原始
你們知道當程式需要讀取或者寫入資料的時候,CPU是如何操作我們的磁盤的嗎?首先CPU肯定是要把讀寫資料的命令告訴給磁盤,這個命令可以通過IO總線傳給磁盤,那這里有個細節,其實我們常說的磁盤不僅僅是只包含存盤資料的媒介,還有介面,介面相信大家都熟悉,介面的意義不僅僅是為了連接到IO總線上的,其實這個介面里還有個叫做控制器的東西,控制器才是真正控制磁盤讀寫的東西,當CPU發出讀寫指令的時候,這個指令其實是告訴磁盤控制器的,以讀為例,當控制器收到讀的請求時,它告訴磁盤:“你把xx資料給我吧”,當機械硬碟經過轉動、尋道找到目標扇區后,把目標資料給磁盤控制器:“哥,這是你要的資料”,控制器收到資料之后,其實不會立馬通知CPU,因為需要讀的資料可能涉及到多個扇區,如果每讀一個扇區的資料就通知,會導致效率低下,
CPU:“控制器老弟,你這是搞事啊,我很忙的,每次搞這么點資料就通知我,能不能把我需要的資料都準備好,再通知我”,
“控制器”:“好的,CPU老哥”,
于是控制器內部就搞了個緩沖區,把讀到的資料先快取起來,然后通知CPU來取資料,但是問題又發生了...
CPU:“控制器老弟,資料你是準備好了,但是你給我的資料已經是損壞的,玩我呢!”
“控制器”:“CPU老哥,俺錯了,下次一定不會”,
于是控制器為了判斷讀到的資料是否發生了損壞,會先計算下校驗和,如果校驗和不通過,那么就不會通知CPU來取壞的資料了,
