18 # 貓狗圖路徑 19 path='E://Python_Projects/data_test/DogVSCatLit/' 20 # 訓練資料集使用增強資料 21 train=ImageDataGenerator(rescale=1./255,rotation_range=20, 22 width_shift_range=0.2,height_shift_range=0.2, 23 shear_range=0.2,zoom_range=0.2, 24 horizontal_flip=True,fill_mode='nearest') 25 # 驗證資料集和測驗資料使用原資料 26 test=ImageDataGenerator(rescale=1./255) 27 # 圖片統一轉換成 256*256,每批 50個 28 trainData=https://www.cnblogs.com/leslies2/archive/2021/12/07/train.flow_from_directory(path+'train',target_size=(256,256), 29 batch_size=50,class_mode='binary') 30 validationData=https://www.cnblogs.com/leslies2/archive/2021/12/07/test.flow_from_directory(path+'validation',target_size=(256,256), 31 batch_size=50,class_mode='binary') 32 testData=https://www.cnblogs.com/leslies2/archive/2021/12/07/test.flow_from_directory(path+'test',target_size=(256,256), 33 batch_size=50,class_mode='binary') 34 # 獲取模型 35 model=getModel() 36 # 使用 adam 優化器,binary_crossentropy 二進制交叉熵損失函式 37 model.compile(optimizer=optimizers.Adam(3e-4), 38 loss=losses.binary_crossentropy, 39 metrics=['acc']) 40 # 日志記錄 41 callback=callbacks.TensorBoard(log_dir='logs/091902') 42 # 訓練資料 2000 個,每批 50 個,所以 steps_per_epoch 訓練批次為 40 43 # 驗證資料 1000 個,每批 50 個,所以 validation_steps 訓練批次為 20 44 # 重復訓練 30 次 45 model.fit(trainData,steps_per_epoch=40,epochs=30, 46 validation_data=https://www.cnblogs.com/leslies2/archive/2021/12/07/validationData,validation_steps=20, 47 callbacks=callback) 48 print('---------------------------------test---------------------------------------') 49 # 測驗結果 50 model.fit(testData,steps_per_epoch=20) 51 52 if __name__=='__main__': 53 test()
模型層次圖

運行結果
tensorboard
4.4 微調 VGG16 模型
前一節的例子訓練時會將 VGG16 卷積層的模型完全凍結,是為了避免在資料訓練期間,錯誤資訊對已有的模型造成影響,而事實上應用更廣泛的是對模型的最頂的卷積層進行微調,使模型更匹配新輸入的資料,但注意微調一般只針對最頂層的抽象模型,而不適合用于底層,因為這樣做對模型影響過大從而造成誤判,
