目錄
引言
一,基本概念與術語
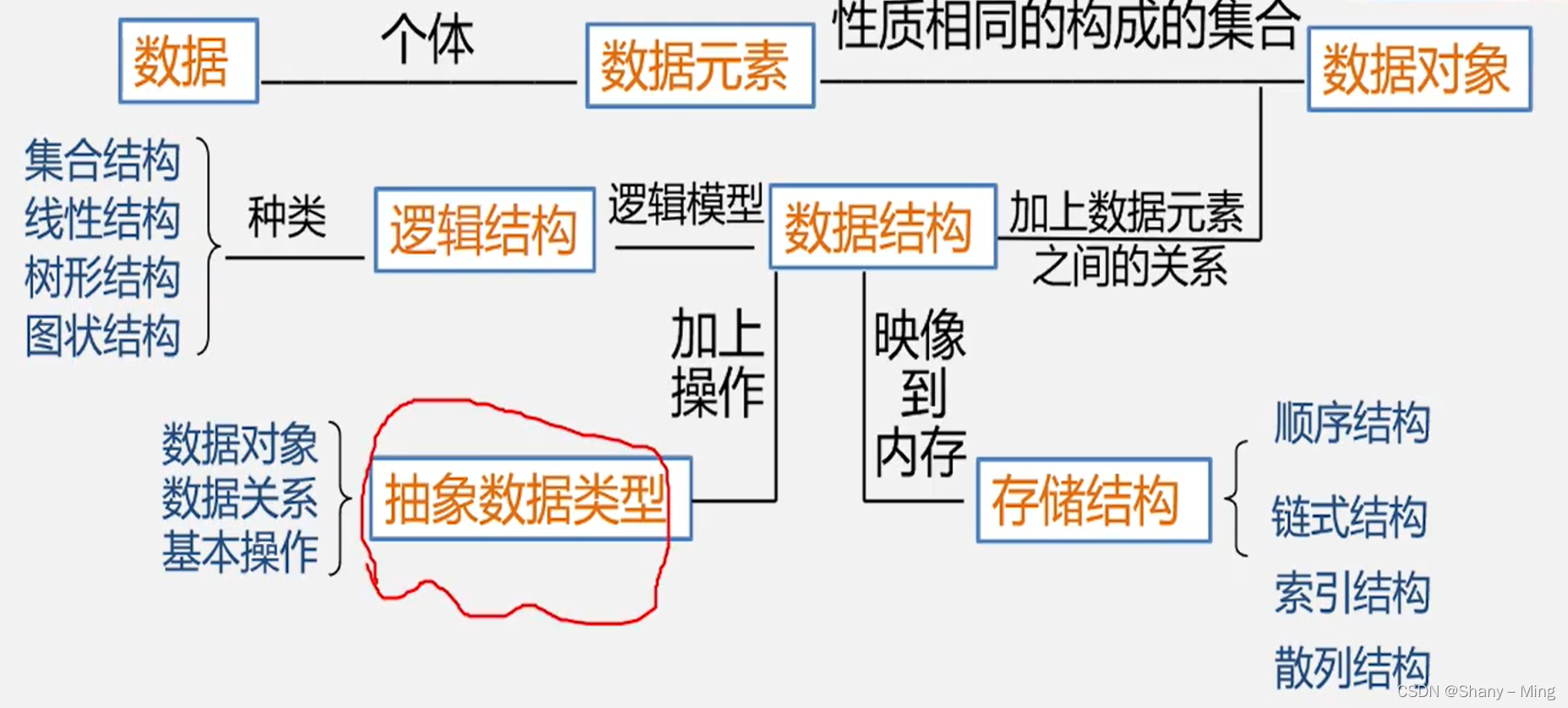
1.資料、資料元素、資料項和資料物件
2.資料結構
1)邏輯結構
2) 存盤結構
3).索引存盤結構
4).散列存盤結構
3.資料型別與抽象資料型別
1).資料型別
2).抽象資料型別
4.概念小結
二.演算法和演算法分析
1.演算法的定義及特性
2.演算法的時間復雜度
1).陳述句頻度及計算方式
2).演算法時間復雜度的定義
3).最好、最壞和平均時間復雜度
三.演算法空間復雜度
引言
為什么學習資料結構和演算法?
憑借一句話獲得圖靈獎的Pascal語言之父——Nicklaus Wirth,讓他獲得圖靈獎的這句話就是他提出的著名公式:
“程式=資料結構+演算法”
----這個公式展現了程式的本質:
演算法其實就是用于解決某一類問題的公式與思想,(給出問題的數學模型)而資料結構就是資料的組織、管理和存盤格式,其使用目的是為了高效的訪問和修改資料,至于程式就是計算機處理問題的一系列指令,
程式設計的實質是對確定的問題選擇一種好的資料結構,并設計一種好的演算法,
一,基本概念與術語
對于基本概念的掌握,不要求完全一致,但含義不能有誤
1.資料、資料元素、資料項和資料物件
資料(Data)是客觀事物的符號表示,是所有能輸入到計算機中并被計算機程式處理的符號的總稱(集合),是資訊的載體;是對客觀事物的符號化表示;可以被計算機識別、存盤和加工,資料不僅僅包含整型、實型等數值型別,還包含圖形、影像、聲音、視頻及影片等非數值型別 ,