當緩沖區快要滿了或者需要讀的資料已經讀完了并且校驗資料也是OK的,這時控制器就會發出個中斷:“CPU老哥,你要的資料好了,過來取吧”,于是CPU屁顛屁顛的過來拿資料,當然它也是分批拿的,每次從控制器的緩沖區中一個位元組一個位元組的拿,直至取完,整個程序看起來還不錯,但是有個很嚴重的效率問題:CPU每次取資料的單位有點小(一個位元組),這樣勢必造成CPU多次往返,那有什么辦法解決這個問題呢?我們接著往下看,
緩沖
在講緩沖之前,我們先了解一下當我們的程式發出read的時候,資料是怎么回傳的,首先和設備打交道的時候,需要發起系統呼叫,系統呼叫會導致進入內核態,然后CPU去讀資料,讀到資料后,在把資料返給用戶程式,這時又回到用戶態,
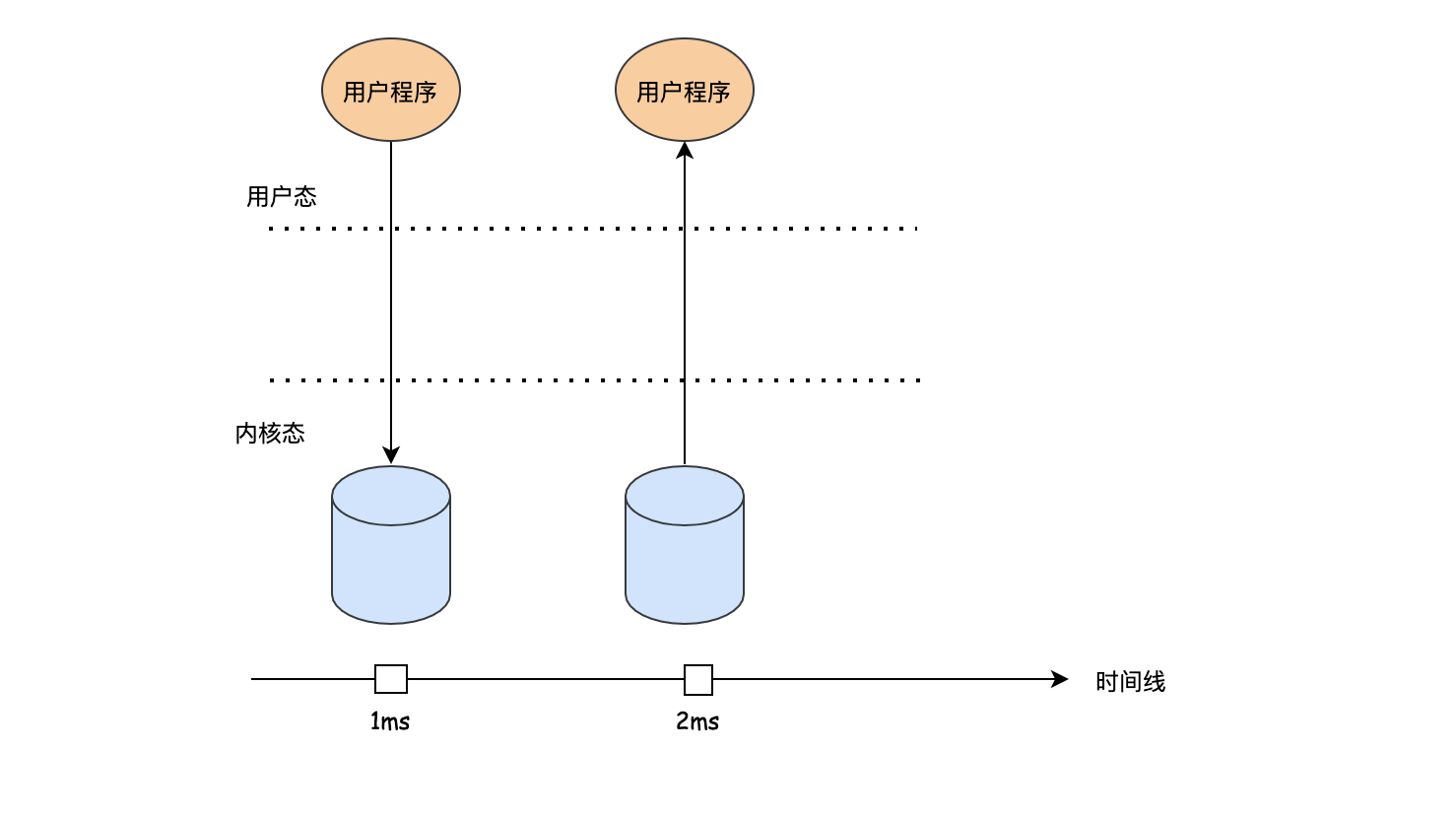
這里我們先著重看下資料從內核態到到用戶態的程序,通過上文我們知道CPU是一個位元組一個位元組的讀取資料的,當CPU拿到資料之后,可以有這樣幾個選擇:
-
每次讀到一個位元組后立馬發出中斷,然后由中斷程式把每個位元組交給用戶行程,用戶行程收到資料之后,再發起下個位元組的讀取,就這樣不停的回圈...,直至把資料讀完,這種模式的問題在于每個位元組都要喚起行程,然后用戶行程繼續阻塞等待下個位元組的到來,很傻很低效,
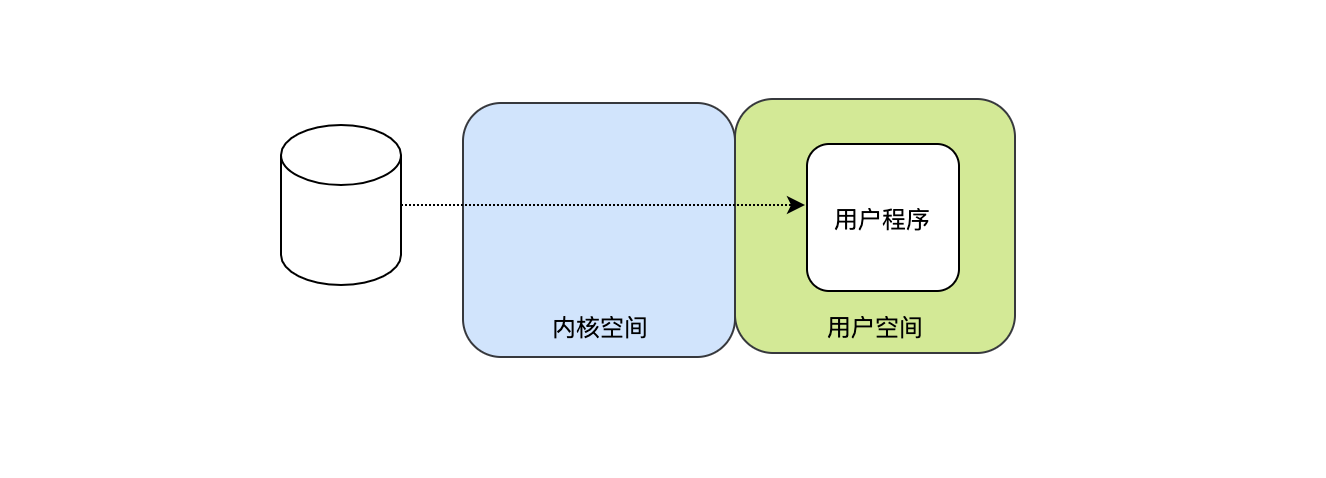
-