下面的例子就是對頂層的卷積層 [ 'block5_conv1','block5_conv2','block5_conv3' ,‘block5_pool’] 進行解凍,加入微調訓練,輸出后拉直進入三層全連接層,防止過擬合加入 dropout 層,丟失率設定為 0.3,運行后測驗資料的準確率上升到 95%以上,
1 def getModel(): 2 # 獲取 VGG16 模型,把 include_top 設定為 False,使用自定義全連接, 平均值池化 3 conv_base=applications.VGG16(weights='imagenet',include_top=False, 4 input_shape=(256,256,3)) 5 # 把 trainable 屬性設計為 False,凍結卷積層權重 6 conv_base.trainable=True 7 # 把頂層卷積層進行解凍 8 layer_names=['block5_conv1','block5_conv2','block5_conv3','block5_pool'] 9 for layer in conv_base.layers: 10 if layer.name in layer_names: 11 layer.trainable = True 12 else: 13 layer.trainable=False 14 15 # 新建模型,使用 VGG16 的卷積層,拉直后,自定義三層全連接層 16 model=models.Sequential() 17 model.add(conv_base) 18 model.add(layers.Flatten()) 19 model.add(layers.Dense(256,activation='relu')) 20 model.add(layers.Dropout(0.3)) 21 model.add(layers.Dense(1,activation='sigmoid')) 22 # 顯示模型層特征 23 model.summary() 24 return model 25 26 def test(): 27 # 貓狗圖路徑 28 path='E://Python_Projects/data_test/DogVSCatLit/' 29 # 訓練資料集使用增強資料 30 train=ImageDataGenerator(rescale=1./255,rotation_range=20, 31 width_shift_range=0.2,height_shift_range=0.2, 32 shear_range=0.2,zoom_range=0.2, 33 horizontal_flip=True,fill_mode='nearest') 34 # 驗證資料集和測驗資料使用原資料 35 test=ImageDataGenerator(rescale=1./255) 36 # 圖片統一轉換成 256*256,每批 50個 37 trainData=https://www.cnblogs.com/leslies2/archive/2021/12/07/train.flow_from_directory(path+'train',target_size=(256,256), 38 batch_size=50,class_mode='binary') 39 validationData=https://www.cnblogs.com/leslies2/archive/2021/12/07/test.flow_from_directory(path+'validation',target_size=(256,256), 40 batch_size=50,class_mode='binary') 41 testData=https://www.cnblogs.com/leslies2/archive/2021/12/07/test.flow_from_directory(path+'test',target_size=(256,256), 42 batch_size=50,class_mode='binary') 43 # 獲取模型 44 model=getModel() 45 # 使用 adam 優化器,binary_crossentropy 