資料元素(DataElement)是資料的基本單位,在計算機中通常作為一個整體進行考慮和處理,在有些情況下,資料元素也稱為元素、記錄等,資料元素用千完整地描述一個物件,如前一節示例中的一名學生記錄,樹中棋盤的一個格局(狀態),以及圖中的一個頂點等,
資料項(DataItem)是組成資料元素的、有獨立含義的、不可分割的最小單位,例如,學生基本資訊表中的學號、姓名、性別等都是資料項,
資料物件(DataObject)是性質相同的資料元素的集合,是資料的一個子集,例如:整數資料物件是集合N={O,士1'士2,…}, 字母字符資料物件是集合C={'A','B',…,'Z','a','b',…,'z'},學生基本資訊表也可以是一個資料物件,由此可以看出,不論資料元素集合是無限集(如整數集),或是有限集(如字母字符集),還是由多個資料項組成的復合資料元素(如學生表)的集合,只要集合內元素的性質均相同,都可稱之為一個資料物件,
據上,我們可總結他們間的關系:資料>資料物件>資料元素>資料項
2.資料結構
說了那么多,接下來,我們就來說說什么是資料結構
資料結構(DataStructure)是相互之間存在一種或多種特定關系的資料元素的集合,換句話說,資料結構是帶”結構"的資料元素的集合,“結構”就是指資料元素之間存在的關系,
資料結構分為兩類:邏輯結構與存盤結構
1)邏輯結構
資料的邏輯結構是從邏輯關系上描述資料,它與資料的存盤無關,是獨立千計算機的,因此,資料的邏輯結構可以看作是從具體問題抽象出來的數學模型,
資料的邏輯結構有兩個要素:一是資料元素;二是關系,資料元素的含義如前所述,關系是指資料元素間的邏輯關系,根據資料元素之間關系的不同特性,通常有四類基本結構,它們的復雜程度依次遞進