用戶程式可以每次多讀點資料,比如每次告訴CPU:“我要讀n個位元組”,CPU收到指令后去磁盤把資料讀到,當然這里肯定不是一個位元組一個位元組的發起中斷,不然和1無區別,由于一開始已經告訴CPU要讀n個位元組,所以要等讀滿n個位元組后才能發起中斷,那如何知道讀滿n個位元組了呢?這就需要緩沖了,可以在用戶空間開辟一個n個位元組的緩沖區,當緩沖區滿了,再發起中斷,相比第一種n次中斷,這里只需要一次中斷,是不是效率提高了許多,
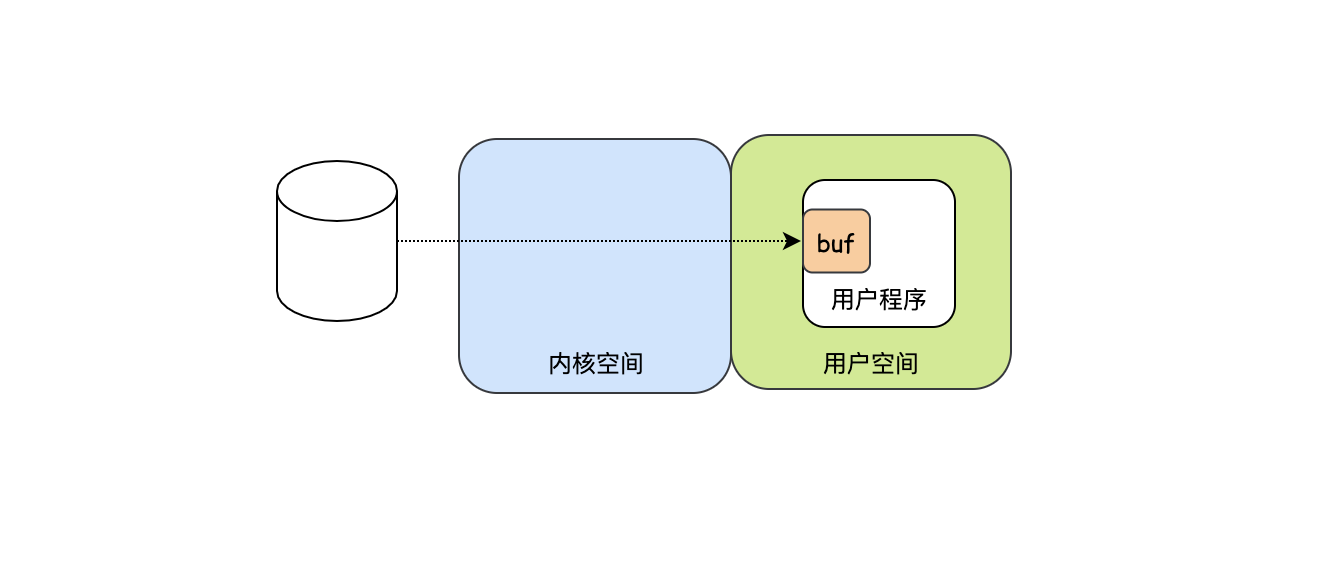
-
第二種方法解決了用戶程式低效的問題,但是不要忘記了還有CPU,CPU還是一個位元組一個位元組的把資料搬運到用戶的緩沖區中,這樣看CPU還是挺辛苦的,不僅要讀取資料,還要低效的把資料從內核空間搬運到用戶空間,注意這個在內核空間和用戶空間之間的切換還是挺耗費時間的,于是為了減少切換開銷,內核空間干脆也搞個緩沖區,等緩沖區有足夠多的資料之后,一次性的給到用戶程式,這樣是不是就高效多了,
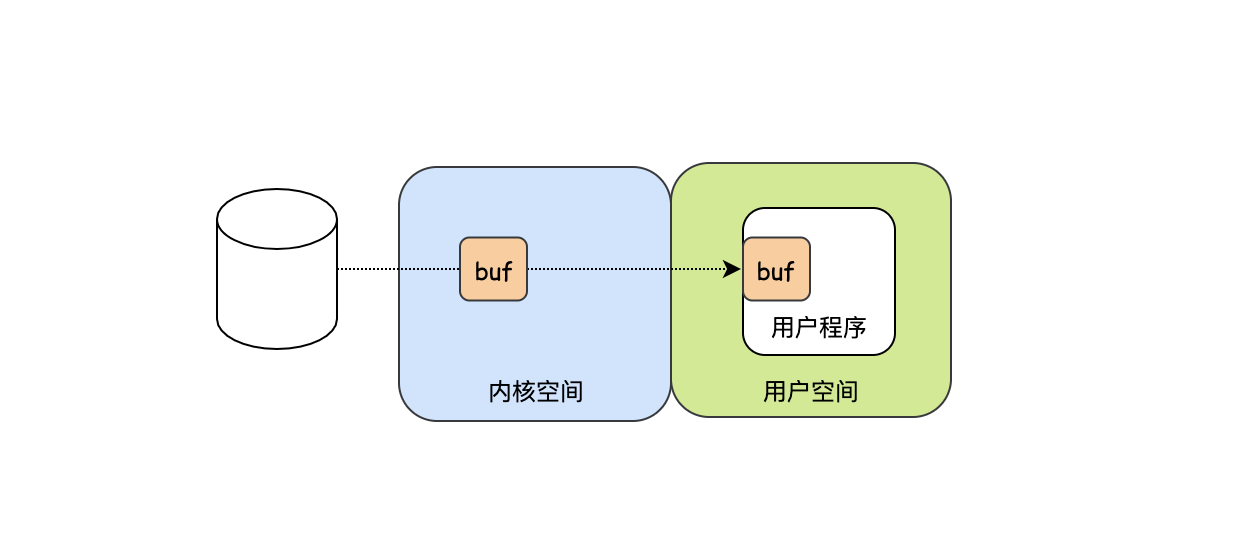
可以發現最后一種肯定是效率最高的,這也是現代作業系統普遍使用的方式,然而這種模式也不是百分百的完美,我們來看下相關的時序圖,
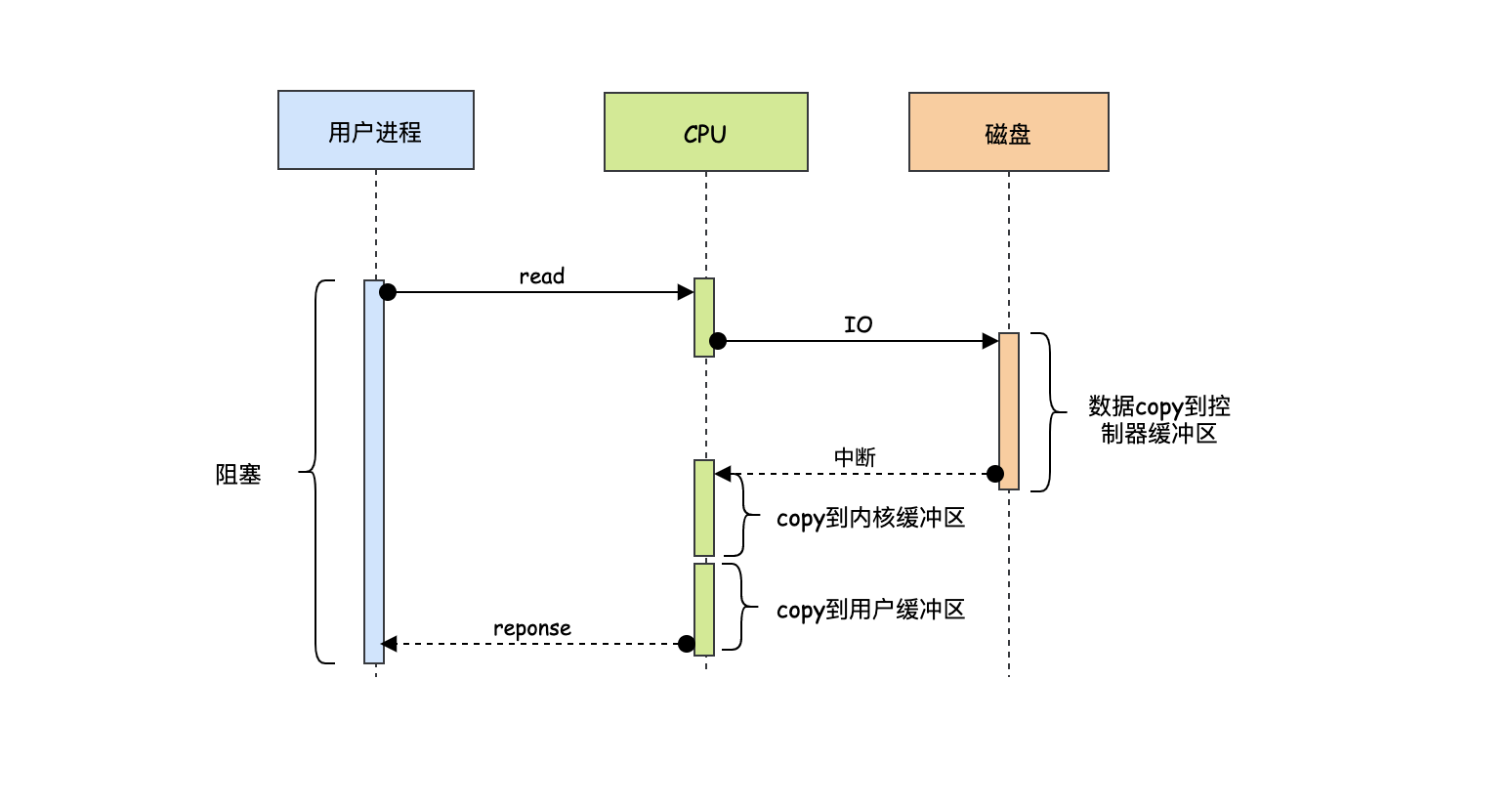
時序圖中我們先重點看下CPU這塊,可以發現當控制器的緩沖區滿了之后需要CPU把資料copy到內核緩沖區,然后CPU再把內核緩沖區的資料copy到用戶緩沖區,CPU不僅要負責資料的讀寫還要負責資料的搬運,