二進制交叉熵損失函式 46 model.compile(optimizer=optimizers.Adam(3e-4), 47 loss=losses.binary_crossentropy, 48 metrics=['acc']) 49 # 日志記錄 50 callback=callbacks.TensorBoard(log_dir='logs/091903') 51 # 訓練資料 2000 個,每批 50 個,所以 steps_per_epoch 訓練批次為 40 52 # 驗證資料 1000 個,每批 50 個,所以 validation_steps 訓練批次為 20 53 # 重復訓練 30 次 54 model.fit(trainData,steps_per_epoch=40,epochs=30, 55 validation_data=https://www.cnblogs.com/leslies2/archive/2021/12/07/validationData,validation_steps=20, 56 callbacks=callback) 57 print('---------------------------------test---------------------------------------') 58 # 測驗結果 59 model.fit(testData,steps_per_epoch=20) 60 61 if __name__=='__main__': 62 test()
運行結果

回到目錄
五、CNN 中間激活層輸出圖
下面的例子嘗試對各層輸出圖進行可視化,你會發現一個很有趣的現象,在底層的通道都是比較形象地反應圖片的特征,越往頂層,其特征越抽象,甚至有些輸出是空白的,這證明在頂層里越來越多特征經過濾波器后的輸出是空白,這表示輸入影像中找不到這些濾波器的特征,
原始圖

首先讀取圖片,把圖片升維成 (1,224,224,3),對其除以 255.0 進行標準化,建立VGG16,根據名稱獲取層輸出,對圖片進行運算后獲取層輸出,
最后隨機顯示每層的 25 張 channel 的輸出圖,
1 def getImg(): 2 # 測驗圖片 3 path = 'E://Python_Projects/data_test/DogVSCatLit/train/dogs/dog.444.jpg' 4 img=image.load_img(path,target_size=(224,224,3)) 5 # 轉換成陣列 6 img=image.img_to_array(img) 7 # 升維成(1,224,224,3) 8 img=np.expand_dims(img,axis=0) 9 # RGB最大值為255,輸入前進行標準化 10 img/=255. 11 return img 12 13 def getLayerOutput(layername): 14 # 使用 VGG16 模型 15 vgg16=applications.VGG16(weights='imagenet') 16 # 獲取層 17 layer=vgg16.get_layer(layername) 18 # 獲取層輸出 19 layerout=layer.output 20 # 以 vgg16 建立 model,獲取輸出層 21 model=models.Model(inputs=vgg16.input,outputs=layerout) 22 # 輸入圖片運算后回傳層輸出 23 outputs=model.predict(getImg()) 24 return outputs 25 26 def display(layername): 27 # 獲取 axes 28 fig, axes = plt.subplots(5, 5, figsize=(50, 50)) 29 # 獲取層輸出 30 outputs=getLayerOutput(layername) 31 for ax in axes.ravel(): 32 # 隨機抽取 25 個 channel 進行顯示 33 high=len(outputs[0,0,0]) 34 index=np.random.randint(low=0,high=high) 35 ax.imshow(outputs[0,:,:,index]) 36 plt.show() 37 38 if __name__=='__main__': 39 display('block5_pool')
