概述
最近在讀Designing Data-Intensive Application(簡稱DDIA)設計資料密集型應用,中文翻譯, 整體感覺翻譯得還是不錯的,讀到第九章《一致性與共識》的時候,里面有對因果一致性的闡述,結合之前微信朋友圈技術負責人在2015年ArchSummit全球架構師峰會(相關的分享資料可從如下地方獲取)上關于朋友圈某一條狀態的評論以及評論的回復,在跨資料中心(IDC)多副本間復制資料時,對因果一致性理論的應用,巧妙地解決了寫沖突的問題,我們來看看因果一致性在實際業務開發中是如何應用的,
因果一致性的理解
下面我們先就DDIA的內容來看一個簡單的問-答例子,并由此給因果關系下一個定義:
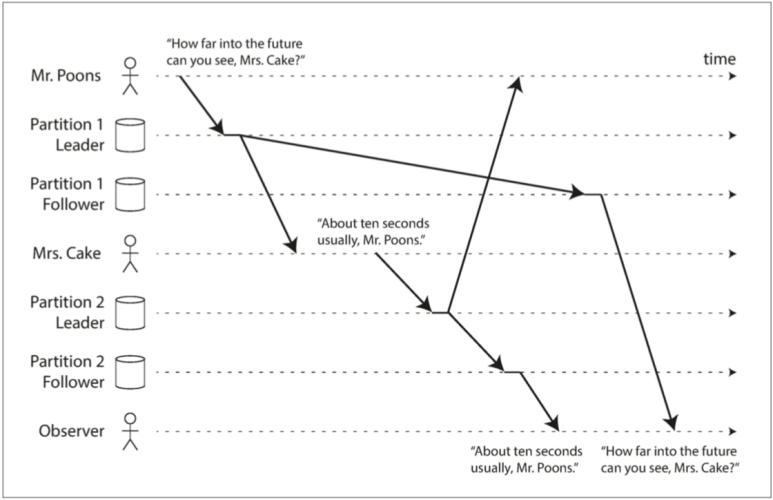
圖1、問-答的因果關系
從上圖1可知,一個對話的觀察者(Observer)首先看到問題的答案“About ten seconds...”,然后才看到被回答的問題“How far into the ...”,這是令人困惑的,因為它違背了我們對因與果的直覺:如果一個問題被回答,顯然問題本身得先在那里,因為給出答案的人必須已經看到這個問題,我們認為在問題和答案之間存在因果依賴,
考慮我們設計這樣一個問答平臺,當有一個用戶去訪問資料,例如重繪最新的所有問-答串列,就像重繪知乎推薦頁面一樣,他一定要先看到問題,然后再看到答案,否則就會給用戶帶來很大的困擾,因為只看到答案,而沒有相應的問題是沒有實際的意義的,
正如DDIA所提到的,因果關系對事件施加了一種順序:因在果之前,訊息發送在訊息收取之前,而且就像現實生活中一樣,一件事會順序地導致另一件事發生:某個節點讀取了一些資料然后寫入一些結果,另一個節點讀取其寫入的內容,并依次寫入一些其他內容等等,這些因果依賴的操作鏈定義了系統中的因果順序,即什么在什么之前發生,從而我們也引出了分布式系統的因果一致性,如果一個系統服從因果關系所規定的順序,我們說它是因果一致性的,
微信朋友圈的因果一致性
下面我們來看微信朋友圈某條狀態的評論以及對評論的答復(也是評論)所構成的因果關系,以及微信是怎樣通過保證不同資料中心間的因果一致性來保證一個用戶在刷朋友圈的時候不會出現看到評論所對應的答復,卻看不到答復對應的評論,要理解下文的前提是一定要實事前去學習前文提到的:微信朋友圈技術負責人陳明在2015年ArchSummit全球架構師峰會上的分享資料,