進階-DMA
“我堂堂CPU,竟然要為了緩慢的磁盤而卑躬屈膝,能不能給我安排個下手呀,和低等磁盤打交道的任務就交給下手去做吧,還有其他很多行程在等著我調度呢”,于是設計者們就意識到這個問題,為了讓CPU全身心的投入到調度、計算等作業中,后來就搞了個DMA(Direct Memory Access),中文名叫直接存取器存取,中文名挺抽象的,別急,我們接著往下看,
首先這個DMA它內部也有些暫存器,這些暫存器可以存什么呢?答案是記憶體地址,嚴格來說是內核緩沖區的地址,有了DMA后,read操作不再由CPU告訴磁盤,而是由CPU告訴DMA:“DMA同學現在某個程式員要讀xx資料,你把xx資料放到記憶體地址是0x1234的記憶體里去吧”,DMA收到老大CPU的通知后:“收到了老大,這種小事交給小弟吧,你去忙吧”,到這里CPU就去忙別的事了,然后DMA就去通知我們的磁盤控制器了:“你先把xx資料的這一部分直接讀到0x1234記憶體里去吧,讀完告訴我一下,我這邊還有xx資料的另一部分”,磁盤控制器:“好的,老大哥”,就這樣每次控制器讀完一部分資料之后就會通知DMA,然后DMA讓它再讀下一個資料,直至把需要讀的資料讀完,在讀完了資料之后,肯定不能完事呀,這時得告訴老大哥CPU,于是DMA發出一個中斷:“CPU大哥,資料已讀取完畢,請享用~”,CPU收到通知后,發現資料已經在內核緩沖區了,不需要親自干一個位元組一個位元組搬運的鳥事了,而且這期間CPU指揮了三次交通(調度)、扶了四個老奶奶過了馬路(計算),