嘗試對 block1_pool,block2_pool,block3_pool,block4_pool,block5_pool 層執行獲取輸出圖,根據運行結果可以看到,越往頂層,其輸出圖越抽象,而空白的輸出圖則代表在輸入圖片中找不到該濾波器的特征,
運行結果
|
block1_pool |
block2_pool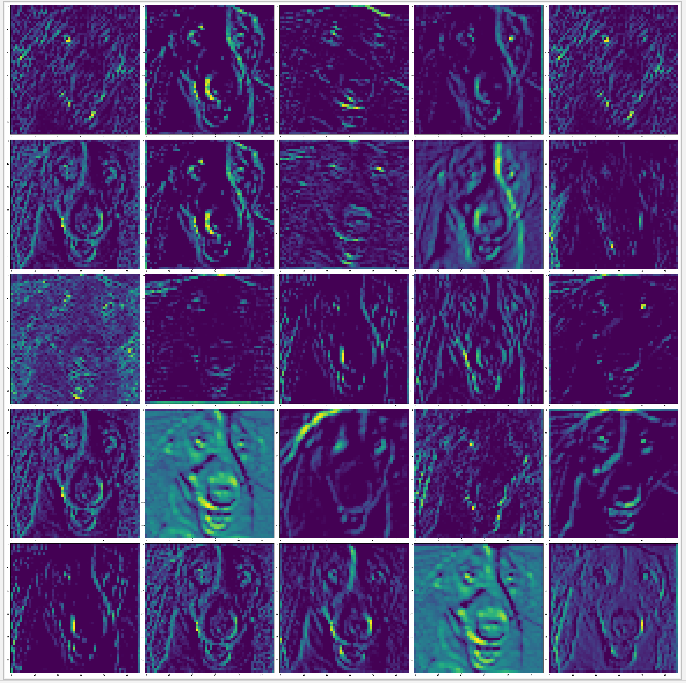 |
block3_pool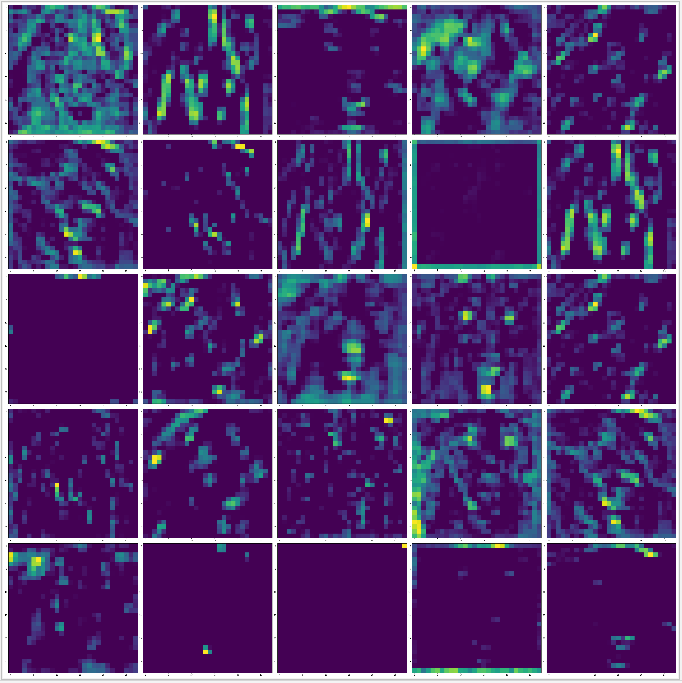 |
block4_pool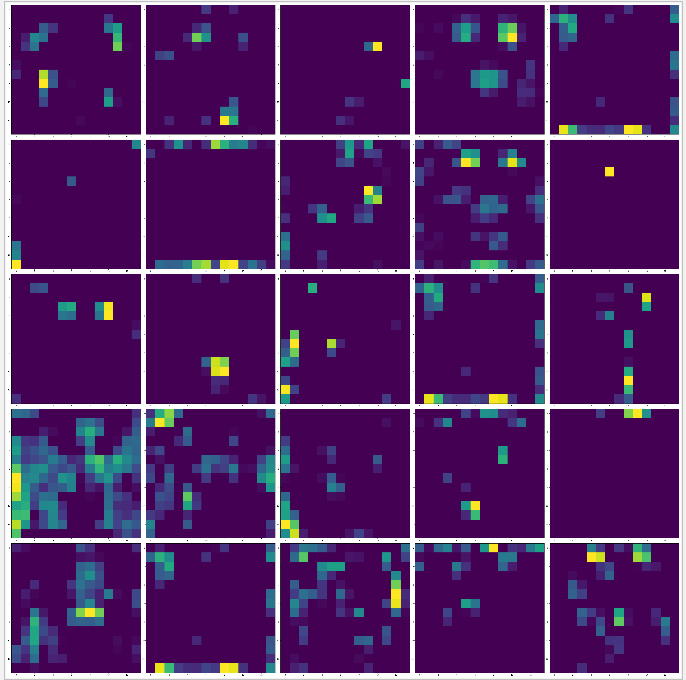 |
block5_pool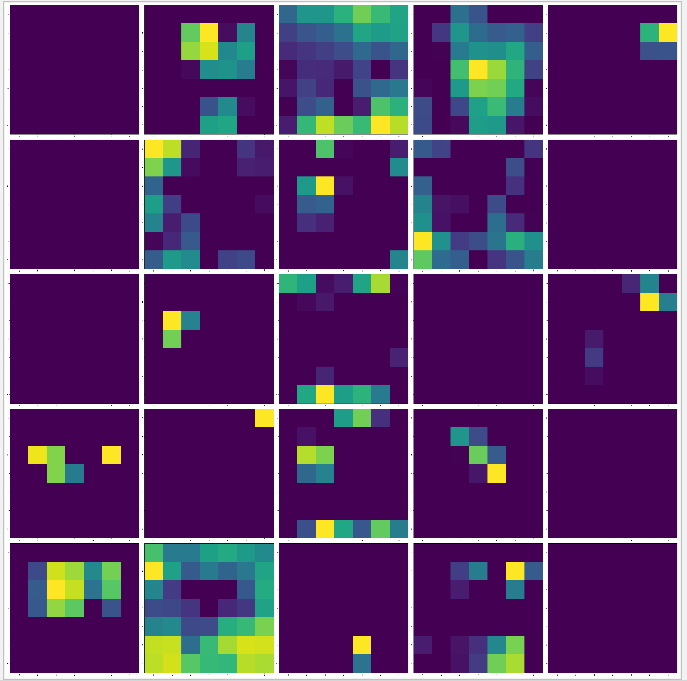 |

回到目錄
六、CNN 濾波器的可視化輸出
要觀察 CNN 濾波器最簡單的方法就是使用梯度上升來實作,首先以某一層的輸出值作為損失函式,使用 backend.gradients 函式系結輸出值對輸入值的梯度,注意gradients 默認回傳一個串列,取第一個元素即可,然后輸入隨機圖片,利用梯度上升的原理,重復呼叫 backend.function 函式進行累加,讓濾波器的輸出回應值實作最大化,此時觀察讓濾波器有最大輸出值的圖案,
1 def getfilter(layername,filterindex): 2 # tensorflow2.x 以上版本需要手動關閉 eager execution 3 tf.compat.v1.disable_eager_execution() 4 # 使用 VGG16 模型 5 vgg16=applications.vgg16.VGG16(include_top=False) 6 # 根據層名稱獲取層 7 layer=vgg16.get_layer(layername) 8 # 以該層的某個過濾器輸出作為 loss 9 loss = K.mean(layer.output[:, :, :, filterindex]) 10 # 建立 loss與 vgg16 輸入特征的梯度 11 # 注意 gradients 回傳一個串列,因此只取其第一個元素 12 grads=K.gradients(loss,vgg16.input)[0] 13 # grads 的更新系數,將梯度除以 L2 范數來標準化,加上 1e-4 保證分母非 0 14 grads/=(K.sqrt(K.mean(K.square(grads)))+1e-5) 15 # 系結輸入引數 VGG16 input 值與輸出引數 loss,grads 16 func=K.function([vgg16.input],[loss,grads]) 17 # 隨機生成輸入圖片 18 image=np.random.random((1,50,50,3)) 19 # 根據梯度上升法重復運行 50 次,將濾波器的輸出值實作最大化 20 for i in range(50): 21 loss,grads=func(image) 22 image+=grads*0.9 23 return image 24 25 #把資料轉化為 RGB 格式 26 def display(x): 27 x-=x.mean() 28 x/=(x.std()+1e-5) 29 x*=0.1 30 x+=0.5 31 x=np.clip(x,0,1) 32 x*=255 33 x=np.clip(x, 0, 255).astype('uint8') 34 return x 35 36 if __name__=='__main__': 37 # 5行5格 38 fig,axes=plt.subplots(5,5,figsize=(50,50)) 39 filterindex=0 40 for ax in axes.ravel(): 41 #過濾器從0開始顯示前25個 42 data=https://www.cnblogs.com/leslies2/archive/2021/12/07/getfilter('block1_conv2',filterindex) 43 #因為 display 輸出為 (1,50,50,3),輸出只用第一個 44 a = display(data[0]) 45 filterindex+=1 46 ax.imshow(a) 47 plt.show()
