參考自:公眾號小林coding的圖解系統
鏈接:https://pan.baidu.com/s/15zW9NaAIL5FJBeEF2aFdxQ
提取碼:fkwx
硬體部分
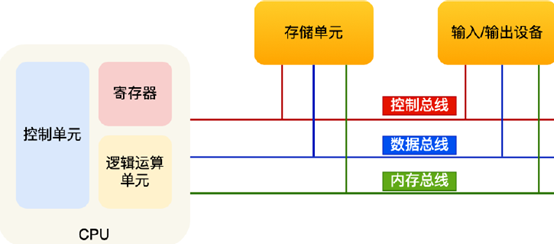
首先我們要明確一個概念,讀寫速度越快(花費的CPU時鐘周期越少)的硬體就越靠近CPU,且越昂貴,
CPU(中央處理器)
等于人體的大腦,是計算機得以運行的根本,32位CPU一次可裝入4位元組資料(32bits),64位CPU一次可裝入8位元組資料(64bits),
64位CPU的優勢在于能夠計算的數值更大,比如(2^40)這個數,64位CPU可一次性裝入并運算,放到32位CPU上只能把數拆分為高位與低位,分兩次裝入,
事實上,如果不計算2^32以上的大數,32位與64位CPU之間沒有區別,只不過在32位CPU上運行的程式并不能直接移植到64位系統上,
在CPU內部,還有多種暫存器,包括但不限于通用暫存器(存放運算的資料)、程式計數器(也就是PC,PC指標指向了下一條指令在記憶體的地址)、指令暫存器(存放指令本身,指令被執行前,會被裝載在這里),
總線
分為以下三種:
1、地址總線:用于指定CPU要操作的記憶體地址,32位CPU采用的地址總線是并行的,也就是說有32根地址總線,可操作的地址空間是4GB(2^32 bytes)
2、資料總線:用于讀寫記憶體資料,32位CPU最好也配備32跟資料總線
3、控制總線:用于發送和接收信號,比如中斷等信號,CPU收到信號就會進行回應
存盤器
存盤器分為很多種,記憶體、cache、暫存器以及硬碟,他們的特性、性能、應用場景各不相同,總的來說,就是讀寫速度越快的越貴,容量越少,除了硬碟之外,其他存盤器在關機后,內部存盤的資料都會丟失,
暫存器
暫存器的數量可達數十甚至數百個,32位CPU中大多數暫存器都能存盤4位元組資料,64位CPU則是8位元組,暫存器的讀寫一般只需要花費半個時鐘周期,
CPU cache
即高速緩沖存盤器,使用SRAM芯片,讀寫速度次于暫存器,cache共分為三級,
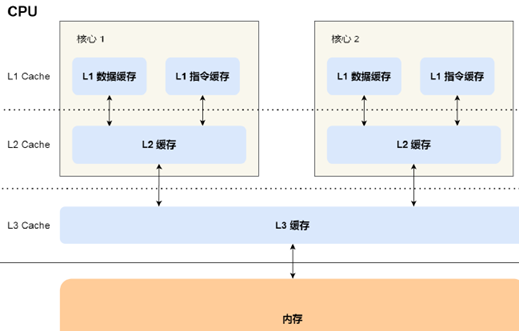
L1級讀寫需要2-4個時鐘周期,大小在幾十到幾百KB,每個CPU核心都有自己的L1高速快取,在L1里指令與資料時分開存放的,所以通常分成指令快取與資料快取,
L2級讀寫需要10-20個時鐘周期,大小在幾百到幾千KB,其位置比L1更遠離CPU,同樣地,每個CPU核心都有自己的L2高速快取,
L3級讀寫需要20-60個時鐘周期,大小在幾MB到幾十MB,多個CPU核心共享L3高速快取,
記憶體
使用DRAM芯片,比SRAM便宜(意味著讀取速度更慢,容量更大),其訪問資料需要200-300個時鐘周期,
硬碟
分為SSD(固態硬碟)以及HDD(機械硬碟),斷電后也能保存資料,固態的速度比記憶體慢10-1000倍,機械比記憶體慢十萬倍,因為內部是靠磁盤旋轉,然后靠磁頭讀取資料的,
存盤器層次關系
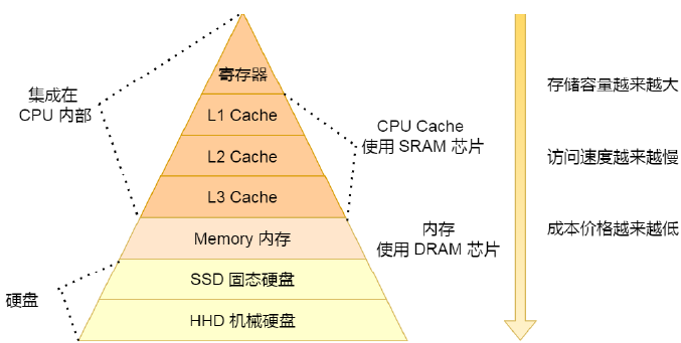 CPU并不會跟每一種存盤器進行資料交換,而是通過暫存器,暫存器再通過cache…,因此每一種存盤器只會與相鄰的存盤器進行資料交換,