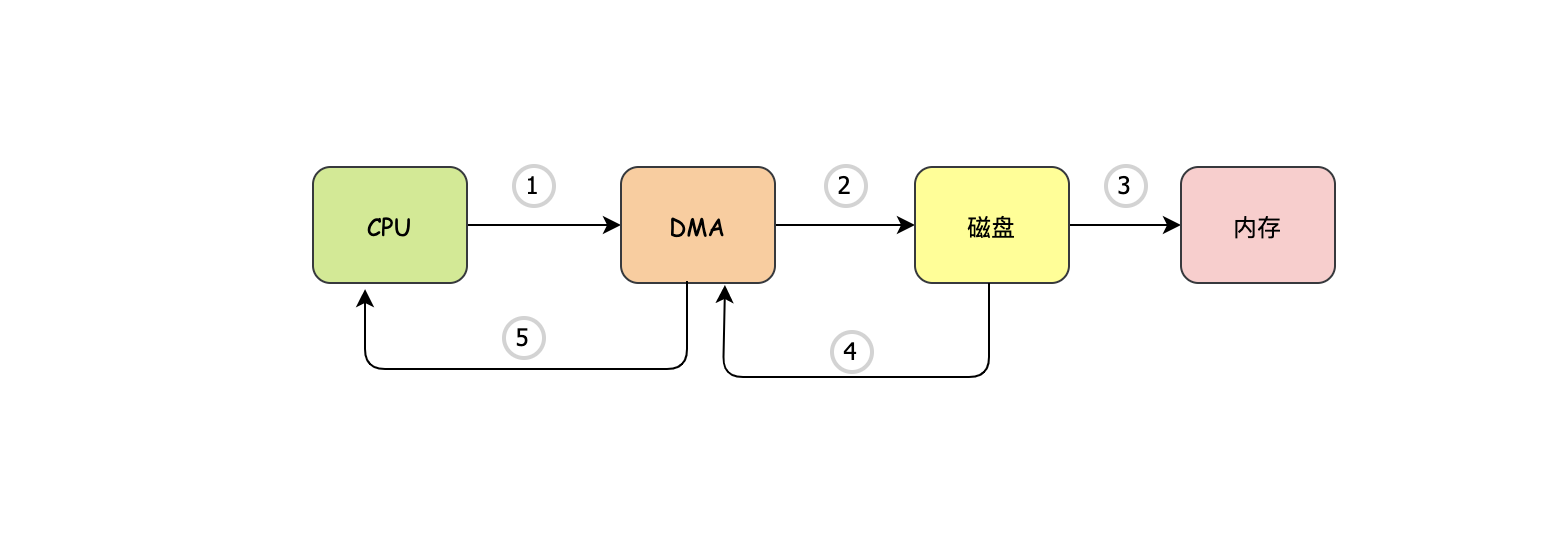
-
CPU告訴DMA
-
DMA告訴磁盤
-
磁盤讀完之后告訴DMA
-
DMA如果還需要讀的話,會重復2,3步驟
-
DMA干完活之后通知CPU
DMA的出現無疑是幫助了CPU很多,特別是和IO設備打交道這塊,
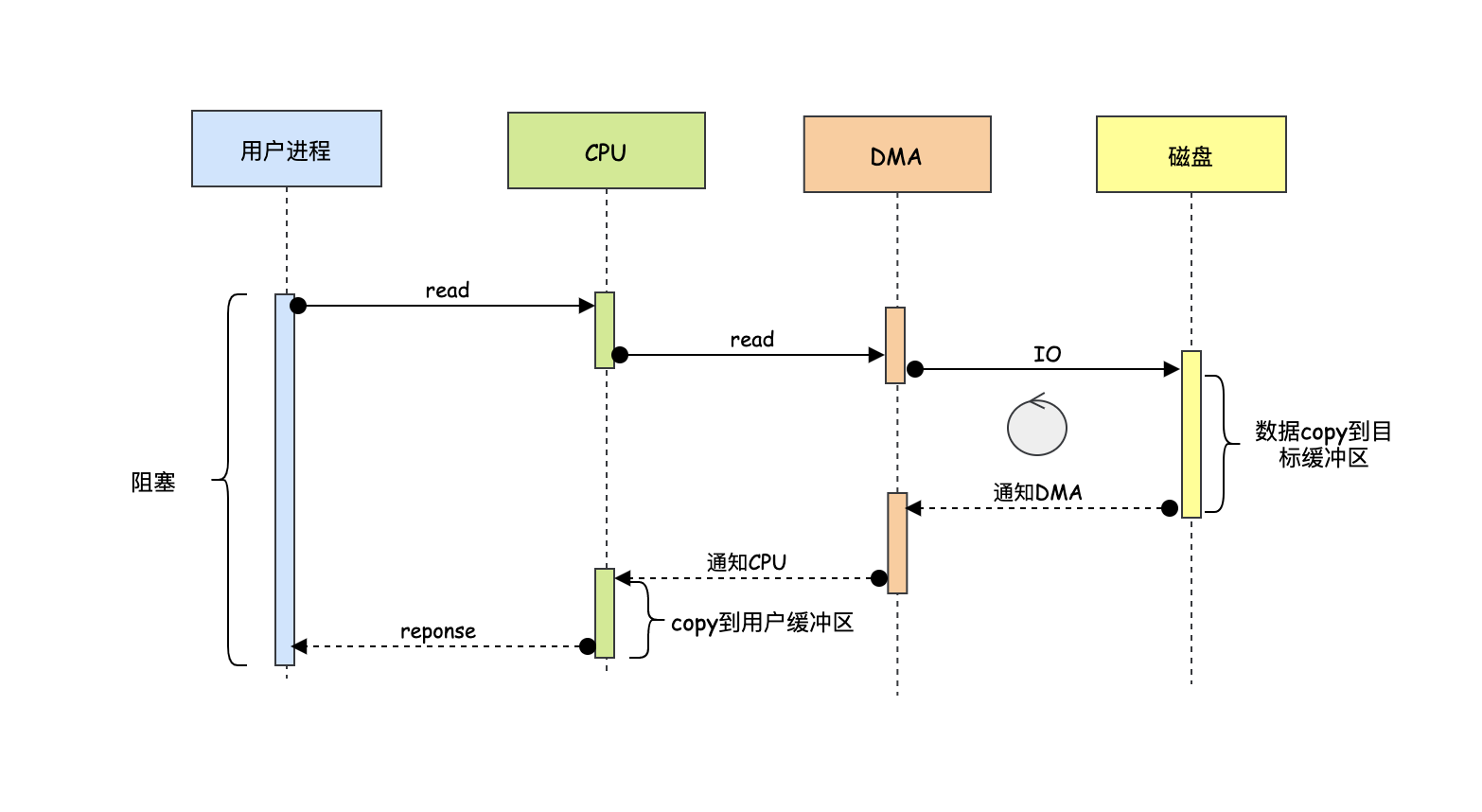
正常來說我們的程式在發起讀資料后,需要等待資料的回傳,因此需要CPU把內核緩沖區的資料再次COPY到用戶緩沖區中,同時整個程序用戶行程是阻塞的(因為要等資料),這一切看起來很合理,然而其實有這樣一種場景:我們需要把讀出的資料通過網路發出去,比如kafka,我們知道kafka是非常經典的訊息引擎,當消費者需要消費訊息的時候,kafka中的broker會把資料讀出來,然后發給我們的消費者,
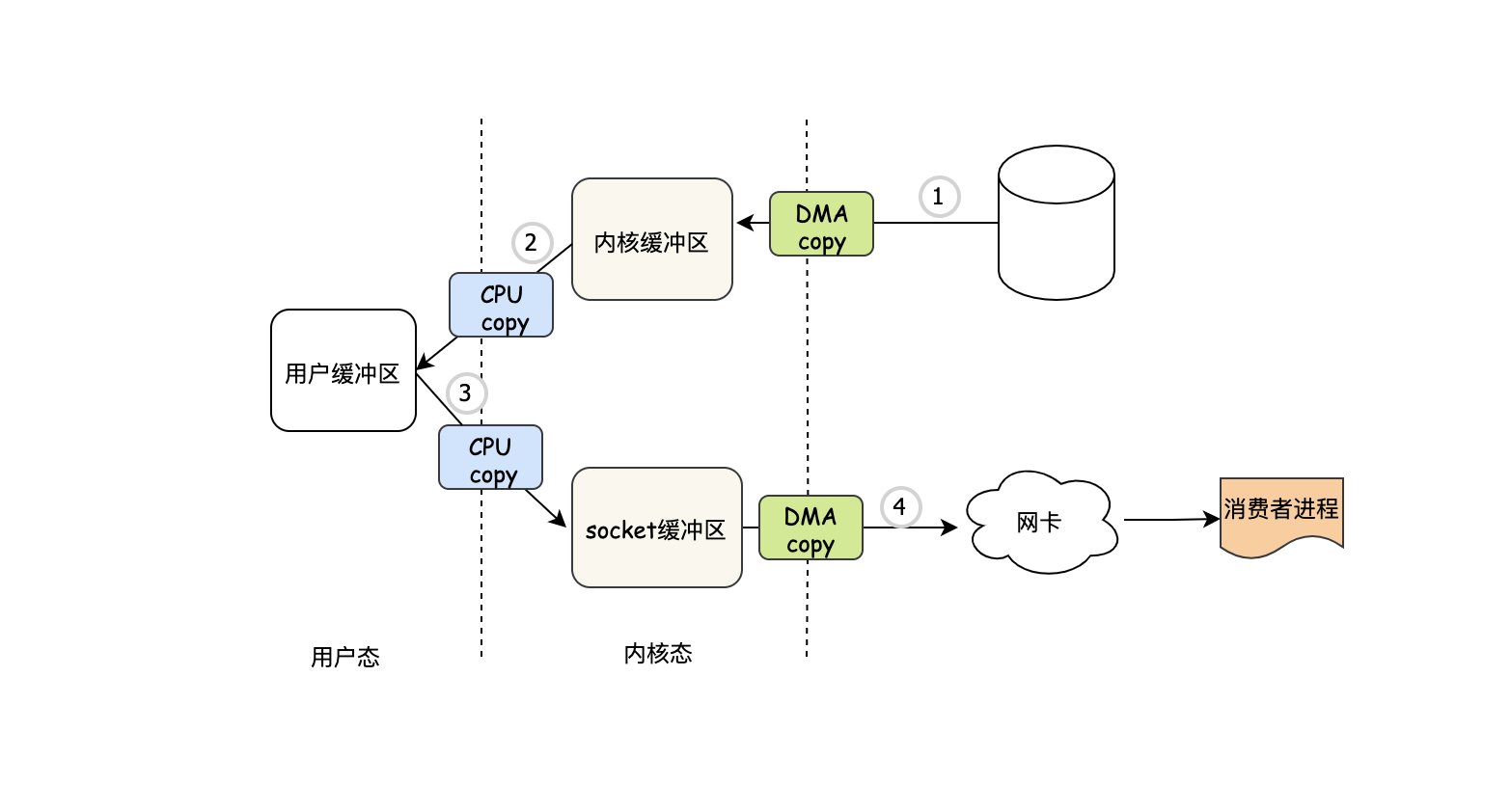
圖中有兩次看起來非常沙雕的操作,分別是第2步和第3步,關鍵這兩步都需要CPU親自參與搬運,并且涉及到內核態->用戶態->內核態的背景關系切換,這個背景關系切換會導致什么呢?答案就是CPU需要進行現場保護(活干到一半就被打斷了,等忙完了回來還要接著干),這個保護需要花費一定的開銷,比如把當前的運行狀態給保存下來,程式執行到哪了,暫存器該保存什么值...,
那有什么辦法能省掉這次的開銷呢?
