一、環境準備
編輯器:vscode
JDK版本:JDK1.8
專案管理器:maven
二、專案結構以及坐標依賴
專案結構:
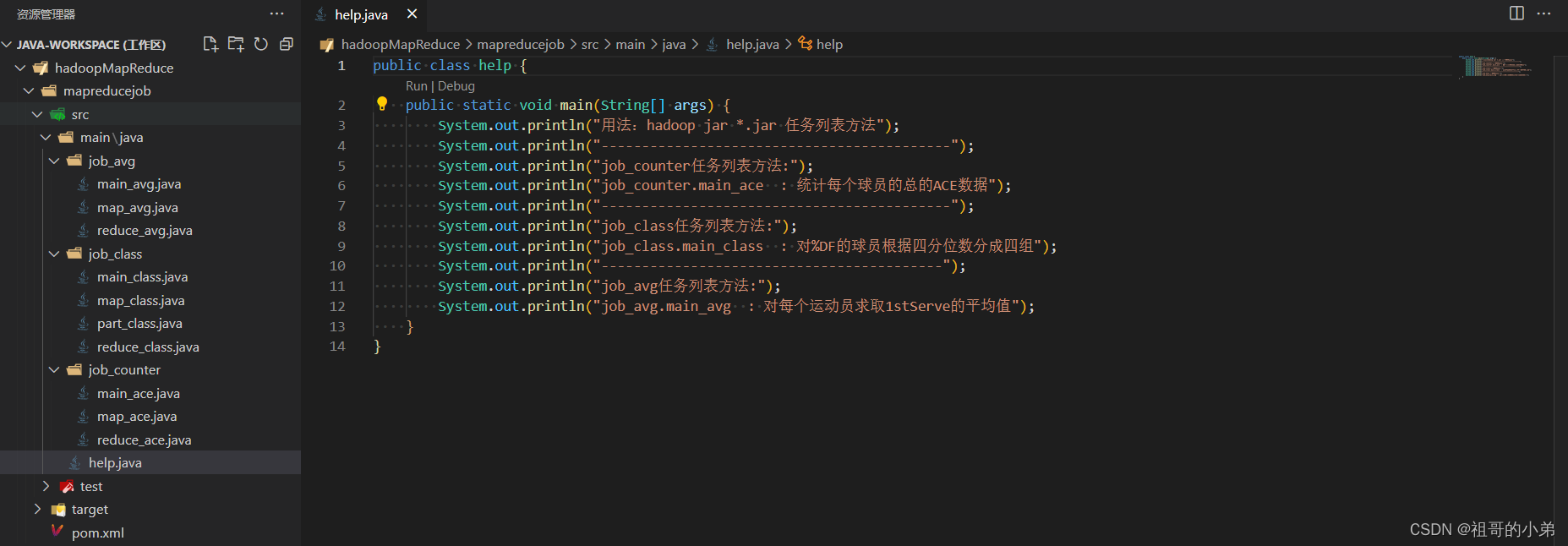
坐標依賴:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.7.5</version>
</dependency>
三、資料結構
資料下載地址:
鏈接:https://pan.baidu.com/s/10h_3TL27zYO0_WRTTfn2CQ
提取碼:8888
資料預覽:
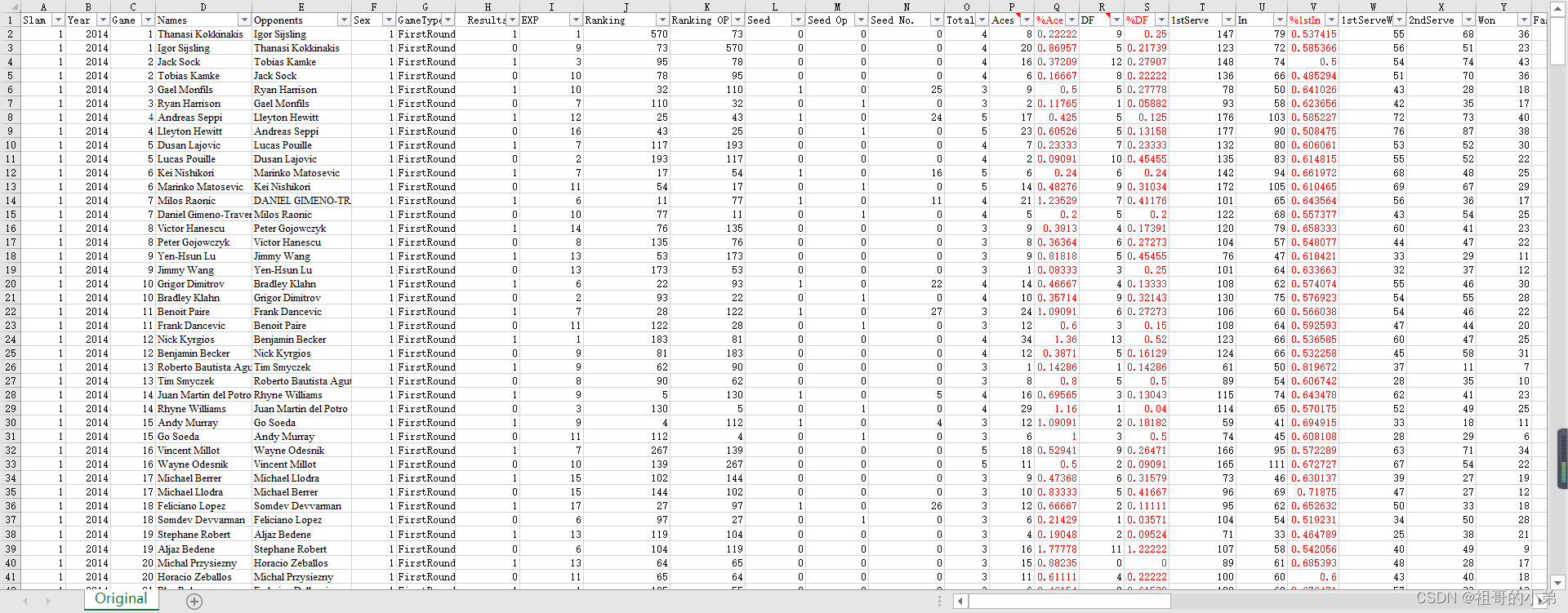
去掉首行索引保存為.csv檔案,上傳到hadoop存盤即可,存盤路徑自定義,只需后續在代碼中修改即可,
四、專案代碼
①MapReduce作業一
目標:job_counter: 統計每個球員的總的ACE資料
檔案結構:
map_ace.java代碼:
package job_counter;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class map_ace extends Mapper<LongWritable,Text,Text,LongWritable> {
/*
輸入的:k1 v1
k1 v1
longwriteable 行號 text "1,2014,1,Thanasi Kokkinakis,Igor Sijsling,1,FirstRound,1,1,570"
輸出的:list(k2 v2)
k2 v2
text name longwriteable ace
A 8
A 5
B 3
*/
//map方法統計ACE球的個數
/*
輸入(行,行值)
輸出(名字,ACE個數)
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//1.每行文本拆分,并獲取值
String[] line=value.toString().split(",");
String name=line[3];
String ace=line[15];
//2.寫入背景關系
Text text=new Text();
LongWritable longWritable=new LongWritable();
text.set(name);
longWritable.set(Long.parseLong(ace));
context.write(text,longWritable);
}
}
reduce_ace.java代碼:
package job_counter;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class reduce_ace extends Reducer<Text, LongWritable, Text, LongWritable> {
//reduce方法統計總和
/* meger list(k2,v2)====>k2 list(v2)===A <8,5>
輸入的: k2 v2
A <8,5>
B <10,7>
輸出的: k3 v3
name ace_totle
*/
@Override
protected void reduce(Text key,Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {
//遍歷集合,將每個值累加
long point=0;
for (LongWritable value : values) {
point=point+value.get();
}
//將k3,v3寫入背景關系
context.write(key, new LongWritable(point));
}
}
main_ace.java代碼:
package job_counter;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class main_ace extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
//1.創建一個job任務物件
Configuration conf=super.getConf();
Job job=Job.getInstance(conf,"main_ace");
//打包運行時函式
job.setJarByClass(main_ace.class);
//2.配置job物件
//第一步:指定檔案的讀取方式和路徑