CPU并不會跟每一種存盤器進行資料交換,而是通過暫存器,暫存器再通過cache…,因此每一種存盤器只會與相鄰的存盤器進行資料交換,
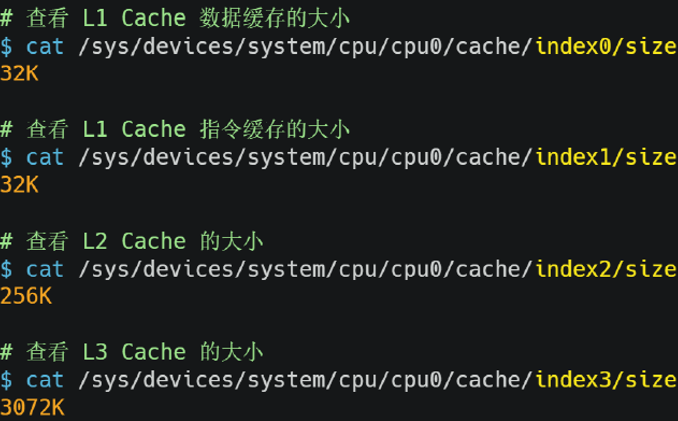
細聊cache
在linux系統中,我們可以根據一下命令查看三級高速快取的大小,
CPU讀取資料時會先訪問cache,如果cache中恰好有所需的資料就直接讀取而不必再訪問記憶體,這就是快取命中,
cache從記憶體中一塊一塊地讀取資料,這些小塊稱為cache line(快取塊),
CPU訪問記憶體資料時同樣是一塊塊讀取的,這些塊稱為Block(記憶體塊),
要把記憶體塊放到cache里面的話,就需要把一塊記憶體塊的地址映射到快取塊的地址上,通過地址取模可以分配快取塊行號,但還需要其他資訊才能唯一指定快取塊中的資料塊,
具體資料結構如下:
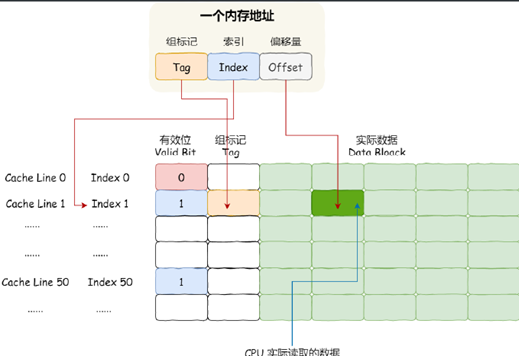
CPU訪問一個記憶體地址的時候,需要4個步驟:
1、找到資料對應的cache line地址
2、判斷有效位,如果無效就直接訪問記憶體并重新加載資料
3、對比記憶體地址和cache line的組標記,如果不一致就直接訪問記憶體并重新加載資料
4、根據記憶體地址的偏移量資訊從cache line中讀取對應的字
快取一致性
即保持快取中的資料與記憶體中的一致,對于單核CPU來說,只需要在快取未命中的時候把對應的cache block標記為臟,然后再把資料寫回記憶體就可以了,但是對于多核CPU(只共享L3 cache),還需要考慮多個CPU間的快取一致性問題,多核CPU的快取一致性需要有以下兩種機制:
1、寫傳播:某個CPU核心的快取更新需要同步到其他CPU
2、事務串行化:某個核心對資料的操作順序,在其他核心看來也是一致的,打個比方,一個核心的快取里的資料i先更改為100,再更改為200,那么這個程序放在別的核心里面也是一樣的流程,
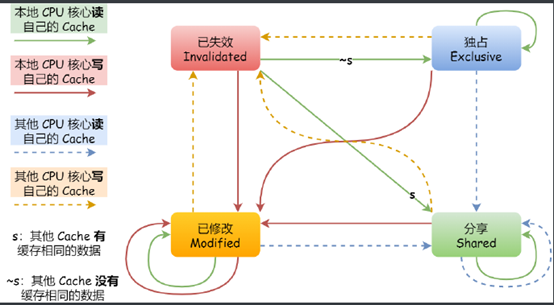
MESI協議
為了實作CPU快取一致性而生的協議,主要定義了cache line的四種狀態:modified(已修改)、exclusive(獨占)、shared(共享)、invalidated(已失效),
1、modified:表示當前快取塊的資料已被更改,并且還沒有與記憶體同步,
2、exclusive:表示資料還沒有更改,且沒有與其他CPU快取分享,
3、shared:多個CPU快取都保存著這份資料,
4、invalidated:資料失效,不能再讀取這份資料了,
舉黎姿(黎姿永遠的女神!):
1、1號CPU從記憶體讀取變數i,此時其他CPU并沒有快取i,因此在1號CPU里對應的快取塊應標記為exclusive,
2、2號CPU也從記憶體讀取了i,此時會發送資訊給其他CPU,由于1號CPU快取了i,因此快取塊應該從exclusive變為shared,
3、1號CPU更改了i的值,由于此時是shared柱狀態,需要向其他所有CPU發送廣播,請求他們把i對應的快取塊標記為invalidated,1號CPU修改完i值后,快取塊標記為modified,