升華
mmap + write
其實明眼人都看出來了,沒必要把一份資料copy來copy去的,直接用內核態的緩沖區不就行了,這就是mmap(記憶體映射),我們還是先來看個例子,通過例子你就明白mmap的好處了:
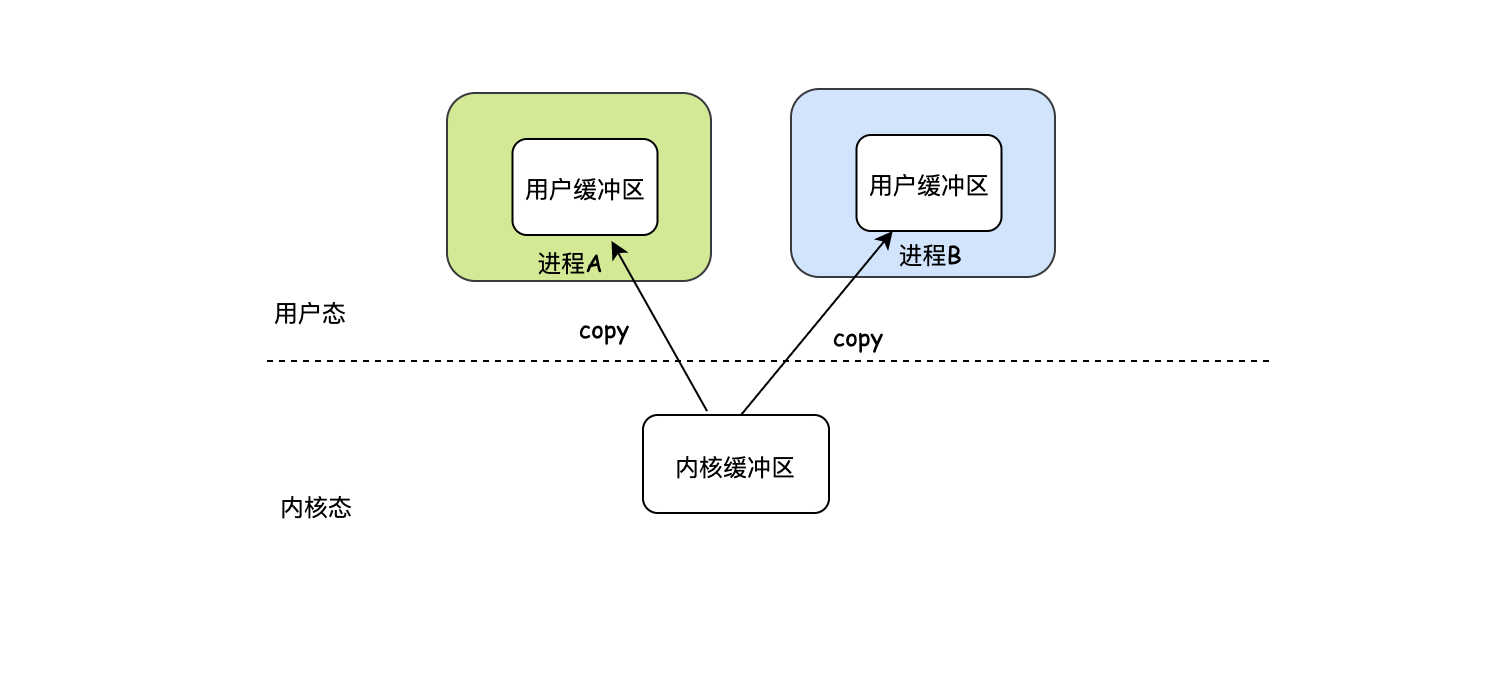
現在有兩個行程A和B,他們都需要讀同一份資料,因此每個行程都要開辟一塊用戶態的緩沖區,即使資料是一樣的,并且CPU還要發生兩次copy,而且這只是兩個行程,如果有更多的行程勢必造成更多的記憶體空間浪費,于是就出現了mmap,有了mmap之后,不需要cpu copy資料了,并且行程A和行程B共享用戶空間的一塊記憶體,然后這塊記憶體和內核空間的記憶體打通,注意這里并不是copy而是開啟了一個映射,相當于開了一個VIP通道,有了VIP通道之后,同一份資料對于不同的行程不需要維護不同的記憶體空間了,因為大家共享一個公共的記憶體空間,