(1)集合結構資料元素之間除了“屬于同一集合”的關系外,別無其他關系,例如,確定一名學生是否為班級成員,只需將班級看做一個集合結構,
(2)線性結構資料元素之間存在一對一的關系,例如,將學生資訊資料按照其入學報到的時間先后順序進行排列,將組成一個線性結構,
(3)樹結構資料元素之間存在一對多的關系,例如,在班級的管理體系中,班長管理多個組長,每位組長管理多名組員,從而構成樹形結構,
(4)圖結構或網狀結構資料元素之間存在多對多的關系,例如,多位同學之間的朋友關系,任何兩位同學都可以是朋友,從而構成圖狀結構或網狀結構,
其中集合結構、樹結構和圖結構都屬千非線性結構,
2) 存盤結構
資料物件在計算機中的存盤表示稱為資料的存盤結構,也稱為物理結構,
1.順序存盤結構
順序存盤結構是把資料元素存放在連續的存盤單元里,資料元素之間的邏輯關系是通過資料元素的位置,(在前面的資料元素就存在前面;在后面的資料元素就存在后面)C語言用陣列來實作順序存盤結構
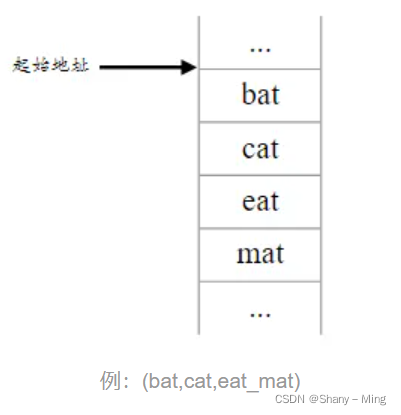
2.鏈式存盤結構
順序存盤結構要求所有的元素依次存放在一片連續的存盤空間中,而鏈式存盤結構,無需占用一整塊存盤空間,但為了表示結點之間的關系,需要給每個結點附加指標欄位,用于存放后繼元素的存盤地址,所以鏈式存盤結構通常借助于程式設計語言的指標型別來描述