4、如果1號繼續修改modified資料,就無須再進行廣播了,
5、1號CPU的i值對應的快取塊將被替換,由于此時是modified狀態,就會在被替換時把i寫回記憶體,
在exclusive和modified狀態下修改資料都是不需要發送廣播的,如果采用總線嗅探技術,每次修改都需要廣播,無疑會增大總線壓力,
狀態轉移圖:
偽共享
所謂的偽共享,是指特定情況下,兩個CPU讀取同一塊資料時,本該都是shared狀態,然而在一系列特定的操作后,卻變成一個已修改,另一個無效,且無法跳出這個狀態回圈,
故事伊始,我們假設有a、b兩個變數,它們都不在cache,我們也有兩個執行緒,它們分別系結了1號CPU和2號CPU,假設執行緒1只讀寫a,執行緒2只讀寫b,
1、1號CPU讀取a,但a、b恰好分在同一個cache line,此時應該是exclusive狀態,
2、2號CPU讀取b,此時應該是shared狀態,
3、1號CPU要修改a,那么就先進行廣播,請求2號把cache line修改為invalidated,然后1號標記為modified并修改,
4、2號CPU要修改b,由于是目前的cache line是invalidated,為了同步,應該先把1號CPU的modified資料協會到記憶體,2號CPU再從記憶體讀取包含b的一塊cache line,把狀態更改為modified并修改,
5、如果1號與2號CPU交替修改a和b,就會重復步驟3和4,那么cache的作用就體現不出來了(每次修改資料都要從記憶體讀進來),
綜上所述,對于多執行緒共享的熱點資料,也就是經常會修改的資料,應當避免分在同一個cache line,
執行緒調度
linux系統中的任務有優先級,優先級越高則越快相應,分為實時任務(優先級0-99),普通任務(優先級100-139),
對于不同的任務,有以下三種調度類:
1、deadline和realtime:用于實時任務,有以下特點:一、按照deadline(ddl)最近的優先調度,二、相同優先級排在前面的先調度,三、每個任務都有時間片,用完之后就放回佇列尾部,支持搶占式任務調度,
2、fair:由CFS調度器管理,應用于普通任務,
每個CPU都有自己的運行佇列,三種調度類各占一個,分別為dl_rq、rt_rq、csf_rq,其中csf_rq根據vruntime(任務的虛擬運行時間)大小來排序,
中斷
搞單片機的應該聽過,中斷是作業系統回應硬體設備請求的機制,一旦發生中斷,當前行程立刻掛起,并保護現場,然后去執行中斷處理程式,處理完畢再回來恢復現場,(然而單片機學的并不好,有些術語好像并沒有用對),
如果整個中斷流程用時太長,就會降低運行效率,因此linux系統把中斷分為兩部分,上半部分處理與硬體相關的事,下半部分用于后續處理,
比如,網卡接收網路包的時候,先是把這些包讀到記憶體中,完成上半部分,然后內核觸發軟中斷,進行網路資料包決議,下半部分用時一般較長,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/376029.html
標籤:其他