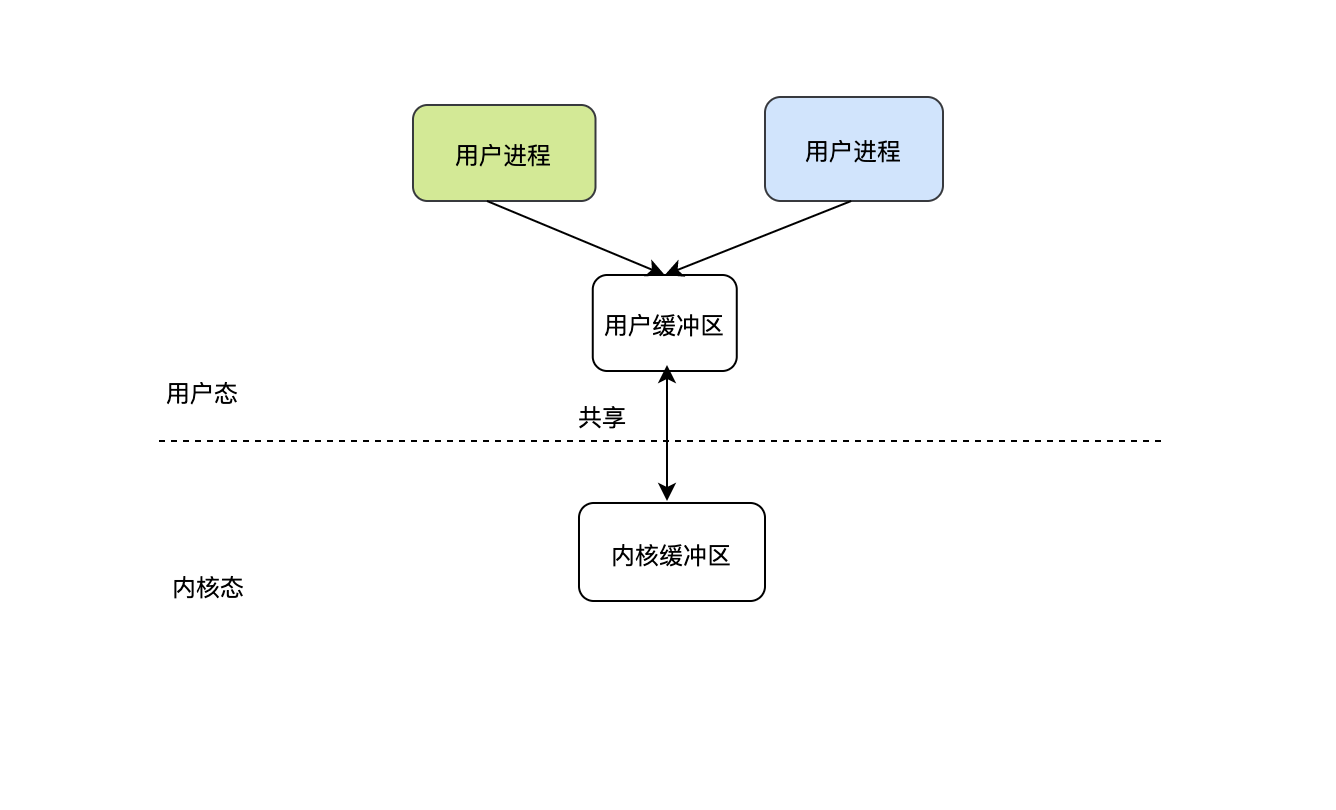
mmap只是打通了用戶空間和內核空間之間的通路,可以說路是通了,接下來還要發資料呀,因此這時一般呼叫write把資料發出去,有了mmap+write ,我們再來看看這時資料是如何發出的:
-
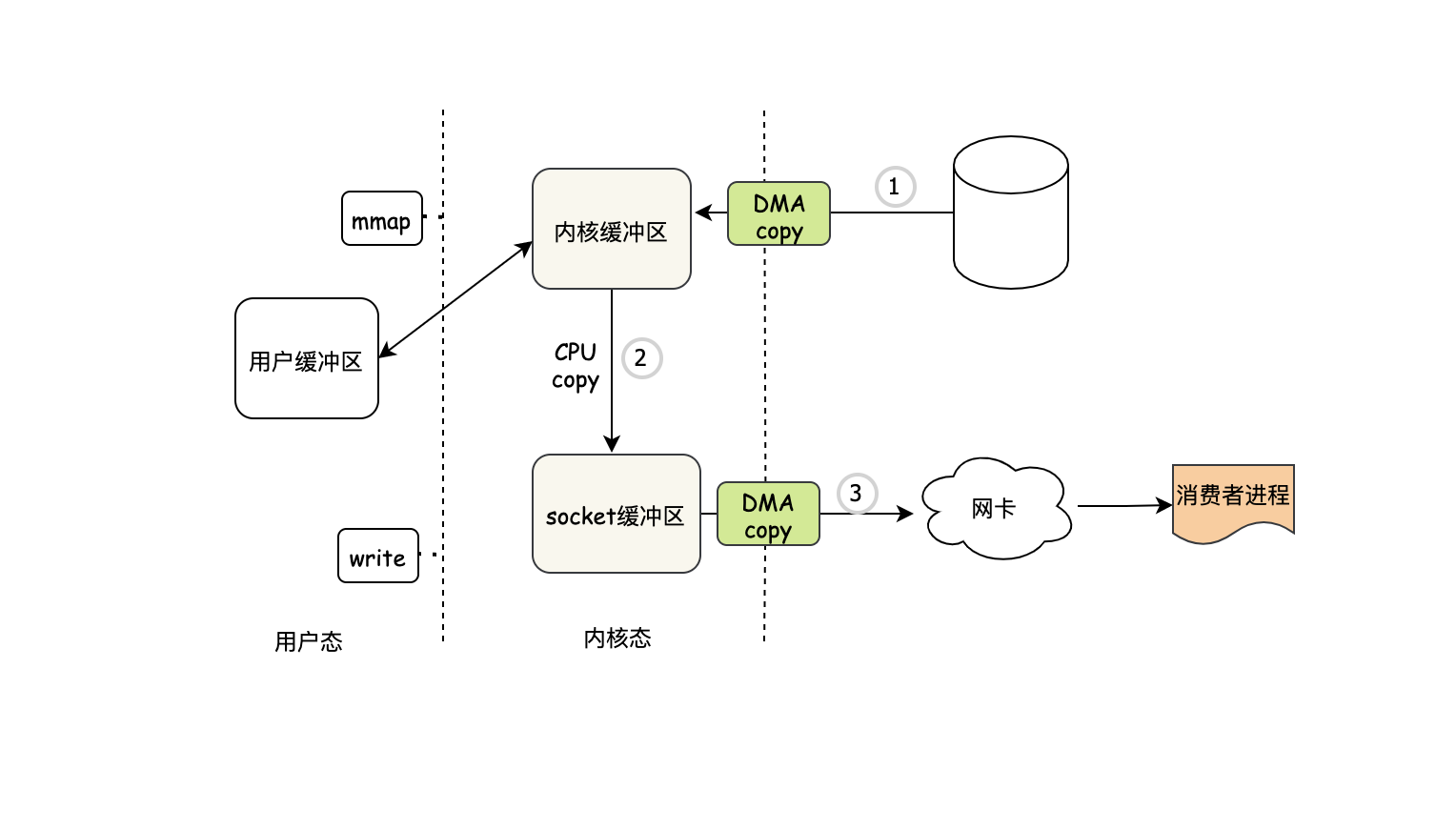
首先肯定是程式發出mmap系統呼叫請求,然后DMA把資料copy到內核緩沖區去
-
DMA copy完之后,把內核緩沖區映射到用戶緩沖區,注意映射和copy不一樣,比copy的開銷小
-
然后用戶程式再次發起write請求
-
這時系統會把內核緩沖區的資料直接發到socket緩沖區
-
DMA copy socket緩沖區資料到網卡
通過 mmap + write 的方式可以發現少了一次CPU copy,但是系統呼叫并沒有減少,有沒有什么辦法讓系統呼叫再少些?