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://192.168.96.138:9000/user/hadoop/job_data"));
//第二步,指定map階段的處理方式
job.setMapperClass(map_ace.class);
//設定map階段k2型別
job.setMapOutputKeyClass(Text.class);
//設定map階段v2型別
job.setMapOutputValueClass(LongWritable.class);
//shuffe使用默認
/*
k1,v1 ===>k2,v2 ===>k3,v3
meger list(k2,v2)====>k2 list(v2)===A <8,5>
*/
//第七步指定reduce階段的處理方式和資料型別
job.setReducerClass(reduce_ace.class);
//k3型別
job.setOutputKeyClass(Text.class);
//v3型別
job.setOutputValueClass(LongWritable.class);
//判斷檔案路徑是否存在
Path output= new Path("hdfs://192.168.96.138:9000/user/hadoop/counter_out_ace");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output)) {
fs.delete(output, true);
}
//設定輸出路徑
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, output);
//等待任務結束
boolean b1=job.waitForCompletion(true);
return b1 ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration=new Configuration();
//start job
int run=ToolRunner.run(configuration, new main_ace(), args);
System.exit(run);
}
}
②MapReduce作業二
目標: job_class: 對%DF的球員根據四分位數分成四組
檔案結構:
map_class.java代碼:
package job_class;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class map_class extends Mapper<LongWritable, Text, Text, NullWritable> {
///對每個運動員進行四分位分類操作
/*
輸入(行,行值)
輸出(行值,null)
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//寫入背景關系
context.write(value,NullWritable.get());
}
}
part_class.java代碼:
package job_class;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class part_class extends Partitioner<Text,NullWritable>{
/*
1:定義磁區
2:回傳對應的磁區編號
*/
/*四分位數
25 0.111111111111110
50 0.181818181818182
75 0.300000000000000
*/
@Override
public int getPartition(Text text, NullWritable nullWritable, int i) {
// TODO Auto-generated method stub
//1,:拆分文本,獲得欄位
String[] split=text.toString().split(",");
String df=split[18];//%DF的坐標
double low = 0.111111111111110;
double zhong=0.181818181818182;
double hig=0.300000000000000;
//判斷df與四分位數的關系
if(Double.parseDouble(df)<low){//小于25%
return 3;
}
