Linux系統(Centos7)實作hadoop安裝
工具:
Linux系統 :Centos7
JDK:JDK1.8
Hadoop:Hadoop-3.3.1
虛擬機:VMware Workstation Pro 16
本機系統:Windows10
一、虛擬機設定
1.設定虛擬機的網路連接方式
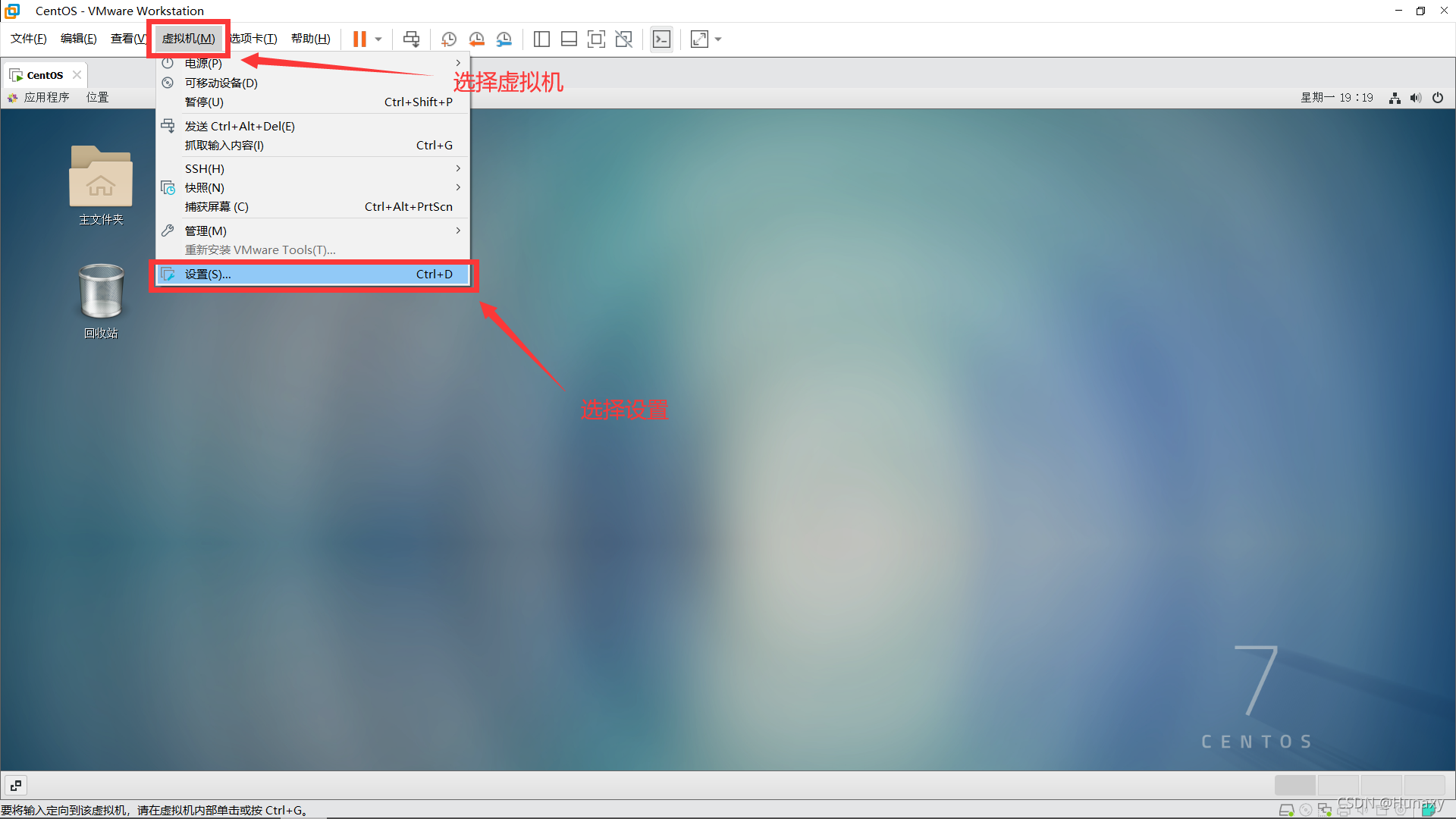
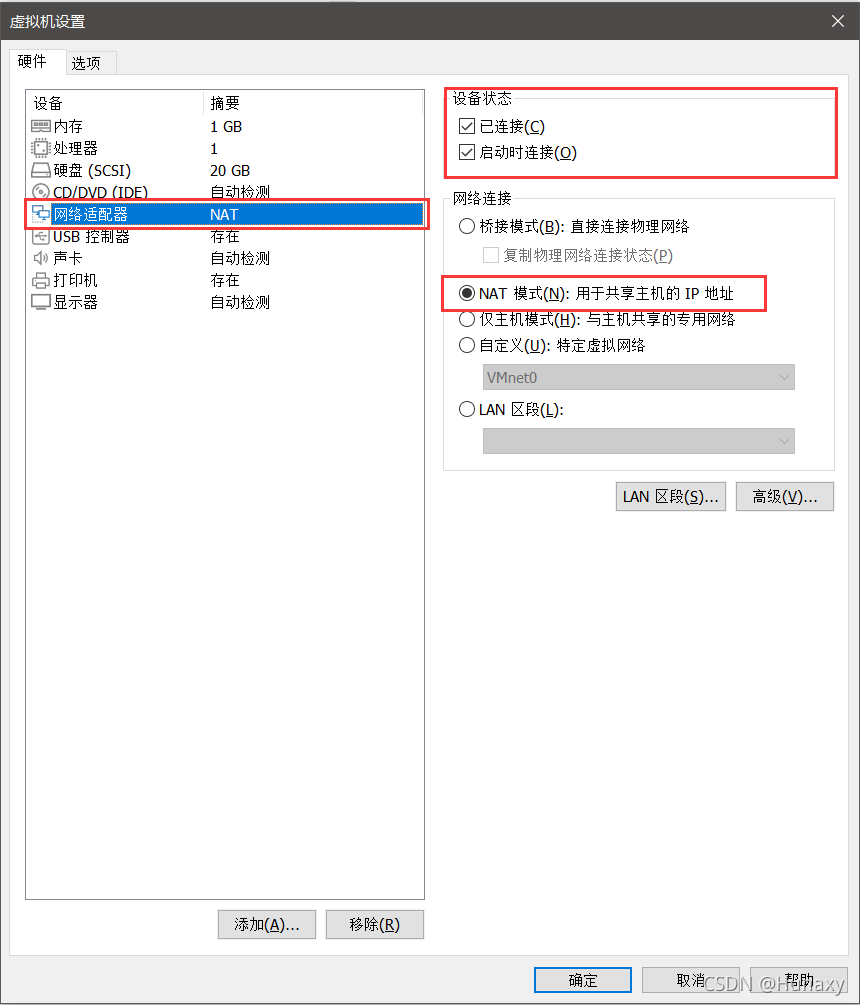
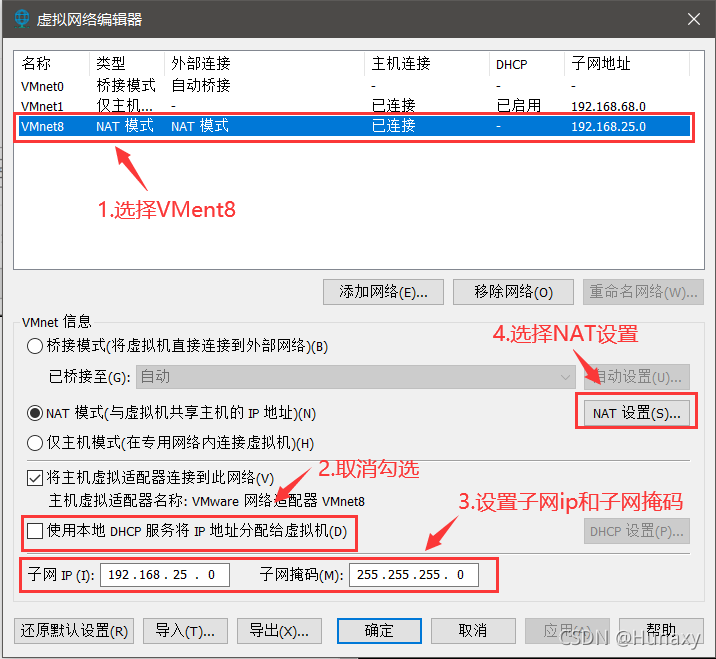
2.設定虛擬機網路配置
說明:修改子網IP設定,可自由設定固定IP;
若設定固定IP為192.168.2.2-255,例如:192.168.2.2,則子網IP為192.168.2.0;
若設定固定IP為192.168.1.2-255,例如:192.168.1.2,則子網IP為192.168.1.0;
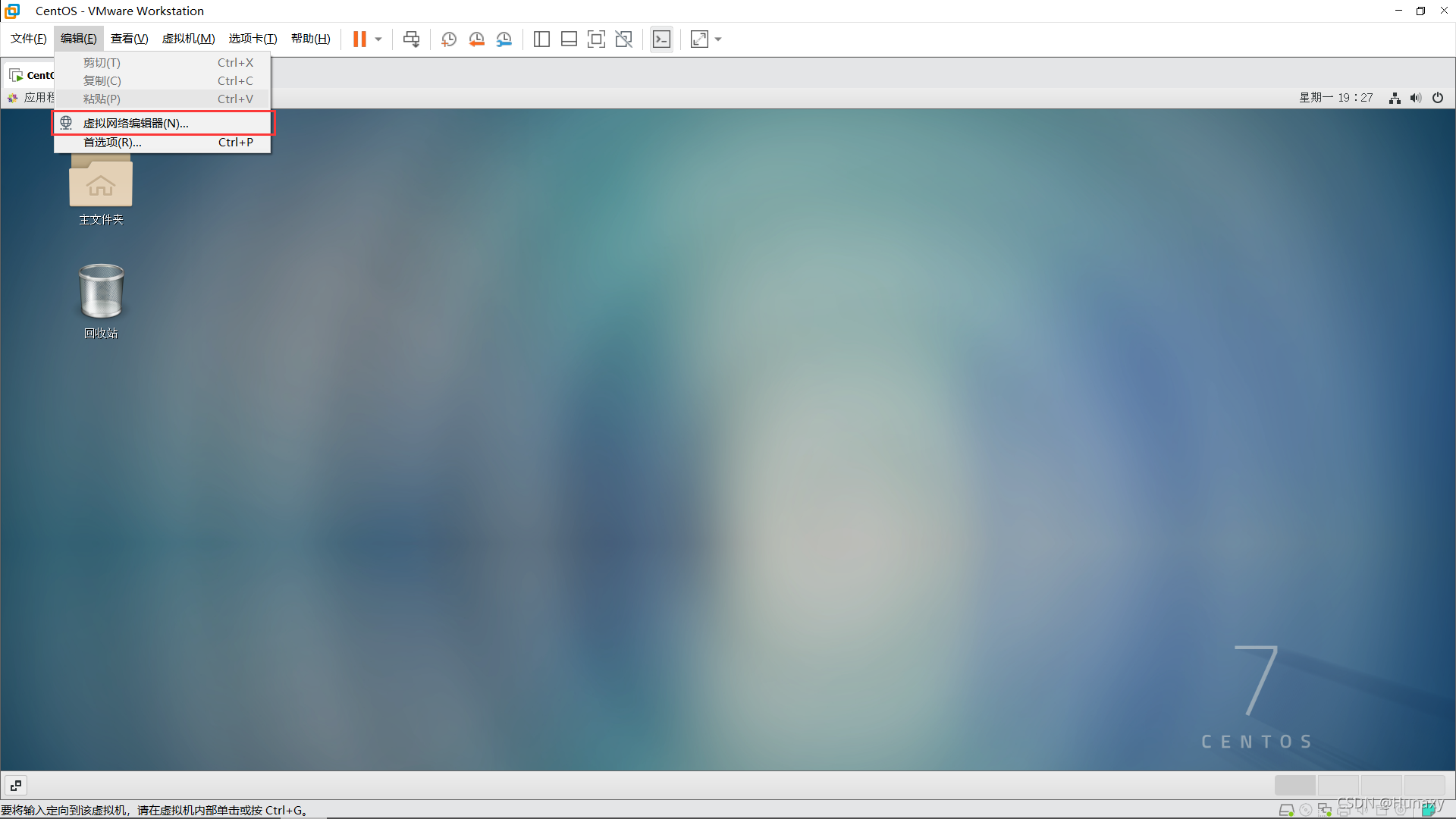
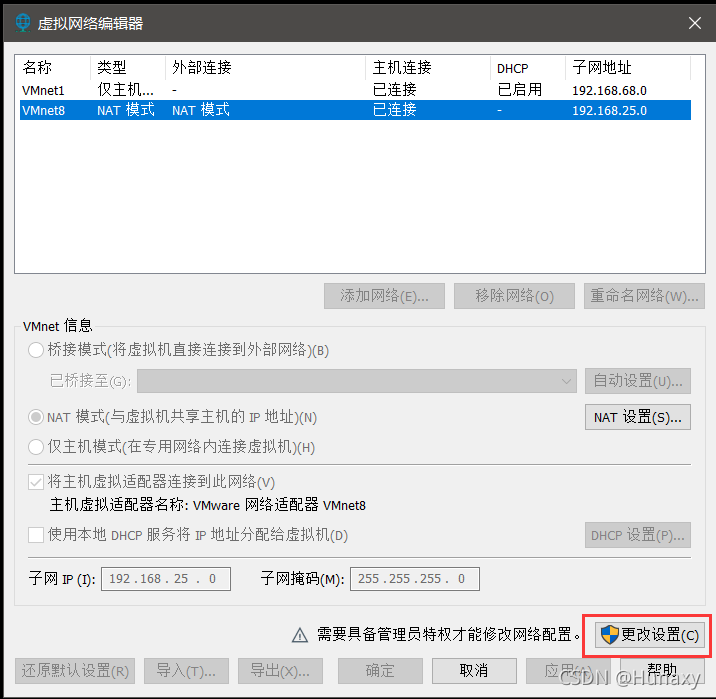
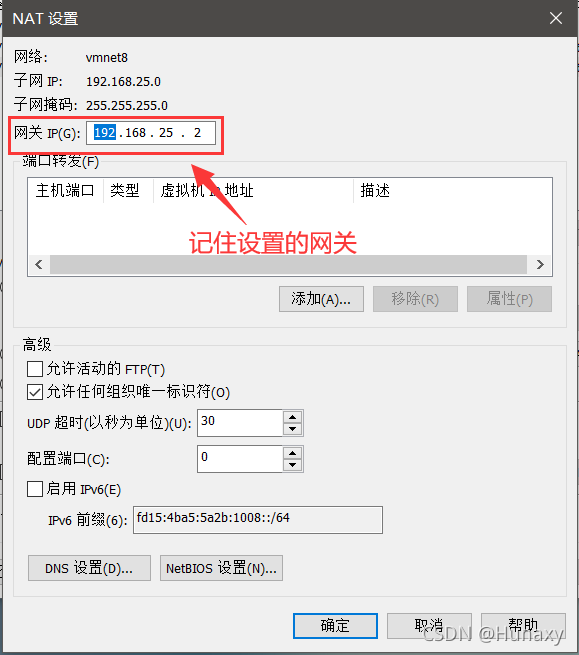
3.配置本機VMent8的本地引數
說明:IPv4中的ip地址可隨意設定,但不能和虛擬機的固定ip一樣,
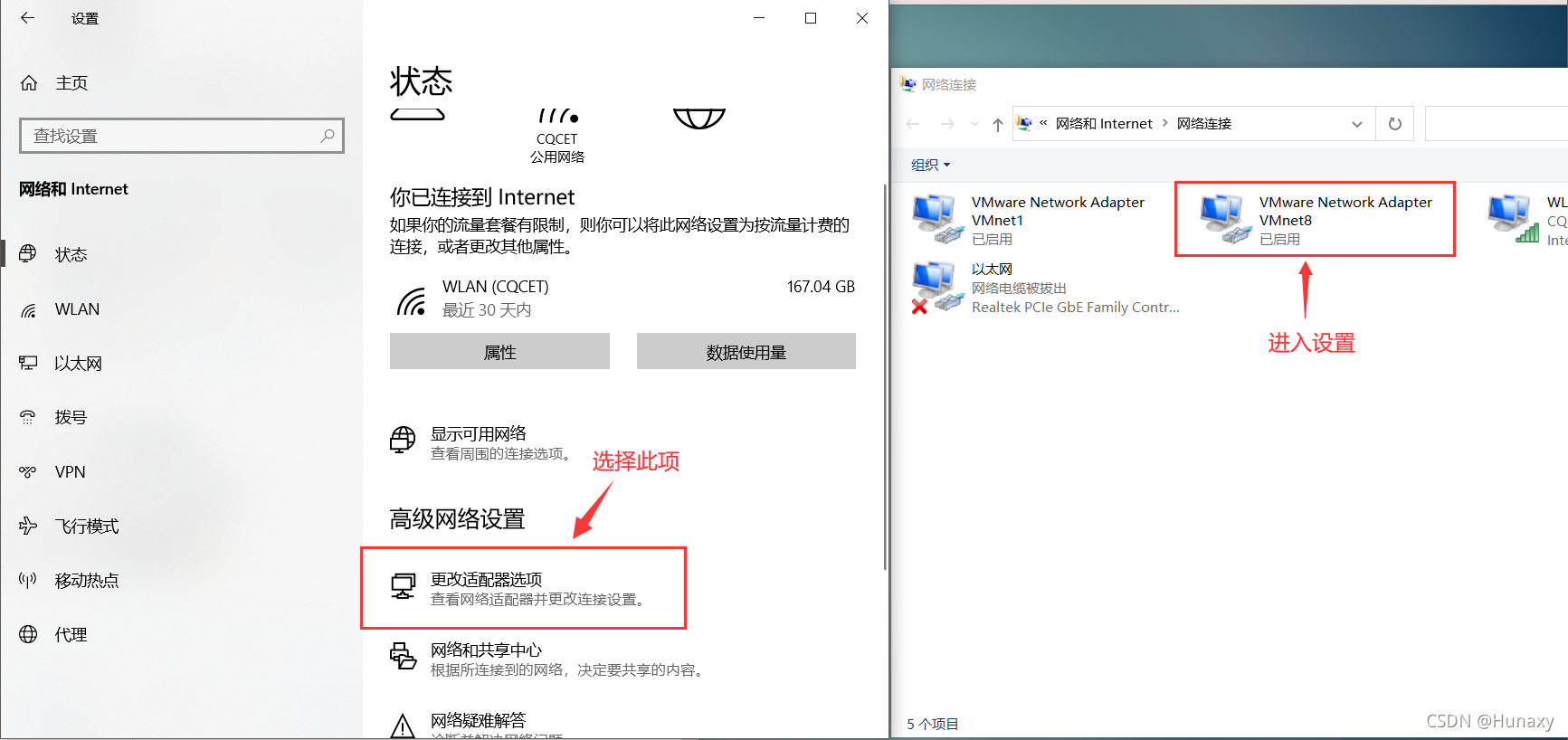
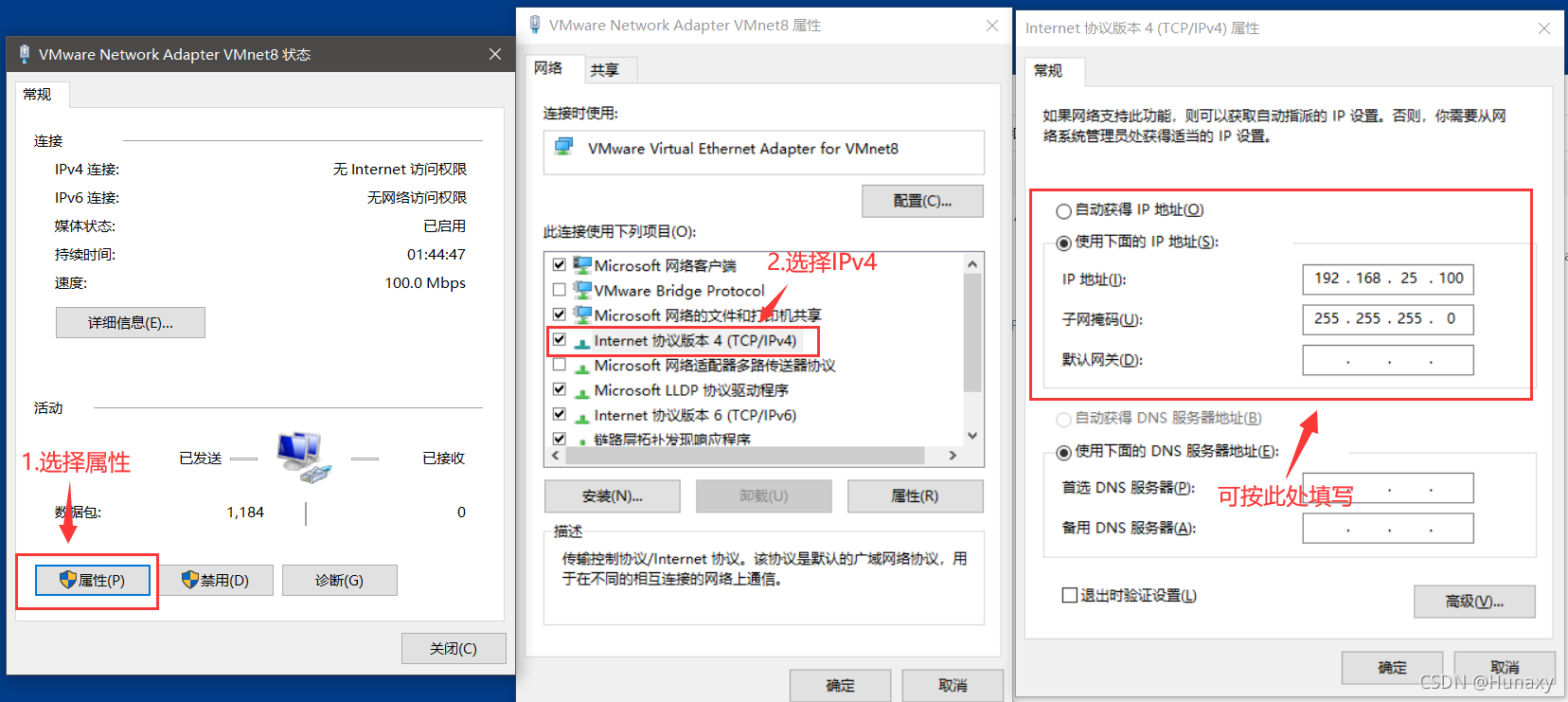
4.修改Centos7的網路組態檔