3).索引存盤結構
在存盤節點資訊的同時,還建立附加索引,索引表中的每一項稱為一個索引項,索引項的一般形式是:(關鍵字,地址)
關鍵字是能唯一標識一個結點的那些資料項,若每個結點在索引表中都有一個索引項,則該索引表稱之為稠密索引(Dense Index),
若一組結點在索引表中只對應一個索引項,則該索引表稱之為稀疏索引(Sparse Index),
就如我們手機中的通訊錄,
4).散列存盤結構
散列存盤,又稱hash存盤,是一種力圖將資料元素的存盤位置與關鍵碼之間建立確定對應關系的查找技術,
散列法存盤的基本思想是:由節點的關鍵碼值決定節點的存盤地址,散列技術除了可以用于查找外,還可以用于存盤,
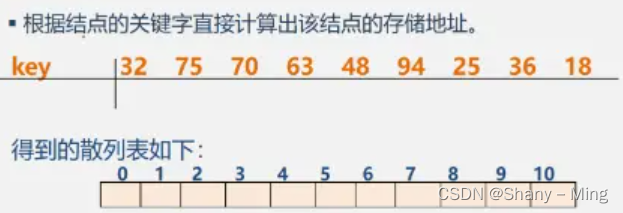
3.資料型別與抽象資料型別
1).資料型別
說到資料型別,其實我們并不陌生,就如c語言中的int,char,float,double等基本資料型別;陣列、結構、共用體、列舉等構造資料型別;還有指標、空(void)型別,用戶也可用typedef自己定義資料型別 ,
資料型別是一個值的集合和定義在這個值集上的一組操作的總稱
例如,C語言中的整型變址,其值集為某個區間上的整數(區間大小依賴于不同的機器),定義在其上的操作為加、減、乘、除和取模等算術運算;而實型變數也有自己的取值范圍和相應運算,比如取模運算是不能用于實型變數的,
資料型別=值的集合+值集合上的一組操作
2).抽象資料型別
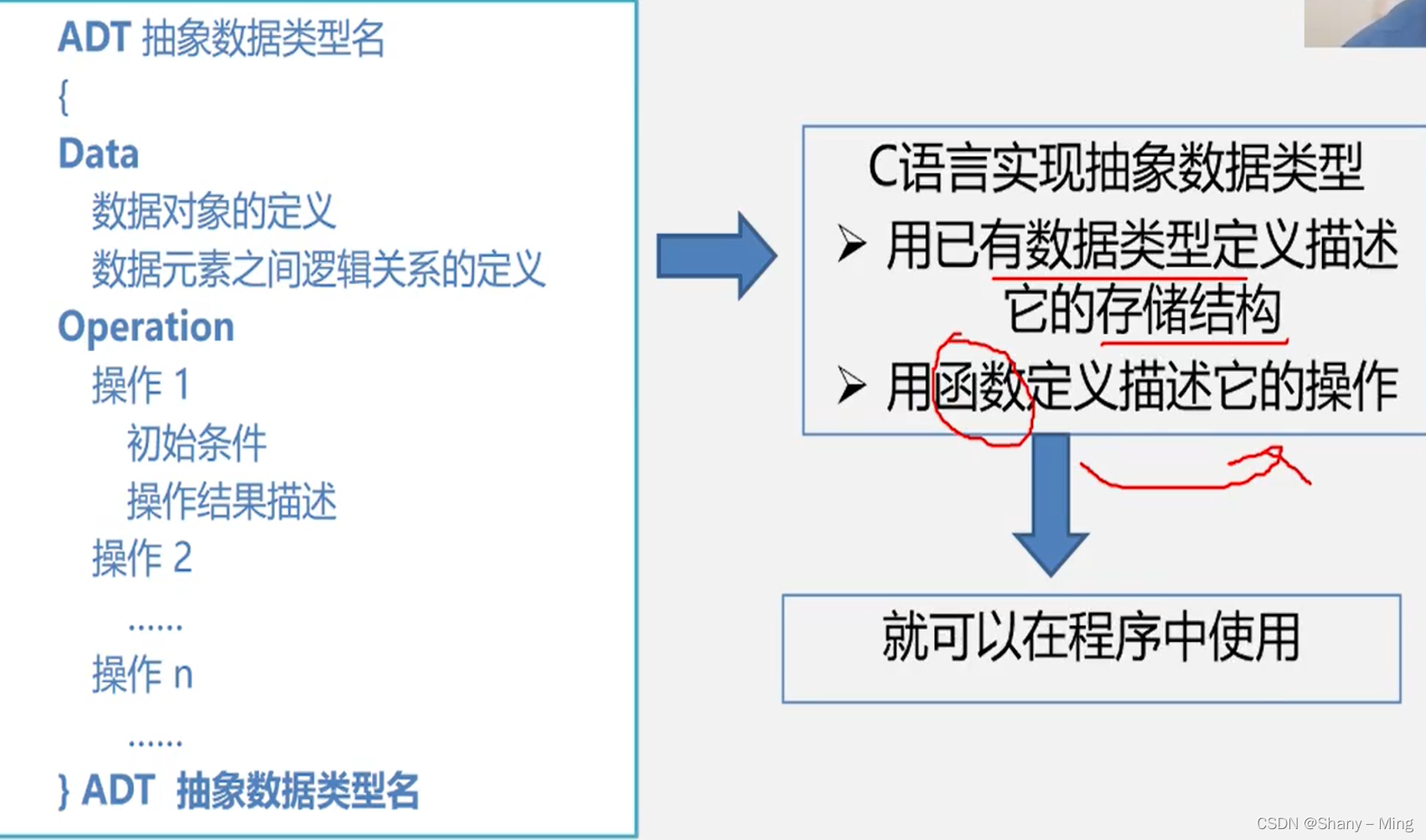
抽象資料型別(Abstract Data Type, ADT)一般指由用戶定義的、表示應用問題的數學模型,以及定義在這個模型上的一組操作的總稱,具體包括三部分:資料物件、資料物件上關系的集合以及對資料物件的基本操作的集合,