sendfile
沒有什么能阻止進步的腳步,于是出現了sendfile,有了sendfile函式之后,首先它不需要進行兩次系統呼叫,只需要一次系統呼叫,當我們sendfile之后等于告訴系統:“幫我把xx資料直接發出去吧,別再copy或者映射進來了,俺不需要,直接發出去就好”,
-
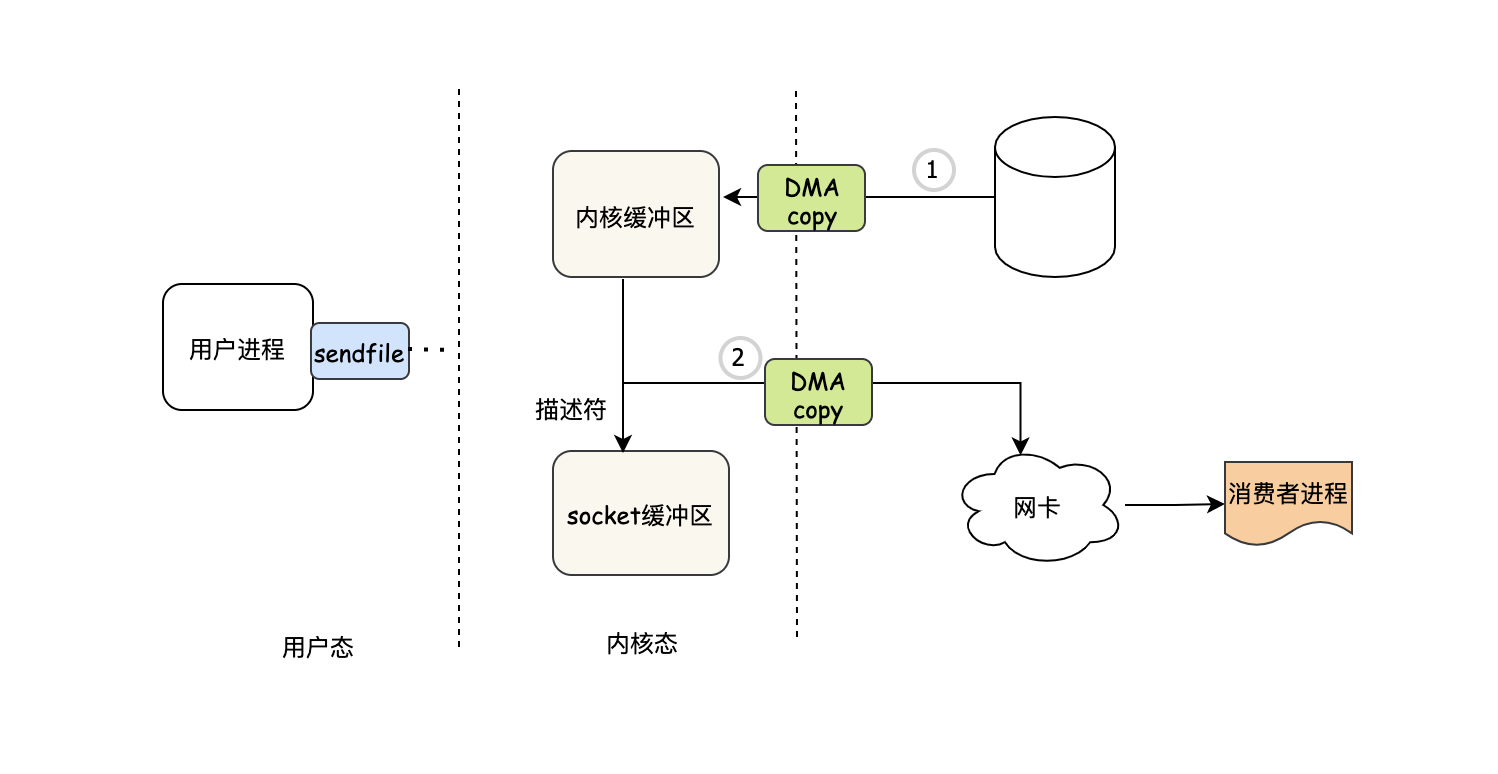
當我們發起sendfile之后,首先會切到內核態
-
然后DMA把資料copy到內核緩沖區
-
DMA把socket描述符等傳到socket緩沖區
-
同時DMA把資料直接從內核緩沖區copy到網卡
可以發現這種方式是目前最優的方式了,通過sendfile+DMA技術可以實作真正的零拷貝,整個程序都不要cpu搬運資料,也沒有背景關系切換,kafka就是利用這種方式來提供吞吐的,
最后
微信搜一搜【假裝懂編程】,關注牛逼知識搶先版,快人一步,勝人一籌,贏在起跑線上,另外這里給大準備了很多牛逼的book:


往期精彩:
-
程式員小扎-位元跳動公司的二面
-
程式員小扎-位元跳動公司的一面
-
內功大增!從機械硬碟和固態硬碟的結構來看IO
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375891.html
標籤:其他