cd /etc/sysconfig/network-scripts/
ls #查看組態檔名字
vim ifcfg-ens33
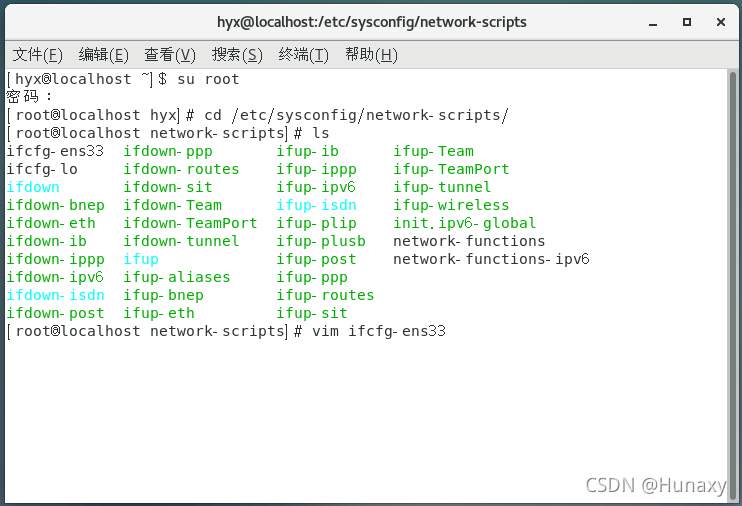
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.25.11
PREFIX=24
GATEWAY=192.168.25.2 #網關,這里需和NAT模式具體地址引數中設定的網關IP一致
DNS1=114.114.114.114
我的個人配置
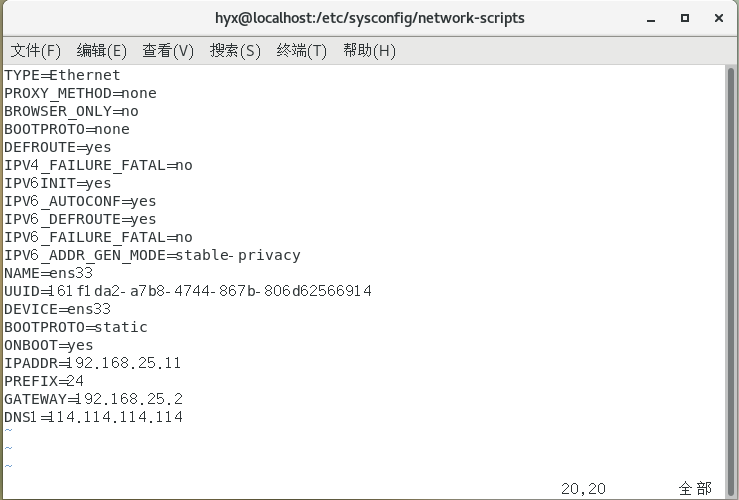
重啟網路服務
service network restart
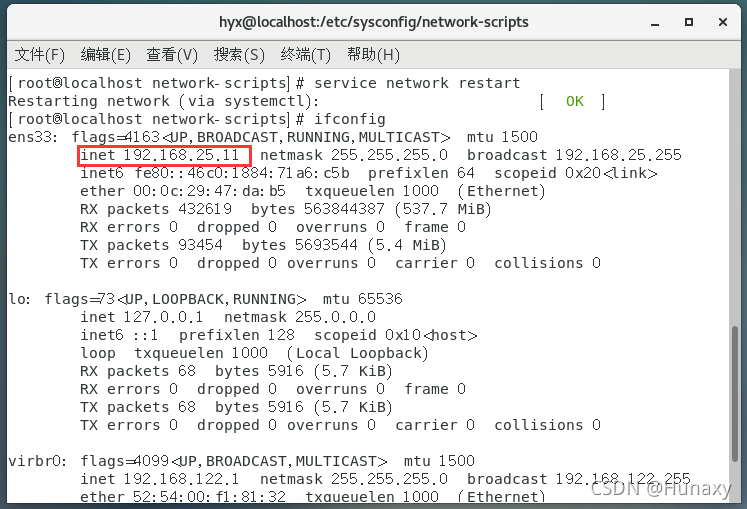
5.檢查配置是否成功
(1)IP顯示為設定后的IP則成功
(2)測驗是否能連通外網,若有資料回傳則成功
ping -c 4 www.baidu.com
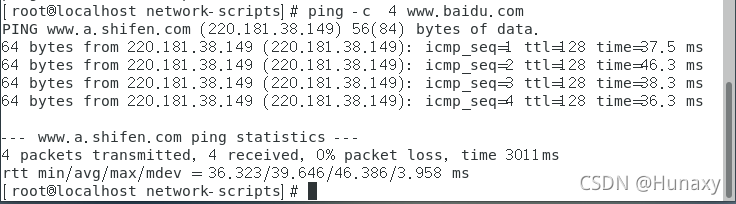
若顯示未找到服務器,但ping外網ip有資料回傳一樣表示成功
(3)使用cmd測驗本機能否ping通虛擬機IP
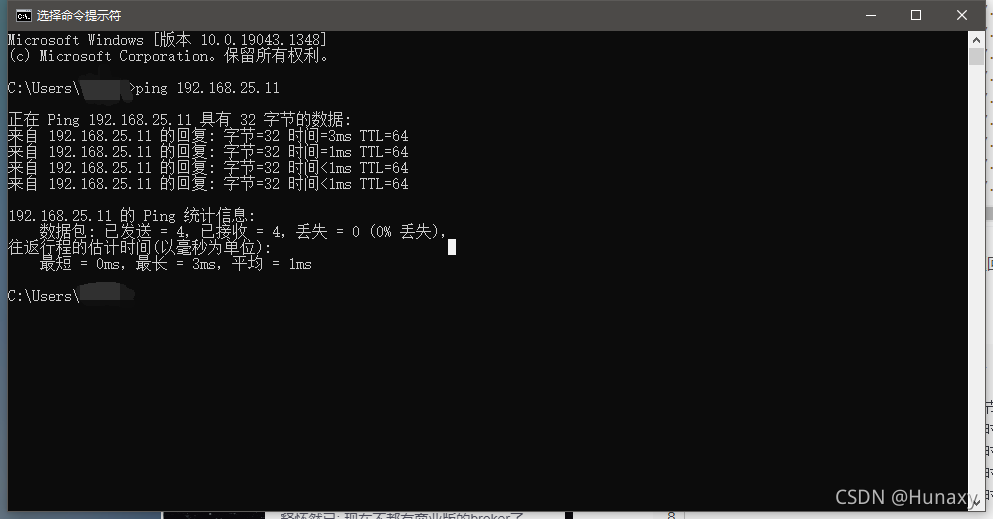
6.修改虛擬機主機名
修改主機名
查看主機名:終端輸入hostname
修改主機名:終端輸入hostname Master
注意:修改主機名不會立刻在終端上顯示,重新打開終端就可看到主機名已更換
二、JDK安裝