抽象資料型別的形式定義:

基本操作格式定義說明:
引數表:賦值引數,只為操作提供輸入值 參考引數以&打頭,
初始條件:描述了操作執行之前資料結構和引數應滿足的條件,若初始條件為空,則省略,
操作結果:說明了操作正常完成之后,資料結構的變化狀況和應回傳的結果,
抽象資料型別的表示及實作:


4.概念小結
二.演算法和演算法分析
1.演算法的定義及特性
演算法(Algorithm)是為了解決某類問題而規定的一個有限長的操作序列,

資料結構通過演算法實作操作
演算法根據資料結構設計程式
演算法必須滿足的五個特性:
(1)有窮性,一個演算法必須總是在執行有窮步后結束,且每一步都必須在有窮時間內完成,
(2)確定性,對千每種情況下所應執行的操作,在演算法中都有確切的規定,不會產生二義性,使演算法的執行者或閱讀者都能明確其含義及如何執行,
(3)可行性,演算法中的所有操作都可以通過已經實作的基本操作運算執行有限次來實作,
(4)輸入,一個演算法有零個或多個輸入,當用函式描述演算法時,輸入往往是通過形參表示的,在它們被呼叫時,從主調函式獲得輸入值,
(5)輸出,一個演算法有一個或多個輸出,它們是演算法進行資訊加工后得到的結果,無輸出的演算法沒有任何意義,當用函式描述演算法時,輸出多用回傳值或參考型別的形參表示,
演算法的評判標準:
1)正確性,在合理的資料輸入下,能夠在有限的運行時間內得到正確的結果,
(2)可讀性,一個好的演算法,首先應便千人們理解和相互交流,其次才是機器可執行性,可讀性強的演算法有助于人們對演算法的理解,而難懂的演算法易千隱藏錯誤,且難千除錯和修改,
(3)健壯性,當輸入的資料非法時,好的演算法能適當地做出正確反應或進行相應處理,而不會產生一些莫名其妙的輸出結果,
(4)高效性,高效性包括時間和空間兩個方面,時間高效是指演算法設計合理,執行效率高,可以用時間復雜度來度量;空間高效是指演算法占用存盤容量合理,可以用空間復雜度來度量,時間復雜度和空間復雜度是衡量演算法的兩個主要指標
在這幾個條件都滿足的情況下,我們就要考慮演算法效率

2.演算法的時間復雜度
1).陳述句頻度及計算方式
一個演算法的執行時間大致上等千其所有陳述句執行時間的總和,而陳述句的執行時間則為該條陳述句的重復執行次數和執行一次所需時間的乘積,
一條陳述句的重復執行次數稱作陳述句頻度,
但由于計算機的硬體關系,相同程式在不同計算機的運行程式的時間是不同的
所以:
設每條陳述句執行一次所需的時間均是單位時間,則一個演算法的執行時間可用該演算法中所有陳述句頻度之和來度量
求兩個n階矩陣的乘積演算法:
由于for回圈需要判斷,所以在到達n時還會進行一次判斷,所以為n+1,但其下的子句仍然是n次,因為最后一次判斷是錯,所以最后一次并未進回圈內部
2).演算法時間復雜度的定義
為了便于比較兩個不同的演算法效率,我們僅比較他的數量級,如上乘積演算法,它的數量級為n^3

上題的時間復雜度為T(n)=O(n^3)
??????
3).最好、最壞和平均時間復雜度
最好時間復雜度,指的是演算法計算量可能達到的最小值;
稱演算法在最壞情況下的時間復雜度為最壞時間復雜度,指的是演算法計算量可能達到的最大值;
演算法的平均時間復雜度是指演算法在所有可能情況下,按照輸入實體以等概率出現時,演算法計算量的加權平均值
三.演算法空間復雜度
關千演算法的存盤空間需求,類似千演算法的時間復雜度,我們采用漸近空間復雜度作為演算法所需存盤空間的扯度,簡稱空間復雜度,它也是問題規模n的函式,記作:
S(n) = O(f (n)
演算法本身要占據的空間:輸入/輸出、指令、常數、變數等,
演算法要使用的輔助空間,
若輸入資料所占據的空間只取決于問題本身和演算法無關,這樣只需分析該演算法在實作時所需的輔助單元即可,若演算法執行時所需的輔助單元相對于輸入資料量而言是個常數,則稱此演算法為原地施工,空間復雜度為O(1)


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/376069.html
標籤:其他