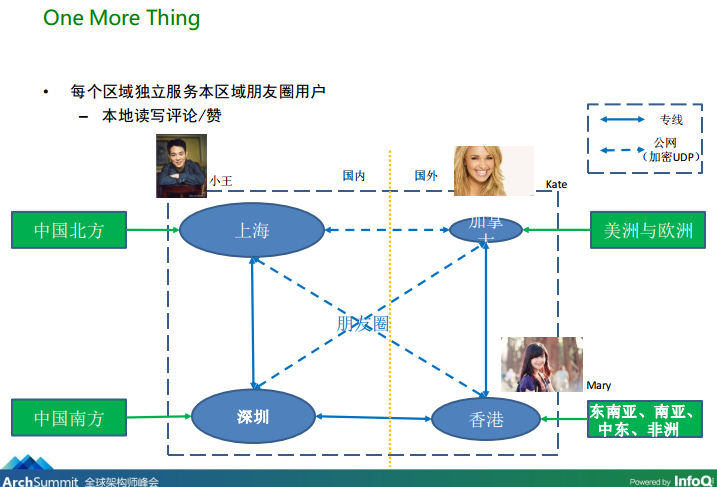
圖2、微信分布在全球四地的資料中心
從圖2微信分布在全球四地的資料中心,可知用戶小王有兩個朋友:Mary、Kate,分別在不同的區域下(資料中心),所以他們要看到彼此朋友圈的內容時,必須等到相關的資料在不同資料中心間的副本同步到用戶所在的IDC完成之后才能看到,
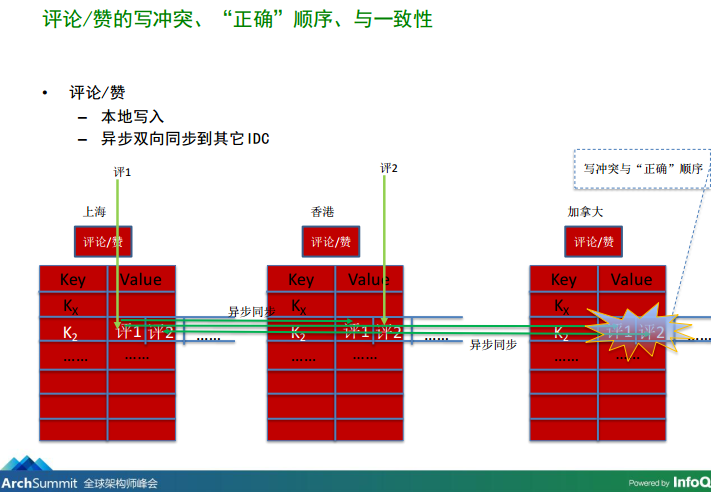
圖3-1、資料在副本間同步時亂序

圖3-2、資料在副本間同步時亂序
從上圖3-1、3-2可知,由于網路在不同副本間復制資料時的延遲、中斷等分布式系統中常見的場景,導致兩條訊息在同步到用戶Kate(加拿大)所在資料中心上的副本時已經亂序了,即原先順序是這樣的:“Mary:這是哪里?”->“小王:Mary,這是梅里雪山”,然而Kate去資料庫中查到的訊息卻是這樣的順序:“小王:Mary,這是梅里雪山”->“Mary:這是哪里?”,或者中間的某個時刻只能查詢到“小王:Mary,這是梅里雪山”這一條訊息,你說Kate會不會懵逼,
為了解決這個問題,微信是怎樣來處理的呢,且看下面分析,
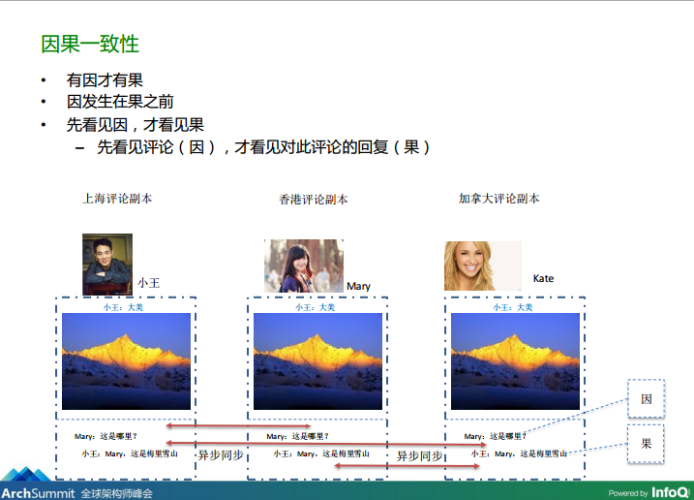
圖4-1、因果關系的梳理
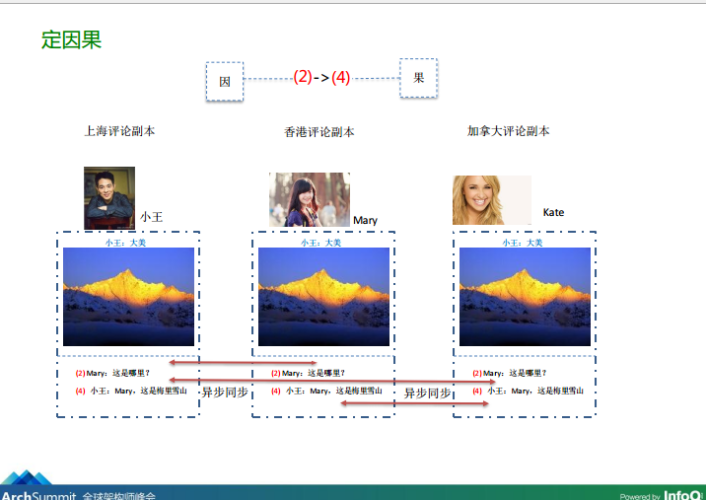
圖4-2、因果關系的梳理
從上圖4-1、4-2可知,我們可以將Mary對小王所發布的朋友圈狀態的評論“Mary:這是哪里?”當成因,而把小王對Mary評論的答復“小王:Mary,這是梅里雪山”當成果,按照這樣的約定,當這兩條資料同步到Kate所在的資料中心副本時即使發生亂序,Kate根據在刷朋友圈時,根據因果關系也可以將這個評論、答復的順序調整到正確的、可閱讀的方式,那微信到底是采用什么方法來讓各個地區的用戶理解這個約定呢?具體來看:
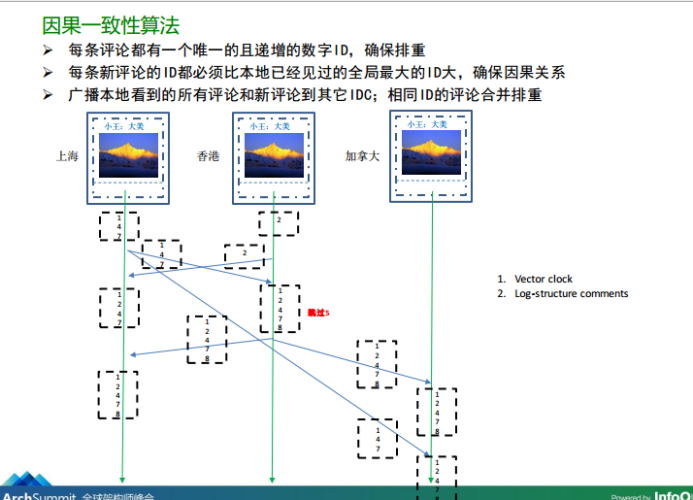
圖5、朋友圈事件因果一致性的演算法