1.前往官網下載JDK安裝包:https://www.oracle.com/java/technologies/downloads/#java8
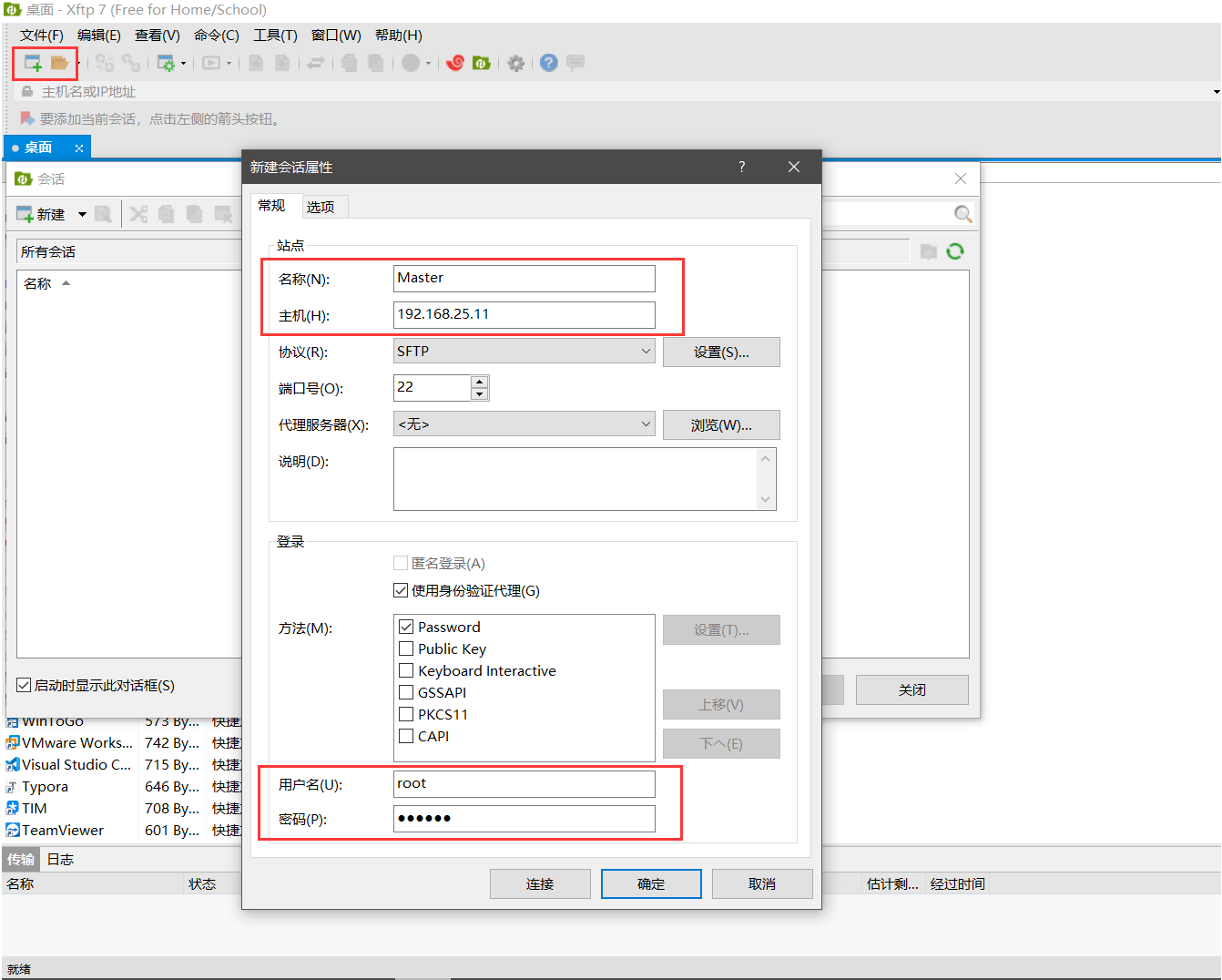
2.解壓檔案:使用XFTP等檔案傳輸軟體進行壓縮包的傳輸,此鏈接為免費版XFTP下載鏈接:https://www.netsarang.com/zh/free-for-home-school/
連接時只需要修改選中的引數,其他保持默認即可
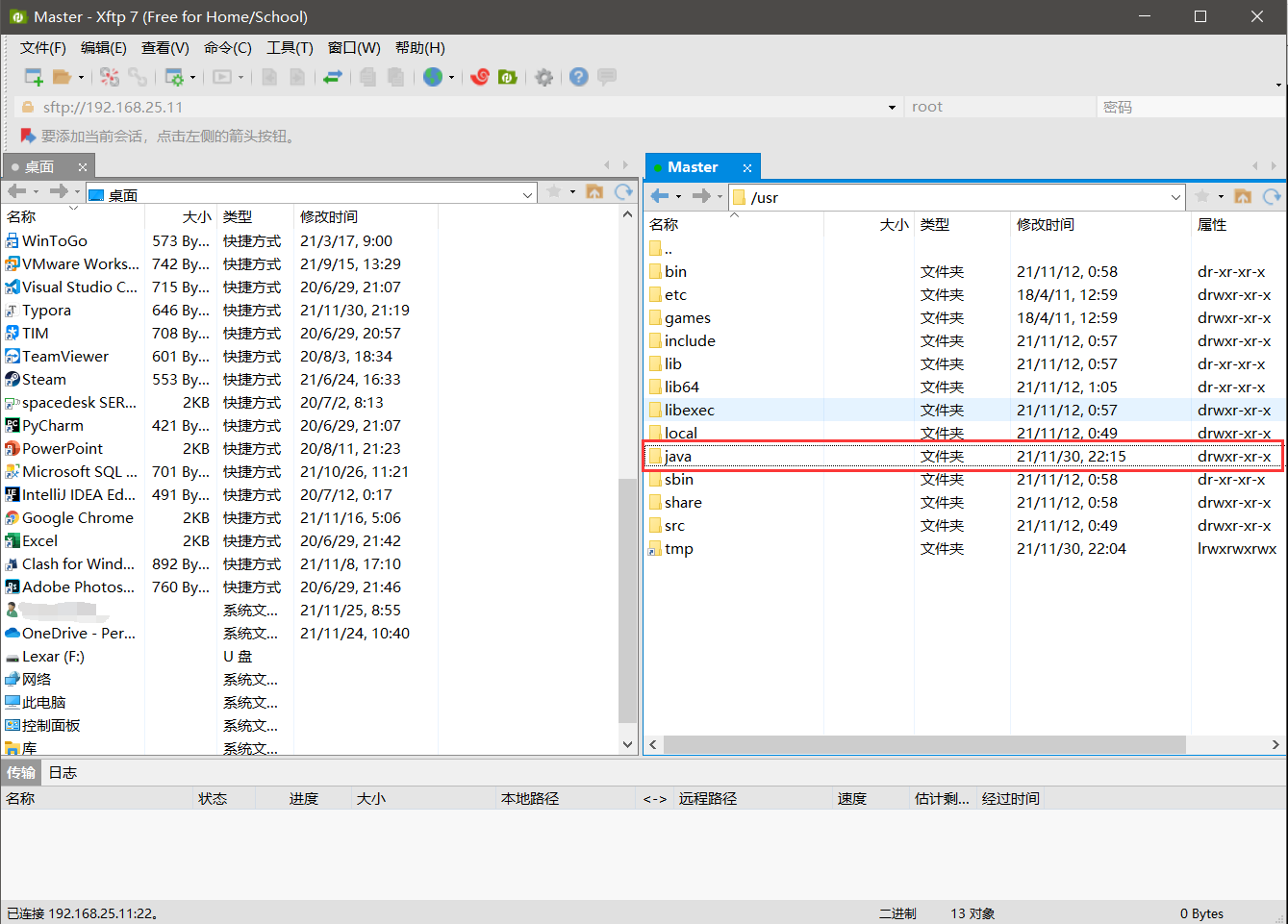
創建java檔案夾并將jdk壓縮包傳入java檔案夾中
也可以在終端中使用mkdir命令直接創建
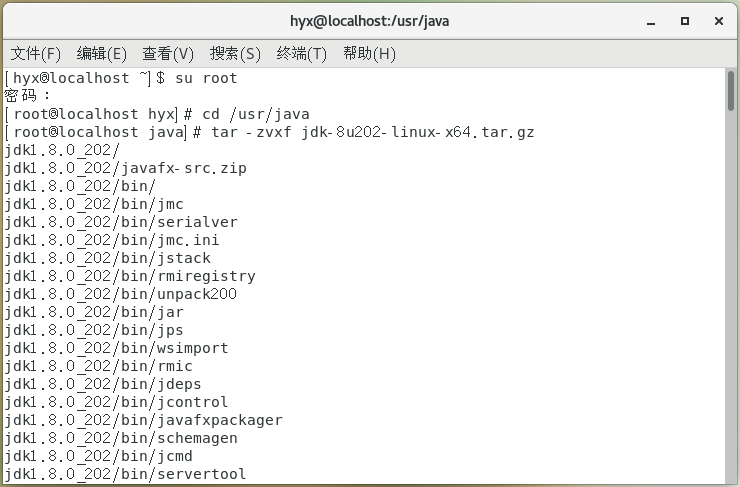
進入jdk壓縮包的目錄下輸入命令進行解壓:
tar -zvxf jdk-8u202-linux-x64.tar.gz
3.配置系統環境,命令:
vim /etc/profile
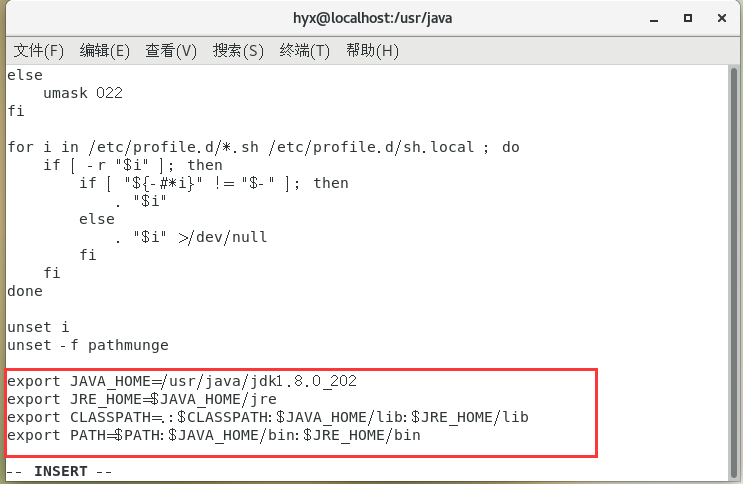
在檔案中添加:
export JAVA_HOME=/usr/java/jdk1.8.0_202 # 此處為自己的jdk版本
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
重啟環境并驗證jdk是否安裝成功
source /etc/profile
java -version
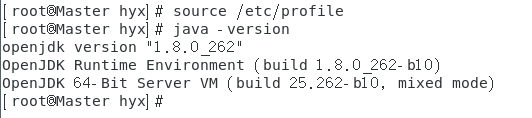
至此JDK安裝完成
三、Hadoop安裝與配置