分別顯示 block1_conv2,block2_conv2,block3_conv2,block4_conv2,block5_conv2 的過濾器
運行結果
|
block1_conv2
|
block2_conv2
|
|
block3_conv2
|
block4_conv2
|
|
block5_conv2
|





每一組濾波器包含一層同型別的特征,block1 可能只包含簡單的顏色,輪廓等特征,block2 開始出現紋理特征,block3 開始演變成復雜的圖案,隨著層的逐步加深,濾波器會變得越來越復雜,
回到目錄
七、CNN 熱力圖
經過前兩個章節的例子可以看到 CNN 的濾波器是逐層復雜化的,每個濾波器都包含了一個特征,越高層的濾波器特征越為得復雜,而圖片經過濾波器后的輸出圖代表這個圖片中是否存在著該特征,隨著高層濾波器的特征越來越復雜化,經過高層的濾波器輸出后,很多輸出特征圖都變成空白,這是因為在圖片中找不到該特征,
結合上述內容,這一節可嘗試使用類似的方法,查看圖片是根據哪些特征去判斷輸出值的,
1 def getImg(): 2 # 讀取用于測驗的圖片 3 path='C://Users/Leslie/Desktop/CNN/01.jpg' 4 img=image.load_img(path,target_size=(224,224,3)) 5 # 轉換成陣列 6 img=image.img_to_array(img) 7 # 升維成(1,224,224,3) 8 img=np.expand_dims(img,axis=0) 9 return img 10 11 def getResult(): 12 # 執行計算 13 result=vgg16.predict(getImg()) 14 # 查看所占比例最高的前5個圖片型別 15 print(decode_predictions(result,top=5)) 16 # 列印出最高可能性型別的索引 17 arg=np.argmax(result) 18 print(arg) 19 20 if __name__=='__main__': 21 getResult()

運行結果如下,斑馬的可能性最大,占比 88%,屬于第 340 類
[[('n02391049', 'zebra', 0.886605), ('n01704323', 'triceratops', 0.09896327), ('n02422699', 'impala', 0.0035573354), ('n02423022', 'gazelle', 0.0028548033), ('n02422106', 'hartebeest', 0.002379738)]]
340
然后根據運算后的索引 340,以 vgg16.output [ : , 340 ] 輸出值為 loss,第5層 block5_conv3 為引數求梯度,然后輸入測驗圖片,把測驗圖片的 block5_conv3 輸出值乘以梯度得出熱力圖,再把熱力圖以降維去負求均值的方式轉化為圖片進行顯示,最后把熱力圖與原圖進行合并,
1 def excute(): 2 # tensorflow2.x 以上版本需要手動關閉 eager execution 3 disable_eager_execution() 4 # 實體化 VGG16 5 vgg16 = applications.vgg16.VGG16(weights='imagenet') 6 # 以 VGG16 最大輸出值作為 loss,斑馬的索引 340 7 loss=vgg16.output[:,340] 8 # 以 block5_conv3 層輸出值作為引數 9 layeroutput=vgg16.get_layer('block5_conv3').output 