else if(Double.parseDouble(df)>low & Double.parseDouble(df)<=zhong){//大于25%小于50%
return 2;
}
else if(Double.parseDouble(df)>zhong & Double.parseDouble(df)<=hig){//大于50%小于75%
return 1;
}
else{//大于75%
return 0;
}
}
}
reduce_class.java代碼:
package job_class;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class reduce_class extends Reducer<Text, NullWritable, Text, NullWritable> {
//reduce方法不做處理,直接輸出
@Override
protected void reduce(Text key, Iterable<NullWritable> values,Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
main_class.java代碼:
package job_class;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class main_class extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
// 1.創建一個job任務物件
Configuration conf = super.getConf();
Job job = Job.getInstance(conf, "main_class");
// 打包運行時函式
job.setJarByClass(main_class.class);
// 2.配置job物件
// 第一步:指定檔案的讀取方式和路徑
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://192.168.96.138:9000/user/hadoop/job_data"));
// 第二步,指定map階段的處理方式
job.setMapperClass(map_class.class);
// 設定map階段k2型別
job.setMapOutputKeyClass(Text.class);
// 設定map階段v2型別
job.setMapOutputValueClass(NullWritable.class);
// shuffe使用part_class
job.setPartitionerClass(part_class.class);
//設定4個任務
job.setNumReduceTasks(4);
/*
* k1,v1 ===>k2,v2 ===>k3,v3
*/
// 第七步指定reduce階段的處理方式和資料型別
job.setReducerClass(reduce_class.class);
// k3型別
job.setOutputKeyClass(Text.class);
// v3型別
job.setOutputValueClass(NullWritable.class);
// 判斷檔案路徑是否存在
Path output = new Path("hdfs://192.168.96.138:9000/user/hadoop/class_out_%DF");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output)) {
fs.delete(output, true);
}
// 設定輸出路徑
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, output);
// 等待任務結束
boolean b1 = job.waitForCompletion(true);
return b1 ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
// start job
int run = ToolRunner.run(configuration, new main_class(), args);
System.exit(run);
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379147.html
標籤:其他