1.Hadoop的安裝與JDK安裝一樣,都是在usr檔案夾下創建新的hadoop檔案夾,使用XFTP將hadoop壓縮包傳入檔案夾中并且解壓
tar -zvxf hadoop-3.3.1.tar.gz
2.配置系統環境,與配置jdk時一樣,輸入命令:
vim /etc/profile
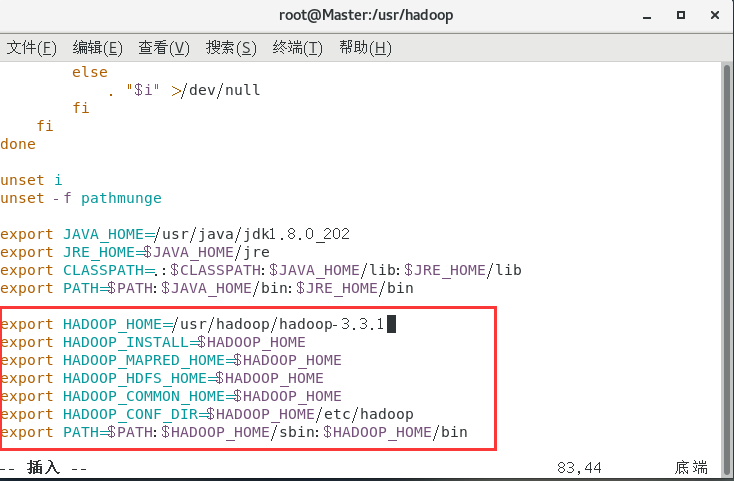
在檔案中添加:
export HADOOP_HOME=/usr/hadoop/hadoop-3.3.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
重啟環境并驗證hadoop是否安裝成功:
source /etc/profile
hadoop version
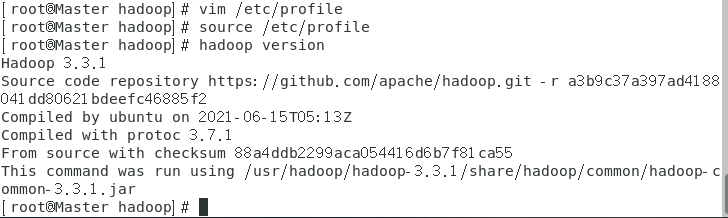
如圖顯示則表示hadoop安裝成功
3.Hadoop完全分布式配置
(1)首先進入hadoop檔案夾中創建幾個檔案夾:
mkdir /usr/hadoop/hadoop-3.3.1/tmp
mkdir /usr/hadoop/hadoop-3.3.1/data
mkdir /usr/hadoop/hadoop-3.3.1/data/namenode
mkdir /usr/hadoop/hadoop-3.3.1/data/datanode
mkdir /usr/hadoop/hadoop-3.3.1/pids
mkdir /usr/hadoop/hadoop-3.3.1/logs
(2)在終端上輸入:
cd /usr/hadoop/hadoop-3.3.1/etc/hadoop
進入該檔案夾中開始配置Hadoop完全分布式搭建所需的檔案:
(注意將以下檔案中的主機名和檔案名修改為自己設定的主機名和檔案名)
配置core-site.xml:
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-3.3.1/tmp</value>
</property>
</configuration>
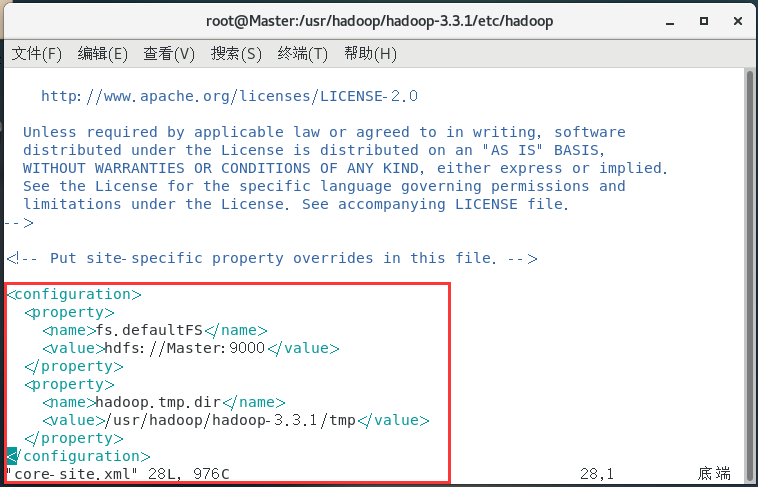
配置mapred-site.xml:
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
</configuration>
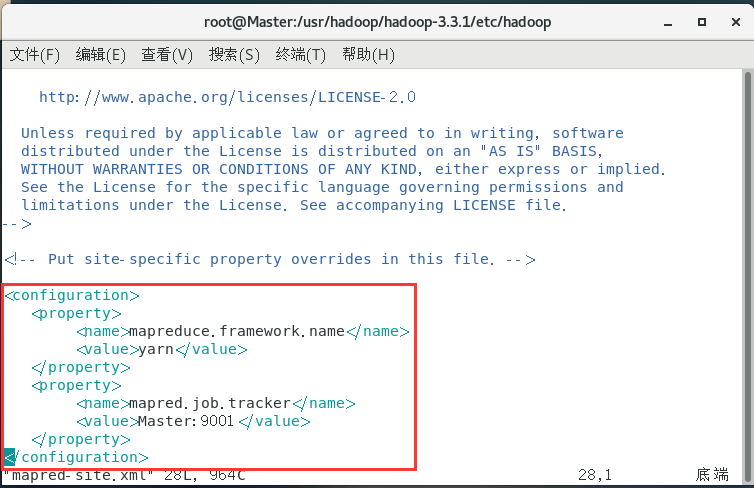
配置yarn-site.xml:
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
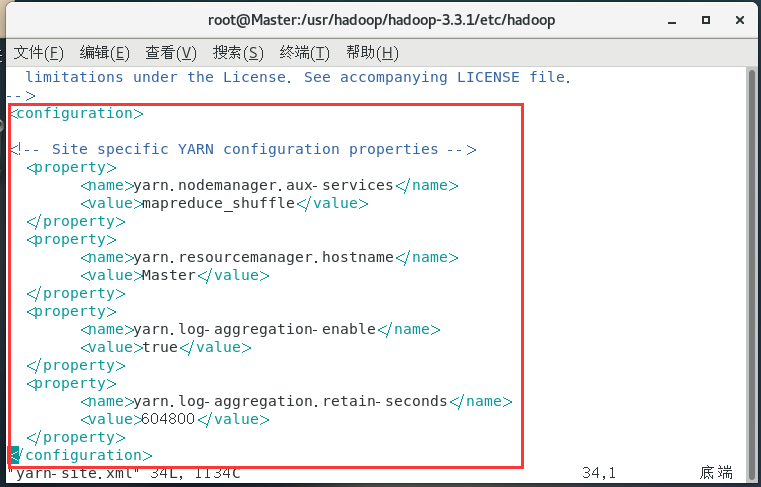
配置yarn-env.sh:
vim yarn-env.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
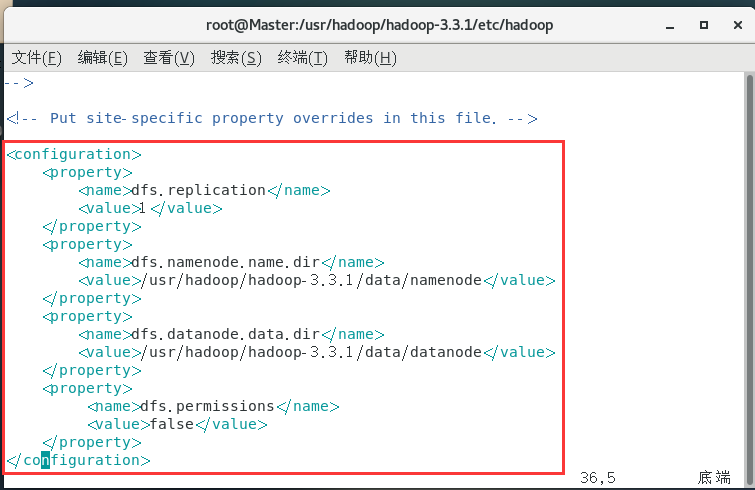
配置hdfs-site.xml:
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop/hadoop-3.3.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop/hadoop-3.3.1/data/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
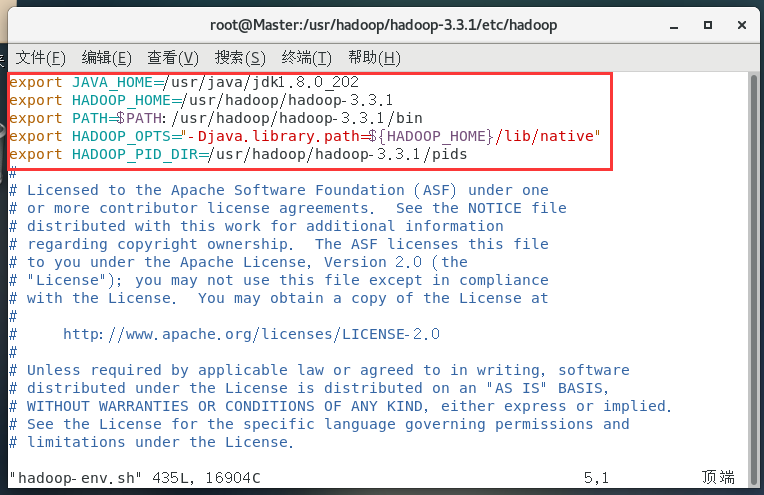
配置hadoop-env.sh:
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_202
export HADOOP_HOME=/usr/hadoop/hadoop-3.3.1
export PATH=$PATH:/usr/hadoop/hadoop-3.3.1/bin
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HADOOP_PID_DIR=/usr/hadoop/hadoop-3.3.1/pids
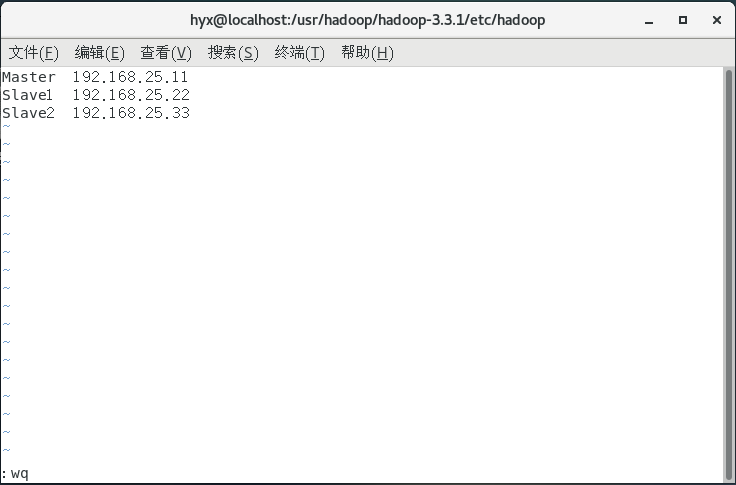
配置workers:
vim workers
打開檔案后將檔案內的內容替換為你的主機名和IP地址,這里先提前寫下另外兩臺需要克隆的虛擬機名字,之后克隆的兩臺虛擬機需要按照此時輸入的主機名和IP進行修改
在終端輸入:
cd /usr/hadoop/hadoop-3.3.1/sbin/
進入新的目錄中
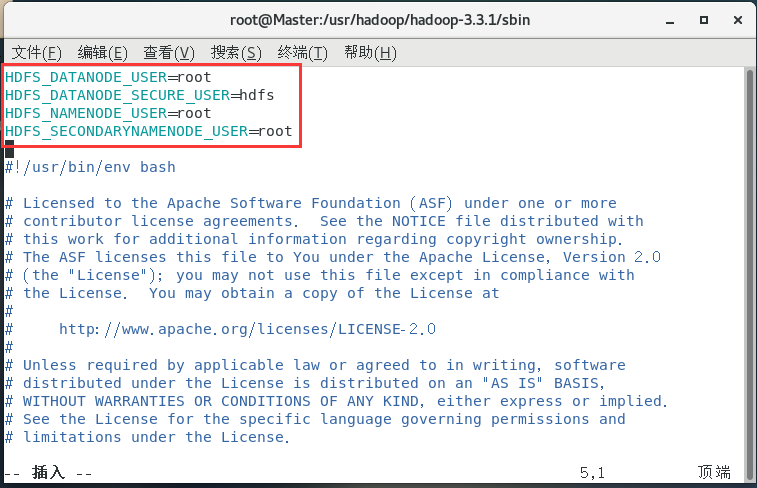
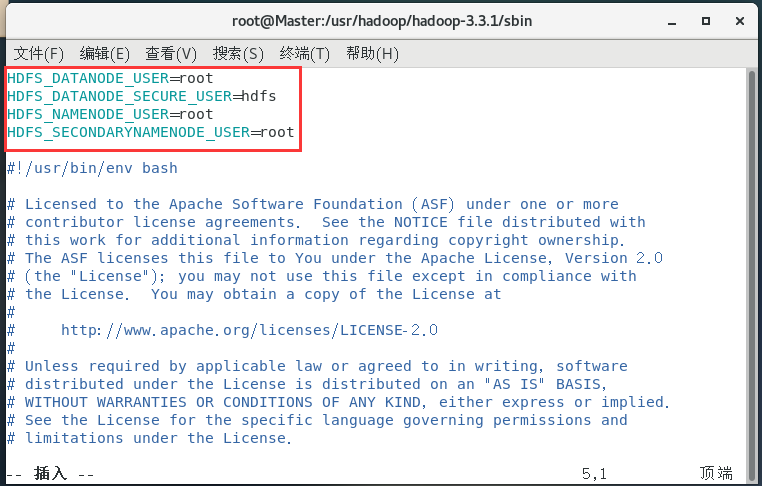