10 # 求兩者的梯度,K.gradients 默認回傳陣列,取第一個元素即可 11 gradient=K.gradients(loss,layeroutput)[0] 12 func=K.function(vgg16.input,[gradient,layeroutput,loss]) 13 grad,layeroutput,loss=func(getImg()) 14 # 把輸入值乘以梯度值得出熱力圖 15 for i in range(512): 16 layeroutput[0,:,:,i]*=grad[0,:,:,i] 17 # 把熱力圖轉化為二維資料顯示 18 heat=convert(layeroutput[0]) 19 plt.matshow(heat) 20 plt.show() 21 return heat 22 23 def applyheat(heat): 24 # 讀入原圖 25 path = 'C://Users/Leslie/Desktop/CNN/01.jpg' 26 image=cv2.imread(path) 27 # 把熱力圖大小轉換成原圖大小 28 heat=cv2.resize(heat,(image.shape[1],image.shape[0])) 29 # 把熱力圖轉換成 RGB 格式 30 heat=np.uint8(255*heat) 31 # 熱力圖與原圖合并 32 heat=cv2.applyColorMap(heat,cv2.COLORMAP_JET) 33 image=heat*0.5+image 34 # 保存合并后的圖 35 cv2.imwrite('C://Users/Leslie/Desktop/CNN/03.jpg',image) 36 37 #對熱力圖進行處理,先降維,再去負,求占比,把數值控制在 0~1 之間 38 def convert(x): 39 # 對最后一個維度進行降維 40 x=np.mean(x,axis=-1) 41 # 去除負值 42 x=np.maximum(x,0) 43 # 求比 44 x/=np.max(x) 45 return x 46 47 if __name__=='__main__': 48 heat=excute() 49 applyheat(heat)
熱力圖
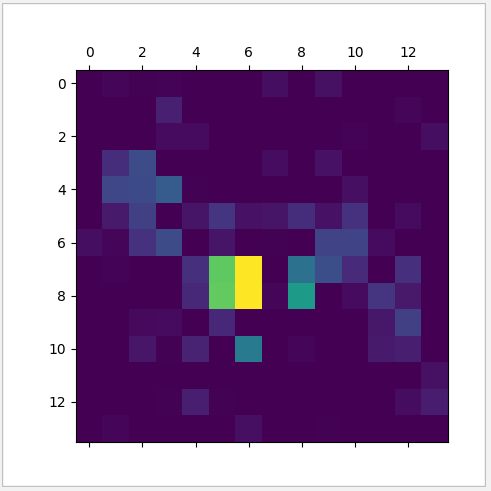
合并原圖后,可見斑紋,輪廓對辨別斑馬型別的影響比較大,

回到目錄
本章總結
本文主要介紹 CNN 卷積神經網路的基本原理和基礎概念,卷積層與池化層的作用,并以常用的 VGG16 為例子,介紹常用模型的使用方式,把中間激活層輸出圖,濾波器,熱力圖等進行可視化分析,讓大家進一步了解 CNN 的結構特征,文章內容受偶像 Keras 之父 Francois 博客和 Antonio 論文的啟發很深,
后面的文章里將會進一步講解 DeepDream,風格遷移,音頻 / 視頻處理等高級 CNN 的應用,敬請留意,
希望本篇文章對相關的開發人員有所幫助,由于時間倉促,錯漏之處敬請點評,
對 .Python 開發有興趣的朋友歡迎加入QQ群:790518786 共同探討 !
對 JAVA 開發有興趣的朋友歡迎加入QQ群:174850571 共同探討!
對 .NET 開發有興趣的朋友歡迎加入QQ群:162338858 共同探討 !
AI人功智能相關文章
Python 機器學習實戰 —— 監督學習(上)
Python 機器學習實戰 —— 監督學習(下)
Python 機器學習實戰 —— 無監督學習(上)
Python 機器學習實戰 —— 無監督學習(下)
Tensorflow 2.0 深度學習實戰——介紹損失函式、優化器、激活函式、多層感知機的實作原理
TensorFlow 2.0 深度學習實戰 —— 淺談卷積神經網路 CNN
作者:風塵浪子
https://www.cnblogs.com/leslies2/p/15215117.html
原創作品,轉載時請注明作者及出處
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375151.html
標籤:其他