從圖5我們可知,微信采用如下的方案:
- 每條評論都有一個唯一的且遞增的數字ID,確保排重
- 每條新評論的ID都必須比本地已經見過的全域最大的ID大,確保因果關系
- 廣播本地看到的所有評論和新評論到其它IDC;相同ID的評論合并排重
我們可以針對上面的三點背后的技術作出合理性的解讀跟假設:
1、每條評論都有一個唯一的且遞增的數字ID:那么背后肯定是一個ID生成器,各個資料中心都有一個這樣的入口來獲取本IDC內唯一、遞增的ID,具體怎么做的可參考,
2、每條新評論的ID都必須比本地已經見過的全域最大的ID大,確保因果關系:如上圖在香港的資料中心,當發表完2的評論,并且已經同步上海資料中心過來的1 4 7等ID的評論之后,如果再有香港地域下的用戶發表新評論時,那么一定要大于當前香港資料中心能看到的全域最大ID,此時是7,所以香港地域此時用戶最新發表的評論的ID必須大于7(上圖有一個“跳過5”的備注),所以上圖中的ID(8)就是從這里得出的,
3、廣播本地看到的所有評論和新評論到其它IDC;相同ID的評論合并排重:那么什么時候廣播呢?其實就是本地域下的用戶針對同一條朋友圈狀態有評論時,該地域就負責申請一個全域ID,然后將這個評論的事件廣播給其他的資料中心,注意這個程序需要合并所有看到的序列,例如香港資料中心就合并1 2 4 7 8等針對同一條朋友圈狀態的一系列評論事件IDs,然后再整體廣播出去,這樣才能保證針對同一條狀態的所有當前最新的事件整體被廣播出去,否則此時香港IDC只廣播8的話,如果前面的事件序列在廣播的中途丟失了,那么其他節點比如加拿大IDC就會漏掉部分評論事件,這也是資料多重補位的措施,當然這個方法有一個前提就是:因為同一個朋友圈的發布狀態,一般的評論不會很多,所以造成的資料冗余互動不會很大,否則是不行的,至于相同ID的評論合并排重,上圖5可以看出,加拿大IDC會收到來自上海IDC的1 4 7事件系列,也會收到來自香港IDC同步過來的1 4 7 8 事件系列,這兩個廣播的事件系列有重復,所以需要去重,
總結
以上就是因果一致性在實際分布式系統業務中的應用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/3787.html
標籤:其他