配置start-dfs.sh:
vim start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置stop-dfs.sh:
vim stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
四、克隆虛擬機
1.關閉防火墻:
systemctl stop firewalld.service // 臨時關閉防火墻
systemctl disable firewalld.service // 設定為開機不自啟
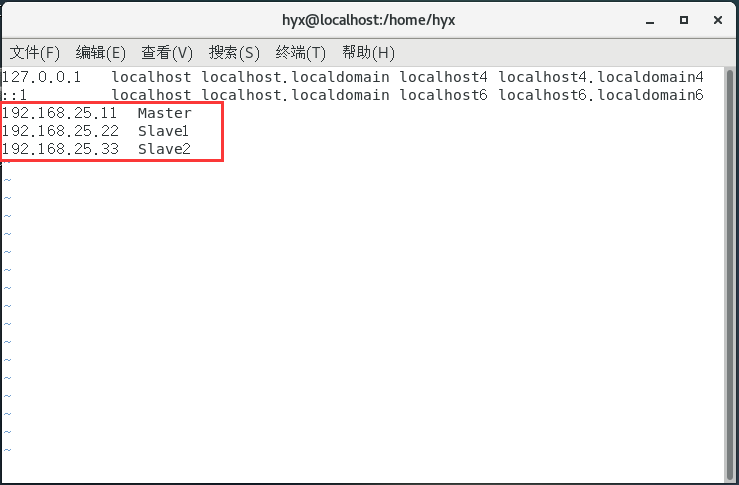
2.添加虛擬機映射
vi /etc/hosts
3.克隆兩臺虛擬機
關閉當前虛擬機,克隆其余兩臺虛擬機
4.修改克隆機設定
設定Slave1和Slave2的主機名和IP地址
使用 hostname 主機名 修改
修改IP的方法和文章開始修改Master主機IP一致
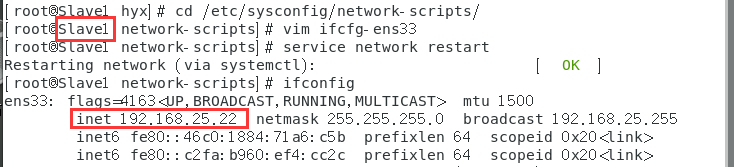
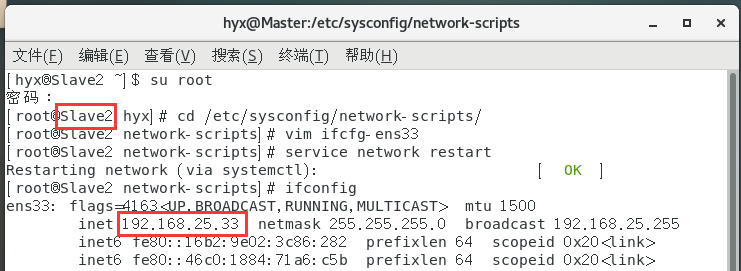
5.設定SSH免密登錄
在三臺虛擬機上輸入:
cd ~/.ssh
ssh-keygen -t rsa
一直按回車直到結束
結束后在三臺虛擬機終端中輸入:
ssh-copy-id Master
ssh-copy-id Slave1
ssh-copy-id Slave2
再在Master傷進行授權:
chmod 0600 authorized_keys
將授權檔案發送到其他主機:
