一,記憶體模型
Spark的記憶體模型如下圖所示:
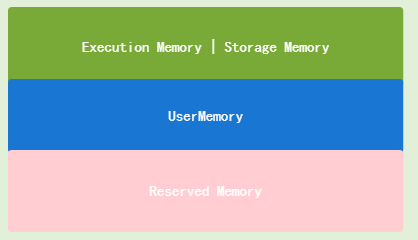
- Reserved Memory 固定為 300MB,不受開發者控制,是啟動Spark框架本身所需要的記憶體空間
- UserMemory 是用戶空間,即用戶定義的資料,通常是用戶在代碼中定義的變數,可以說,除RDD、廣播、全域變數、計算程序中產生的資料之外都是用戶定義的資料
- Execution Memory 執行計算任務所需要的記憶體,如源資料加載占用的是這部分記憶體,以及在計算程序中產生的中間資料使用的記憶體都是這部分記憶體
- Storage Memory 快取、廣播、全域變數使用這部分記憶體
PS:在記憶體不夠時,Spark是報OOM還是把部分資料溢位到檔案中?
在兩個場景下,會有溢位到檔案,一是RDD的cache,二是shuffle的中間資料,其他場景下,如果記憶體不足,會導致OOM錯誤,
二,配置項

- spark.executor.memory 是絕對值,它指定了 Executor 行程的 JVM Heap 總大小,
- spark.memory.fraction 標記 Spark 處理分布式資料集的記憶體總大小,這部分記憶體包括 Execution Memory 和 Storage Memory 兩部分,如上圖所示,表示第一層記憶體占用的大小
- spark.memory.storageFraction 區分 Execution Memory 和 Storage Memory 的初始大小,標識第一層劃分的兩部分各自占用的比例
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/377439.html
標籤:其他