scp authorized_keys Slave1:/root/.ssh/
scp authorized_keys Slave2:/root/.ssh/
將密鑰發送出去
若在任意一臺虛擬機中使用:
ssh 主機名
能進入所輸入的虛擬機中則表示免密登錄成功
登錄之后一定要使用exit退出后再嘗試登錄其他主機或進行其他操作
五、啟動集群
1.三臺虛擬機先進行格式化處理:
hdfs namenode -format
2.啟動集群
在Master中輸入:
start-all.sh
以此來啟動集群,若要關閉集群則輸入:
stop-all.sh
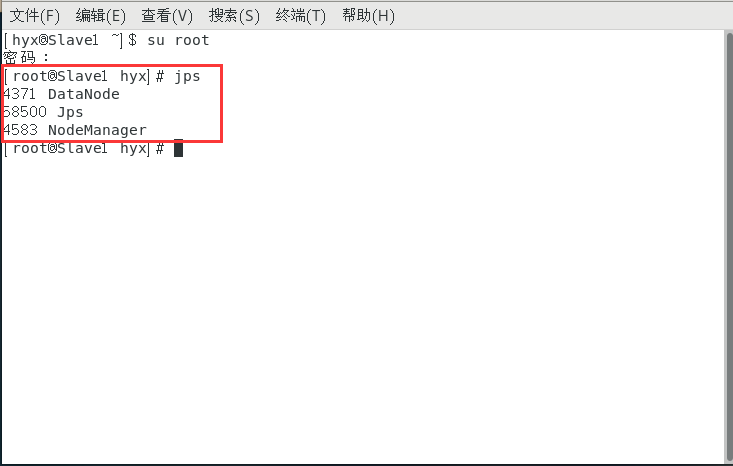
啟動完畢之后輸入jps查看狀態
Master和Slave應該有如下資訊:
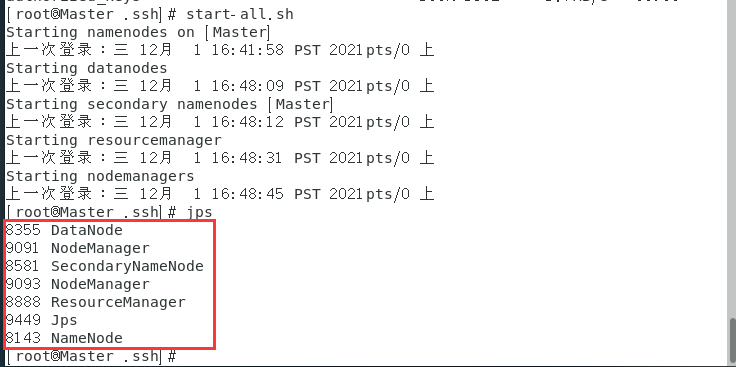
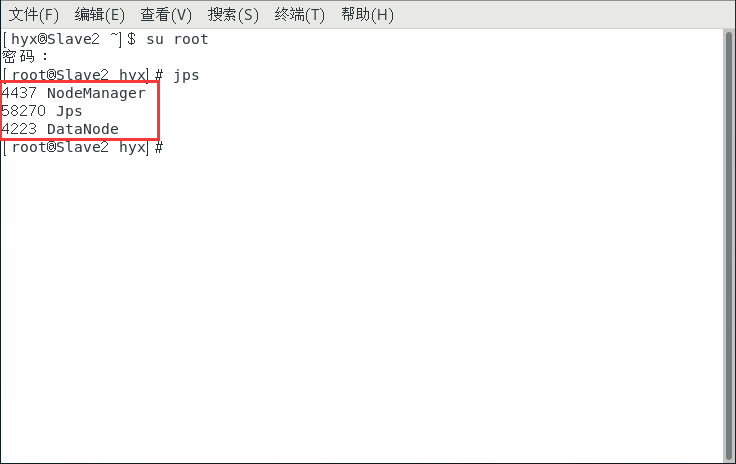
在Master主機上打開瀏覽器,輸入:
Master:9870
Master:8088
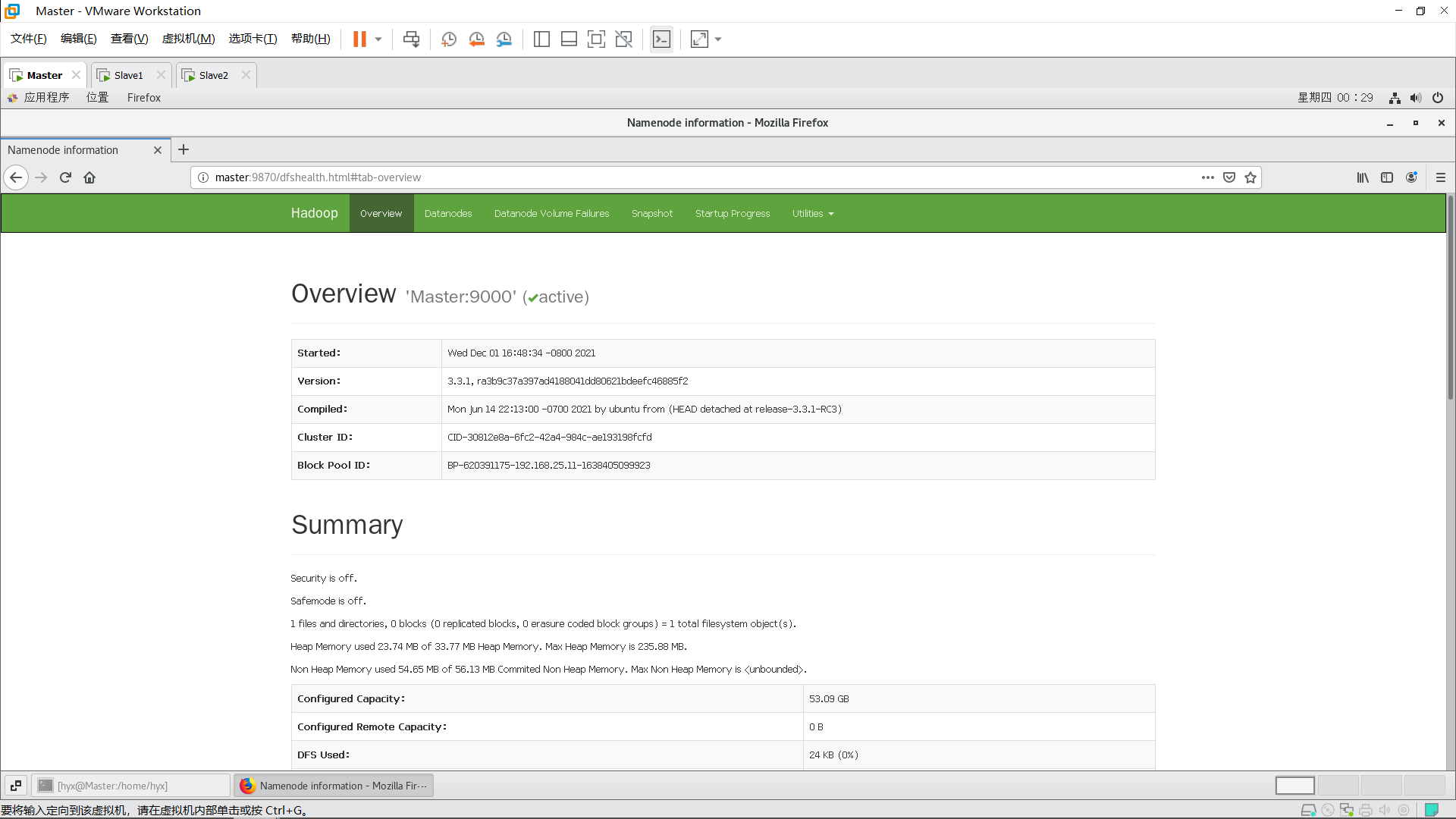
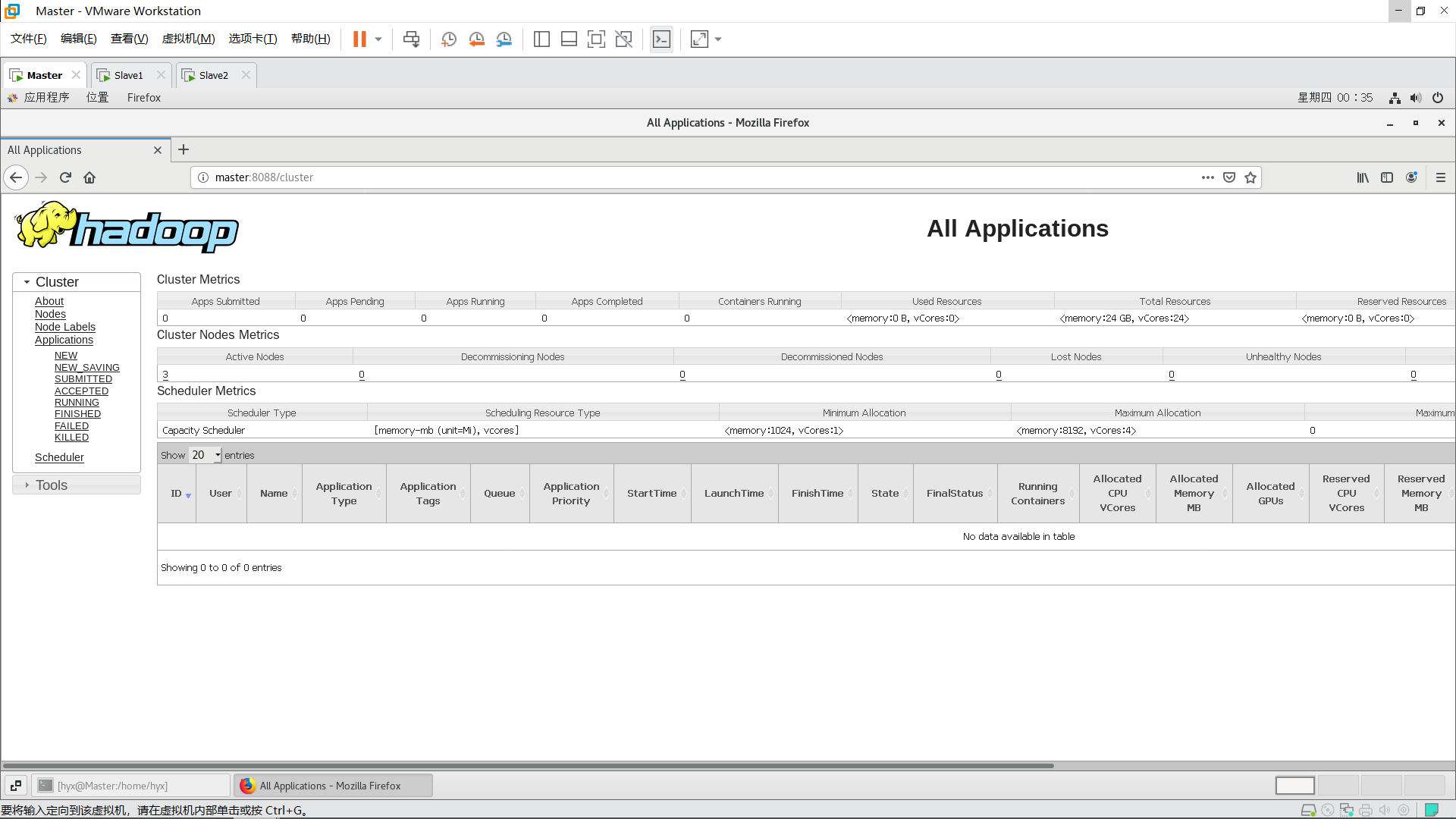
若能訪問這兩個地址則表示Hadoop完全分布式搭建成功
參考文章:https://www.zhangshengrong.com/p/zAaOK6Z3ad/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375804.html
標籤:其他